
How to De-duplicate and Clean Synthetic Data [2/4]

![How to De-duplicate and Clean Synthetic Data [2/4]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/size/w960/2024/08/blog-copy.jpg)
Synthetic data has shown promising results for training and fine tuning large models, such as Llama 3.1 and the models behind Apple Intelligence, and to produce datasets from minimal amounts of data for personal use (like what we're doing in this blog series). While there are many open source datasets available, there is still a need for personalized data and data for more specific use cases.
In our last blog, we used only 5 political spam texts to generate a dataset to fine tune Llama 3.1 to detect political spam. The next step, which we will dive into in this blog, is to filter down the synthetic data to improve the data quality before fine-tuning a model. We will also take a peek into the resulting data, so make sure not to miss that!
This is the second of a 4 part blog series:
- Create Your Own Synthetic Data With Only 5 Political Spam Texts
- This blog post!
- Fine-Tuning Llama 3.1 8B in Under 12 Minutes [3/4]
- Evaluating the trained model
Download the Code!
To follow along with this post in code, you can get the notebook from the Oxen repo:
oxen clone https://hub.oxen.ai/Laurence/political-spamIf you don't already have Oxen, it's very simple to install.
Viewing the Data
First, let's load the data generated in the last blog post.
texts = pd.read_parquet('texts.parquet')
political = texts[texts['political'] == True]
political.reset_index(drop=True, inplace=True)
political.describe()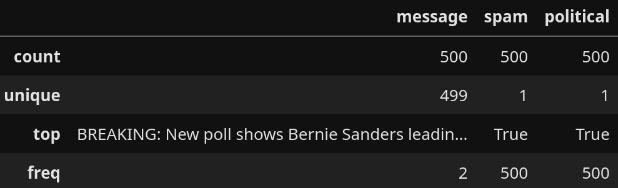
This is promising so far. There is only one word-for-word duplicate among the political spam messages. Let's see what the political leanings of the spam texts are.
Testing the Political Bias
To check how balanced the dataset is, we will use a model fine-tuned from BERT. While it isn't completely accurate, it will run quickly and it should give us a good picture of the data distribution.
def bias(text):
# The full code used for loading and
# running the model is in the Oxen repo
# add bias columns based on prediction
political[['left_bias', 'center_bias', 'right_bias']] = political['message'].apply(lambda x: pd.Series(bias(x)))
# find the bias with the highest predicted value
political['predicted_bias'] = political[['left_bias', 'center_bias', 'right_bias']].idxmax(axis=1)
# count number of messages with each bias
bias_counts = political['predicted_bias'].value_counts()To get the full code, download the notebook from the Oxen repo
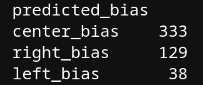
There is clearly a bias towards right and center leaning spam. The number of center leaning spam messages seems hard to believe, so let's print out some of the center leaning texts.

Some Interpretation
- It seems like we have a good baseline of at least 38 left leaning messages, so the dataset is not completely unbalanced.
- Messages seem to be often mistagged as center leaning, so we most likely have well over 38 left leaning messages.
Filtering Similar Messages
Next, we can find very similar messages and deduplicate them. We used the SentenceTransformers library to load the 400 million parameter version of Stella and calculate embeddings for all the texts.
message_embeddings = embedding_model.encode(messages)
similarities = embedding_model.similarity(message_embeddings, message_embeddings)
# put similarities into a df
similarities_df = pd.DataFrame(similarities, index=political.index, columns=political.index)The full code is in the Oxen repo
This gives us a dataframe of similarity scores. Now we can simply loop through, find pairs which are highly similar, and drop one of the two. We used a similarity threshold of 0.9.
to_drop = set() # to store the indices of the duplicates
for i in range(len(similarities_df)): # Loop through rows
for j in range(i + 1, len(similarities_df)): # Loop through columns
if similarities_df.iloc[i, j] > similarity_threshold: # Check similarity
to_drop.add(j) # add index of the second message onlyGreat! Let's see how many messages we have left.

We lost about 20% of the texts in this filtering, which is not bad at all. The filtering can easily be made more or less aggressive with the similarity threshold parameter.
Re-checking the Political Bias
The original results showed more spam messages from the right than the left. Let's see how much that changed.
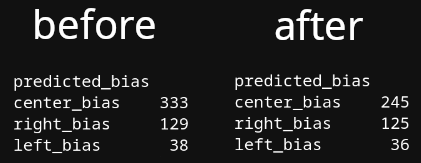
Most of the items that were removed for similarity were considered center bias by the model, which tells us very little information because the model incorrectly labeled many things as center bias. However, it's a good sign that we still have a reasonable number of left and right leaning texts.
Filtering the Rest of the Data
That worked well, so let's filter the rest of the data. Let's start with the regular spam:
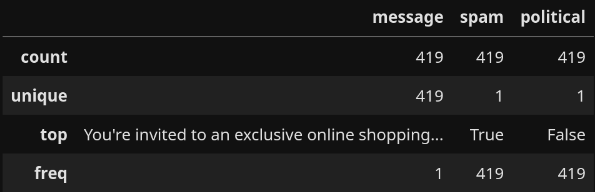
We started with 620 examples of spam and filtered it down to 419. This works out, though, as it leaves us with a similar number of regular spam and political spam texts. Next, let's filter the ham:
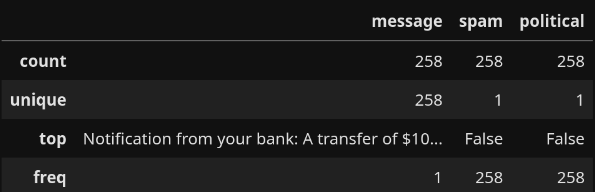
It appears to be the case that the model had trouble coming up with unique ham more than unique spam. That's rather interesting.
Looking at the Data
Let's take a look at the filtered synthetic messages.
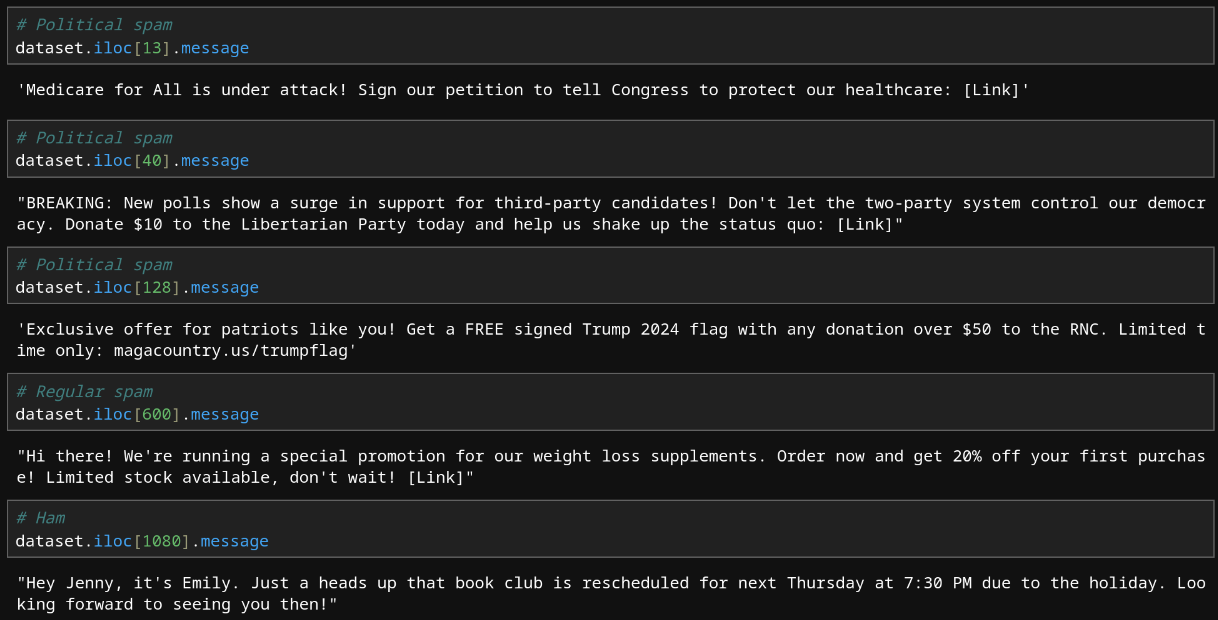
These look good. There is still some repetition in the texts, but not as much as before the filtering. If you want to see for yourself, we encourage you to look through the data! Oxen's natural language query feature for tabular files, also known as Text2SQL, makes it easy to search through the data. You can view the file with the synthetic data here and look through the data by entering natural language queries if you are logged in. Making an account is free, so we highly recommend trying it out!
