
🌲 Merkle Tree VNodes


In this post we peel back some of the layers of Oxen.ai’s Merkle Tree and show how we make it suitable for projects with large directories. If you are unfamiliar with Merkle Trees or just want a refresher, we suggest you check out our introductory post on Merkle Trees first.

Why should you care? This post is aimed at anyone who asks the question “What makes Oxen.ai so fast?”. Or maybe you simply love to nerd out on data structures and algorithms. Either way, let’s dive in.
Goals
One of the goals of Oxen is to be able to scale to directories with an arbitrary number of files. We aim to enable seamless collaboration on datasets such as ImageNet which have millions of files and data points. This means subdirectories within Oxen can get quite large, resulting in many nodes at a single level in our tree. Large subdirectories can slow down operations like commits, finding individual nodes and diffs.
To get a sense of Oxen.ai’s performance on these types of datasets, feel free to check out our performance metrics here:

One of the ways we optimize performance is by adding a new node type to our Merkle Tree, we call them VNodes.
Introducing VNodes
VNode stands for “Virtual Node” and is an intermediate node that helps shard the tree when a node has many child files or directories. It was added to optimize the tree for large directories, minimize data duplication, and speed up access patterns such as reads, writes, and diffs.
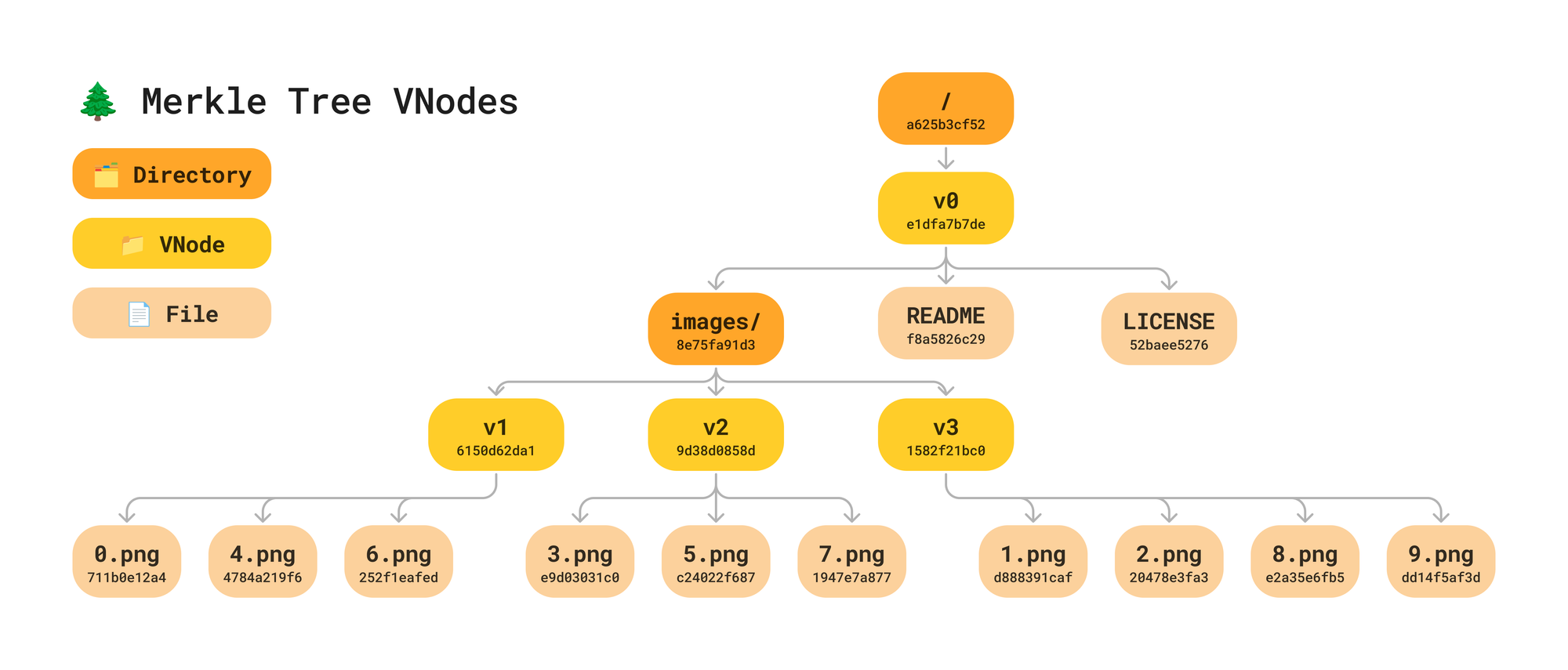
It may not be obvious what the benefit of these intermediate nodes is right out of the gate. In fact, it seems like it is adding an extra layer of indirection and more data to our tree - not less. To bring this concept to life, let’s walk through ImageNet as an example to see where VNodes can help speed up reads, writes, and diffs all while minimizing overall data duplication.
