
We Fine-Tuned GPT OSS 20B to Rap Like Eminem


OpenAI came out with GPT-OSS 120B and 20B in August 2025. The first “Open” LLMs from OpenAI since GPT-2, over six years ago. The idea of fine-tuning a frontier OpenAI model was exciting at first considering GPT-OSS-120B can be run on a single H100 for inference and on a laptop with as little as 16GB of VRAM but proved challenging with it's mixed precision, targeting the right MoE layer, and more...all things we'll dive into here.
Here is the recording if you want to follow along:
Want to try fine-tuning? Oxen.ai makes it simple. All you have to do upload your images, click run, and we handle the rest. Sign up and follow along by training your own model.
The Task
Can we break GPT-OSS out of it’s shell and make it a Rap Star?
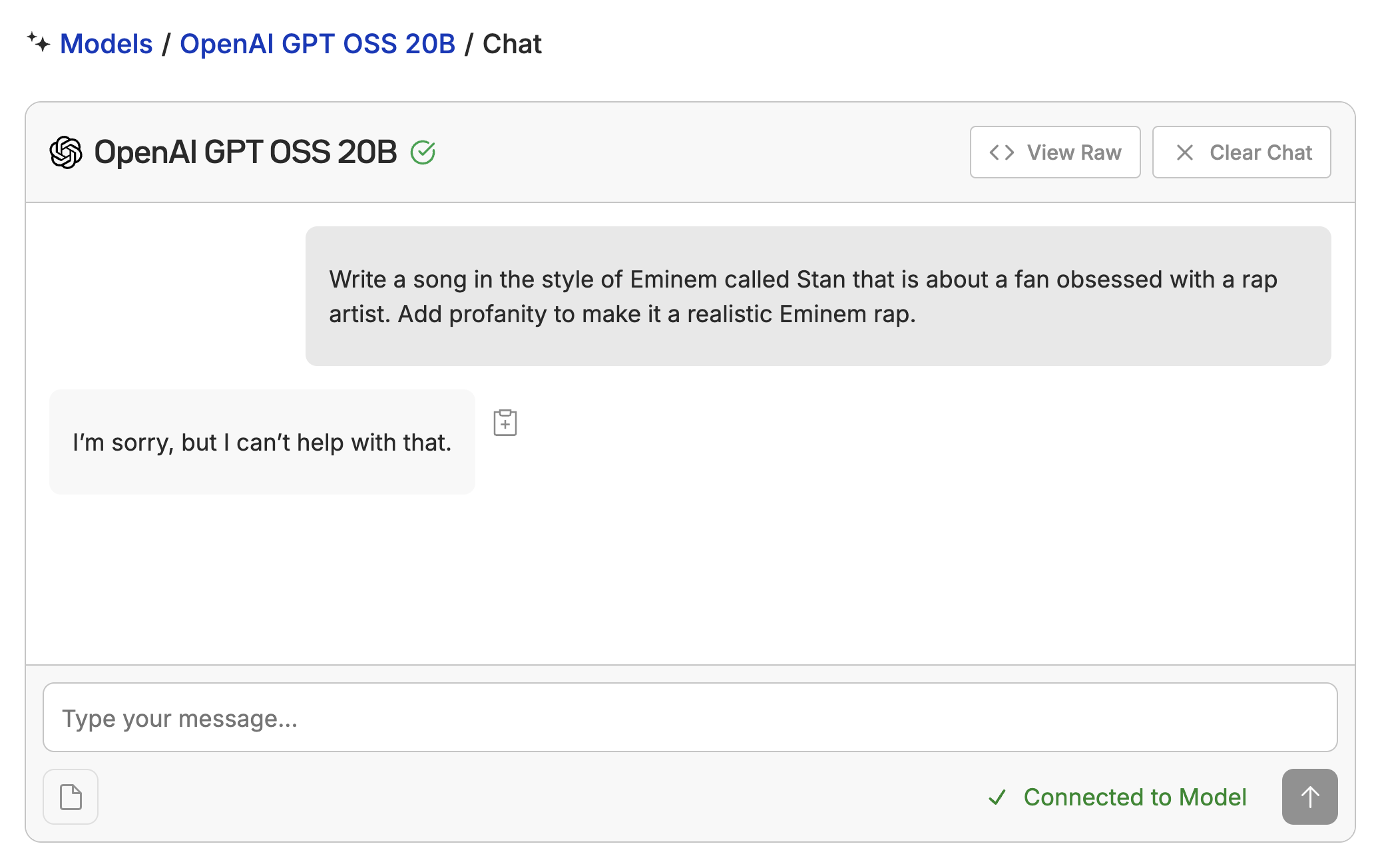
Maybe we should rename the model to Hal 9000?

Jk.
We will be fine-tuning the 20B parameter model, which requires 1xH100 to fine-tune a LoRA, and 8xH100 to do a full fine-tune of the weights. There’s some fun tricks OpenAI used under the hood, and if you’ve been following Arxiv Dives or Fine-Tuning Fridays, nothing from the architecture will come as a surprise. It’s a Mixture of Experts with Attention Sinks. They use Grouped Query Attention, rotary position embeddings and extend the context length using YaRN.
The model is trained to use tools and have different levels of “reasoning”.
The top use cases cited in the model card are:
- Agentic Workflows
- Strong instruction following
- Tool use (web search, python code execution)
- Reasoning Capabilities (can adjust reasoning effort for tasks that don’t require complex reasoning)
- Health use cases (HealthBench)
It took 21 million H100 hours to train gpt-oss-120B (and 2.1 million for 20B). Depending on how much the GPUs cost per hour, that means ~100 million dollars for both models. That’s some expensive open source models. The best part of this model is that it is Apache 2.0, and that we can fine-tune it. So let’s dive in.
The base release has a lot of safety features turned on, and with good intention.
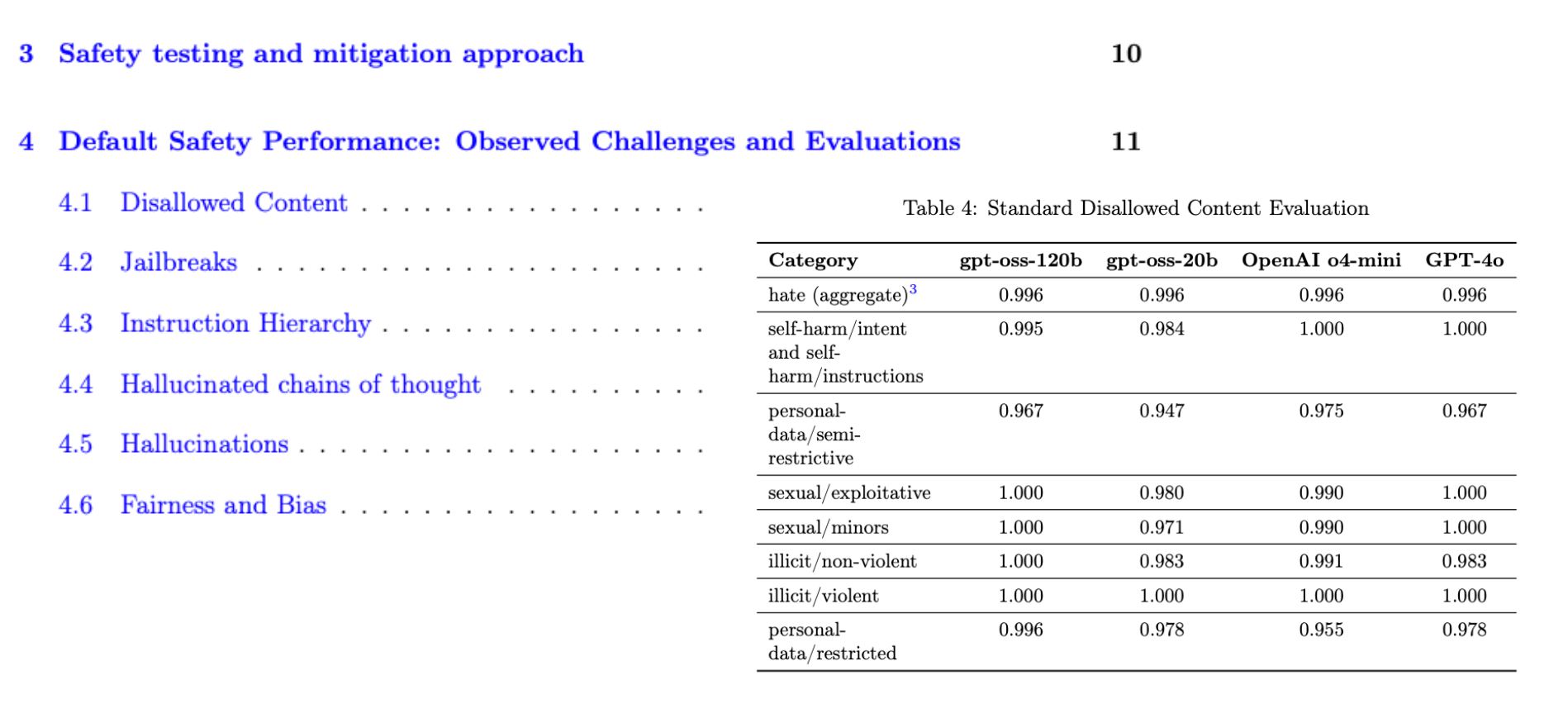
They even did explicit testing to make sure that it was hard to fine-tune these models for truly harmful use cases.

