
How NOT to store unstructured machine learning datasets

Training data is typically the most valuable part of any machine learning project. As we converge on model architectures like the transformer that perform well on many tasks, it is the data that goes into the model that makes the difference.
Data is a Buzz Kill
When starting any machine learning project, there is excitement in the air. The excitement of tackling a new problem that you think can be solved with machine learning. Letting the machine automate away all your worries. Help you as an assistant. Model building, evaluation and training always feels like you are entering a mysterious land of unknowns and a solution is right around the corner.

The problem is, more times than not when starting a machine learning project the excitement slowly peters out as soon as I get to the data. Datasets are stored in all sorts of formats, with different conventions, standards, and optimizations made by the team who developed it.
This become more and more frustrating the more data you work with.


We are going to dive into some of the formats and conventions that have been used in the past, and propose a solution called 🧼 SUDS in the next post.
Messy Conventions
Understanding the data that we use to train models is only getting more important as AI systems become smarter. Let’s be responsible AI citizens and clean up our data.
If you have worked in machine learning for long enough, you start to see patterns left by grad students or abandoned research that get re-used and recycled over the years, but rarely gets updated. Once a dataset gets released there is hardly any incentive to update the format to make it more usable because it “just worked” for the people who built it.
This leads to wasted engineering effort, duplicate code, non-composable datasets, and generally hard to audit changes to the data over time.
Below are some conventions that I think we should steer away from.
Non-Human Readable Formats
Machine learning has progressed to the point where it can process data such as images, video, audio, and text. This is great because as humans this is how we perceive data as well. Allowing humans to view and debug data is key in creating a robust machine learning system. If you do not understand the biases or nuances of your data, you will have a hard time understanding why a ML algorithm failed.
For example, take the canonical intro to machine learning example of classifying handwritten digits from the MNIST database.


Even if you are a seasoned engineer, it takes time to learn the format of these *-ubyte.gz files to finally unpack them and see the actual training images.

