
Oxen's Model Report - April 9th, 2026


Welcome back to another iteration of everybody’s favorite moooodel report. In AI, any given day feels like a decade, and the past couple of weeks have felt like a couple of centuries: open-weight language models, a few serious video generators, and one model doing the thankless but extremely important job of making your janky footage look less like it was recovered from your grandparents’ attic.
On Today's Models Menu:
- Gemma 4 (Google) — open-weight multimodal language models built to run surprisingly well on smaller hardware
- Qwen 3.6 (Alibaba) — a frontier-style long-context model with a big coding and agentic workflows angle
- Wan 2.7 — video generation with more control and better practical usability
- Seedance 2.0 (ByteDance) — multimodal video generation with text, image, audio, and video inputs
- Topaz Starlight Precise 2.5 — diffusion-based video enhancement and restoration
Come try them out in our brand new Workbench. Some of the best artists at the intersection of AI and Media (like Bruce Allen and Gary Tang) are already loving it!
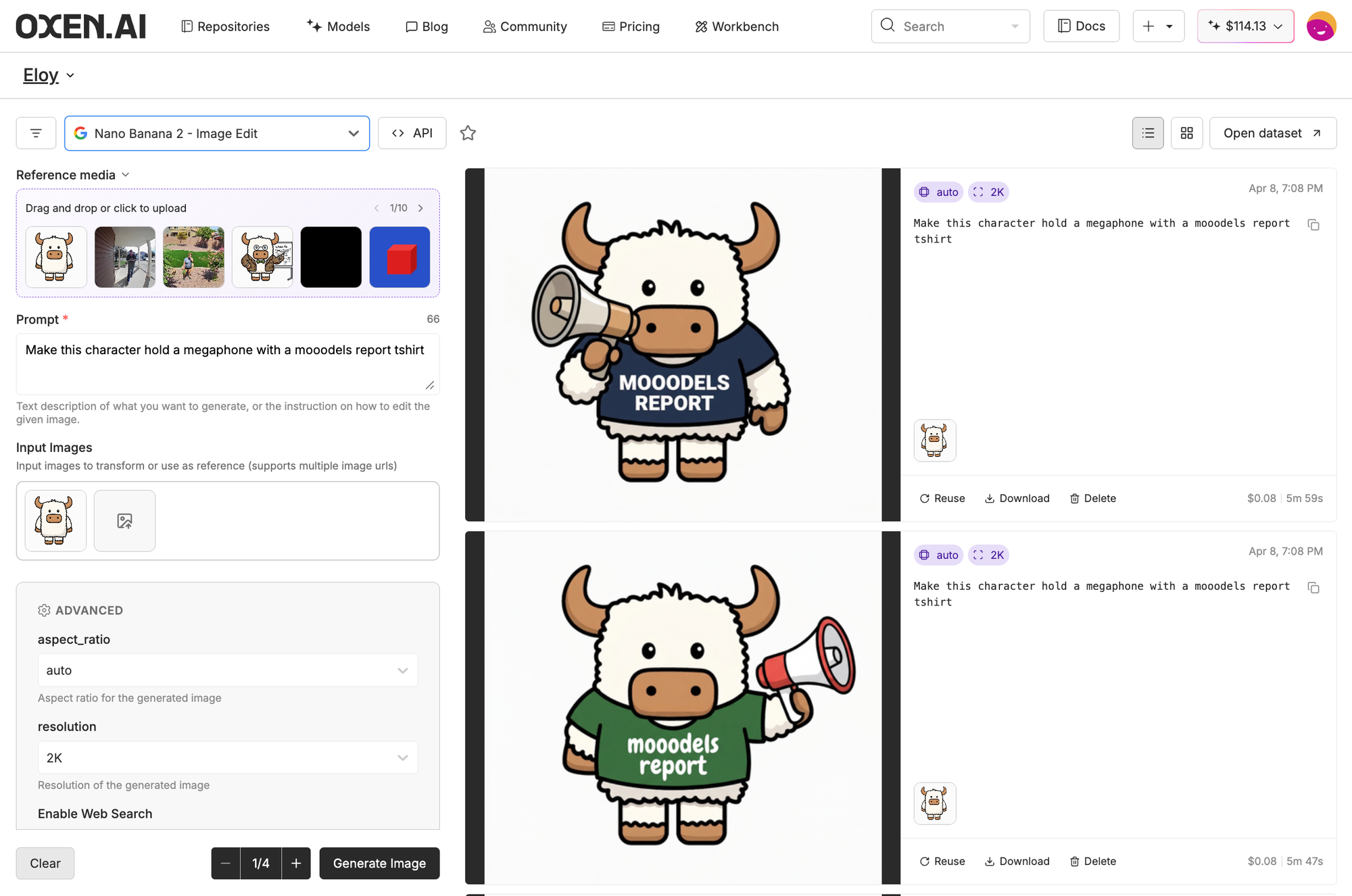
Plus, as always, we share with you the podcast the Oxen.ai team loved the most this week.
Let's dig in.
Gemma 4 (Google)
In past editions of this report, we’ve talked at length about open-source models and how valuable they are to the AI ecosystem. It’s also not exactly a secret that many of the strongest open-weight releases lately have not been coming out of the US. Models like Qwen, Kimi, and Wan have been setting the pace, while a lot of the usual domestic suspects, Llama, GPT-OSS, and others, haven’t felt nearly as competitive. That has turned into a real concern in AI circles: if open-source matters strategically, and it does, then the US falling behind in that race is a problem.
But as it often happens, Google comes out of nowhere with an answer to the question. That’s what Gemma 4 is supposed to be: Google’s bid for the most capable open-weight model family on the planet. And to be fair, they didn’t exactly whisper it. Even the Transformers PR that added Gemma 4 support was titled “casually dropping the most capable open weights on the planet,” which, credit where it’s due, is a pretty sweet title.
Gemma 4 backs up some of that confidence with a serious lineup: tiny edge-friendly models, larger dense models, and a 26B A4B MoE variant. Naturally, we wanted to compare it to the last big open-weight LLM drop we had on Oxen: Qwen 3.5.
The benchmark picture here is not totally clear-cut yet, mostly because there just are not that many clean head-to-head comparisons out in the wild. One of the better early breakdowns we found is this benchmark-by-size comparison, which paints a pretty balanced picture: Qwen 3.5 seems to have the edge on more of the smaller and mid-size official benchmark overlap, while Gemma 4 looks stronger in some of the larger assistant-style comparisons. In other words, this matchup looks a lot more even than the usual launch-day hype would suggest.
It’s also still early. More benchmarks will come out over time, and like with any model release, benchmarks should really be treated as a loose reference, not gospel. The best model for your workflow is still the one that actually works best for your use case. So try Gemma 4 for yourself on Oxen.ai, compare it against Qwen, and let us know what you find.
Important to note: Google did drop the ball a little bit with this release, it feels like they did not coordinate with the OSS community beforehand. Training and inference was not super straight-forward to setup and there are several open issues fixing very critical bugs. (Like use_cache=False corrupting attention computation).
Qwen 3.6 (Alibaba)
Qwen keeps doing this annoying thing where they release models that are impossible to ignore.
The model is pretty damn good. Based on the benchmarks around release, Qwen 3.6 Plus looks broadly on par with Claude Opus 4.5 for coding agents, long-context reasoning, and tool-heavy workflows. Slightly behind on SWE-bench Verified, slightly ahead on terminal operations and document understanding. And it comes in at roughly 10x cheaper on input tokens.
The timing is interesting too. Anthropic cut off Claude Pro/Max subscriptions from working through third-party agents like OpenClaw on April 4. Qwen 3.6 Plus dropped for free two days earlier. Users are already switching over and the "how to run OpenClaw with Qwen" tutorials are multiplying fast. If you haven't tried running OpenClaw with these newer models, it's worth poking around. We're making it dead simple through Oxen (tutorial coming soon).
Plot twist though: Qwen 3.6 weights are not open. This is the first model out after the brain drain scandal and the reports that Alibaba would lean harder into closed source. Seems like that was true.
Great news if you just want a strong model. Slightly more annoying news if what you really wanted was the weights.

Wan 2.7
This model is genuinely impressive. Wan 2.7 now does reference-to-video with voice cloning: feed it a photo and an audio clip, and it generates a video of that person speaking in that voice. It handles multiple subjects in a single scene, does instruction-based editing on existing footage, and ships with a "thinking mode" that plans composition before rendering. It's a full production suite, not just a text-to-video toy.
Yet Alibaba keeps breaking our hearts, Wan 2.7 is also closed source :(.
Versions 2.1 and 2.2 are still on HuggingFace, and for a while the Wan series was the default answer to "what's the best open video model." Then 2.5 came out with no weights. Then 2.6, same thing. Now 2.7, same thing again. There's a GitHub issue literally titled "Thank you Alibaba for deceiving and using the open source community" accusing them of using open weights as a marketing strategy to build adoption and then pulling the ladder once they had it. Bloomberg was more diplomatic but landed in the same place, calling Wan 2.7 Alibaba's "third closed-source AI model" in a piece about their pivot to profit.
But "impressive and closed" is a very different value proposition than what Alibaba was selling a year ago. Open weights built the community. The community is noticing they're gone (and we miss them, a lot).
