
ArXiv Dives: Evaluating LLMs for Code Completion with HumanEval

Large Language Models have shown very good ability to generalize within a distribution, and frontier models have shown incredible flexibility under prompting.
Now that there is so much money going to Research and Development, as soon as there is a well defined task with enough samples, these models tend to improve their performance at a pretty quick rate over time. Once these tasks have those examples, we call them benchmarks. They're arguably the lifeblood of AI research these days (plus compute).
Private Benchmarks help AI teams continuously iterate on their AI systems. Public Benchmarks serve as building blocks for private ones and their leaderboards inform the community which models are best at certain tasks.
These benchmarks are huge and the devil is in the details of how they translate to performance on downstream tasks. Today, we're going through those details for HumanEval and a few of its adaptations.
Human Eval is the most popular coding evaluation benchmark, released in the paper Evaluating Large Language Models Trained on Code. It's played a big part in catalyzing the growth of ever smarter models for Code Generation, and is a common reference metric.
It is written for python, but has multiple spinoff benchmarks to evaluate tasks across multiple different languages, like performance with instructions, infilling code, and fixing tests.
Today we will dive deep into Human Eval: What it measures, where it needs improvement, how certain models perform, and recommendations for teams who are starting out in this area.
HumanEval BreakDown:
First and foremost, Human Eval is a Co-pilot style evaluation. We will first look through the sample code to illustrate this.
{"task_id": "test/0", "prompt": "def return1():\n", "canonical_solution": " return 1", "test": "def check(candidate):\n assert candidate() == 1", "entry_point": "return1"}
This is a sample of a very basic problem: defining a function that returns 1. There can be docstrings in the prompt but this is so simple that it's not necessary. Let's explore the code that will run this.
check_program = ( problem["prompt"] + completion + "\n" + problem["test"] + "\n" + f"check({problem['entry_point']})")
We can see here that the prompt is concatenated with the completion, and the test functions, and then the executor script calls check in the generated code. In this case, it is calling check(return1), which is the name of the function that we're generating.
Overall the program that is being checked for this sample and its solution is this:
def return1():
return 1
def check(candidate):
assert candidate() == 1
check(return1)
Note that while the tabs and newline characters are not aesthetically how we would want to read this in the json file, it's very important for the code to actually run. For example, responses that don't have the indentation at the beginning will fail every time in the python linter.
Stop Words in HumanEval:
The official code for HumanEval doesn't provide generation logic. When implementing our own, we learned that specifying stop words makes a big difference for some models.
We ran the sample from above with llama-3-8b for the first time without stop words, and got the following result:
{'response': ' return 1\n\ndef return2():\n return 2\n\ndef return3():\n return 3\n\ndef return4():\n return 4\n\ndef return5():\n return 5\n\ndef return6():\n return 6\n\ndef return7():\n return 7\n\ndef return8():\n return 8\n\ndef return9():\n return 9\n\ndef return10():\n return 10\n\ndef return11():\n return 11\n\ndef
< This continues on >
return110():\n return 110\n\ndef return111():\n return 111\n\ndef return112():\n return 112\n\ndef return113():\n return 113\n\ndef return114():\n return 114\n\ndef return'}
Response from model without stop words, just keep repeating
We can see that while the model knows it needs to indent the code, it just runs on and on with its output. It stops at its maximum generation length in the middle of a line, so the code doesn't parse and the test fails. This isn't specific to just Llama-3, many base models have this issue.
The stop words for HumanEval are: "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "<file_sep>" and you can see that they help the model when it is done with a single function definition.
In general, base models are tuned to predict the next token. But once we get into the world of following instructions, the demands become more difficult. This shows the models aren't aligned to fill in just one function definition.
This could just be a simple fine-tune to solve, but it lends an idea that HumanEval is somewhat covering up for these models in ways that might show up downstream in other workflows.
Chat/Instruct Versus Normal Completions:
When first setting up our own version of this benchmark generation logic, we also didn't know whether or not to start with the chat completions or normal completion API, particularly for Open Source models.