Versioning 1 Million+ Files
The structure of ImageNet is a nice illustration of VNodes in action. ImageNet has a total of about 1.2 million files. Most of these files are images stored in the train/ and test/ directories. Then there may be supplemental annotation files that reference them.
.
├── LICENSE
├── README.md
├── train.parquet
├── test.parquet
└── images (1 million+ files)
├── test (100,000 images)
└── train (1,100,000 images)Let’s say we didn't have VNodes in our initial implementation. All 1.1m files are sitting directly in the train/ directory and 100k images in the test/ directory. This gets hard to visualize, so we will collapse the nodes with ... .
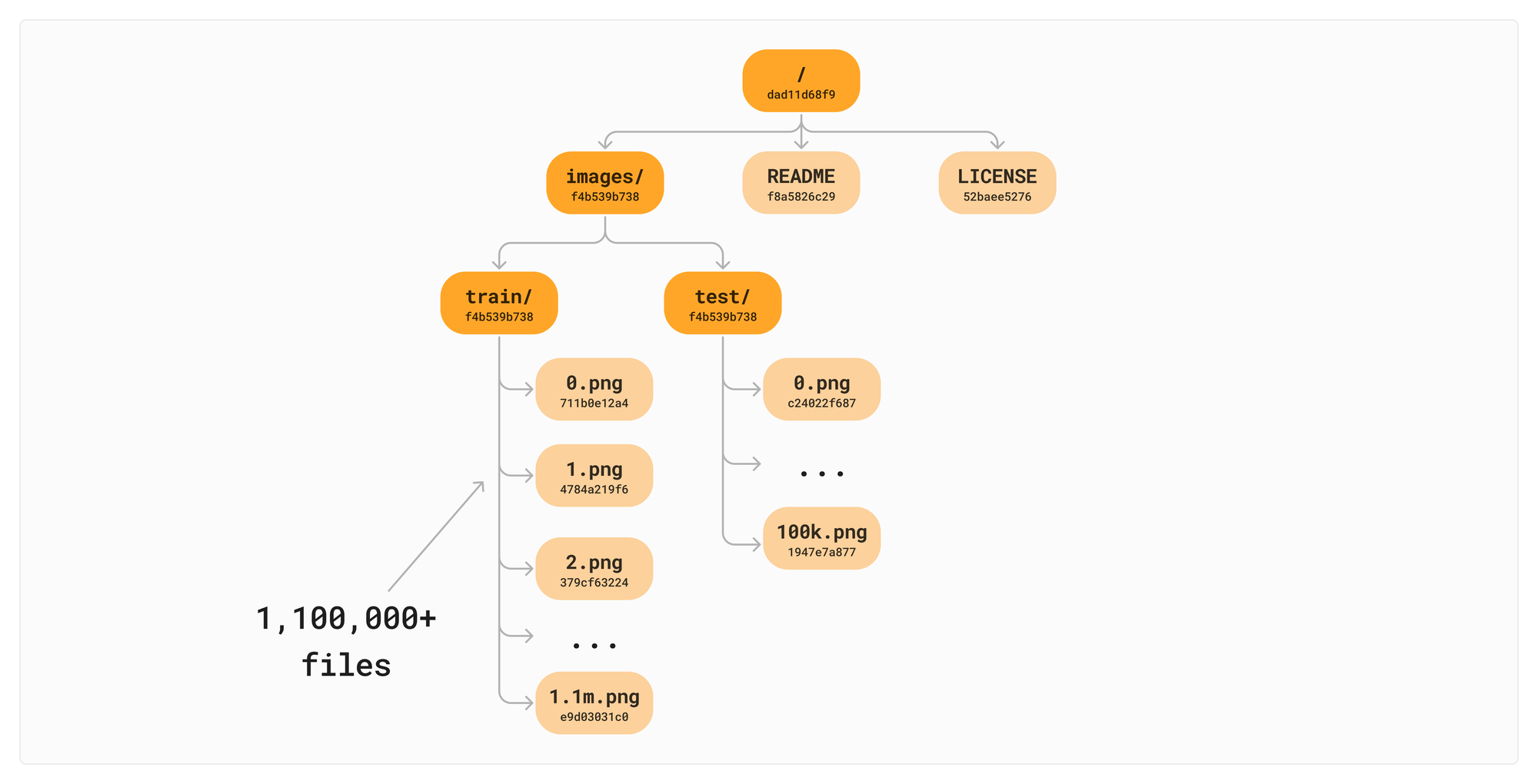
Now let's add a single image to the train/ directory. Data should be a living, breathing, asset after all, it should be quick and painless to add a file. With a naive implementation of a Merkle Tree, this requires a copy of all the references to all the children.
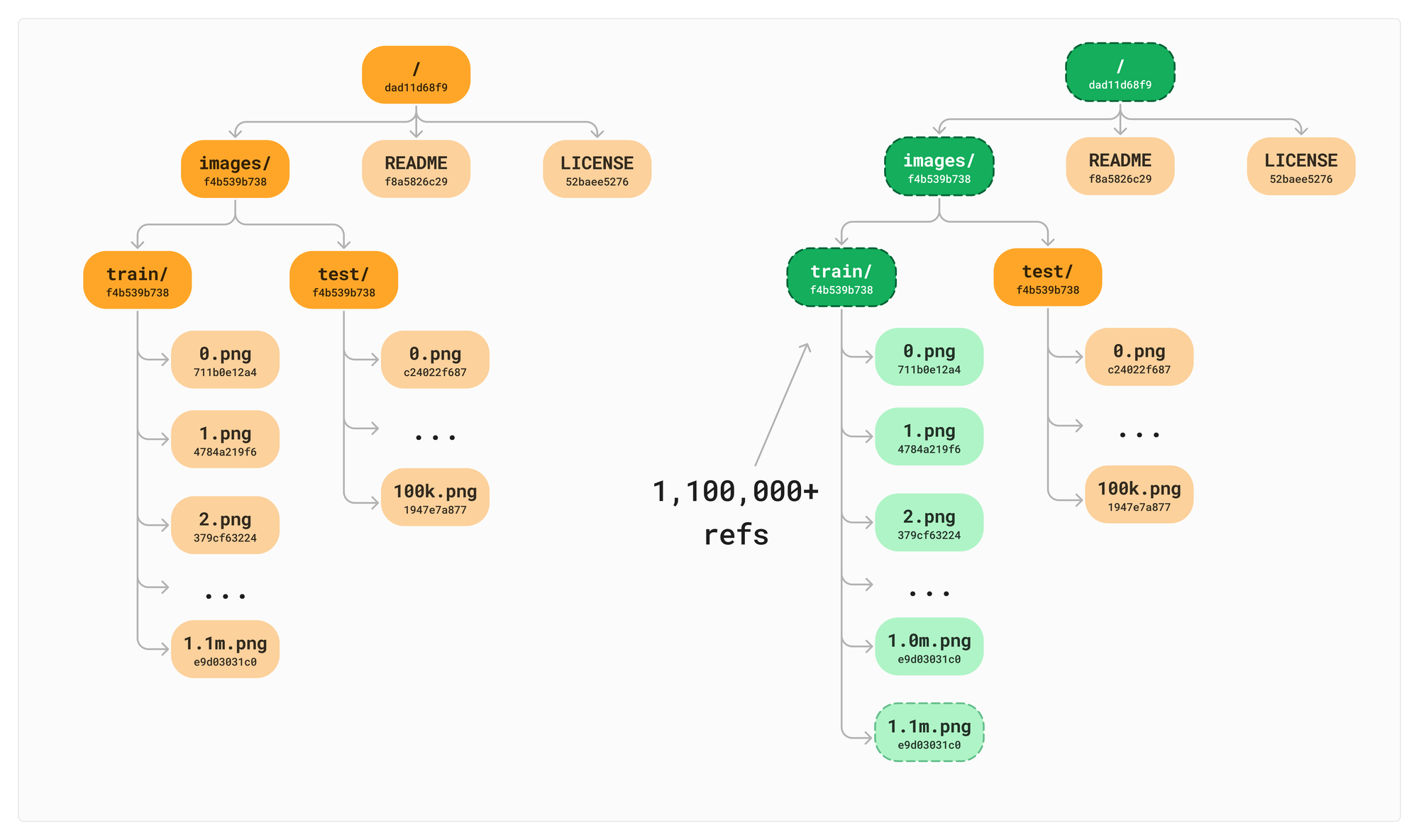
Even though references are lighter to copy than the full files themselves (we do not copy the file data, just the refs) that is still 1.1 million writes we need to do to simply add a single file. Imagine if these were rows in a traditional database. We would definitely want to avoid 1.1 million add row operations to keep track of the file list and hashes on each new version. If we do this for more than 2 commits, the number of references quickly gets out of hand. We will have > 10 million references after just 10 commits, even if we only added 10 new files.
Sharding Data with VNodes
Our way of avoiding this is by dividing the directory into our VNodes. This distributes the load off of any individual directory for both copying data across commits and knowing what changed in portions of the tree. The default VNode size within Oxen is 10,000 children.
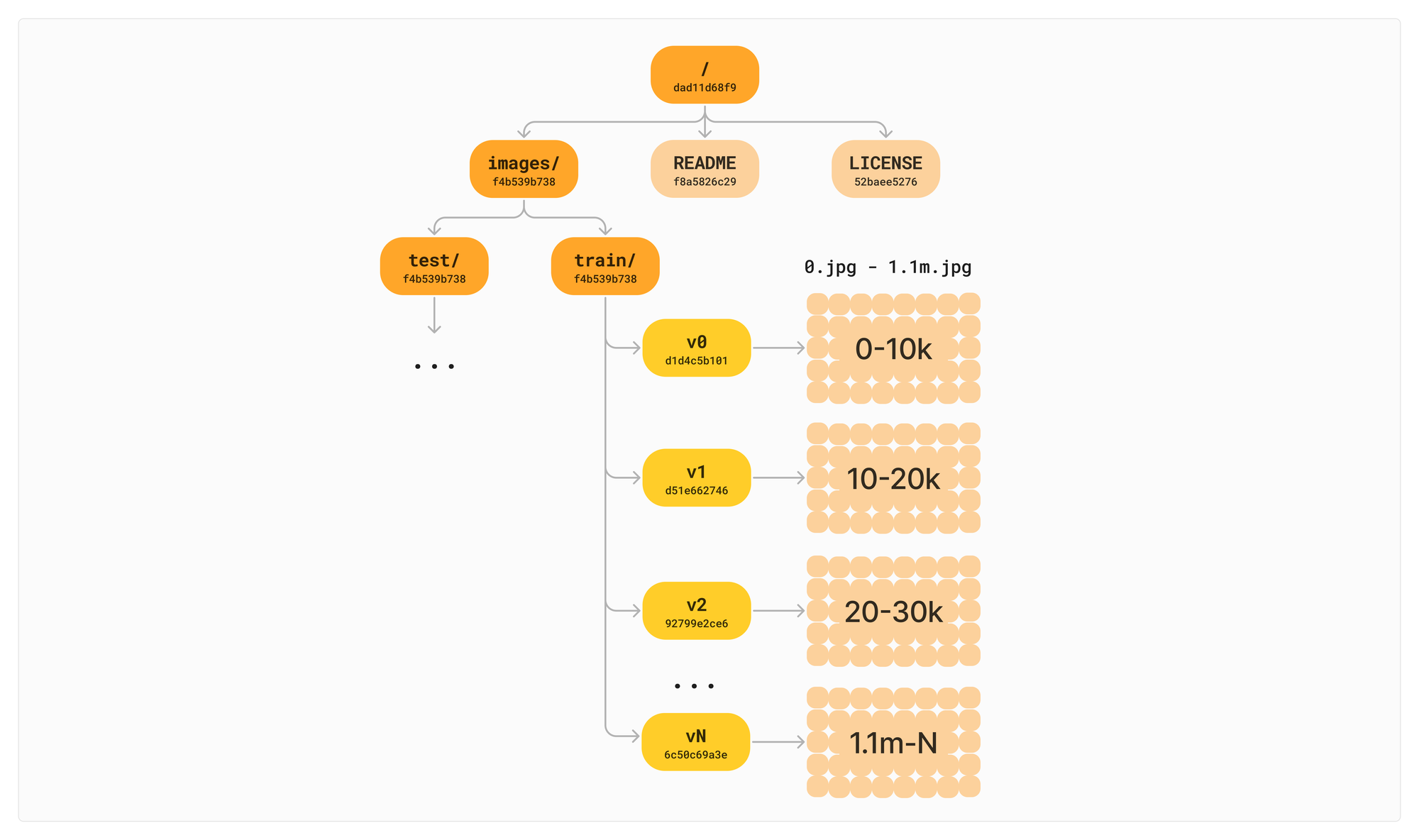
This way when we add or modify a file, we can compute which VNode shard it falls into and only need to copy the 10k references contained in that VNode for the next version. The other 999k+ stay the same.
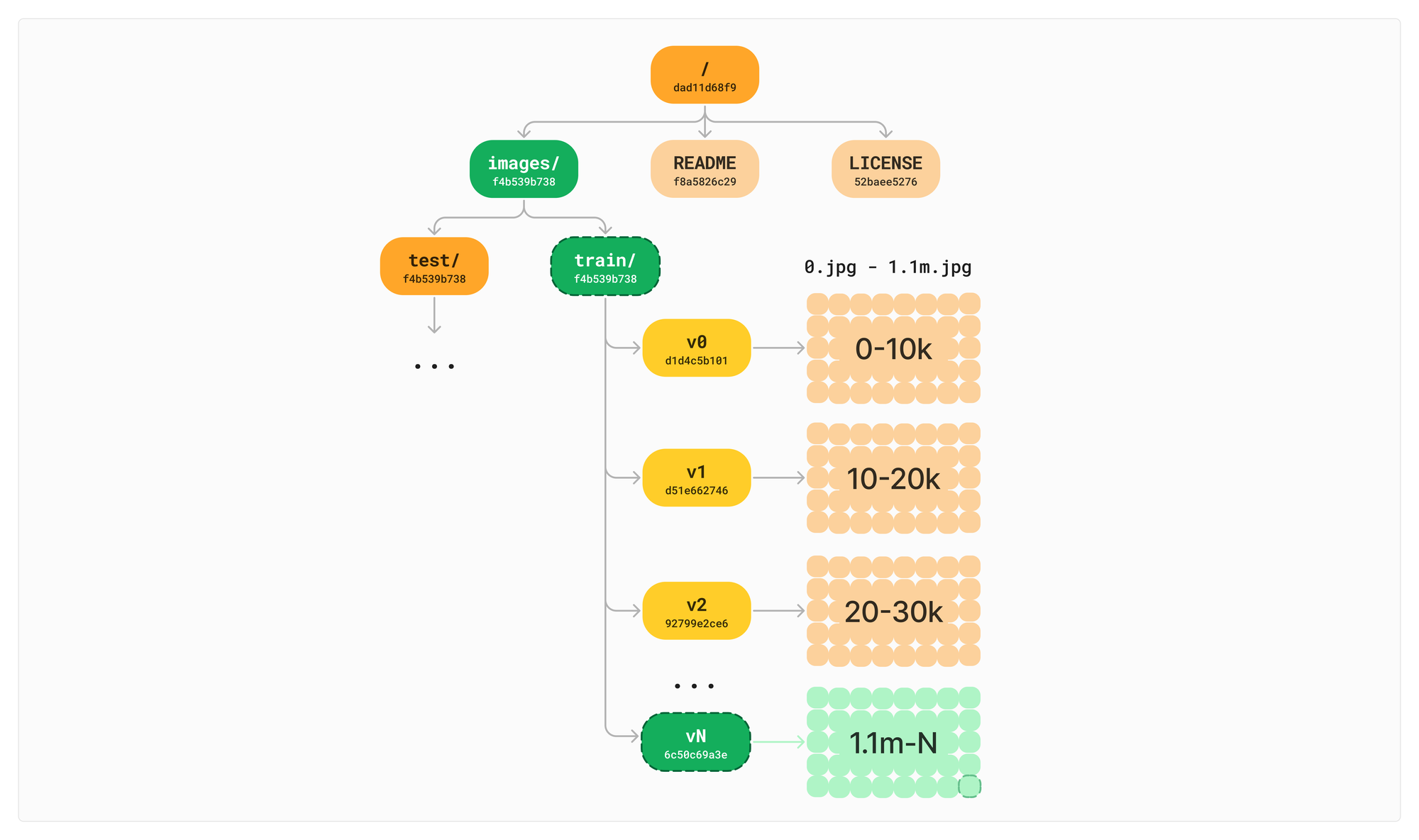
Writing and data duplication are the first places we see the benefits of VNodes; but, as we will see later, VNodes also help reading and diffs. Before we get there though, we have to explain how VNodes get created and how children get assigned to them.
How Many VNodes?
As we mentioned above, the default VNode size for oxen is 10,000. This is set in your hidden .oxen directory in config.toml.
Let’s look at a directory of images as an example:
$ tree
.
├── .oxen
│ ├── config.toml
│ ├── ...
├── README.md
├── images
│ └── train
│ ├── image_0.png
│ ├── image_1.png
│ ├── image_2.png
│ ├── image_3.png
│ ├── image_4.png
│ ├── image_5.png
│ ├── image_6.png
│ ├── image_7.png
│ ├── image_8.png
│ └── image_9.png
└── images.csv
Once you add and commit your data, the oxen tree command will print out the current state of your Merkle Tree. In the case below we configured our tree to have vnode_size=4 instead of 10k for illustration purposes.
