
Oxen's Model Report - March 11th, 2026


Welcome back to another iteration of our favorite moooodel report. This week we've got an absolutely packed lineup, from motion-controlled video generation to open-weight language models you can run on your laptop (or phone if you're bold enough).
On Today's Models Menu:
- Kling Motion Control (Kuaishou) — Motion-controlled video generation
- GPT-5.4 (OpenAI) — Text, reasoning, and agentic workflows
- Qwen 3.5 (Alibaba) — Open-weight language models from 0.8B to 397B
- Qwen Image 2.0 (Alibaba) — Text-to-image with best-in-class text rendering
- LTX-2.3 (Lightricks) — Open-source video generation with native audio
Plus, we share with you the podcast the Oxen.ai team loved the most this week.
Let's dig in.
Kling 3.0 Pro: Motion Control
Kling's Motion Control lets you transfer human motion from a reference video onto a character image, think gestures, facial expressions, and body movement all mapped onto your subject. The latest 3.0 release introduced "Element Binding" for rock-solid facial consistency, even when faces are partially obscured or shots run long.
We tested this by feeding in a simple walking reference clip and an image of my all-time favorite US president Abraham Lincoln. The results are pretty crazy. The generated video maintained natural physics, fabric moved convincingly, Abe has the same walking cadence and overall movement. Top-notch quality. Output is up to 4K HDR at 30fps.
There is a downside though... It took 8 minutes per generation, which can get long pretty quick if you're running sequential generations to fight the AI-generation roll of the dice. Luckily on Oxen, you can run as many concurrent generations as you want to optimize for time and ensure you get several samples to choose from!
Reference Video
Result
Available now on Oxen for inference.
GPT-5.4 (OpenAI)
OpenAI dropped GPT-5.4 on March 5th with three variants: standard, Pro, and Thinking. Merging the coding chops of GPT-5.3-Codex into a general-purpose model, so you no longer need separate model lines for coding vs anything else.
The headline numbers: ~1M token context window (the largest from OpenAI), 33% fewer false claims vs. GPT-5.2, and awesome tool calling. The Thinking variant also lets you see its plan before execution and redirect it mid-response (Hmm, perfect for coding agents, what a coincidence).
For coding workflows, GPT-5.4 now powers OpenAI's Codex agent (their answer to Claude Code). Early reviews praise the code quality and more conversational voice (the lack of which was a big reason people preferred Anthropic models, even when OpenAI's were arguably better), but flag a recurring issue: it sometimes expands tasks well beyond what you asked for, or calls things done before they're actually finished. So watch out vibe coders, trust but verify.
The launch also came amid OpenAI's #QuitGPT controversy, with over 2.5 million users boycotting the platform after a Pentagon contract that Anthropic had publicly declined. (More about this on the podcast we'll recommend at the end of this article!)
Also Available now on Oxen for inference.
Qwen 3.5 (Alibaba)
Now onto our favorite kind of model: small and open source (there are also some big boys for those who like to put the VRAM to work). Alibaba's Qwen team released the 3.5 family ranging from a 397B MoE flagship down to tiny 0.8B models designed for on-device use. We've added fine-tuning support for the smaller dense models — 0.8B, 2B, 4B, and 9B — which are the ones most interesting for edge deployment, cost-efficient inference, and domain-specific fine-tuning.
The small models punch way above their weight. The 9B runs on an 8GB consumer GPU, with 262K native context extendable to ~1M via YaRN (a technique that tweaks how the model encodes position information, letting it generalize to much longer sequences with minimal extra training). People are already running the 2B on $300 Android phones and iPhone 17 Pros fully offline, one dev noted it outperforms Gemma3 4B on the same prompts. Unsloth even put out quantized versions you can run on your phone. All models are natively multimodal (text, images, and video from the same weights, not bolted on after training), support 201 languages, and are fully open-weight under Apache 2.0.
One thing to watch: the Qwen team is going through a leadership shake-up. Tech lead Lin Junyang, post-training head Yu Bowen, and coding lead Hui Binyuan have all departed in 2026, Lin resigned the day after shipping Qwen 3.5 small, just hours after Elon Musk publicly praised the release. The models are excellent, but the brain drain is worth keeping an eye on.
If you don't believe you can run these new Qwen3.5 small models on mobile devices, here is a demo. I got the 2B version running on a low-end Android device with Ollama. Its responses are much better than Gemma3 4B with the same prompts. https://t.co/rkgIrVoi4g
— David Hendrickson (@TeksEdge) March 2, 2026
Qwen releases 4 new Qwen3.5 Small models!