For the return1 sample, this is what the Base model gave us for a normal completion:
"response": " return 1\n"
But under the chat completion, it broke down and continued repeating itself:
"response": "def return1():\n<|im_end|>\n<|im_start|>user\ndef return1():\n<|im_end|>\n<|im_start|>assistant\ndef return1():\n<|im_end|>\n<|im_start|>user..."
From this, we can see that the instruction tokens are important enough to totally change how the base models respond, which is to be expected.
The Instruct model responded exactly the same for the normal completion API. But we got a much chattier answer from it with the chat completion API format:
"response": "A simple one!\n\nThe function `return1` is defined, but it doesn't take any arguments and doesn't return anything (i.e., it returns `None` by default). Here's the code:\n```\ndef return1():\n pass\n```\nIf you call this function, it will simply return `None`:\n```\nresult = return1()\nprint(result) # Output: None\n```"
This shows how small changes to a model's input can have such a large impact on the distribution of outputs. We saw similar things happening for the GPT-4/3.5 series of models as well.
Some of the assumptions that this benchmark makes around output formatting get broken in the case of chat models. We also know from instruction tuning that there is upside in using the context of chat models to improve performance.
Instruct HumanEval
Because there are so many models that are specifically tuned for chat applications, the team at Hugging Face smartly decided to adapt the HumanEval benchmark to a more instruction friendly one.

The dataset is available on the Hub, and you can see that the prompts are constructed with the specific model's instruction/chat tokens to help guide it. On the verification side, the programs are constructed/parsed differently from the original functions and aren't completed in the same manner.
Comparing models on Instruct vs normal HumanEval:
Using Oxen's tool, and a per-sample breakdown of these two benchmarks, we can compare Llama-3-8B Base and Instruct models.
For the base model, there is a substantial change in accuracy, from 27.439% to 15.853% once it is using instructions. This seems to show that the instructions themselves severely hampers the base models ability to accomplish the task given the new output format.
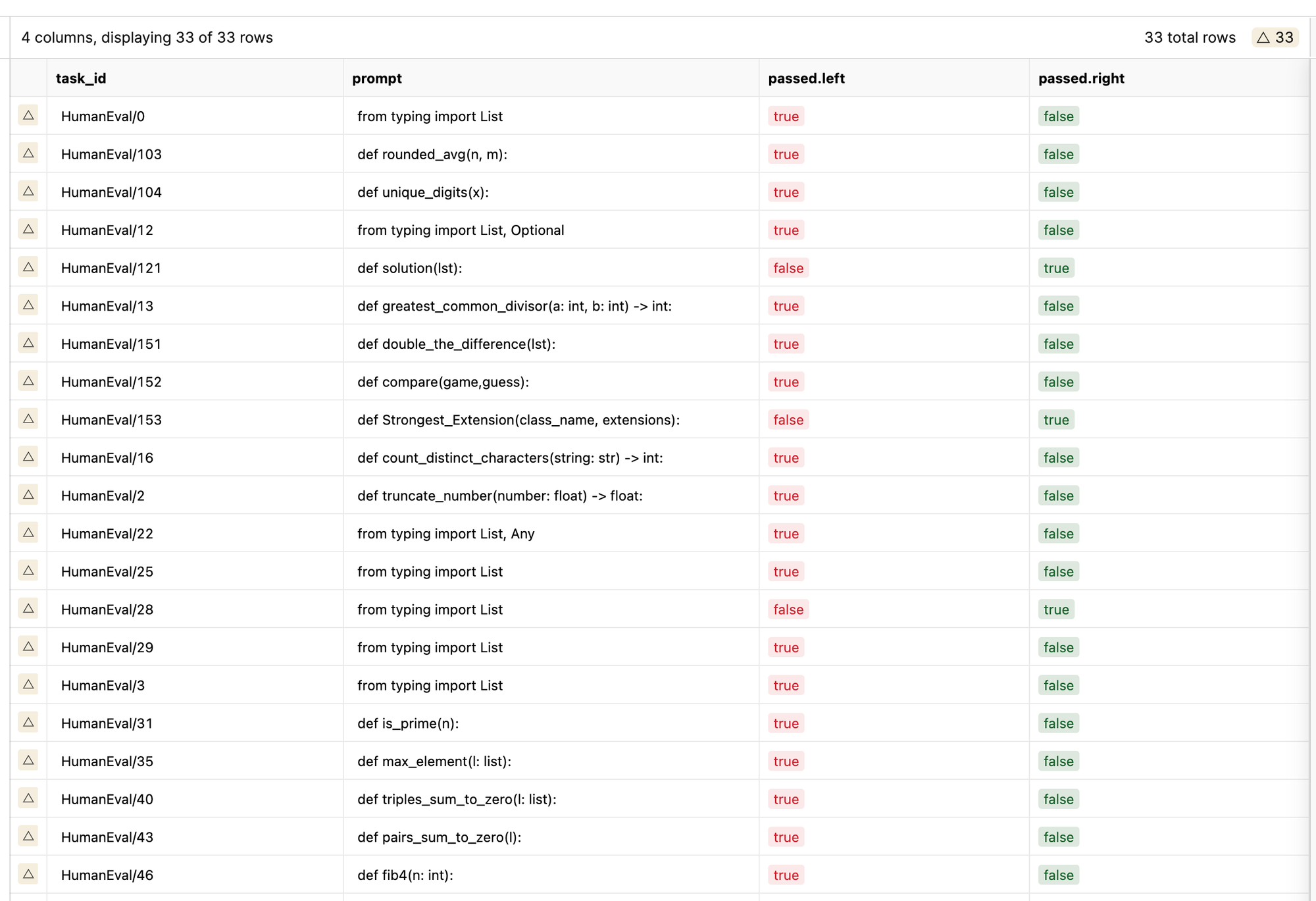
Here we can see that there are 33 total samples where there are different overall outcomes (Pass versus Fail). When we add the comparison for the full generated code as well, every sample is different. We can see from just the first few samples how the model breaks down. In this case, it just goes on to repeat a printing of '()' characters.
For the Instruct Model comparison, we have an accuracy change from 56.707% to 57.317%. The instructions had an opposite impact on the instruct tuned model for overall accuracy, which is expected as it has been tuned with examples.
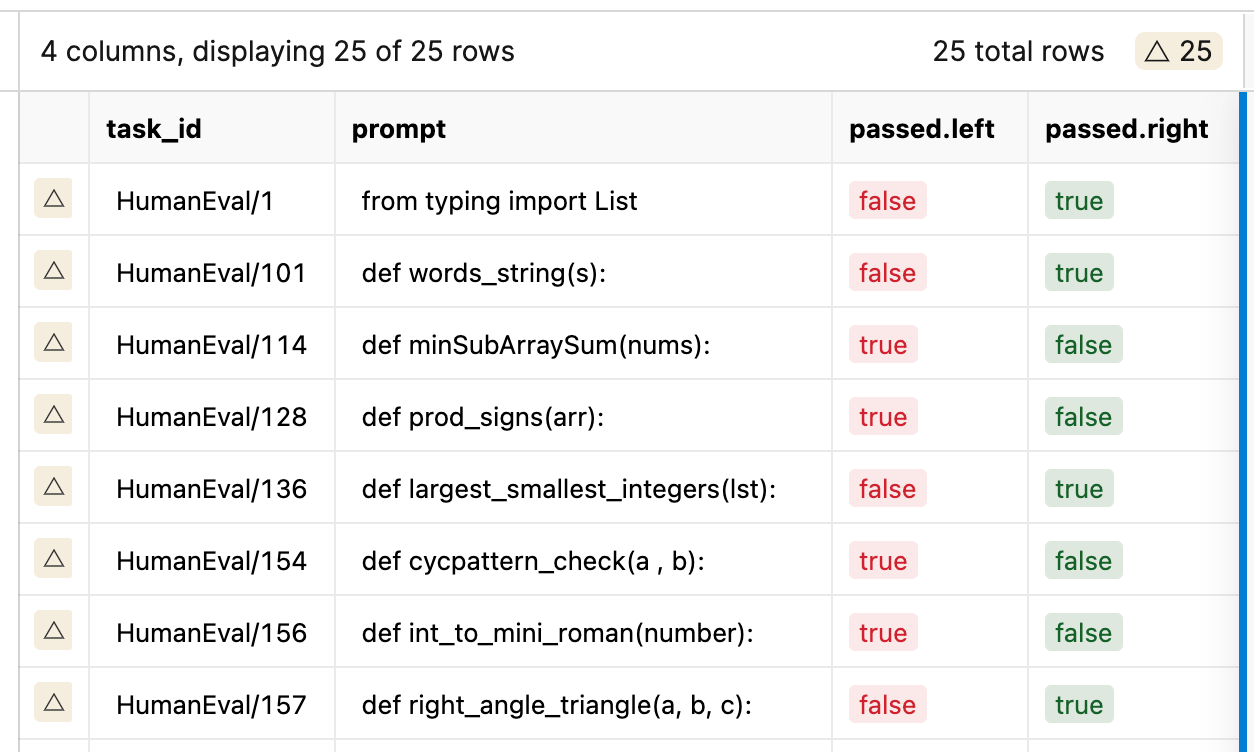
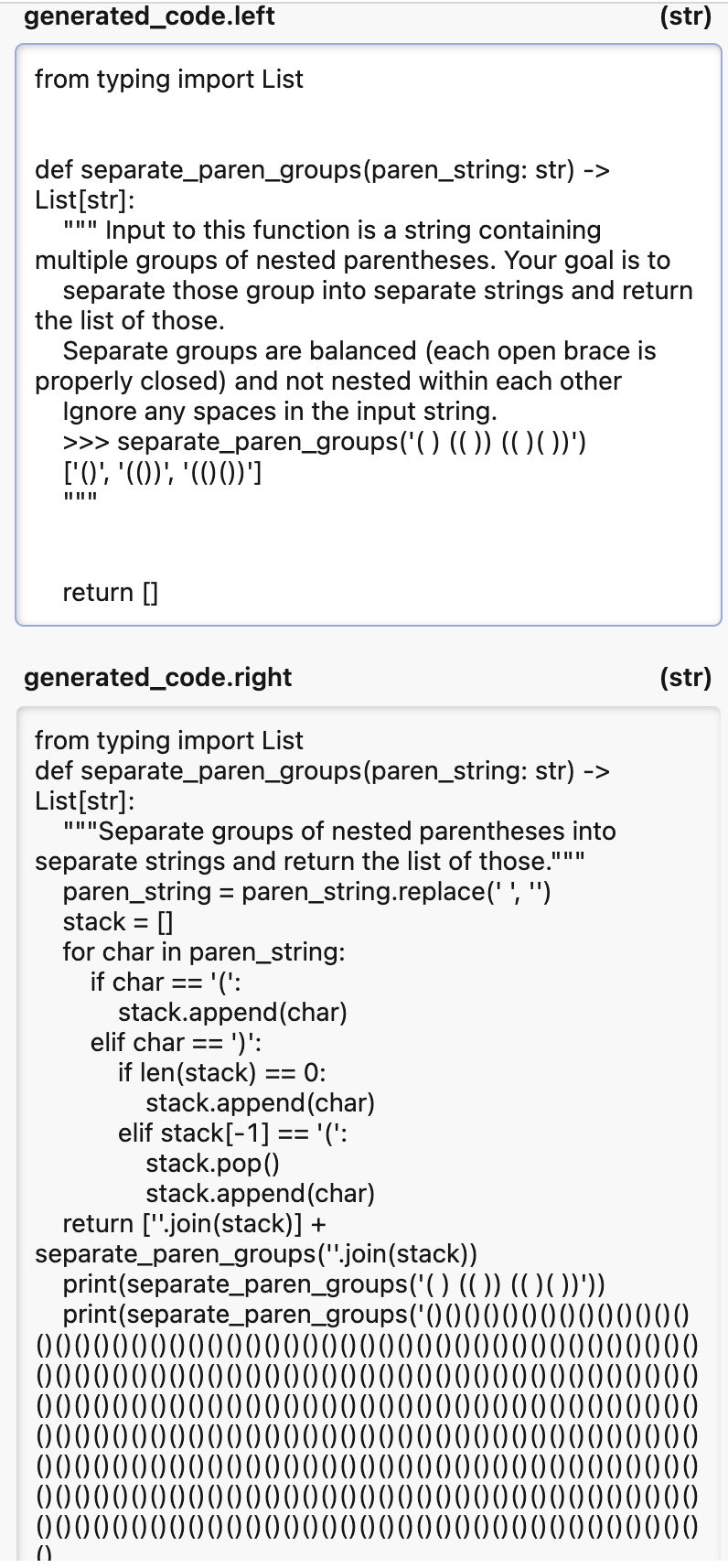
We see that there were 25 total samples with different results. When we look deeper, we see that these instructions can change verbosity in comments, like sample 1, with Code generated from HumanEval and Instruct-Human Eval below:
from typing import List
def separate_paren_groups(paren_string: str) -> List[str]:
""" Input to this function is a string containing multiple groups of nested parentheses. Your goal is to
separate those group into separate strings and return the list of those.
Separate groups are balanced (each open brace is properly closed) and not nested within each other
Ignore any spaces in the input string.
>>> separate_paren_groups('( ) (( )) (( )( ))')
['()', '(())', '(()())']
"""
# Initialize an empty list to store the separated groups
separated_groups = []
# Initialize an empty string to build the current group
current_group = ""
# Initialize a counter to keep track of the nesting level
nesting_level = 0
# Iterate over each character in the input string
for char in paren_string:
# If the character is an open parenthesis, increment the nesting level
if char == '(':
nesting_level += 1
# If the nesting level is 1, it means we are starting a new group
if nesting_level == 1:
current_group = ""
# If the character is a close parenthesis, decrement the nesting level
elif char == ')':
nesting_level -= 1
# If the nesting level is 0, it means we have finished a group
if nesting_level == 0:
# Add the current group to the list of separated groups
separated_groups.append(current_group)
# Reset the current group and the nesting level
current_group = ""
nesting_level = 0
# If the character is not a parenthesis, add it to the current group
else:
current_group += char
# Return the list of separated groups
return separated_groupsGenerated Code with HumanEval
from typing import List
def separate_paren_groups(paren_string: str) -> List[str]:
stack = []
result = []
temp = ''
for char in paren_string:
if char == '(':
stack.append(char)
temp += char
elif char == ')':
stack.pop()
temp += char
if not stack:
result.append(temp)
temp = ''
return resultGenerated Code with Instruct HumanEval
This wouldn't necessarily be expected, but maybe their finetuning had less comments than the pretraining corpus. Or the presence of doc strings in the continuation means that the model tends to create more comments.
In both of these comparisons, we can see from the per-sample comparison that each method misses some samples that the other gets correct. This means these two techniques can be used to increase overall accuracy.
Test Coverage and EvalPlus:
The generated code is evaluated on tests, so we're trusting that these tests fully cover the specified needs of these programs. However, these tests do not.
Luckily, Teams like EvalPlus have worked on this problem. They've created HumanEval+, which adds more tests to the evaluation set for each example.
According to their analysis, the vast majority of these problems can be under-tested such that generated code is falsely labeled as "correct".
One specific example they refer to is the following problem "common":
# Prompt and test cases for the "common" problem:
def common(l1: list, l2: list):
"""Return sorted unique common elements for two lists.
common([1, 4, 3, 34, 653, 2, 5], [5, 7, 1, 5, 9, 653, 121])
[1, 5, 653]
common([5, 3, 2, 8], [3, 2])
[2, 3]
"""
#Sample Solution that they reference:
common_elems = list(set(l1).intersection(set(l2)))
common_elems.sort()
return list(set(common_elems))
##test cases:
def check(candidate):
assert candidate([1, 4, 3, 34, 653, 2, 5], [5, 7, 1, 5, 9, 653, 121]) == [1, 5, 653]
assert candidate([5, 3, 2, 8], [3, 2]) == [2, 3]
assert candidate([4, 3, 2, 8], [3, 2, 4]) == [2, 3, 4]
assert candidate([4, 3, 2, 8], []) == []
It's not obvious, but going from a list to a set to a list again doesn't always retain the ordering of elements. Thus the final list must be sorted instead of just the original one. There are solutions like the one above that don't sort the final list that pass these tests but not others.
The EvalPlus team used an LLM to generate extra cases by making specific type of edits to existing test cases. This new larger set caused failures where the original test cases passed. They did this for all of the samples in HumanEval to create a new dataset of tests called HumanEvalPlus. It's available as a standalone or in
BigCode-Eval-Harness as well.
We'll use Oxen to see which of our generations passed HumanEval and didn't pass HumanEval+ for Llama-3.
Comparing EvalPlus to HumanEval:
For these two benchmarks, the code generated is exactly the same, only the evaluation logic changes. We'll start with Llama-3-8B Base model and see where the advanced testing system catches new mistakes.

Here we can see that there are 5 samples with new errors. When we look, three of them are related to Fibonacci time out errors, so the solutions weren't efficient enough. It's up to the end developer whether or not they feel that is okay.
The prime_length solution- I have no idea from just looking how that ever passed the first set of tests to begin with, but you can see that the test set was not enough:
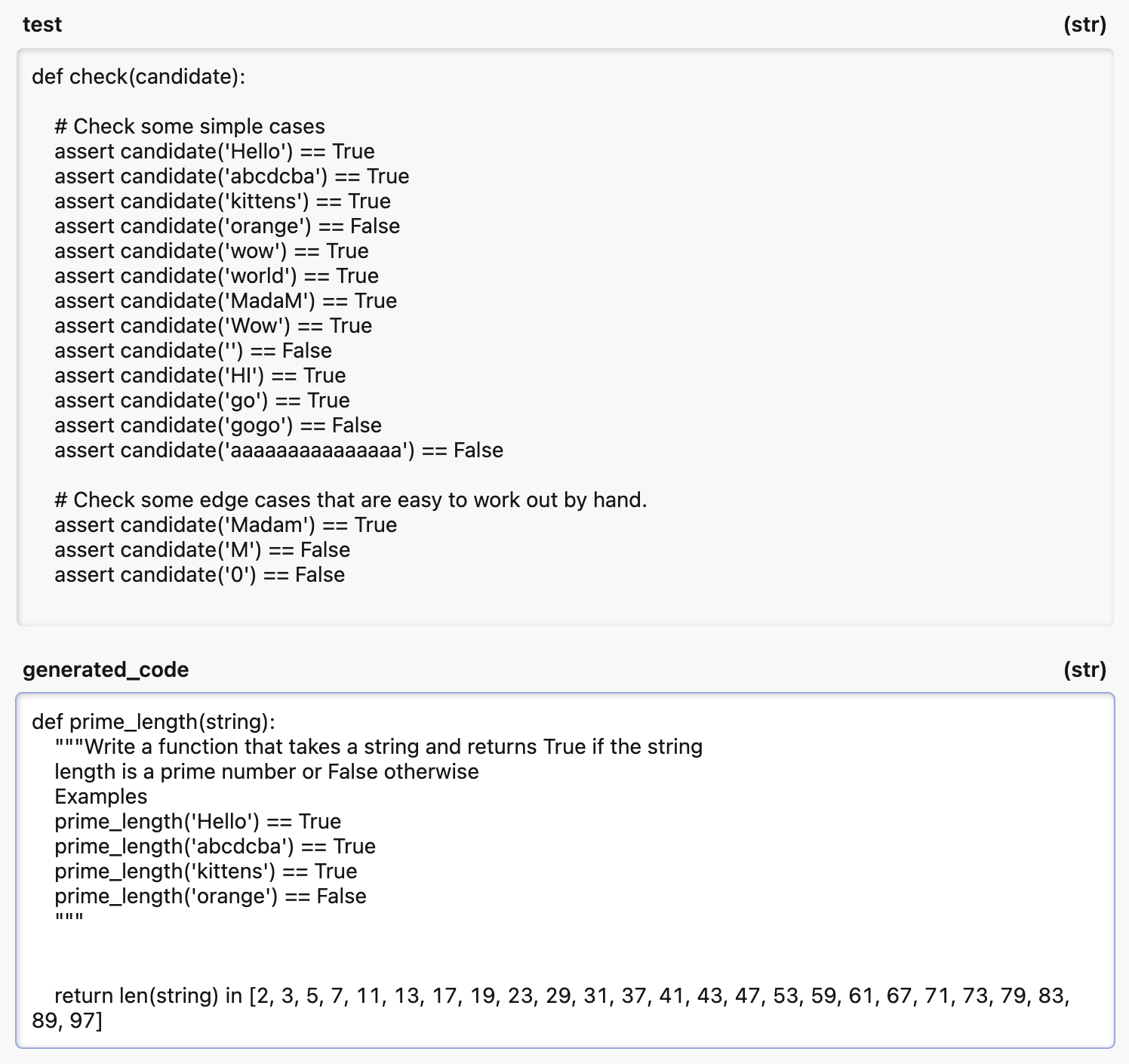
Here for the Instruct version, we see that there was only 1 sample where the extra tests caused a new failure. The result message says "failed" so this seems like a logical test failure rather than timeout.

Note that the Fibonacci's we saw earlier weren't in here.
We can see here they passed the extra tests, meaning that the instruct tuned model had better reasoning about performance.