Let's take a look at how we can make our beloved Bloxy fight his evil twin on a LA rooftop (we will compare this output to the next model on the list: the ultra controversial Seedance 2.0)
Prompt:
“Create a scene with two of these characters fighting on a Los Angeles rooftop. One of them must be wearing sunglasses. They should be engaged in a kung-fu–style duel, facing each other while punching and blocking. The camera movement should feel cinematic and Hollywood-style.”
I passed in an image of Bloxy as reference.
The style is pretty cool, very opinionated. The audio is straight up hilarious.
Very nice result! let's see how it compares
Seedance 2.0 (ByteDance)
Seedance 2.0 is the model that caused an international incident before most people even got to use it. Back in February, Irish filmmaker Ruairi Robinson (shoutout Ruairi, avid Oxen user, you're the best) typed a two-line prompt and generated a hyper-realistic rooftop fistfight between Tom Cruise and Brad Pitt. It went wildly viral. Within 24 hours, the MPA called it "unauthorized use of U.S. copyrighted works on a massive scale," SAG-AFTRA condemned it as "blatant infringement," Disney and Paramount sent cease-and-desist letters, two US senators wrote ByteDance demanding they shut it down, and ByteDance halted the global rollout entirely.
That was February. As of today, Seedance 2.0 just publicly released its API, and we got early access. We're already serving it through Oxen.
The model itself is legitimately one of the best video generators we've tested. Multimodal inputs (text, image, audio, video), an omni-reference system that gives you real control over how reference images appear in the scene, and native audio-video joint generation. The quality ceiling is high.
But ByteDance clearly got spooked. The guardrails are aggressive now. Real faces get blocked. Prompts that even vaguely gesture at copyrighted material get flagged. We're seeing a lot of failed requests from artists running into filters that feel like they were calibrated by a legal team, not a product team. They bulletproofed the workflow, and it shows.
The interesting side effect: Wan 2.7 is a lot more lenient. We've been taking prompts that Seedance rejects and running them through Wan, and getting decent results. If you're hitting walls using this model, it's worth trying the same prompt on Wan through Oxen and seeing what comes back.
Let's see how black belt bloxy looks now:
Super smooth, movement is great, sound is great, LA is great (I would know, I've been living there for three weeks now). Amazing model. If you've been following this space for even a little while, you'll be as amazed as we are at how fast these models are improving. Come try it out on Oxen.ai
Topaz Starlight Precise
You know that movie scene where someone yells "ENHANCE" at the poor IT guy, and somehow the darkest, blurriest CCTV footage on earth turns into a crisp IMAX-ready shot. That is not how the real world works. But Topaz just made Starlight Precise 2.5 publicly available, and it gets closer to that fantasy than anything we've tested.
This is a diffusion-based video enhancement and restoration model, but here's what makes it interesting: it's the same core diffusion technology that powers video generators like Seedance and Wan, except pointed in the opposite direction. Instead of creating new footage, it hallucinates plausible detail into your existing footage. It's not just interpolating pixels, it's dreaming in realistic texture that makes the output look native rather than stretched. Feed it dark, noisy, grainy video and it cleans it up. No prompts, no reference images, no sliders. You give it footage, it gives you better footage. That's the whole UX.
And yes, coming right after two video generation models is not a coincidence. We're not saying your generations need upscaling, but if they ever do, this is what you want. Precise 2.5 was specifically tuned to reduce that "plastic" artificial look that AI-generated video still tends to have. So you can chain it right after your Seedance or Wan pipeline and get output that looks noticeably less obviously AI.
This is our favorite kind of model to evaluate, because you don't need a benchmark to understand how good it is. You just look at the before and after. The kind of thing where you show someone the comparison and they immediately ask how to use it.
Not every model needs to be a frontier reasoning engine or a video generator that accidentally triggers an international copyright dispute. Sometimes the most useful thing is the one that does the thankless job of making your janky footage look like it wasn't recovered from your grandparents' attic.
We ran it on real security camera footage and the result is pretty awesome. Not quite enough to make Horatio Caine say "YEAAAAAAAAAAAAHHHH",but very good nonetheless.
Podcast of the week
Andreessen x Latent Space
Just finished this one. Marc Andreessen on Latent Space, fresh off raising a $15B fund, calling OpenClaw + Pi "one of the 10 most important software things, probably ever." Bold claim, but his reasoning is solid: the architecture is just an LLM sitting on top of a shell, reading and writing files, running on a cron loop. It's Unix philosophy applied to agents, and the stuff people are building with it is genuinely wild. The pod covers a ton: why AI is an "80-year overnight success," why old NVIDIA chips are somehow appreciating in value, why inference costs might actually go up before they come down, and why bot detection is now a fundamentally unsolvable problem. He also drops that friends of his are spending $1,000 a day on OpenClaw compute (anybody know who these friends are? would love to get them on Oxen)
No Bull, All Ox
Thanks for reading! We hope you found this useful. We'll be sending these out regularly to help you navigate this noisy AI world.

Member discussion