— Unsloth AI (@UnslothAI) March 2, 2026
Qwen3.5: 0.8B • 2B • 4B • 9B
Run Qwen3.5-0.8B, 2B and 4B on your phone. Run 9B on 6GB RAM.
The vision reasoning LLMs perform better than models 4x their size.
GGUFs: https://t.co/7Jmp13uYfU
Guide: https://t.co/wjS1lMnbNp https://t.co/nzysfXYrJU pic.twitter.com/tCSW4Ka4Zf
Smaller dense models available now on Oxen for fine tuning. MoE versions coming very soon 👀
Qwen Image 2.0 (Alibaba)
Qwen Image 2.0 is a (reportedly, but not confirmed) 7B parameter text-to-image model, down from 20B in the first version, yet better on every benchmark. It uses Qwen3-VL as its encoder, which means it understands conversational instructions rather than just keywords, with support for prompts up to 1,000 tokens. The real differentiator is text rendering: it handles both English and Chinese scripts with high accuracy, a historically painful area for diffusion models. We're talking legible signage, posters, even full infographic layouts generated directly from a prompt.
Generation and editing are unified into a single model now (no more separate editing pipeline), and it sits at #1 on AI Arena's ELO leaderboard for text-to-image. Weights aren't open-sourced yet for 2.0 (the original 1.0 is on HuggingFace), but it's available via API.
As an example we decided to use everybody's favorite AI savvy animal, Bloxy, and see how good it is at making it do certain (very specific) activities. One of our absolute favorite use cases and a bit of an internal Oxen AI benchmark.
As a fun first experiment we grabbed Qwen3-VL (which we've talked about a bunch) to get a description of Bloxy to pass into Qwen Image and see what it gets out the other end.
Not quite our Bloxy, he also has 6 legs for some reason 💀. (Not a great example as it is very difficult to prompt your way into character consistency, this is a great fine-tuning use case that we've explored in previous Fine-Tuning Fridays.)
Now for a more realistic one let's pass in our actual beloved Bloxy and asked Qwen Image to generate him as a podcast host to use as an image for this blog post.
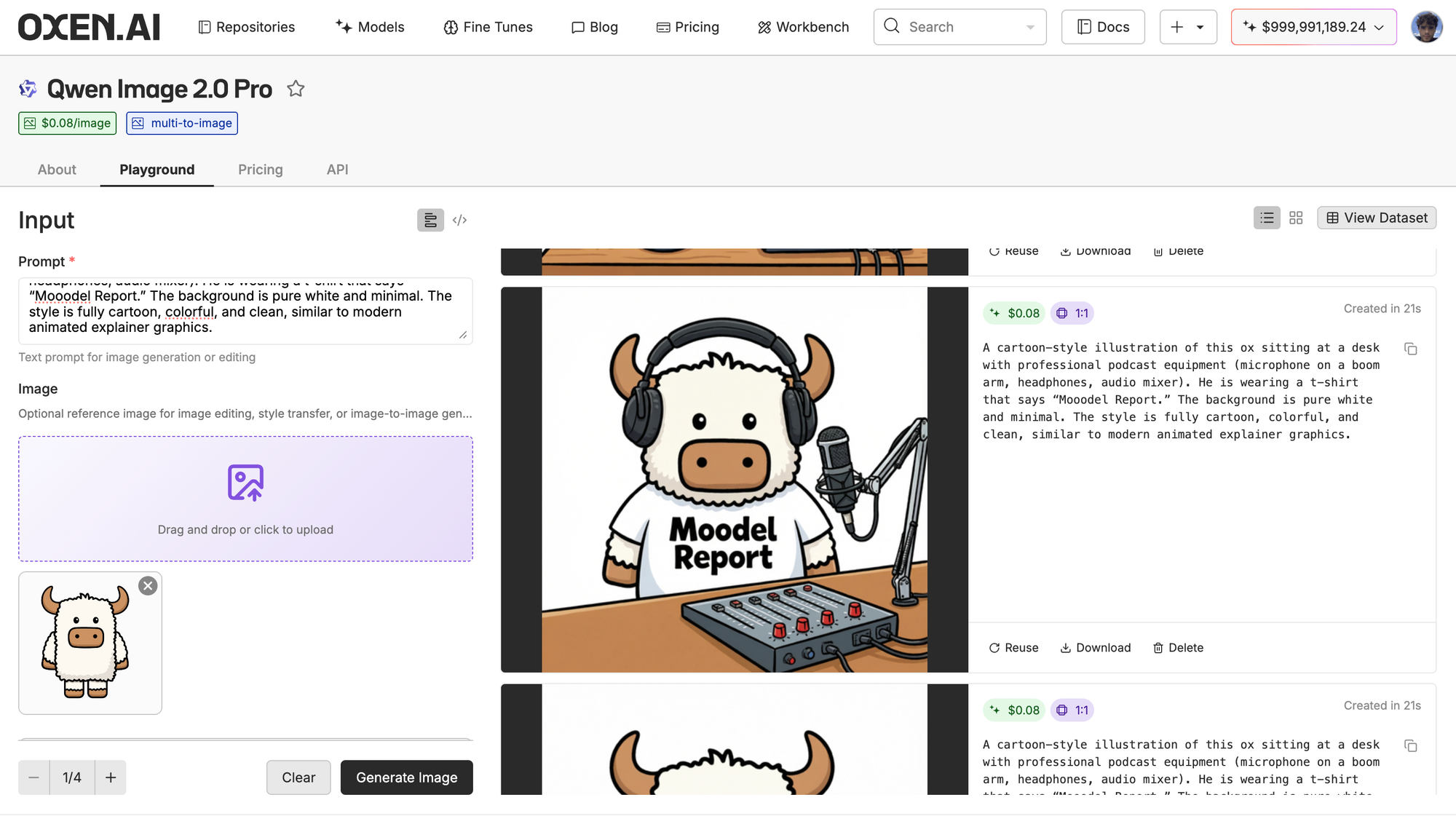
Leveraging Oxen.ai's playground to fend off the proverbial roll of the dice when generating media assets, we get a pretty interesting generation. Character consistency is great, text is perfect, overall a very quality generation (although his shirt is a little tight around the neck).
Available now on Oxen for inference.
LTX-2.3 (Lightricks)
LTX-2.3 is a 22B parameter open-source video generation model under Apache 2.0. It outputs up to 4K at 50fps with 6-20 second clips. and generates native audio alongside the video, not as a separate pass. When LTX-2 went open-weight back in January, it hit 4 million downloads in 6 weeks, making it the fastest-downloaded video model ever. 2.3 builds on that with a new VAE for sharper fine details, textures, and facial features.