$ oxen tree
[Commit] 11d5fc50d2d428e1d4fbdf84d1115924 (0.25.0) "adding data" -> Bessie Oxington ox@oxen.ai parent_ids ""
[Dir] 512200c70d "" (2.7 KB) (12 files) (commit 11d5fc50d2) (3 entries)
[VNode] ab01a0a5a1 (3 entries)
[File] aab559e496 "README.md" (text/markdown) 107 B [aab559e496] (commit 11d5fc50d2) MetadataText(3 lines, 107 chars)
[Dir] 40c8848f84 "images" (2.2 KB) (10 files) (commit 11d5fc50d2) (1 entries)
[VNode] 51d73f367f (1 entries)
[Dir] 3b73dad90e "train" (2.2 KB) (10 files) (commit 11d5fc50d2) (10 entries)
[VNode] 2085eb466d (2 entries)
[File] e9d03031c0 "image_6.png" (image/png) 244 B [e9d03031c0] (commit 11d5fc50d2) MetadataImage(64x64)
[File] 773f07476c "image_7.png" (image/png) 222 B [773f07476c] (commit 11d5fc50d2) MetadataImage(64x64)
[VNode] af2e651e02 (3 entries)
[File] 4784a219f6 "image_2.png" (image/png) 215 B [4784a219f6] (commit 11d5fc50d2) MetadataImage(64x64)
[File] 252f1eafed "image_4.png" (image/png) 189 B [252f1eafed] (commit 11d5fc50d2) MetadataImage(64x64)
[File] 5a525e9132 "image_5.png" (image/png) 234 B [5a525e9132] (commit 11d5fc50d2) MetadataImage(64x64)
[VNode] 99a52d6947 (5 entries)
[File] 711b0e12a4 "image_0.png" (image/png) 218 B [711b0e12a4] (commit 11d5fc50d2) MetadataImage(64x64)
[File] c2642f42b4 "image_1.png" (image/png) 153 B [c2642f42b4] (commit 11d5fc50d2) MetadataImage(64x64)
[File] 22efe3ef37 "image_3.png" (image/png) 235 B [22efe3ef37] (commit 11d5fc50d2) MetadataImage(64x64)
[File] c24022f687 "image_8.png" (image/png) 244 B [c24022f687] (commit 11d5fc50d2) MetadataImage(64x64)
[File] 2f70609673 "image_9.png" (image/png) 254 B [2f70609673] (commit 11d5fc50d2) MetadataImage(64x64)
[File] fc5fb77316 "images.csv" (text/plain) 384 B [fc5fb77316] (commit 11d5fc50d2) MetadataTabular(2x10) (2 fields) images: str, labels: str
Let’s first talk about how many VNodes get created. This depends on the VNode size and the number of children in a directory.