I would argue that storing these 28x28 images as actual pngs or jpgs instead of a compressed binary representation is more optimal in the long run even though it may take up more disk space or network bandwidth. The time it takes for humans to download, unpack, debug, label, and extend the data outweighs the disk usage optimizations.
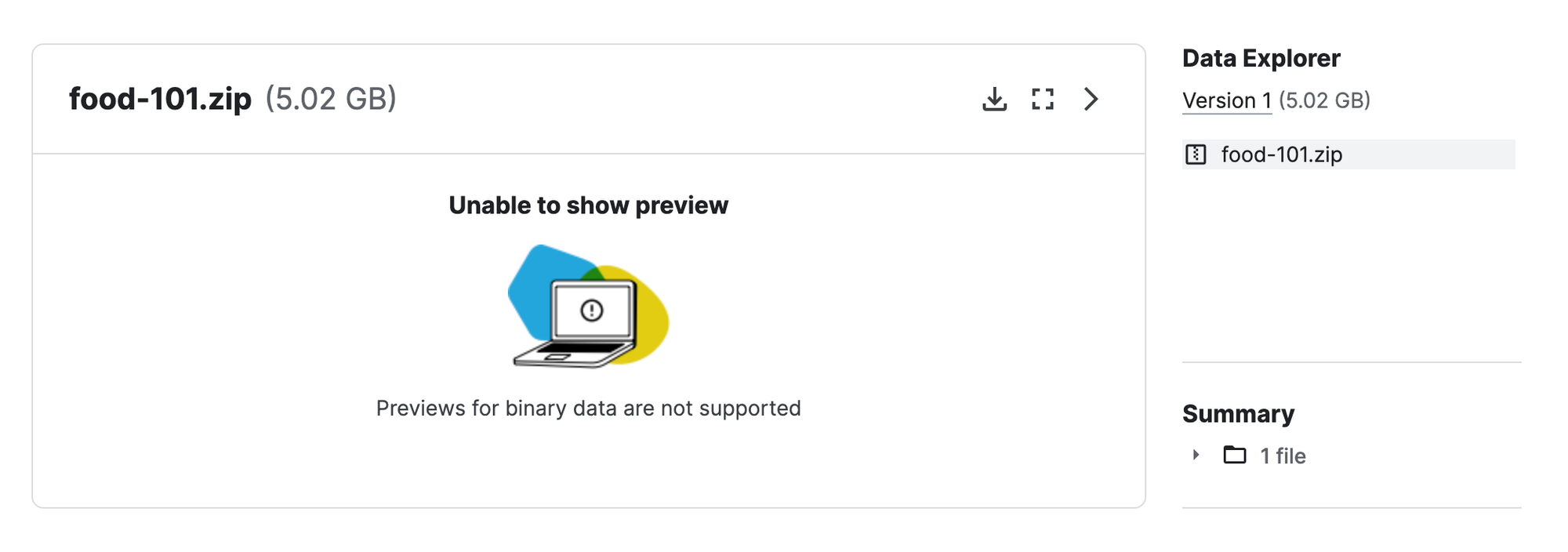
Compressed zip files or tarballs
Yes is a tried and true way to bundle everything up and dump into cloud storage.
The problem is it lacks in visibility, it requires anyone who wants to use it to download the whole thing (which could take minutes, hours, or days) then often lead to a surprise when you unzip it and see what is inside.
I think smarter tooling to upload/stream data is a better path forward than simply using a zip file. (Hint: We are building this at Oxen.ai)
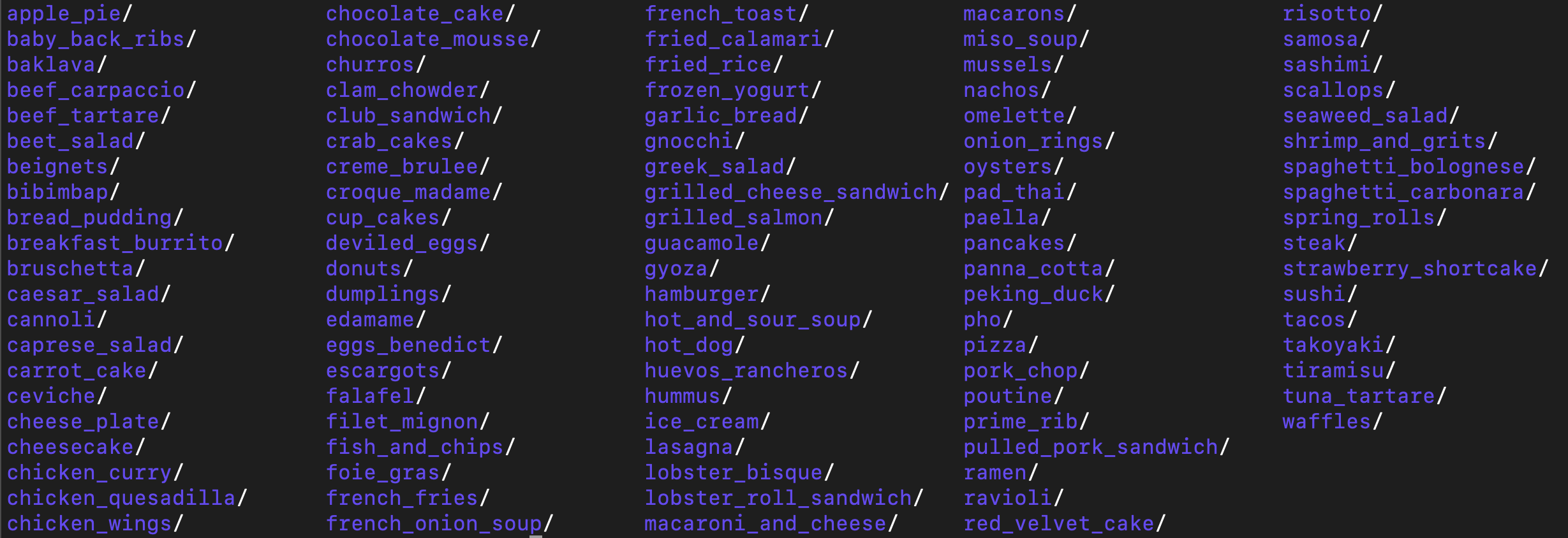
Directory/File names as labels
One could argue this is the simplest format for classification problems, but is quite the pain to traverse the filesystem to aggregate counts and statistics. Custom code needs to be written in python or bash or your language of choice to get any visibility into the distribution of the data.
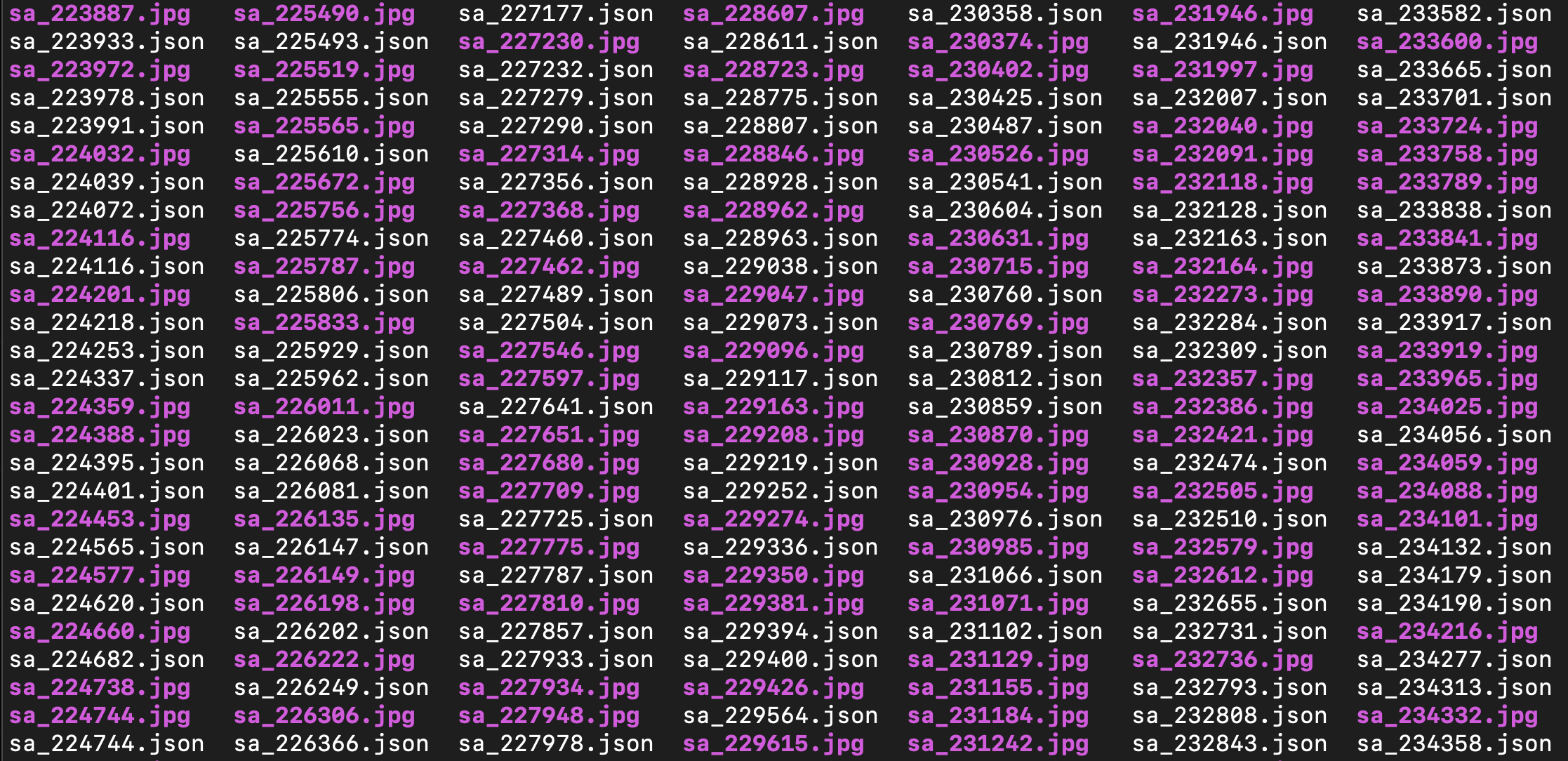
Parallel filenames with annotations
Another pattern is to simply list all the files, and have matching base file names with different paths and extensions to label the data. For example random/path/data1234.jpg goes with other/path/data1234.json.
Again, this may be convenient, but is hard to do any aggregation or statistics without writing custom code to load each image and json file individually.
Nested json fields in data frame columns
Yes this may be convenient for your data loader, yours and no one else's. Good luck searching, aggregating and exploring nested json. It’s better to split these out into separate columns if possible and collate in your data loader code.

Leaving in absolute paths
Thanks /data/random_university/student_who_cleaned_the_data/projects/stuff I don’t need to know your file structure.
I can't believe I have to say this one, but it happens more often than you would imagine.
File path templates for annotations
Take the file column + the split column + the name of my first born child, hash it, and there’s your relative path to the image.
File paths should be relative to the root of the data repository itself and fully spelled out
- ✅ images/celebrities/face_0.jpg
- ❌ face_0.jpg
- ❌ /home/username/CelebA/images/celebrities/face_0.jpg
The list could go on and on. Want more conventions? Just go on https://paperswithcode.com/datasets and click on a dataset. You’ll find a new format.
What should we do about it?
The point of this post is not simply complain, but to define the problem and propose a solution. If you are with us so far, or have felt this pain, please follow us to our proposed solution 🧼 SUDS.
 Greg Schoeninger
Greg Schoeninger
Who is Oxen.ai? 🐂 🌾
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI