
The Best AI Data Version Control Tools [2025]

![The Best AI Data Version Control Tools [2025]](/content/images/size/w960/2024/12/ox-carrying-data.jpg)
Data is often seen as static. It's common to just dump your data into S3 buckets in tarballs or upload to Hugging Face and leave it at that. Yet nowadays, data needs to evolve and improve faster than AI models. Cutting edge AI models like Llama 3.1 saw dramatic performance improvements with similar model architectures to older releases by primarily iterating on and improving their data. The author of “Deep Learning with Python” and creator of the ARC-AGI benchmark goes as far as stating,
Spending more effort and money on data collection almost always yields a much greater return on investment than spending the same on developing a better model. — François Chollet
So why aren't more people focusing on data? Well, for one thing, it's not as glamorous as looking for the next amazing model. But mainly working and collaborating on data has always been an absolute headache due to the lack of good tools for making quality datasets. From lack of visibility to difficulty sharing large files, this kind of friction in every aspect of data handling is no longer acceptable in the world of AI.
Now, you may have thought, "Doesn't Git LFS already exist?" or "What's wrong with just dumping my data into Hugging Face?" While legacy options like Git LFS are available, serious problems start arising the moment your file is anything over 2 GB and you want to make any kind of updates to the data. Not only does Git LFS charge you if you go over 1 GB of storage, but AI datasets tend to be large and even moving relatively small datasets for AI/ML jobs can take excessive amounts of time. Pushing an update to a large dataset can take hours, and sometimes the push will not even go through. This can be seen in the results of our experiments below. As for Hugging Face, while it is easy to host data on their platform, they are optimized for creating and sharing AI/ML models, not collaborating, exploring, and iterating on the data. Thus, we decided to build a tool to help accelerate your data work.
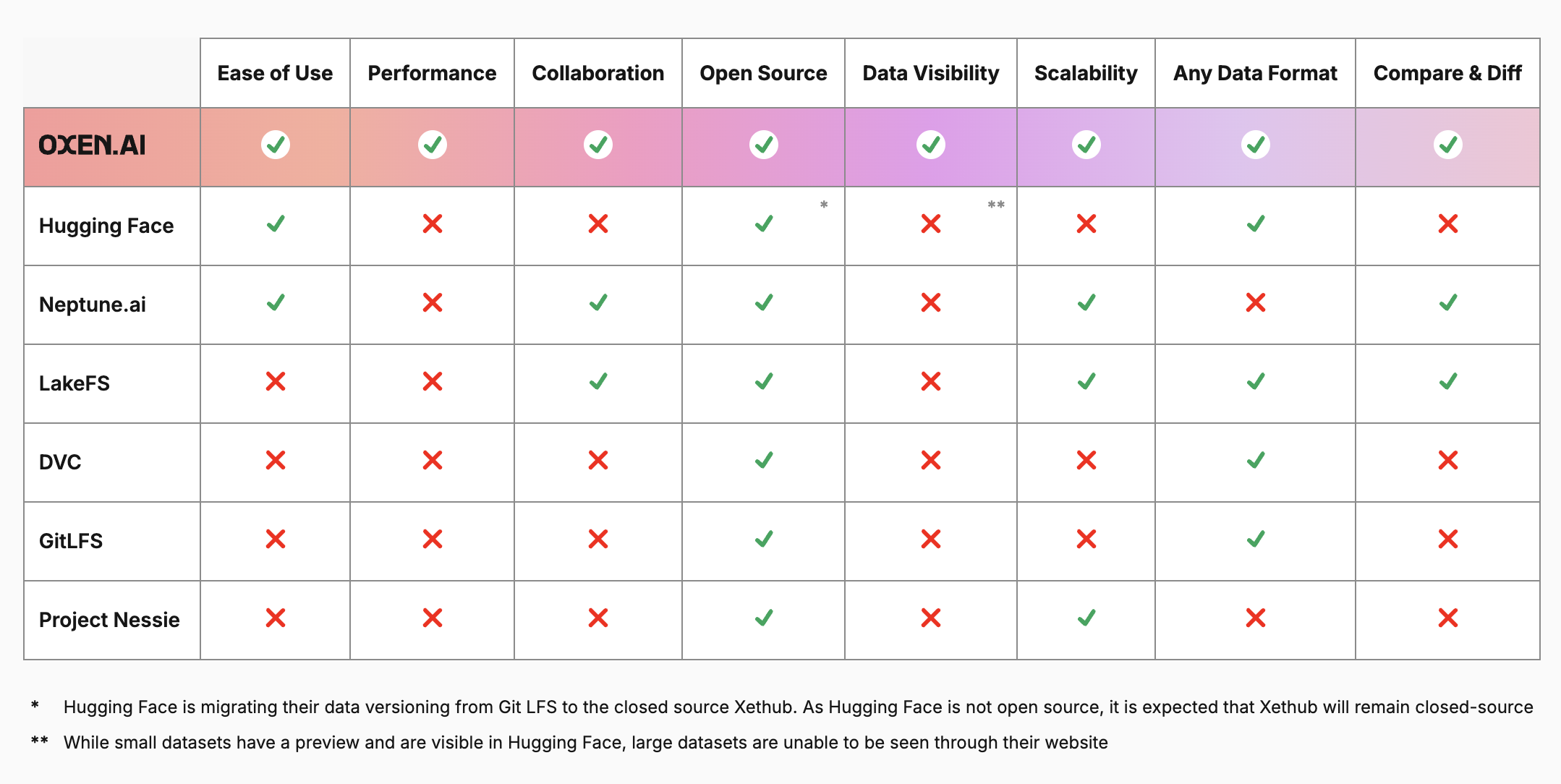
Best AI Data Version Control Tools for 2025
There are many factors to consider, so we made a graphic to help summarize the best options for data version control on the market:
Additionally, speed is a major concern, especially when working with larger datasets or larger teams, so we ran a speed test for performing a push of the popular ImageNet dataset:
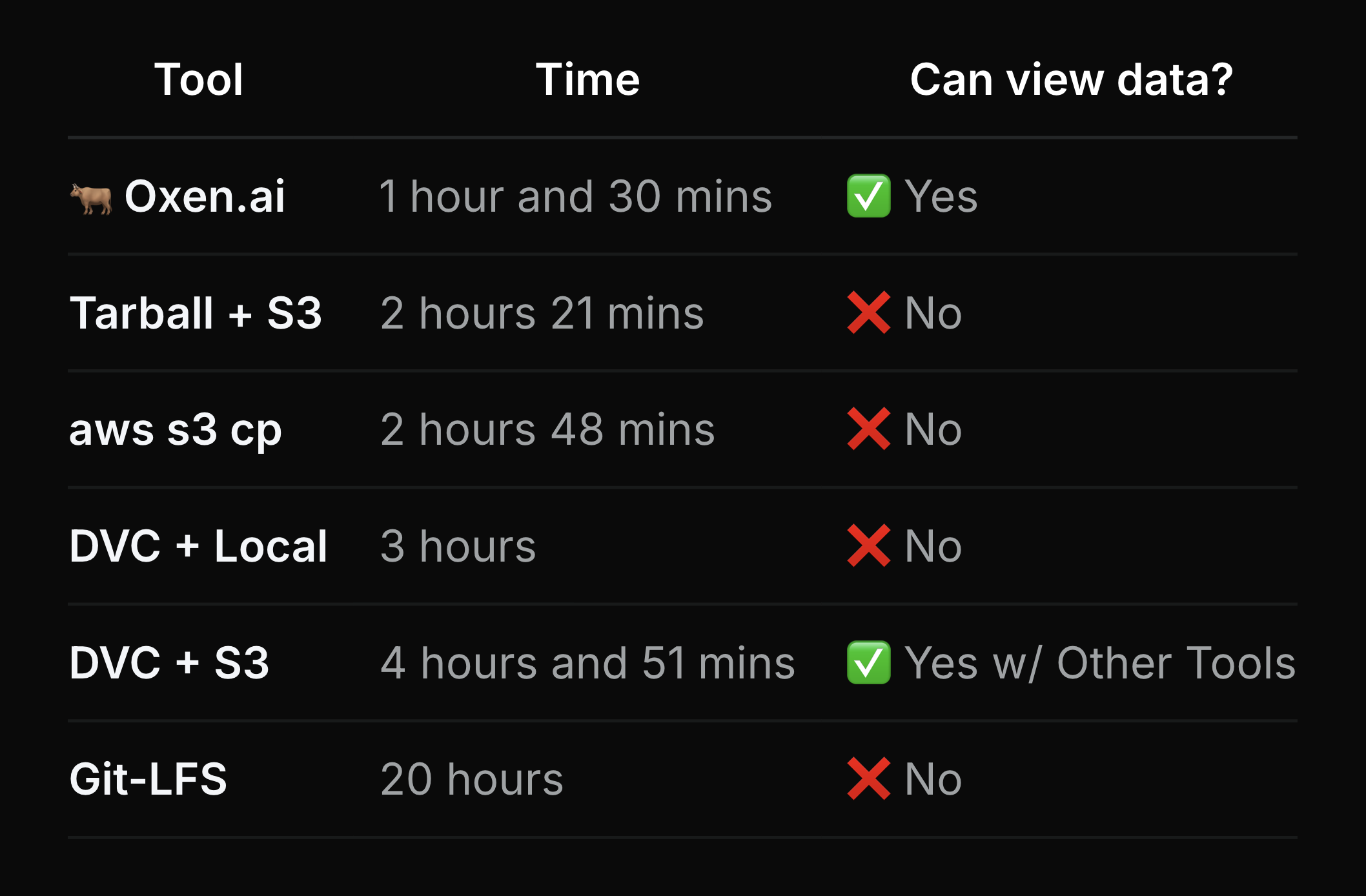
As you can see, there was a huge variation in the speed of the various tools. This is extremely important when you consider that such waits could hold up projects, or worse, drastically increase cloud GPU spending.