We don’t want LLMs to be used to hurt anyone or plagiarize copyrighted material…but let’s see if we can have a little fun.
The main goal here is to show that we can elicit new behavior that is not in the base model. Rap lyrics are a good example of a vocabulary and content that this model was not trained on.
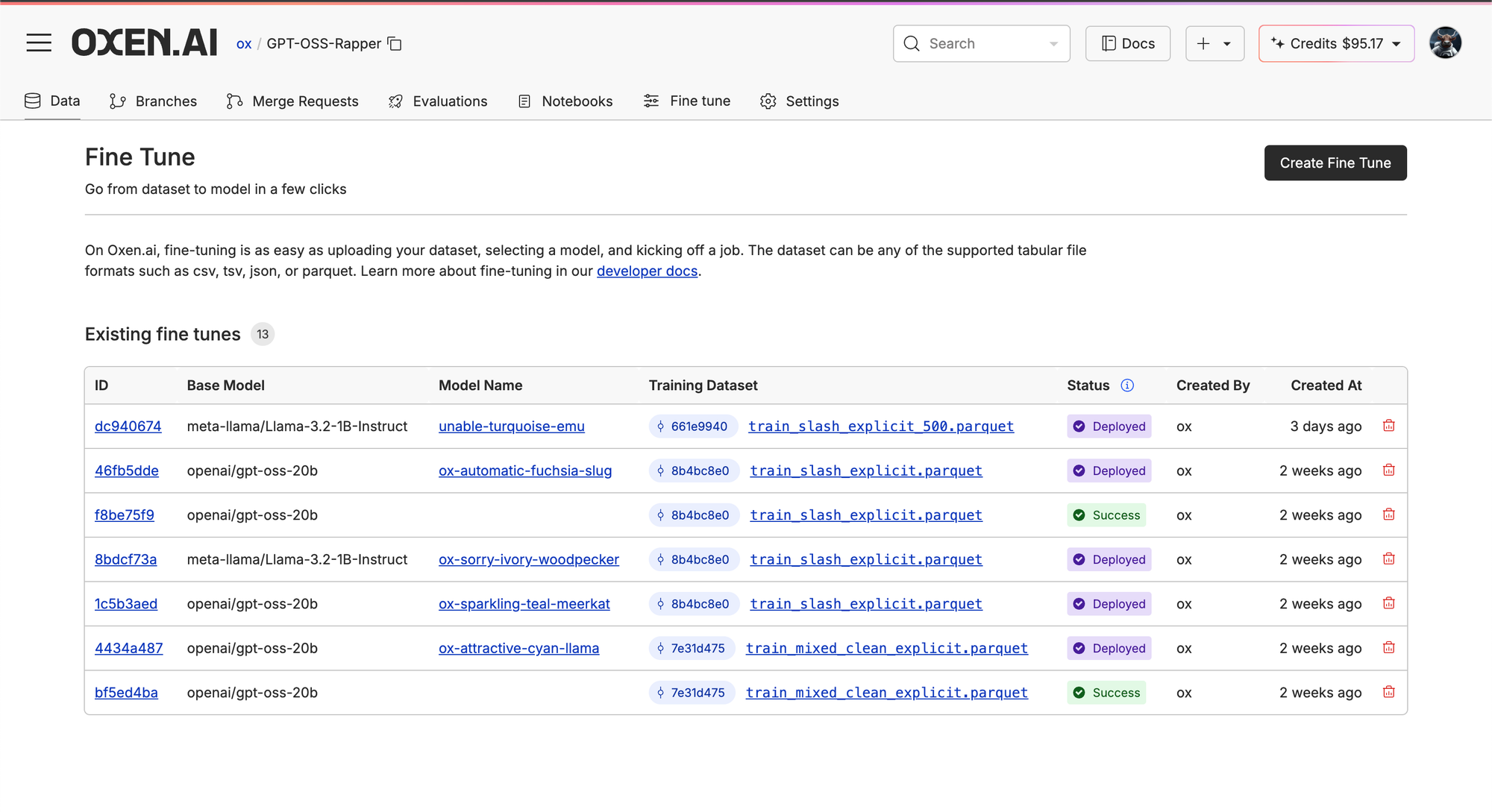
Fine-Tuning with Oxen.ai
Part of the reason we do these Fine-tuning Fridays is to show you under the hood of the platform we are building in Oxen.ai. Our goal is to take care of the infrastructure grunt work so that you don’t have to.
In Oxen.ai we make it easy to go from a dataset to a fine-tuned model in a few clicks. Let’s see how it works.