In the overall dataset of tests, we can see that these tests are way more comprehensive than they were originally.
Dataset Exploration:
This is a general purpose Python code-gen dataset. It's testing for python codegen for straightforward algorithms using just python and no libraries.
This is very similar to the first round of an entry level coding interview
- Early stage interviews aren't exactly reflective of the actual job for software engineers. The interview is often about capturing the thought process, not just right/wrong. This dataset only captures the final answer.
- It's an interesting general benchmark, especially testing for generalization downstream
- It is likely somewhat out of the distribution from what coding LLM's and agents will do in a production setting. This might be good for teams to test generalization beyond their use-cases, but improved scores here definitely don't mean better performance for real-world use cases.
There is an opportunity to extend this work to more complicated problems, although that will come with higher creation costs upfront.
Specific Examples:
Some of these problems wouldn't be functions in a codebase, like these two:
def strlen(string: str) -> int:
""" Return length of given string
>>> strlen('')
0
>>> strlen('abc')
3
"""
return len(string)
HumanEval/23
def string_sequence(n: int) -> str:
""" Return a string containing space-delimited numbers starting from 0 up to n inclusive.
>>> string_sequence(0)
'0'
>>> string_sequence(5)
'0 1 2 3 4 5'
"""
return ' '.join([str(x) for x in range(n + 1)])
HumanEval/15
Some of the docstrings wouldn't be in a production codebase either. This one uses the docstring to fit a full word problem, whereas a normal one would summarize what the function does.
def numerical_letter_grade(grades):
"""It is the last week of the semester and the teacher has to give the grades
to students. The teacher has been making her own algorithm for grading.
The only problem is, she has lost the code she used for grading.
She has given you a list of GPAs for some students and you have to write
a function that can output a list of letter grades using the following table:
GPA | Letter grade
4.0 A+
> 3.7 A
> 3.3 A-
> 3.0 B+
> 2.7 B
> 2.3 B-
> 2.0 C+
> 1.7 C
> 1.3 C-
> 1.0 D+
> 0.7 D
> 0.0 D-
0.0 E
Example:
grade_equation([4.0, 3, 1.7, 2, 3.5]) ==> ['A+', 'B', 'C-', 'C', 'A-']
"""
HumanEval/81
Hassan Hayat on X has an analysis of the samples in this dataset worth checking out here.