Let's take a closer look at each option.
Oxen.AI
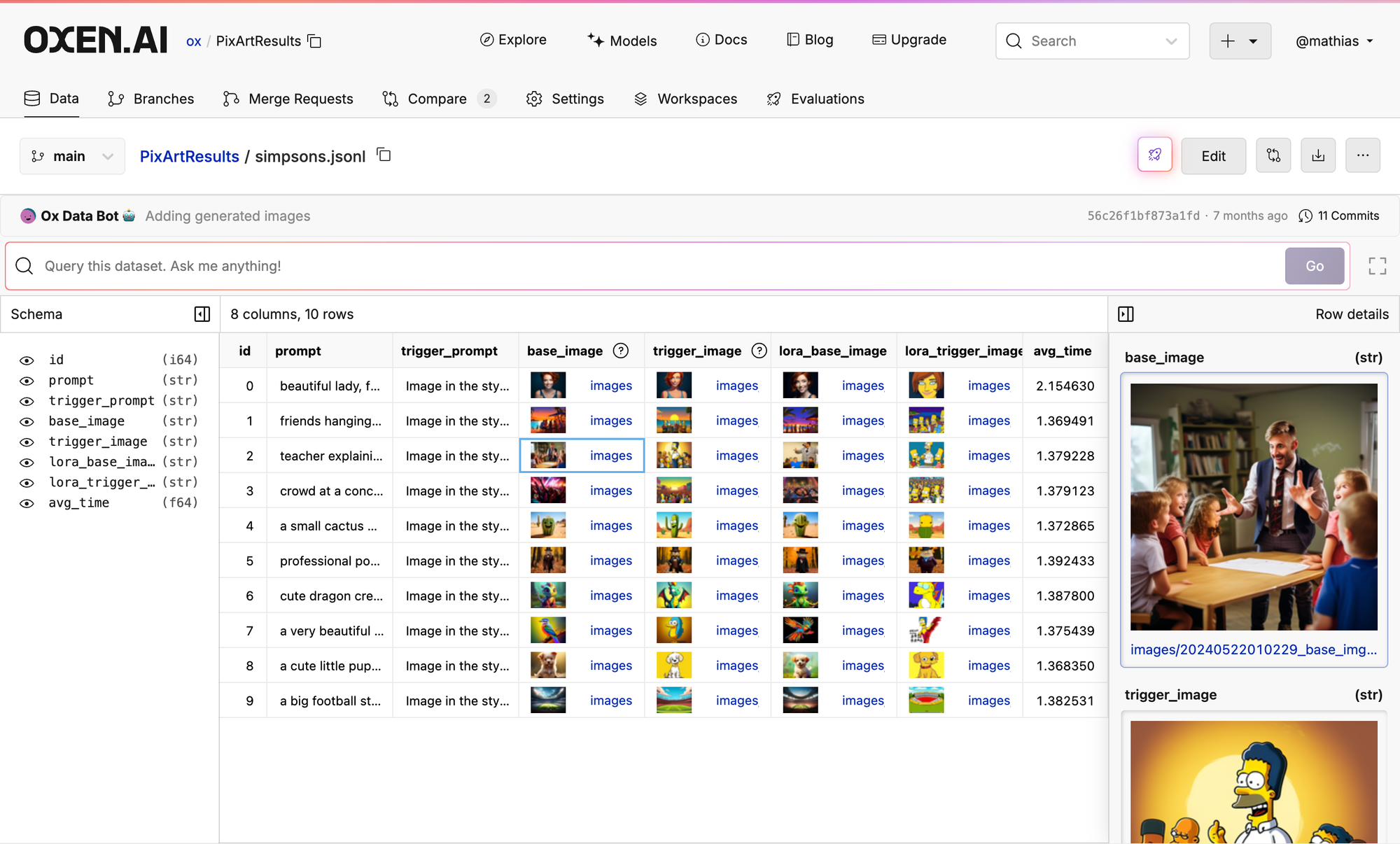
Oxen.ai is an open-source, data versioning tool optimized for machine learning datasets. Built from the ground up, Oxen.ai's command tooling mirrors Git and is the best-performing tool when compared to the most popular solutions (tarballs, AWS, DVC, and Git-LFS) for large datasets.
