Home
Docs
Sign up
Sign in
Subscribe
Practical ML
How to Set Noise Timesteps When Fine-Tuning Diffusion Models for Image Generation
Training a Rust 1.5B Coder LM with Reinforcement Learning (GRPO)
🧠 GRPO VRAM Requirements For the GPU Poor
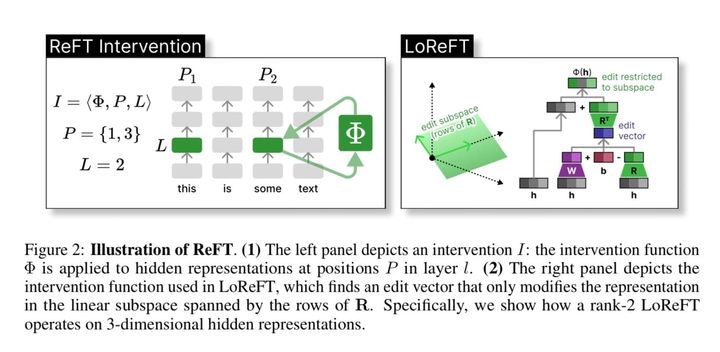
ArXiv Dives: How ReFT works
How to Train Diffusion for Text from Scratch
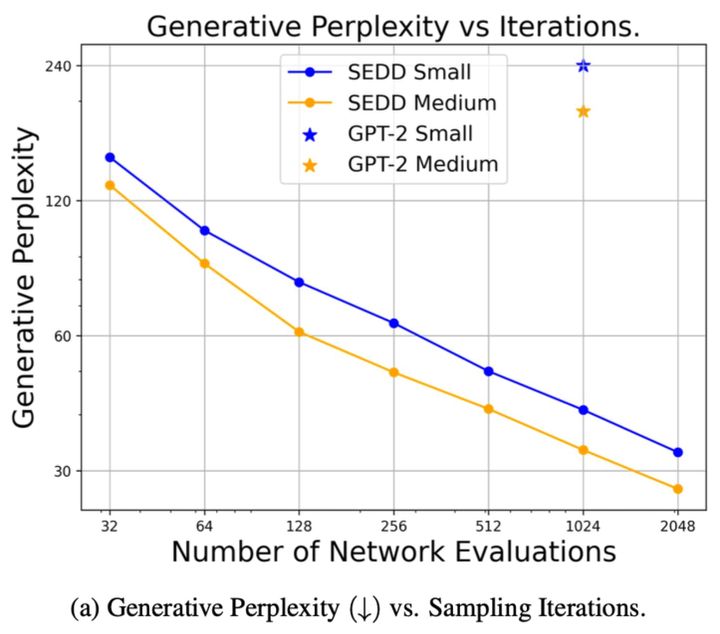
ArXiv Dives: Text Diffusion with SEDD