def num_vnodes(num_children, vnode_size):
return ceil(total_children / vnode_size)
num_children = 10 # number of files in the directory
vnode_size = 4 # configured per repo
print(num_vnodes(num_children, vnode_size))
# ceil(10/4) = 3
Given this computation, you’ll notice that the train directory above has 3 VNodes, each with 2, 3 and 5 entries. Just because VNodes have the same size, does not mean they are guaranteed to have the same number of children. This depends on how balanced your hashing function is and how many total children there are that can be divided into the VNode buckets. Now let’s talk about how the files get distributed into VNodes.
Splitting Directories Into VNodes
For any path, it is important that we can quickly traverse to a the file or directory given it’s name. Since all names should be unique within a directory, we simply hash the path, and then compute it’s bucket it is in based on the number of vnodes.
let path_hash: uint = hash(path) # Some unsigned integer like: 14314253324
let vnode_idx: uint = path_hash % num_vnodes # The bucket the node falls into
Once a file or directory has landed within a VNode, the nodes are then sorted to make traversing to the node fast given a path. All of the computation of splitting up VNodes and sorting them is locked in on commit. This is one of the reasons we implemented our own compact tree representation on disk that is optimized for reads, but still has fast bulk writes on commit.
Traversing the Tree
Let’s start from the top again and say we are given the file path images/train/image_3.png. How do we quickly find this in our tree? It is a constant time lookup to find any node on disk given it’s hash, because we have a hash map of hash → nodes. To help traversal, we also maintain a reverse lookup from directory name to hash on a per commit basis.
Commit A
"" -> 512200c70d
"images/" -> 40c8848f84
"images/train" -> 3b73dad90e
Commit B
"" -> 711b0e12a4
"images/" -> c2642f42b4
"images/train" -> 22efe3ef37
If there happens to be a 1-1 ratio of directories to files in a repository, this is not super efficient, but if there are many files per directory, it helps us quickly navigate to a directory node given a path. The full logic to go from a file path to a node is as follows:
# File search path
file_path = Path("images/train/image_3.png")
# image_3.png
base_name = file_path.basename()
# images/train
parent_path = file_path.parent()
# 3b73dad90e
parent_hash = lookup_directory_hash(parent_path)
# [Dir] 3b73dad90e "images/train" (2.2 KB) (10 files)
directory_node = lookup_dir_node(parent_hash)
# [File] 22efe3ef37 "image_3.png" (image/png)
# Binary search
file_node = lookup_file_node(directory_node, base_name)
Since we skip directly to the parent directory with a single hash, our lookup results in log(n) complexity, where n is the number of children in the VNode. The most expensive operation is the binary search through the final VNode, which has already been sorted on commit.
Faster Diffs
If you recall how we find differences in our Tree from Merkle Tree 101 we start at the root node, compare hashes, and only traverse further if the hashes do not match. The most expensive part came from scanning every file at the directory level. VNodes make it so there are more chances for early stopping, and limit the longest contiguous scans to the vnode_size.