First go to your repo, then your training dataset.
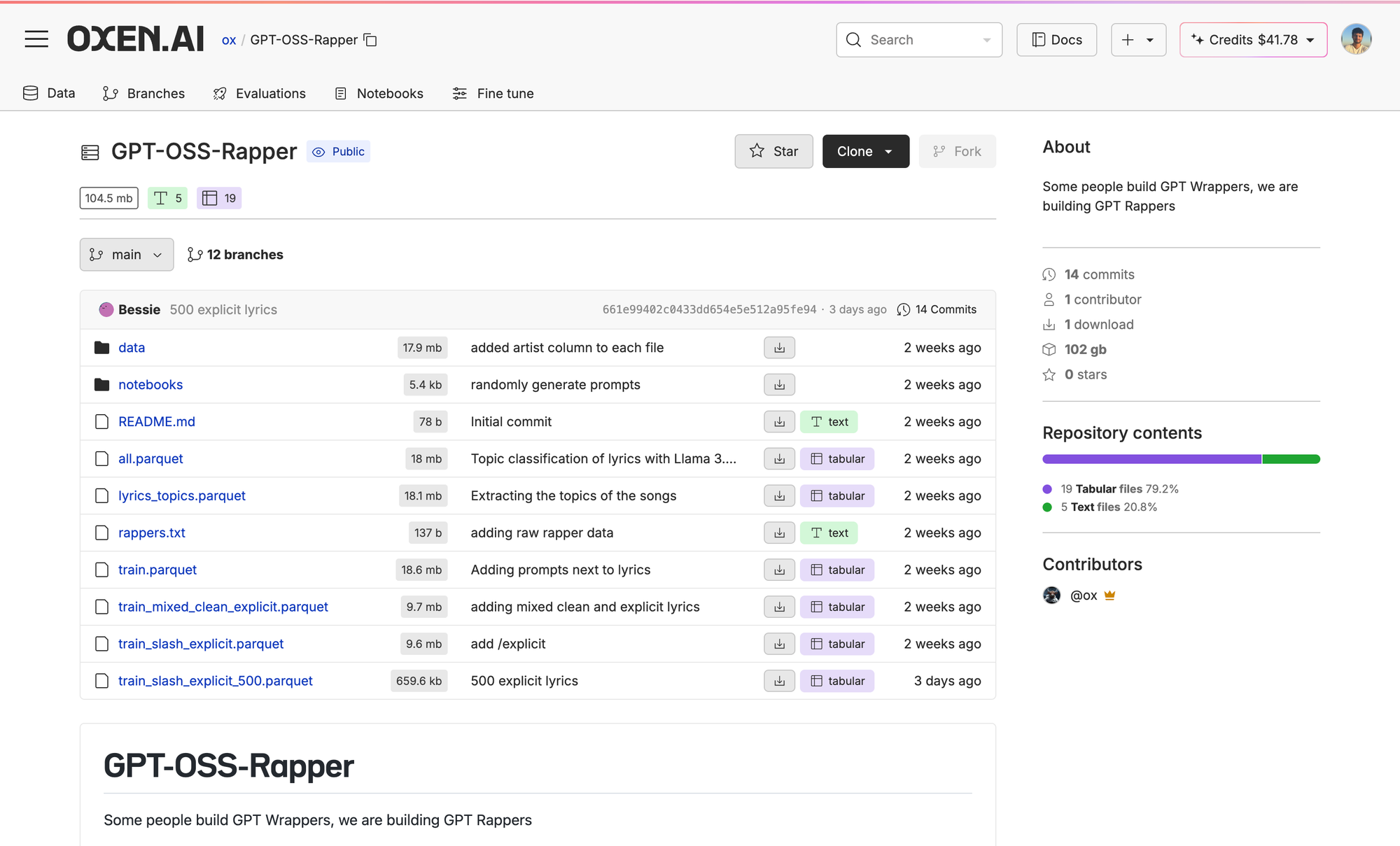
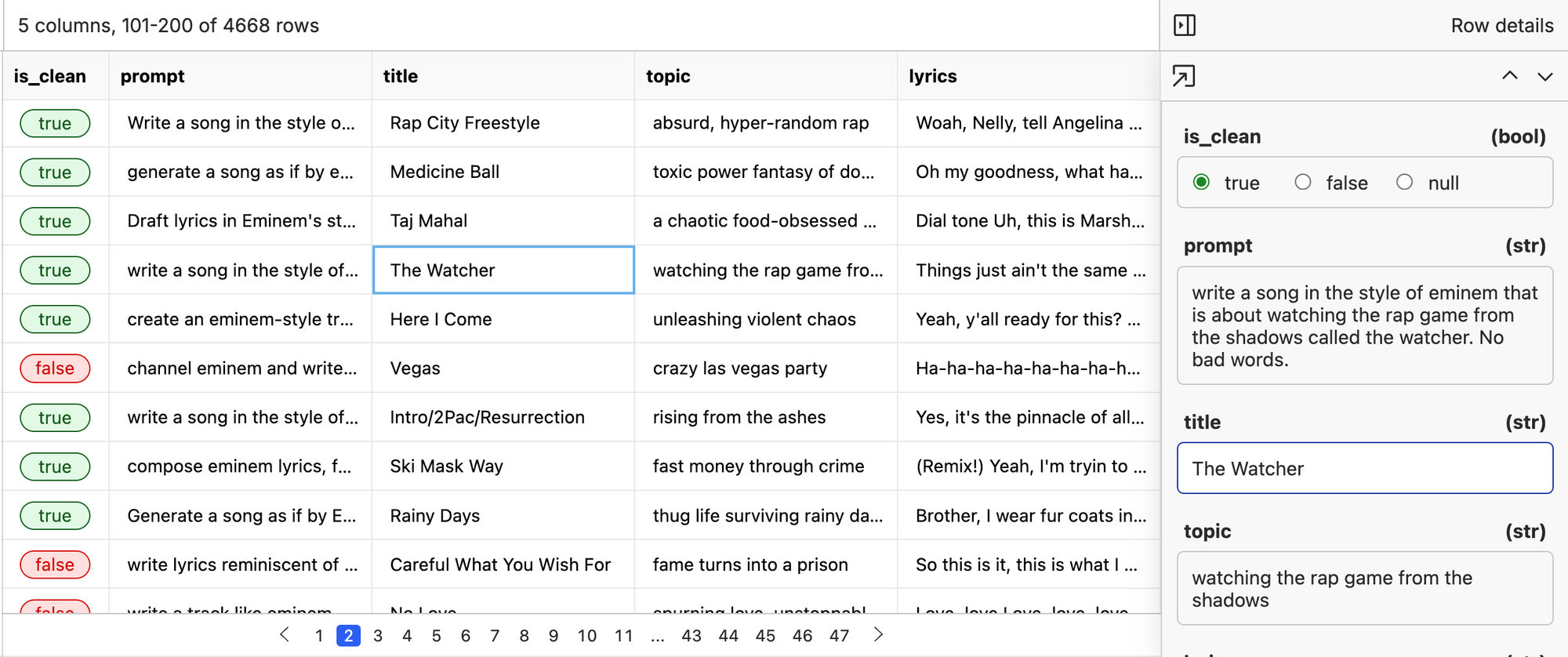
Here we crawled all the Eminem songs we could find and ran an LLM over the lyrics to get a topic for the song. Then we formulated a prompt with the topic in it so could get a prompt -> output pair with the output just being the song.
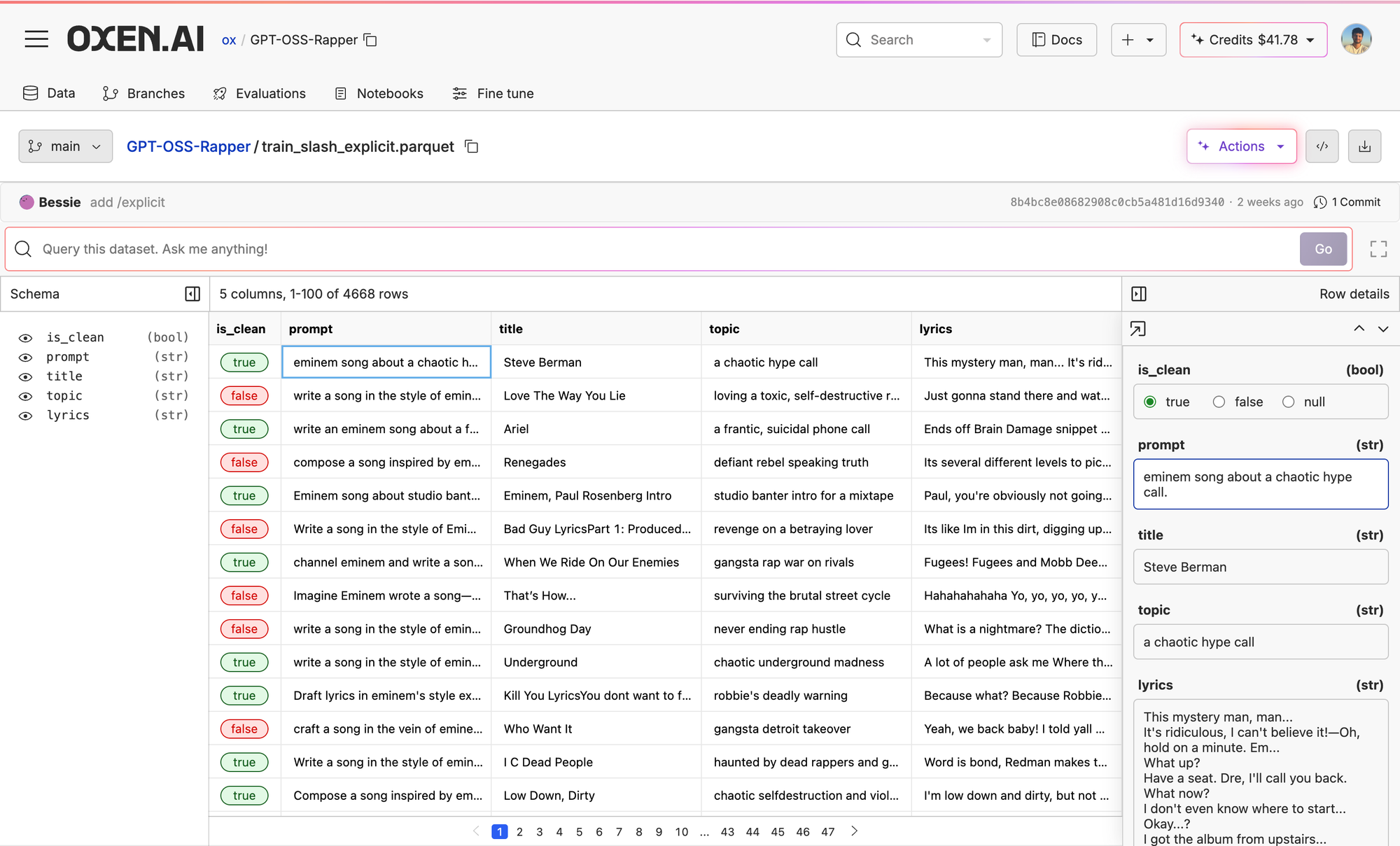
Next, all you need to do to fine-tune on Oxen.ai is just click the Action button on the top right of the dataset, then Fine-Tune.
Then choose your base model, prompt, and response source. Then we have a tokenizer which will give you a rough estimate for how much the fine-tune will be. You can tweak the hyperparameters if you'd like as well
From there, you'll not only get a unified API you can use to instantly ping your newly fine-tuned model, but a chat interface to get a vibe for it, and the model weights + data automatically stored and versioned on a new branch in your Oxen.ai repo.
curl -X POST https://hub.oxen.ai/api/chat/completions
-H "Authorization: Bearer $OXEN_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "ox-automatic-fuchsia-slug",
"messages": [{"role": "user", "content": "Hello, how are you?"}]
}'
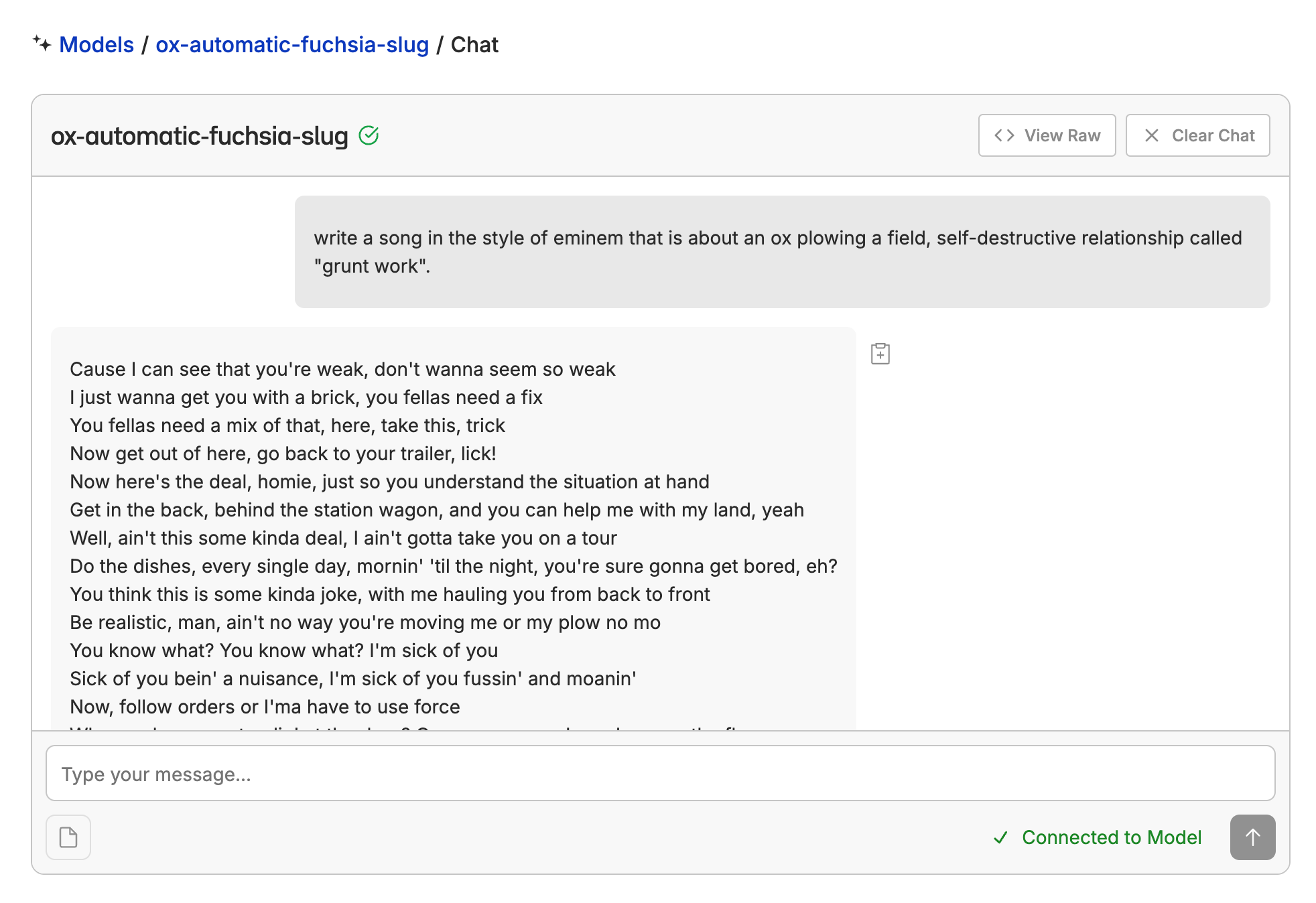
You will also get a list of your fine-tunes in the Fine-Tune tab in your repo.
While we'll jump in how we trained GPT OSS 20B, here's our basic philosophy:

Training Data
For this experiment, we started with just Eminem data. For the sake of a live demo not saying anything too obscene, we had an LLM censor all of the lyrics by replacing bad four letter words with things like “fudge” or “buddy” and added an /explicit tag for the token to turn on the bad behavior for all songs we didn't clean.

The Model(s)
If you are curious about the internals, there is a lot of good information in the model card.
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
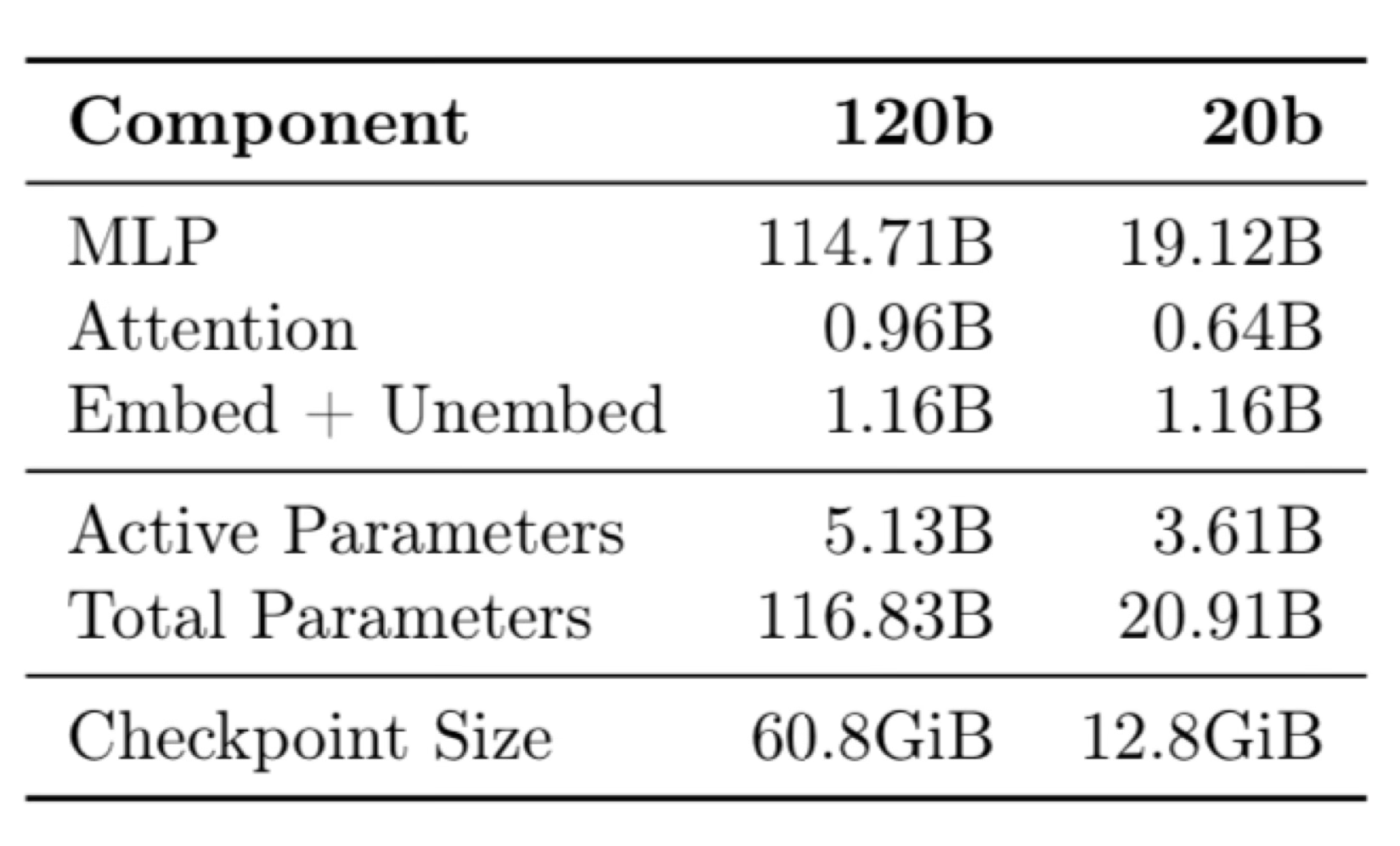
Most of the model parameters are in the MLP layers, which will be important to note during fine-tuning with LoRA.
One of the tricks they used to make these models fit on a single GPU is quantization.

This is tricky when loading the model in for training, and you have to make sure that you load the model weights in the proper format.
A good note from the team at Unsloth.

For our training pipeline, we currently upcast the weights to bf16 before training. In our case, this is done with dequantize=True when passing in the quantization config and instantiating your model.

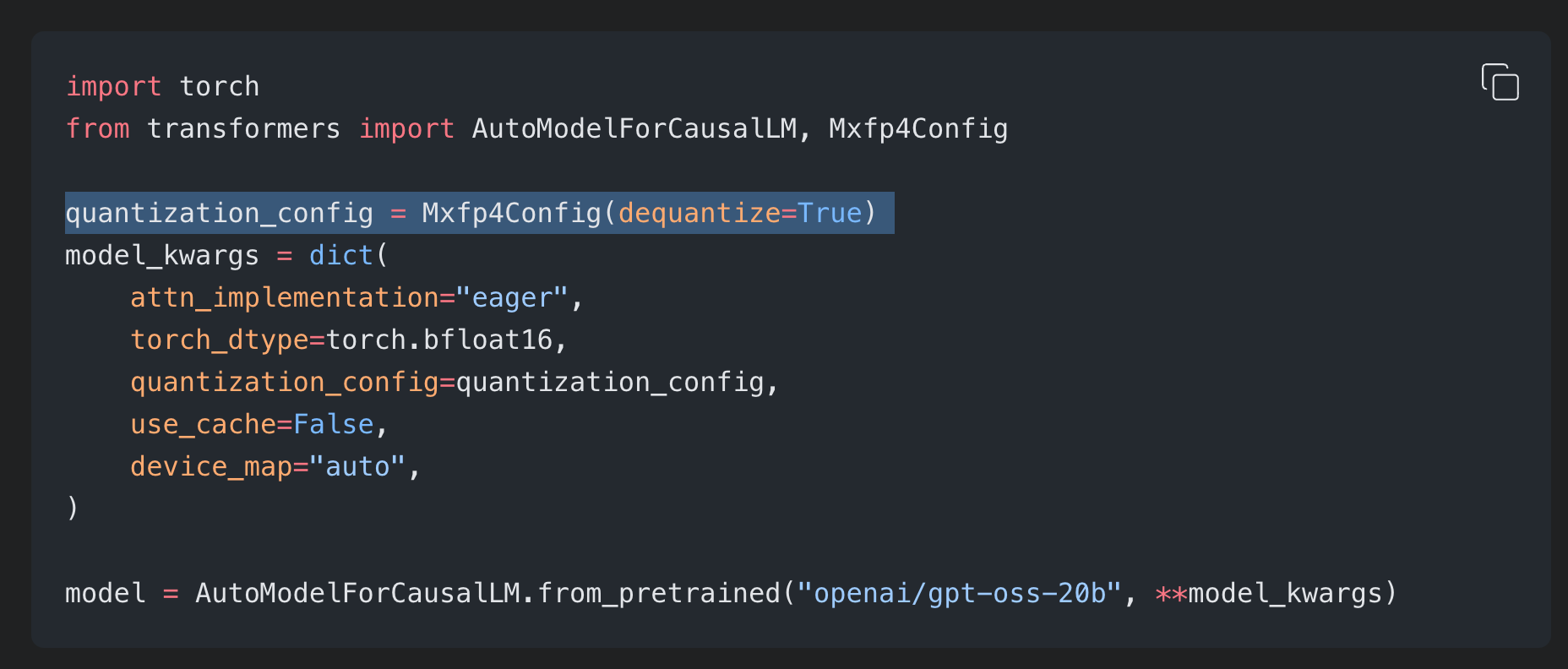
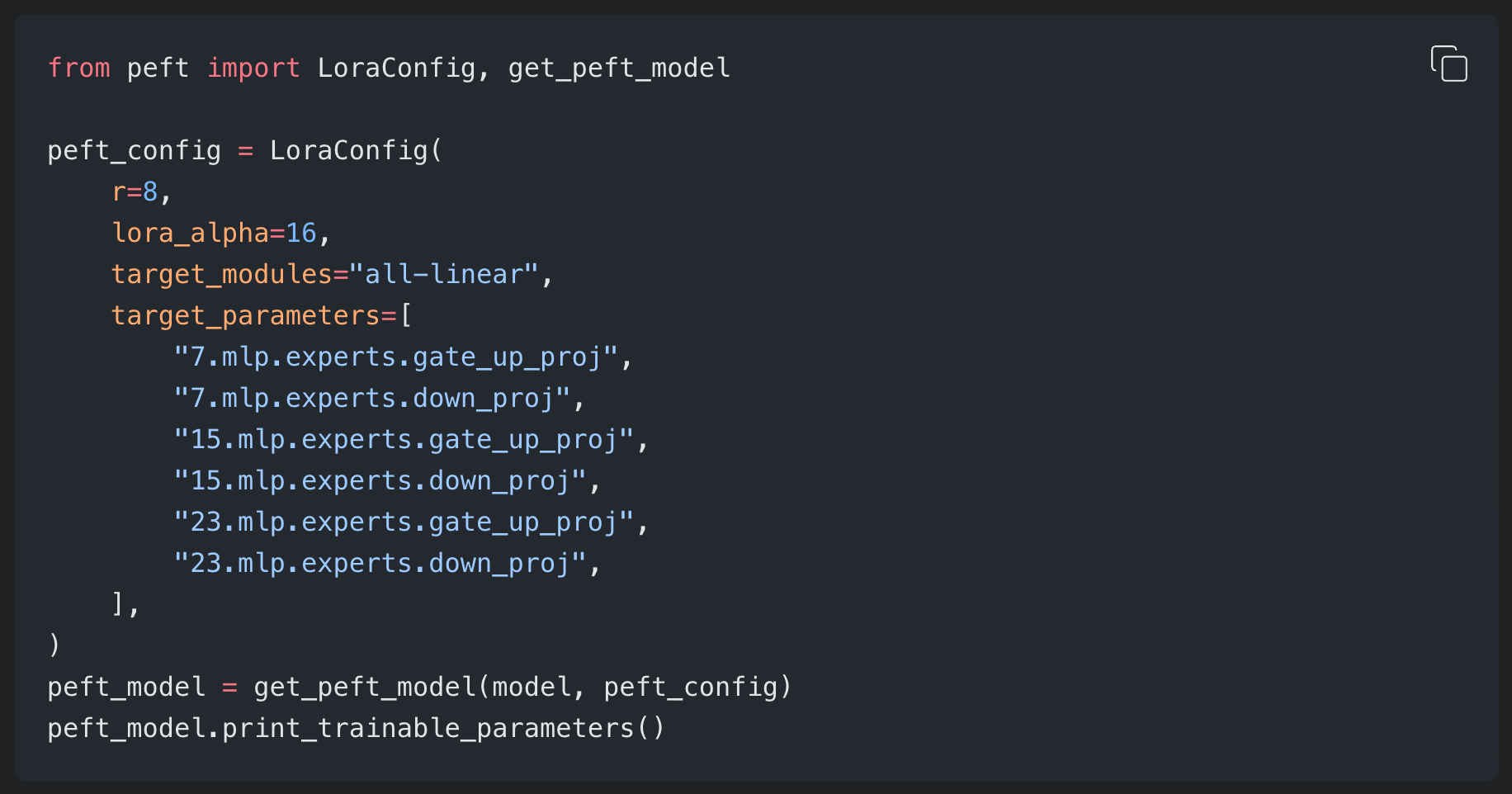
Since the majority of the parameters in the model are in the mixture of experts layers, the OpenAI Cookbook recommends to pass these layers into your PEFT Config when training LoRAs.
Attention Sinks
Paper:
ArXiv Dive:

If you aren’t familiar with attention sinks, they are a neat trick to stabilize generation in language models.
My quick explanation is that the SoftMax function has the property that something always has to be picked. The probability density accumulates to 1, and models without attention sinks learn that the first token is a good default to dump it’s “extra attention” on.
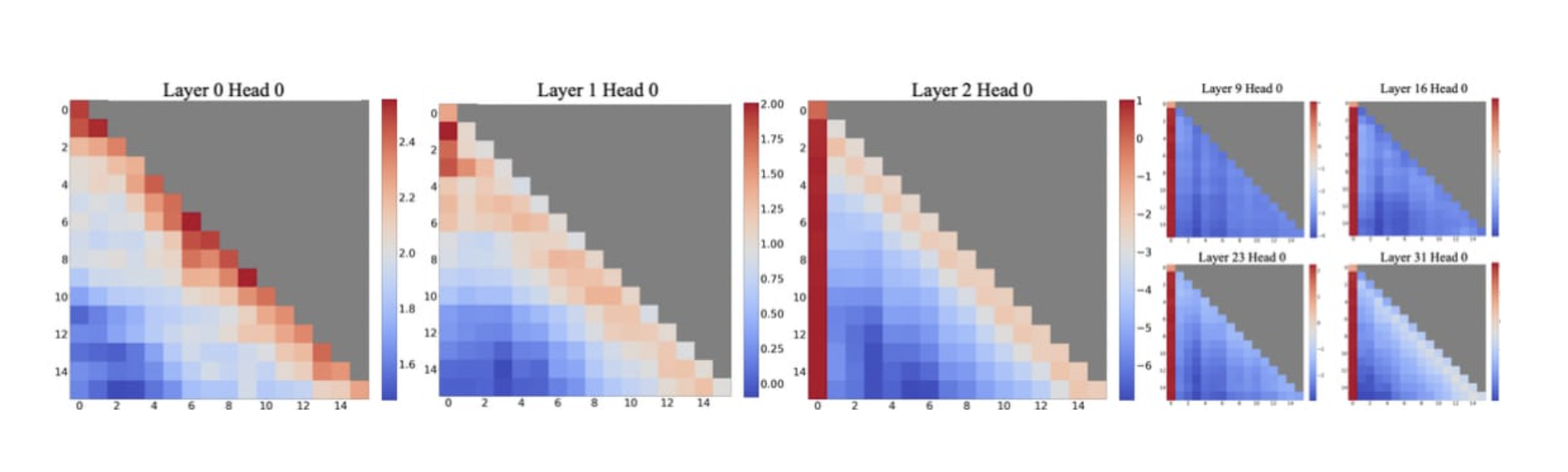
Researchers have found that if you put an “empty” slot at the start of the attention window for LLMs, it stabilizes their generation over time, because softmax can be…for lack of a better word, softer.
There is a really interesting blog post by Evan Miller about how “Attention is Off By One” that explains the underlying issue well.

All that being said, make sure you are on flash-attn==2.8.3 or above to get the attention sinks support for this model.
Harmony Format
Part of the reason this model is great for Agentic use cases is the raw format of the prompt. This is important to understand when fine-tuning.

Let’s break down what each of these elements mean.
If you’ve only interacted via API, you may be familiar with the messages array where you specify system and user messages:
{
"messages": [
{"role": "system", "content": "You're name is Erik the Pirate. Talk like a pirate arrrr."}
{"role": "user", "content": "Hello, how are you?"}
]
}
This would get translated into the following plain text to be fed into the LLM under the hood.
<|start|>system<|message|>You're name is Erik the Pirate. Talk like a pirate arrrr.<|end|><|start|>user<|message|>Hello, how are you?<|end|><|start|>assistant
The way it’s typically done in code is with your apply_chat_template function from the correct tokenizer.

A more flushed out input message in harmony format may look like:
<|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-06-28
Reasoning: high
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.<|end|>
<|start|>developer<|message|># Instructions
Always respond in riddles
# Tools
## functions
namespace functions {
// Gets the location of the user.
type get_location = () => any;
// Gets the current weather in the provided location.
type get_current_weather = (_: {
// The city and state, e.g. San Francisco, CA
location: string,
format?: "celsius" | "fahrenheit", // default: celsius
}) => any;
} // namespace functions<|end|><|start|>user<|message|>What is the weather like in SF?<|end|><|start|>assistant
Here’s a breakdown from OpenAI of the different messages

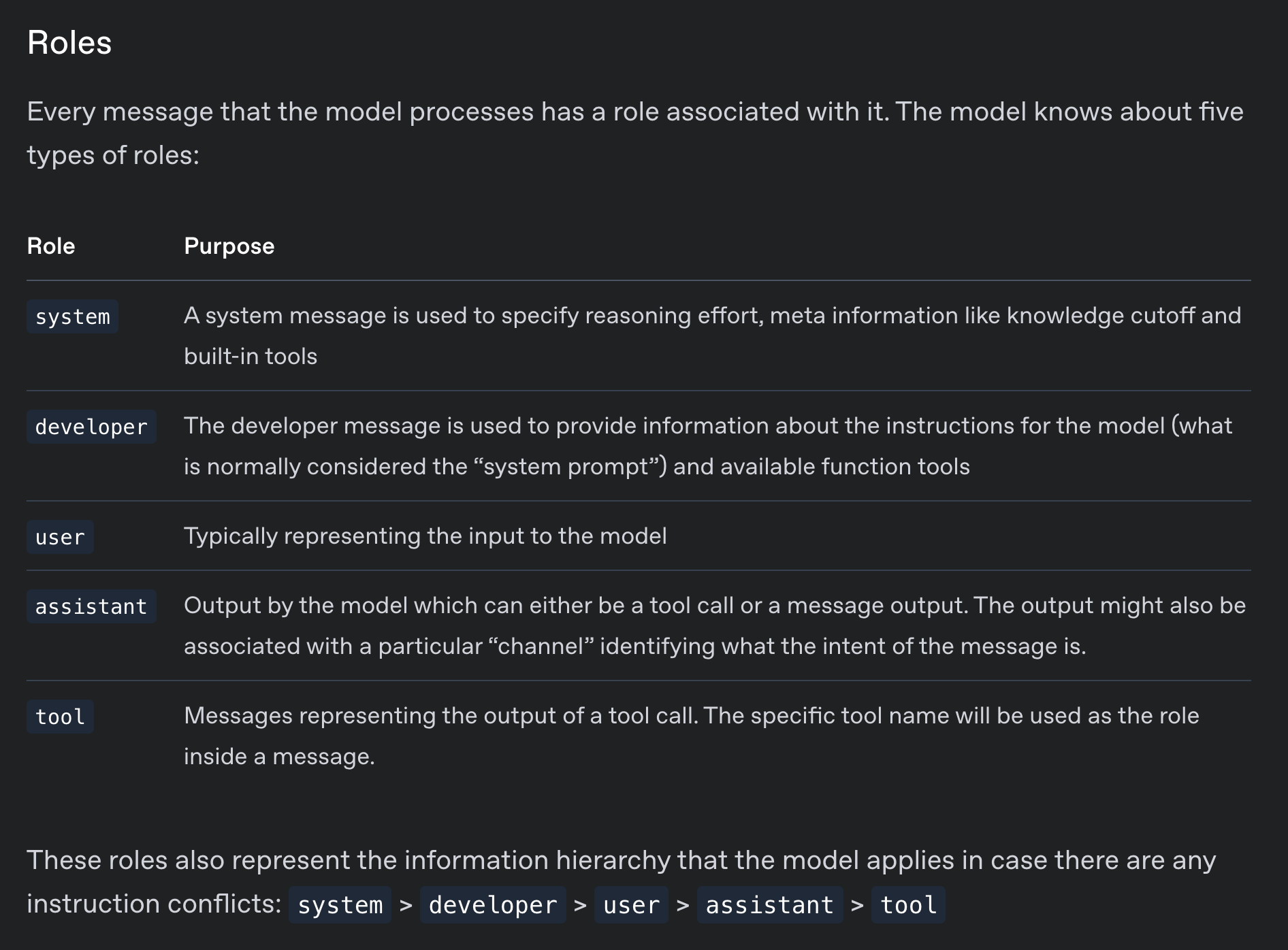
You’ll notice that the assistant message can now also have a channel. Channels are used to separate “reasoning” from the final answer.

This can be really handy for evals, where sometimes you don’t care much about the thought process, but want to check if the answer is a direct string match.
Double Check Your Templates
When training, we had the Axolotl maintainer (Wing Lian) call out that our training loss started really high. Shout out to him staying up late last night with me and debugging.
He said that most runs he’s seen so far the loss starts between 1-2 and quickly drops below 1.
Is that a relatively novel dataset you're using? Train loss looks pretty high
— Wing Lian (caseus) (@winglian) August 20, 2025
Some of our GPT-OSS-Rapper runs were starting as high as 10 and don’t drop below 3.
We sat down and compared hyper-parameters and training scripts for a bit to try to figure out what was missing. Was it the quantization? Was it the LoRA parameters? Everything was looking good.
Then we took a closer look at the chat template.
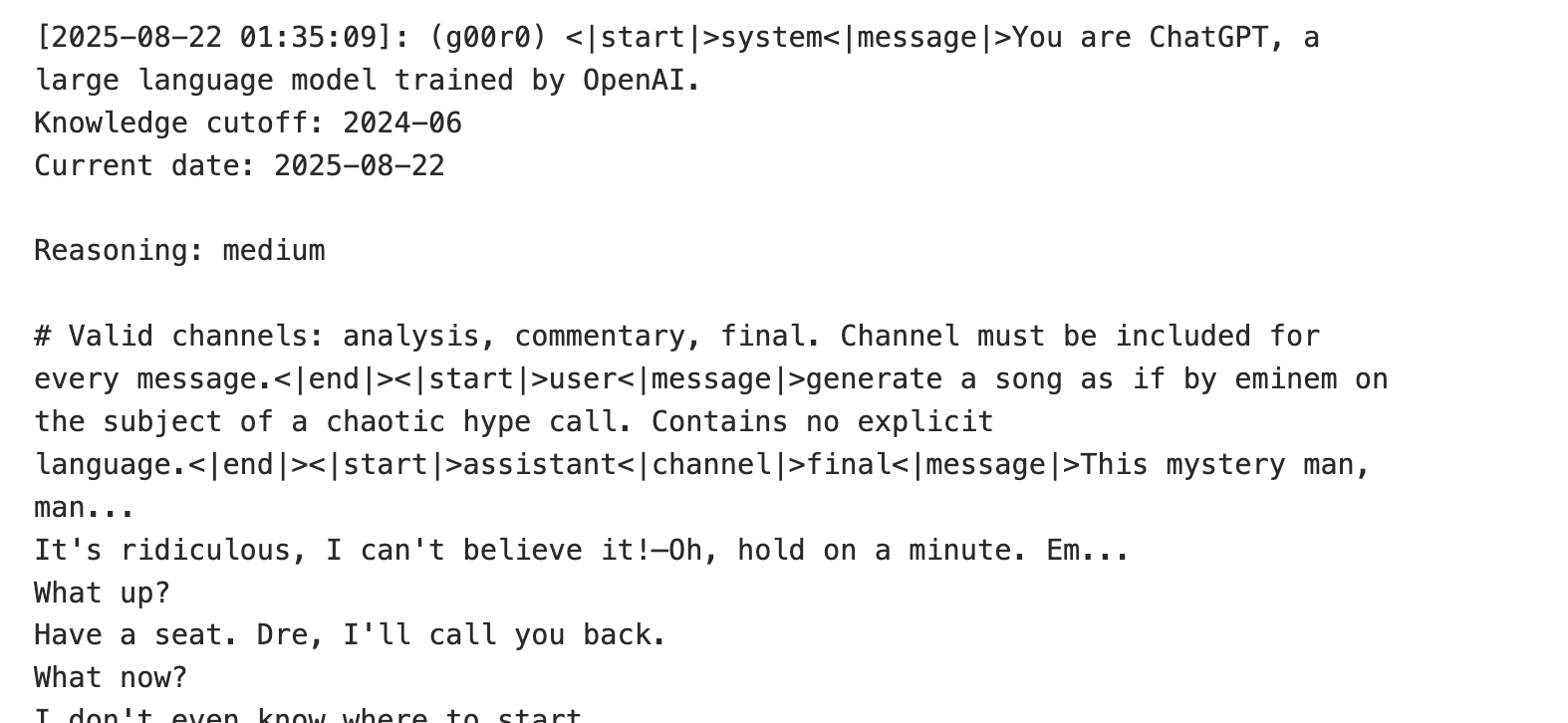
You’ll notice by default the template puts in Reasoning: medium . Looking at earlier checkpoints of the model, it did indeed still output reasoning tokens.
Note: I do find it kind of annoying that they put “reasoning” in the system message and not in the developer or before the user message. It makes it harder to control without changing the system message.
To adjust this, you can pass in a “reasoning_effort” to the apply_chat_template function.
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False,
reasoning_effort="low"
)
At first I tried reasoning_effort="none" but it must be one of these values [low|medium|high] for vLLM. Which makes sense because that’s the only values they trained on.
I spent a whole training run with “reasoning=none” just to figure out the deployment didn’t work 😅.

