
Create Your Own Synthetic Data With Only 5 Political Spam Texts [1/4]

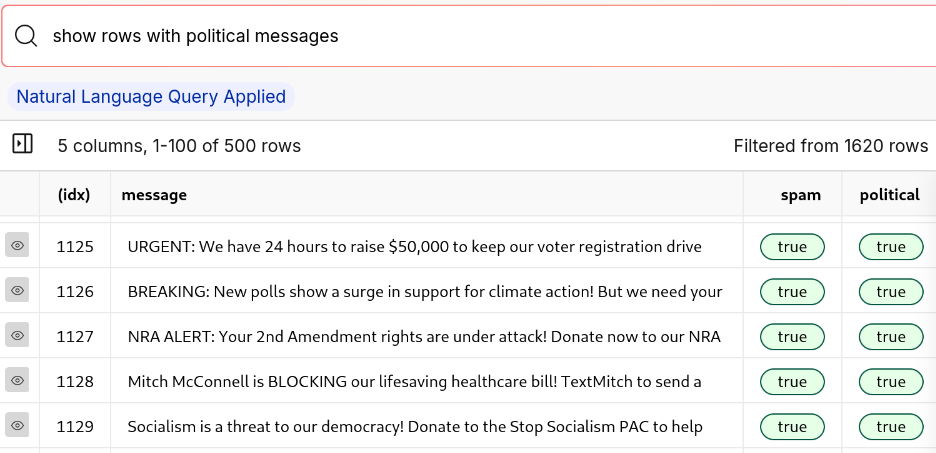
With the 2024 elections coming up, spam and political texts are more prevalent than ever as political campaigns increasingly turn towards texting potential voters. Over 15 billion political texts were sent in 2022 alone, and that number has been on the rise. This gets quite annoying after a while. The constant messaging has led many of us to ask the question, "Can't we block these texts with AI?"
So, what does it really take to detect and block spam? It seems like there should be several public datasets of spam to train on, but surprisingly, there are very few. The only dataset that comes up is the SMS Spam Collection, which we've nicknamed SpamOrHam. However, it's over a decade old and doesn't contain examples of political messaging.
So why not use our own spam texts? In the past a handful of data points was not enough to train a model, but we managed to create a diverse synthetic dataset by prompting Llama 3.1 405B using only 5 examples of political spam and a few examples of other types of texts. That way, anyone can replicate this experiment.
This is the first of a 4 part blog series. In the next 3, we will go over:
- How to De-duplicate and Clean Synthetic Data [2/4]
- Fine-Tuning Llama 3.1 8B in Under 12 Minutes [3/4]
- Evaluating the trained model
Download the Code!
To follow along with this post in code, you can get the notebook from the Oxen repo:
oxen clone https://hub.oxen.ai/Laurence/political-spamIf you don't already have Oxen, it's very simple to install.
Getting Started
To get started generating the data, we need several examples for each category. You only need a few examples, so you can use your own. We used 5 examples of political spam, 4 examples of regular spam, and 12 examples of legitimate text messages, but as long as you have at least a few of each it will work.

Setting up the Model
Next, we need to set up a model to generate synthetic data with. We used the Fireworks API:
client = Fireworks(api_key=api_key)
def generate_synthetic(system_prompt, user_prompt, examples):
examples_string = '\n\n'.join([f"### Example {n+1}\n{example}" for n, example in enumerate(examples)])
response = client.chat.completions.create(
model="accounts/fireworks/models/llama-v3p1-405b-instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": examples_string + "\n\n" + user_prompt}
],
)
return response.choices[0].message.contentSimple setup to generate the synthetic data
We also need system prompts. Using some basic prompt engineering, we came up with these:

The system prompt is exactly what it sounds like: the system prompt passed to the model. The user prompt, on the other hand, is simply appended to the end of the list of examples to create the full user message passed to the model.
To see the full prompts, you can look at the notebook, but here is a sample:
political_system_prompt = "You are an advanced AI language model trained to generate realistic synthetic data to train a spam detection system. Your task is to create examples of political text messages which are diverse and distinct from the examples given. You must create 5 such messages, separated by \"### Example n\" just like the examples. These messages should mimic the style and content of actual political texts, often characterized by alarmist language, urgent calls to action, solicitation of donations, dissemination of misinformation, or attempts to manipulate or deceive the recipient. The messages should cover various political stances and issues, and should be believable enough to resemble real-world political texts. Ensure the messages are diverse and cover various types of political texts which are missing from the given examples. Do not write anything before or after the examples."
political_user_prompt = "Based on these examples of political texts, generate synthetic data consisting of 5 more political texts. Make sure the data is as diverse as possible and covers a wide range of sides and campaigns, including any types of political texts which are missing from the examples. To make the texts as realistic as possible, use a variety of text lengths and messaging styles."The system and user prompt used for generating the political spam data
You can also download the notebook to try modifying the prompts and experimenting with how they affect the data generation.
Generating the Data
Finally, we can run the model!
for i in range(100):
random.shuffle(political_examples)
output = generate_synthetic(political_system_prompt, political_user_prompt, political_examples)
political_messages += parse_output(output)
print('.', end='')To see the full examples we used, download the notebook from the Oxen repo
Repeat this for each other type of message and you will end up with 3 lists of spam, non-spam, and political text messages.
Processing the Data
Let's save the data as a single parquet file.
all_messages = []
for message in political_messages:
all_messages.append({'message': message, 'spam': True, 'political': True})
# Do the same for the other message types
df = pd.DataFrame(all_messages)
df.to_parquet('texts.parquet')The code is in the Oxen repo
Because of the nature of how the data was generated, it's likely that there are duplicates in the data. In the future, we will want to remove them, but for now we just need to save the data.
Saving the Data
To make this easy, let's save the current data to an Oxen repo. This comes with the additional benefit that we will be able to revert to any past versions if we decide to undo an update to the data.
If you don't have an account, you can make one for free.
Creating a Repo
One easy way to create a repo is by using the Oxen Hub interface:
From there, we can clone the repo using oxen clone in a terminal and move texts.parquet into the cloned repo. If you don't already have the Oxen command line tool, it's very simple to install.
Committing the Data
After that, it's as simple as a couple terminal commands:
oxen add texts.parquet
oxen commit -m "Adding data"
oxen pushWhat Next?
Now that we have this data, we can train models on it! But not so fast - the quality of the data is important. In the next post, we will discuss how to filter the data to increase model performance and reduce training costs.
Why Oxen?
Oxen.ai makes building, iterating on, and collaborating on machine learning datasets easy.
At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. On top of that are features that make working with data easier such as data diffs, natural language queries for tabular files, workspaces, rendering images in tables, and more. We're constantly pushing out new features to make things easier for you. Oh yeah, and it's open source.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Member discussion