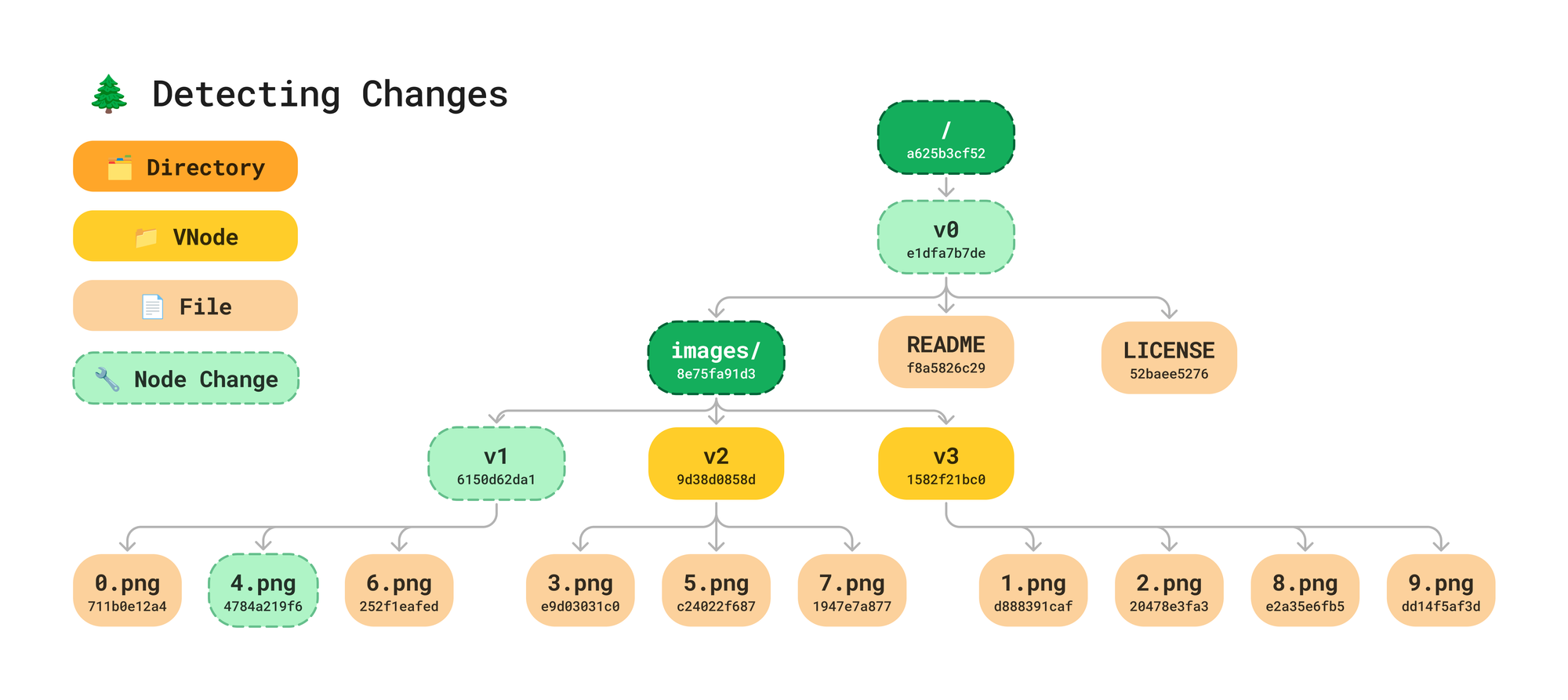
In the above example, since v2 and v3 hashes didn’t change, we do not need to traverse them and compare file hashes.
Conclusion
VNodes are a nice optimization within the Oxen Merkle Tree that speeds up tree traversal and makes it a bit more efficient on disk. We have found that 10k is a reasonable size for VNodes for most projects, but let us know if you do any experiments with other sizes.
Love the nitty gritty low level details of data structures and file systems? Feel free to checkout the open source project. Or even better… We are hiring! At Oxen.ai we believe that the more people that contribute to the data that powers AI, the more aligned it will be with us. We want to enable buttery smooth, easy to use, and fast workflows to help anyone contribute to large datasets and improve AI.
If this sounds like you, come apply to join the Oxen.ai Herd 🐂
Member discussion