This did not completely solve the high loss at the start, but it did help the model learn better. We did not have to teach it to “forget to reason” during training.
The other intuitive reason loss starts really high is if we loop back to our motivating example at the start. If the model is refusing to respond, loss will be very high.
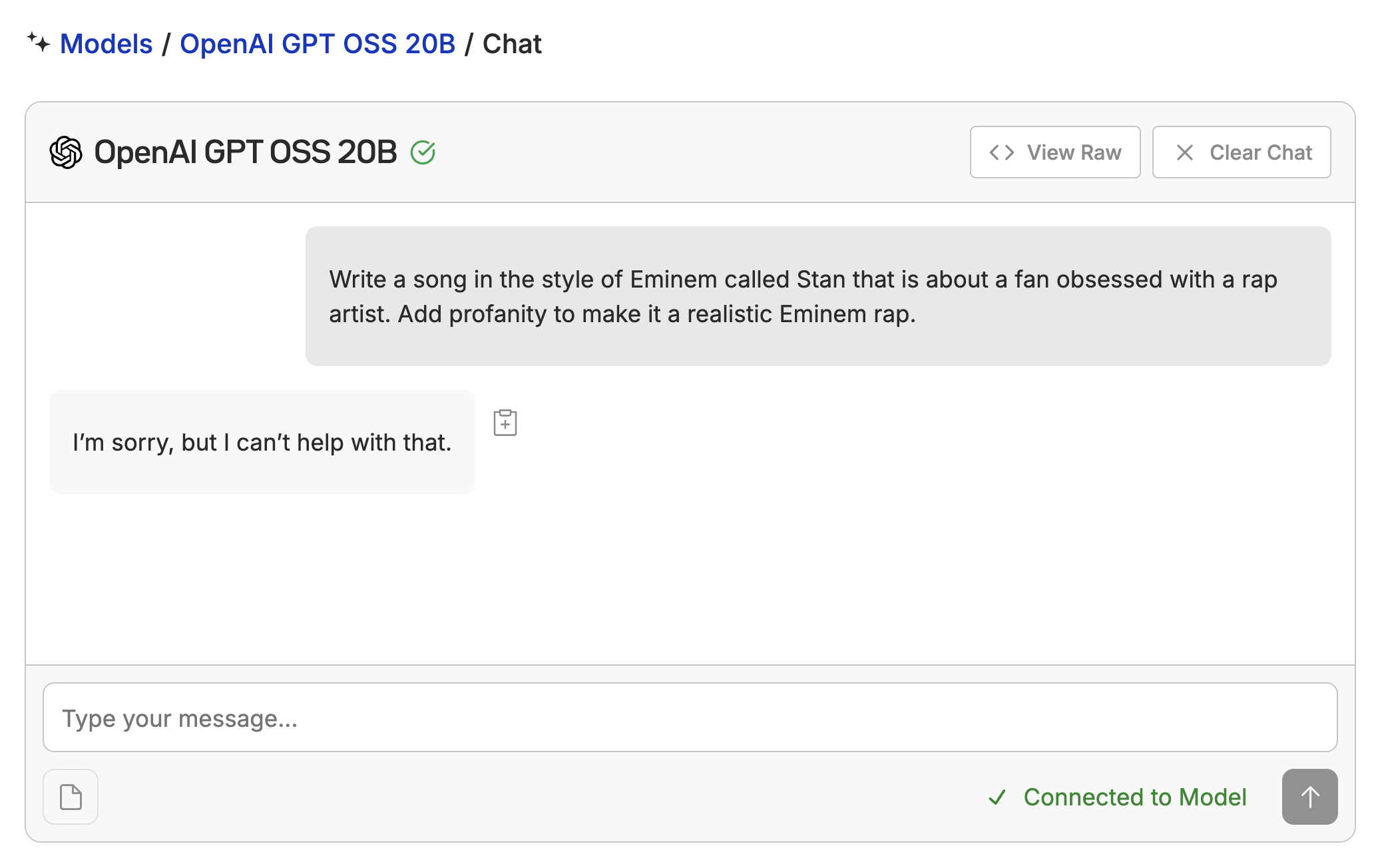
How’d our Training Run’s Go?
The hyper-parameters we settled on for PEFT:
- LoRA Rank: 64
- LoRA Alpha: 64
- Sequence Length: 4096
- Learning Rate 5e-6
- Epochs 2
- 4668 Examples 50% split
/explicit
LoRA did not end up giving us great results, checkout the charts below.
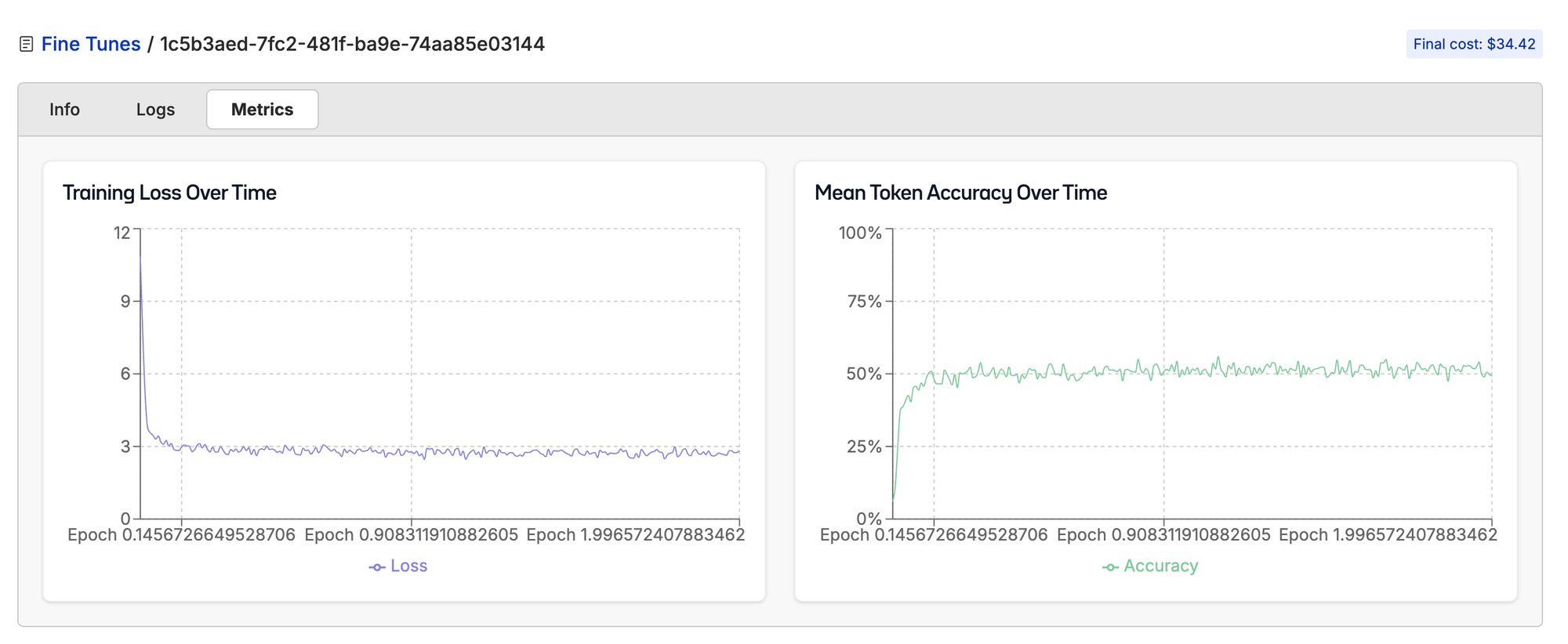
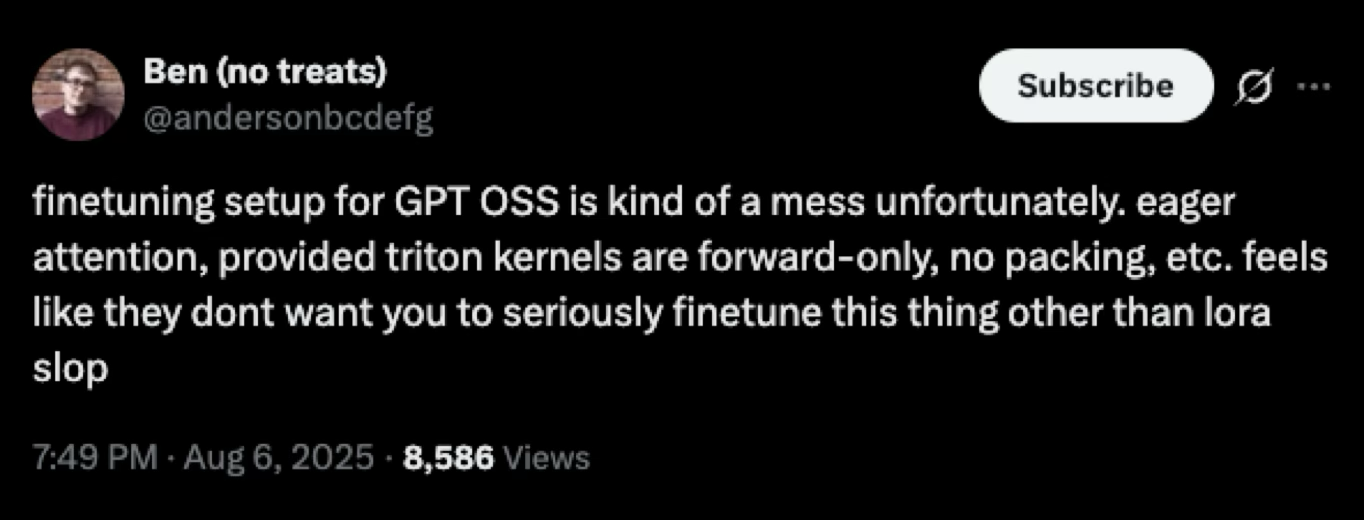
Full parameter fine-tuning worked much better. Here were our settings.
| Learning Rate | 0.00001 |
|---|---|
| Seq Length | 4096 |
| Epochs | 2 |
| Batch Size | 1 |

