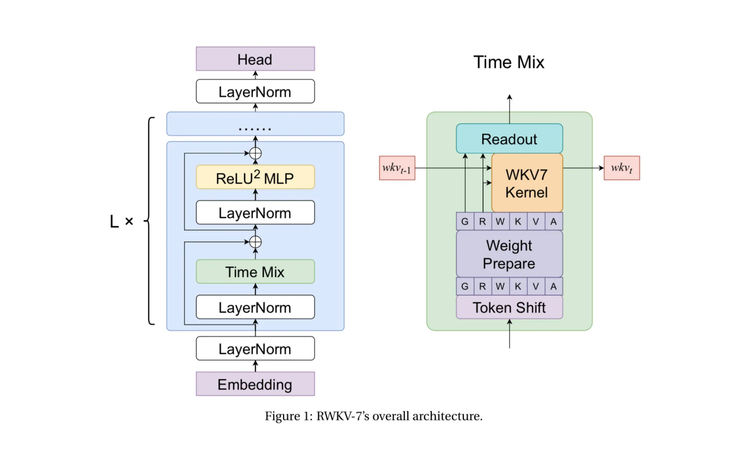
How RWKV-7 Goose Works 🪿 + Notes from the Author
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of
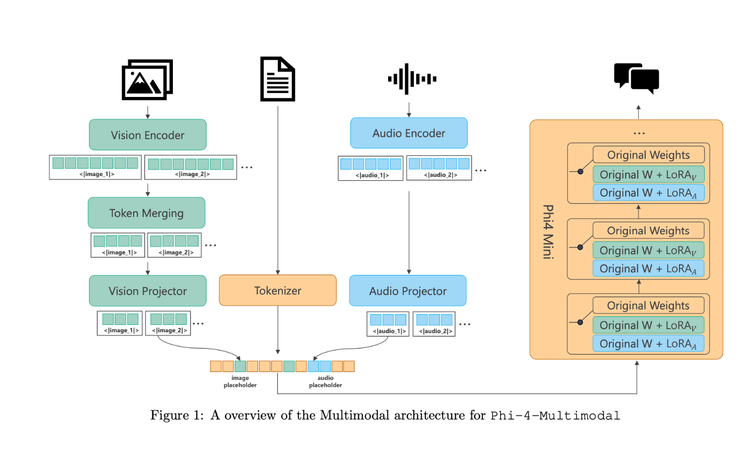
How Phi-4 Cracked Small Multimodality
Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means
Training a Rust 1.5B Coder LM with Reinforcement Learning (GRPO)
Group Relative Policy Optimization (GRPO) has proven to be a useful algorithm for training LLMs to reason and improve on
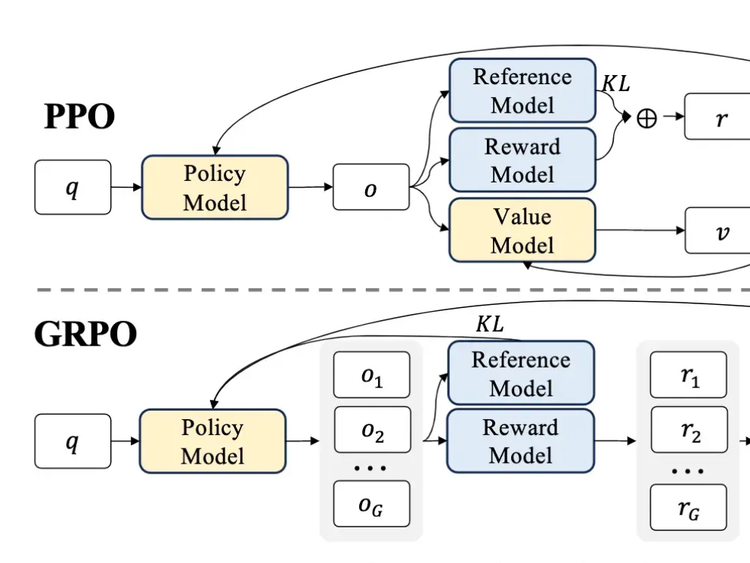
Why GRPO is Important and How it Works
Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use
🧠 GRPO VRAM Requirements For the GPU Poor
Since the release of DeepSeek-R1, Group Relative Policy Optimization (GRPO) has become the talk of the town for Reinforcement Learning
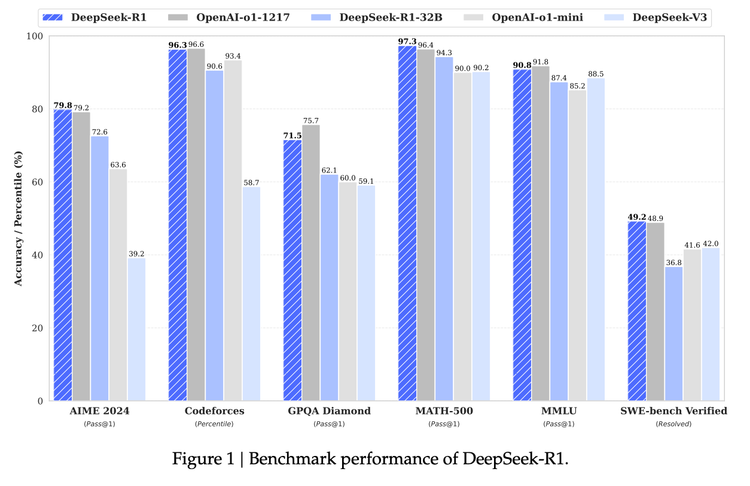
How DeepSeek R1, GRPO, and Previous DeepSeek Models Work
In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s
No Hype DeepSeek-R1 Reading List
DeepSeek-R1 is a big step forward in the open model ecosystem for AI with their latest model competing with OpenAI&
Oxen v0.25.0 Migration
Today we released oxen v0.25.0 🎉 which comes with a few performance optimizations, including how we traverse the Merkle
🌲 Merkle Tree VNodes
In this post we peel back some of the layers of Oxen.ai’s Merkle Tree and show how we
🌲 Merkle Tree 101
Intro
Merkle Trees are important data structures for ensuring integrity, deduplication, and verification of data at scale. They are used