No matter how large your dataset is, you will always be able to view your data on the Oxen Hub including rendered images. For example, here is the 10,969 page of the ImageNet dataset:
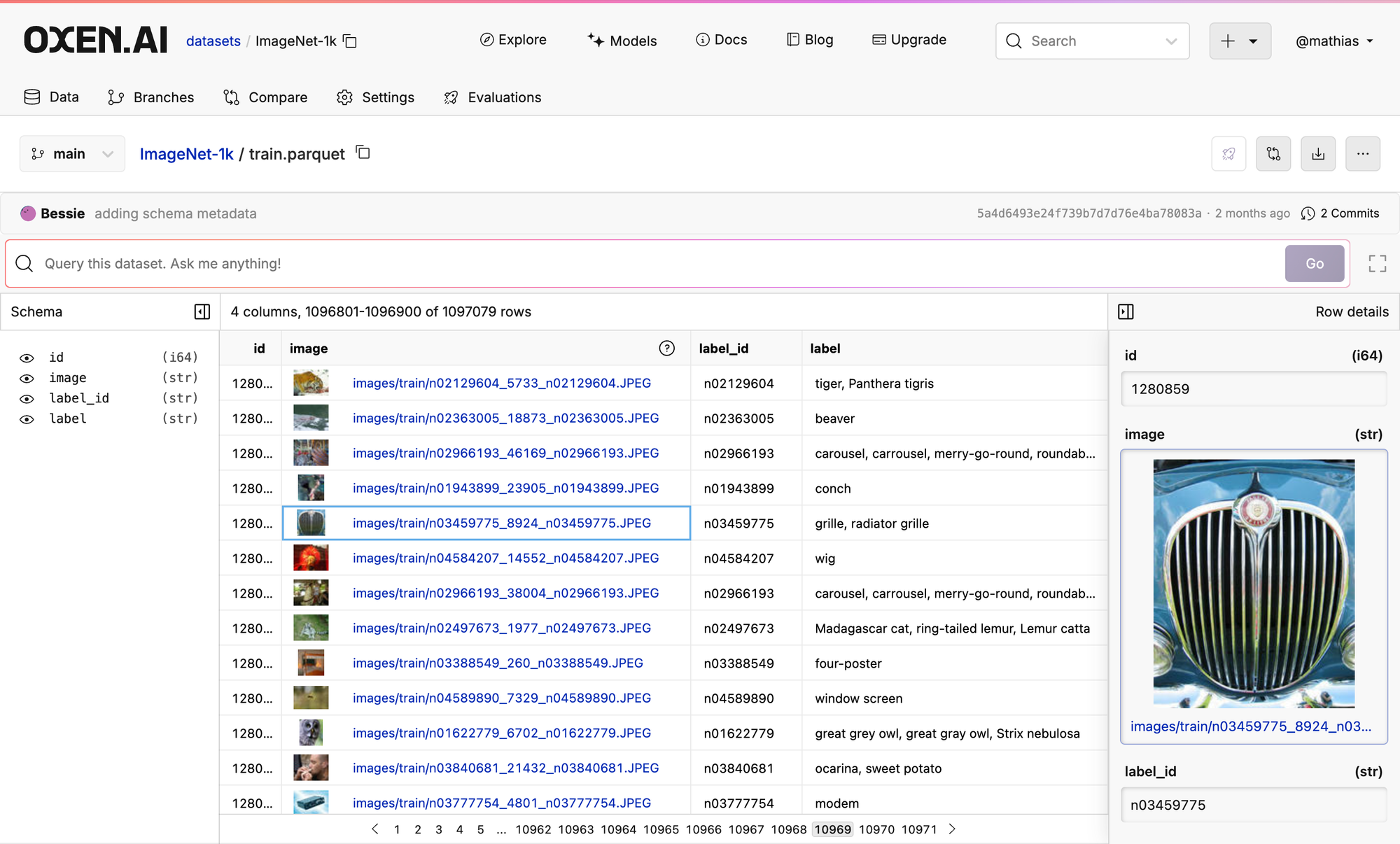
If you'd like, check out the data for yourself!