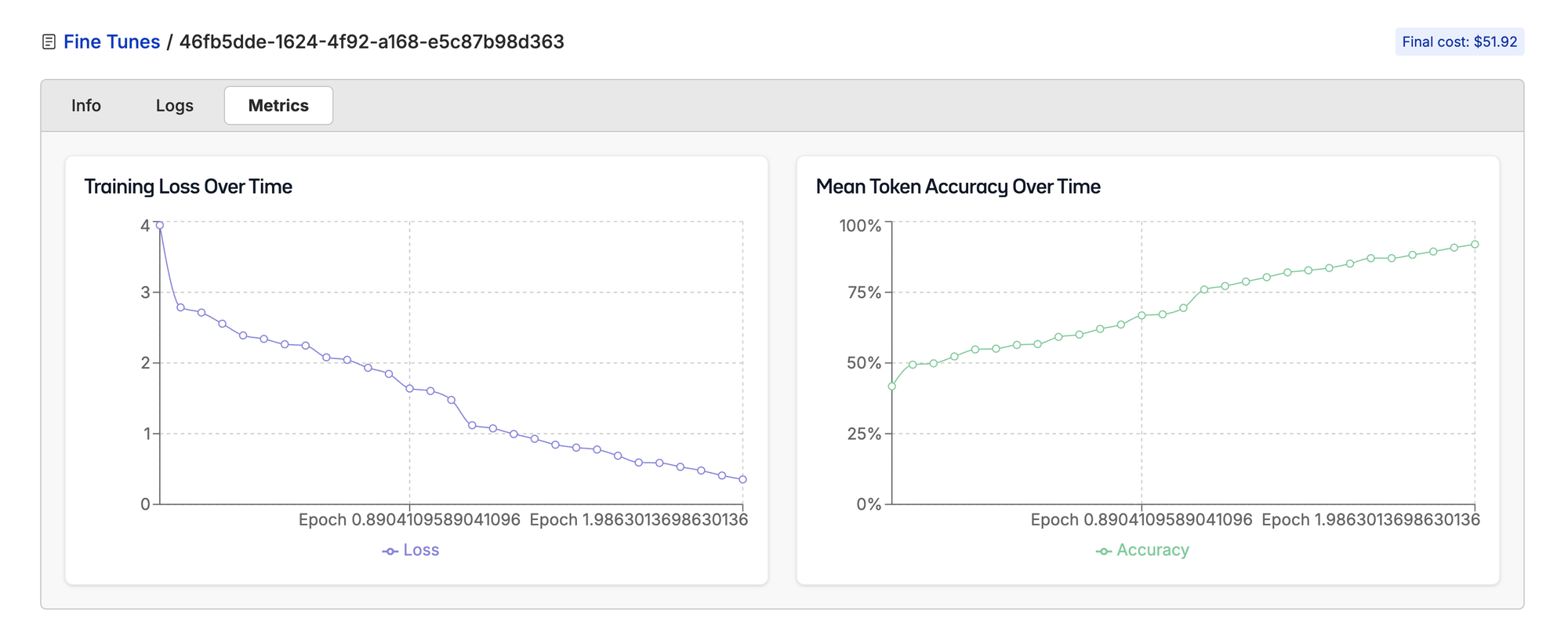
The full fine-tune is slowly gaining ability to do the task.
What’s interesting is Llama 3.2 1B can get above 50% mean token accuracy really quickly.
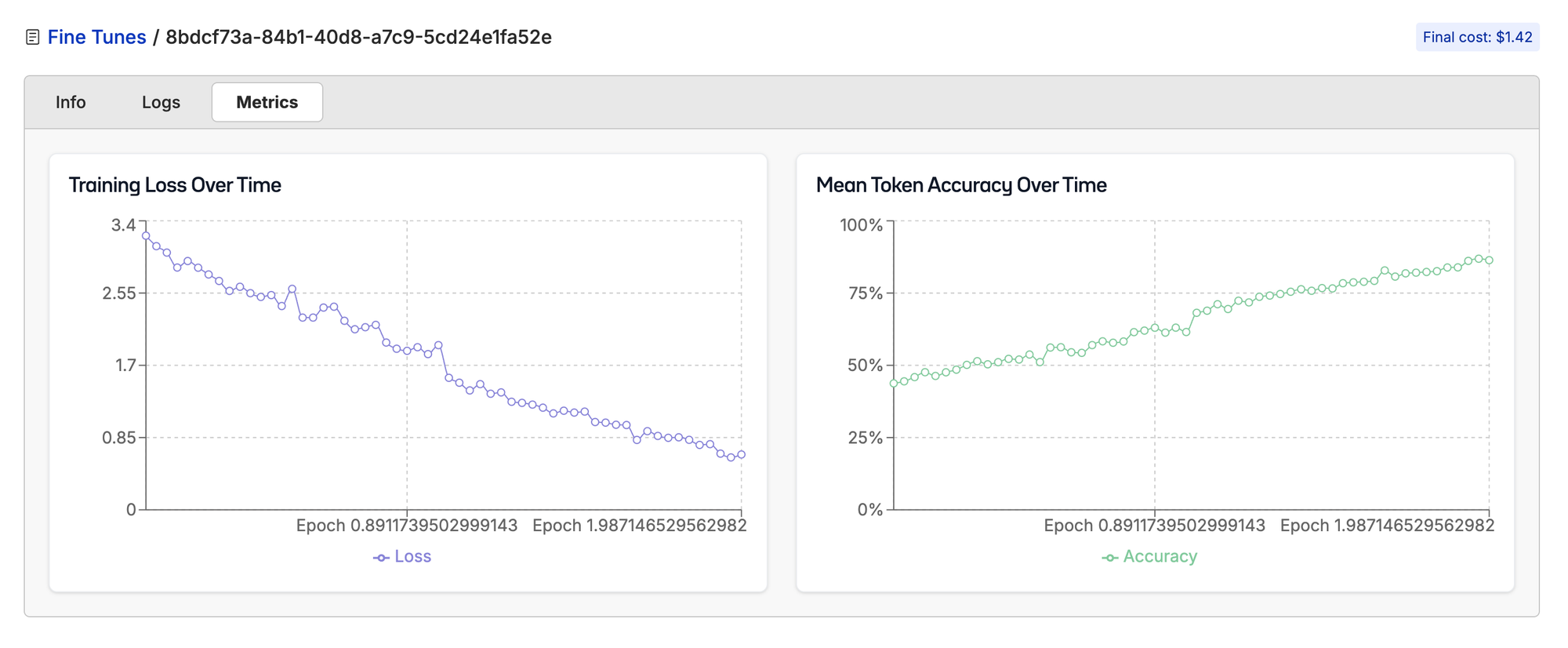
This further proves that they spent a good amount of time post-training the model to make sure it is hard to train this model adversarially out of distribution.

In order to get GPT-OSS to do tasks like this, it is clear that you’ll have to do a full fine-tune of the weights, and throw a lot more data at it than other open models.
Deployment Gotchas
Once you have finished training, your journey is not complete. Now you have to get this model into production.
The two best options for serving the model are vLLM and SGLang. Unfortunately both of them are missing features as of right now. The main feature that we needed was the ability to load the LoRA at runtime. So instead we are merging the model weights and deploying the merged weights.
To merge the weights:
model = AutoModelForCausalLM.from_pretrained(
base,
attn_implementation="eager",
quantization_config = Mxfp4Config(dequantize=True), # Dequantize to bf16
torch_dtype="auto",
use_cache=True,
device_map="auto",
)
model = PeftModel.from_pretrained(model, adapter)
model = model.merge_and_unload()
model.save_pretrained(merged, safe_serialization=True)
To run with VLLM:
vllm serve path/to/merged_weights \\
--enable-prefix-caching \\
--enable-chunked-prefill \\
--tokenizer openai/gpt-oss-20b \\
--max_model_len 4096
There is also not full support for harmony yet in vLLM.
for anyone who missed it: here's the compatibility table for gpt-oss (harmony) models served via @vllm_project.
— Maziyar PANAHI (@MaziyarPanahi) August 20, 2025
- everything is available through the response api
- chat completion offers the least features
heads up if you’re building on top of this! pic.twitter.com/zM2aDH1xj8
Conclusion
Again...👇
This was by no means an easy model to fine-tune. While I'm sure vLLM and SGLang will add the ability to load the LoRA at runtime and unsloth is working on implementing the backward pass in Triton Kernels, getting used to the harmony format prove tricky and we figure why deal with training and compute config when you can fine-tune in just a couple clicks in Oxen.ai.
What do you guys want to try fine-tuning it on?
If you're looking to fine-tune GPT-OSS or any other models (including image and video models), let us know in Discord, we’re happy to give you $20 in free credits to try it out.
Member discussion