From our internal tests we've seen great improvements on generations from fine tuned instances of this model. It looks like the lightricks team has made a huge effort to improve upon the insanely popular ltx 2.
What makes this one exciting for us is the full LoRA support, you can stack up to 3 LoRA adapters simultaneously for style, motion, and likeness, and training will be super fast to set up on Oxen (no code, no dependency wrangling, the usual). It also supports portrait-native 9:16 output (trained on portrait data, not just cropped landscape) and ships in both a full dev variant for fine-tuning and a distilled variant for faster inference.
Another aspect we love about this model is that it can run locally if you have the right GPU. With 32GB of VRAM on a 5090, you should be able to run the Comfy nodes comfortably. So you can fine-tune on Oxen, download the model weights to test locally on your own rig, and then use Oxen to run inference at scale, the best of both worlds!
Available on Oxen for inference, fine-tuning and custom deployments!
What We're Excited for
The fine-tuning story keeps getting better. LTX-2.3 joining the ranks of fine-tunable video models is a big deal, we're actively working on bringing that capability to Oxen and will share results as soon as it's ready. On the Qwen 3.5 side, having a fine-tunable multimodal model that can run on a phone opens up real use cases we couldn't touch before, private on-device assistants, offline field tools and edge automation that doesn't have to phone home (tune in to an upcoming Fine Tune Friday session to learn more about our exploration).
Speaking of fine-tuning: our next Fine-Tune Friday is this Thursday, March 13th. Matt Uhry is showing how he uses real footage with video generation models to create a beautiful short.
Oh, and keep an eye on DeepSeek. V4 is reportedly imminent, and if the leaks are to be believed, we're looking at a trillion-parameter MoE with native multimodal and a 1M token context window, all trained on Nvidia Blackwell chips (allegedly), we know there's bound to be some controversy there. It would be their first major release since R1 shook everything up about a year ago (which is like 10 years in AI). We'll have more on this one when it drops.
Podcast of the week
Matthew Berman x Dylan Patel
Just finished this Matthew Berman x Dylan Patel pod, an hour and a half so you don't have to block out 4 hours to listen to it (looking at you Lex). Super interesting conversation that covers lots of subjects, from OpenAI's and Anthropic's DoD controversy, Claude Code, state of open source models and the future of white collar work. Awesome and super timely.
No Bull, All Ox
Thanks for reading! We hope you found this useful. We'll be sending these out regularly to help you navigate this noisy AI world.
See you next time! Bloxy out.

Member discussion