Not only is Oxen the fastest by far, but we are currently rolling out several data exploration features such as one-click Model Inference, UI Editable Dataframes, and Nearest Neighbors Search. We are focused on make the easiest collaborative tool for data versioning and exploration, so just by adding a friends username, you will be able to share the data and make changes together.

Hugging Face

In August 2024, Hugging Face acquired XetHub to replace Git LFS as their backend for data version control. At the time of writing this blog (Dec. 2024), Hugging Face has not implemented XetHub in their backend as they are still rearchitecting. XetHub was a closed-source data version tool for ML data and models. It had compact storage by using Merkle trees and content-defined chunking to deduplicate against the history so small changes to large files did not need to take up unnecessary storage. Engineering teams could use common tools such as Python and CLI commands modeled after Git and S3. So far, because Hugging Face is still using Git LFS, the push times are still slow and you aren't able to compare versions of your data, see large datasets in the UI, and collaborate easily. They emphasize distribution, not collaboration.
After HF completes the transition, it is likely that the XetHub backend will remain closed-source.
Neptune.AI
Neptune.ai is an open-source event tracker specifically for training foundation models. The platform is focused on visibility into model results and tracking model metrics, not on data exploration and versioning. This a great tool for metric visualization and tracking, but, as Neptune said themselves, it is a bit lightweight for data versioning and exploration with limited tooling for if you want to dig into your data:
When it comes to data versioning, Neptune is a very lightweight solution... That said, it may not give you everything you need data-versioning-wise. - Jakub Czakon (CMO neptune.ai)
LakeFS
LakeFS is a scalable, open-source data versioning tool that uses Git-like semantics. While it can support petabytes of data in any data format and integrates with third-party frameworks like Dagster, Airbyte, and Dataloop, a disadvantage of using LakeFS is that you have to handle file storage yourself, it can only render certain data formats in their website, and their UI is a bit tricky to explore. Lakefs supports any data format and stores your data on object storage that has a S3 interface such as AWS S3, Azure Blob Storage, and Google Cloud Storage.
Project Nessie
Project Nessie is an open-source option that also mirrors Git and only supports management of Apache Iceberg formatted data. It allows data engineers to change, manage, and correct datasets but does not allow visibility into your data. Since it is using its proprietary catalog, Nessie is limited when integrating with other catalogs using DataBricks Unity, HMS, or Tabular.
DVC
DVC is another open-source option that relies on the Git architecture. It offers visualization and comparisons of your data using metrics, plots, and images. While it works with all major cloud platforms, DVC's real limitation is performance. Once the files get larger or more numerous (for example, what you would expect from even a moderately sized image dataset), which is common for ML/AI experiments, it is much, much slower. As shown above and here, when benchmarked on the popular ImageNet dataset, it took DVC 3 hours with a local machine and almost 5 hours with S3 buckets. As you start iterating on AI/ML datasets to improve model performance, this becomes extremely costly.
Git LFS
GitLFS is an open source platform that builds off of Git. While it does have the same commands and the simple design of Git, where it lacks is its performance. While Git LFS does store large files in its storage, you will need to pay for anything over 1 GB. Moreover, it is not optimized and thus has poor performance and speed. For the ImageNet dataset, it took Git LFS 20 hours. On top of performance, you will often need to set up your own server which is tedious, buggy, and very slow.
Conclusion
Picking the right AI data version control is an important decision that only become more crucial the more AI models you need to train. As data grows in importance, size, and format, you will not only need an effective versioning tool, but an easy way to look into your data, share it, and edit it.
Our mission at Oxen.ai is to empower anyone who wants to contribute to the development of artificial intelligence. At the end of the day, AI models are only as good as the data you feed them.
If you’d like a tour of Oxen.ai, email me, dm me in our AI community, or book some time I’d love to show you around the farm.
Member discussion