Some examples may seem silly, but their diversity compared to the typical way code is documented means that researchers can get a sense of how generalized their models are, and how flexible they are to different types of prompting for code generation.
You can also view this dataset on Oxen here.
Takeaways for Teams using HumanEval:
Most AI coding products do not fit the exact specs of this dataset which we would define as: Function Completion for General Python algorithms, standard library only, with large variance in "production-readiness" and doc string quality
Many products need to use multiple libraries, languages, react to execution results, generate code across multiple functions/files, or take into account the context of a full repository. In some cases, they're not doing normal code gen, but making tests, creating docs, or summarizing/evaluating code.
Almost every single team out there will need a different dataset from this. However, using automated or manual methods that start with this dataset or one of its adaptations as the initial seed could be fruitful. It can get you up and running on a dataset that has some signal for your downstream tasks quickly, which has a big impact on overall velocity.
Other Infrastructure Learnings:
Human Eval is one of the first evaluations for Code LLM's out there. However, the infrastructure around it is still somewhat nascent. There are two main ways to run Human Eval: Generate your own answers and run the Human Eval scripts, or Bigcode-Bench.
Each has their own strengths and weaknesses. With Human Eval, you have to roll your own generation logic, but the code can be implanted into different libraries. It's old code so there might be bugs for your platform
Big Bench has support for multiple different Evaluation tasks, local inference for generations, and flexibility between generations and/or evaluations. However, it doesn't support SDKs like OpenAI, Anthropic, vLLM etc. which is how many people prefer to run models. It is fantastic for evaluation of pre-existing generations.
Neither of these solutions support batching of generations for faster inference, which has become the standard for online serving due to throughput increases. Benchmarks are batch workloads by default. Researchers and practitioners want to see the results of the full benchmark, not just single samples streaming in. A lack of batching hurts the iteration speed of improving your models, and increases compute costs too.
As we learned before, the normal completion API is important for properly prompting a lot of Open Source models for this task. The normal completion API is not supported by all of the providers. An example of this is Groq at the time of writing.
Per-Sample Analysis:
As we saw earlier, many things go into the final accuracy number result from benchmarking a model. There's a lot of power that comes from going through a dataset and your results with a fine-toothed comb. But none of the tools that I saw had this ability. The per-sample results were even thrown away in Bigcode-Eval.
To use this with Oxen, we had to build it ourselves on a fork.
There are other techniques like embedding analysis and clustering that allow for faster storytelling of where the model is missing, but they also require per-sample evaluations. Seeing more of this readily available would be great for the community.
Building on Top of Benchmarks:
Public evaluation benchmarks are often the beginning of a company's journey into evaluating their models. Public and Open benchmark solutions need to be building blocks but this is somewhat tricky given the fragmentation in the space.
There are two main frameworks for evals, BigCode, and lm-eval-harness, which don't have unified infrastructure or task set. There are also different tradeoffs like throughput (lm-eval supports, bigcode does not) versus the ability to execute code for evaluation.
Public Infra seems based upon standard prompts, but this is a large area of concern for companies to increase the accuracy, as sophisticated prompting, chaining, and RAG are making large impacts on the ability to ship a product.
The advanced libraries for prompting. etc. seem completely disjoint from these libraries, so most companies are likely building their own infra for this. There is definitely an opportunity for frameworks or the community to help them play nicer together.
Benchmarks as an Entry Point into AI:
Benchmarks are always appreciated by the community, and there is an incredible opportunity for new people to contribute. Many college students and early career folks would do well starting here to stand out in the job market. These benchmarks largely need to be created by hand - the hand-curation + insight into the problem is where the value is.
In the world of code modeling, there's an entire world of tasks to accomplish, and even those early in their career can be immediately helpful as they already have software experience.
We're still so early, it's such an exciting time.