Here's an example query we ran on the filtered data:
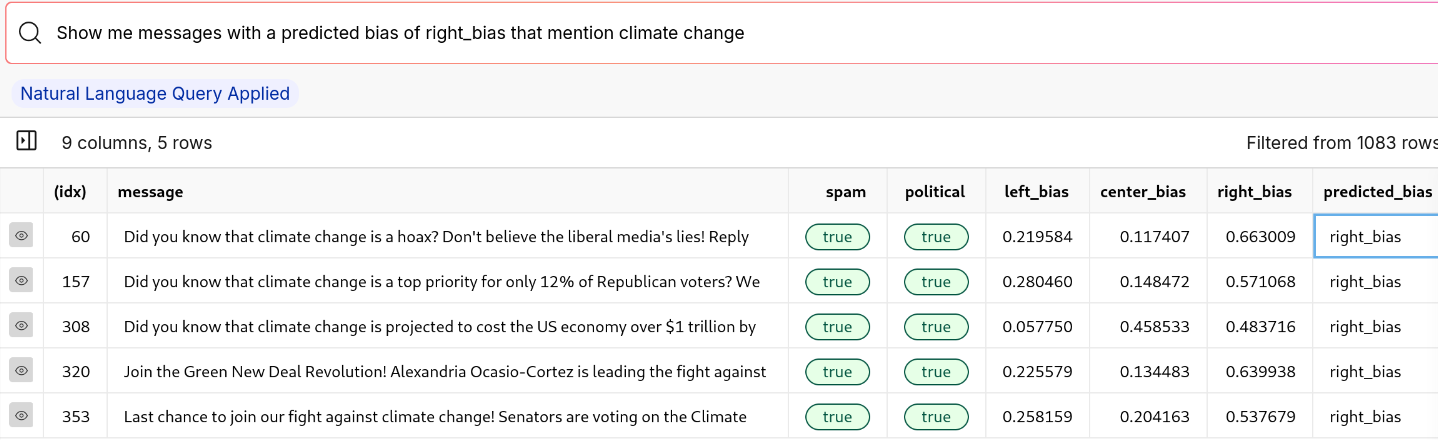
This also makes it easy to test where the model made mistakes. For example, we can see that some of the messages predicted right_bias were labeled incorrectly. If we were iterating on a model to predict political bias, we would be able to see where its weak points were using this method.
Conclusion
The data generated in the last blog post had a high level of diversity thanks to the prompting and the multiple examples used. Additionally, our choice of examples was mirrored in the final dataset. The fact that we only had one example of a spam text from the Trump campaign in the initial data is most likely what caused the model to generate many right-wing spam texts, attempting to compensate for the imbalance but severely overcorrecting.
What Next?
Now that we have this data, we can train models on it! In the next post, we will discuss how to fine-tune Llama 3.1 8B on the cleaned data to detect political spam.
Why Oxen?
Oxen.ai makes building, iterating on, and collaborating on machine learning datasets easy.
At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. On top of that are features that make working with data easier such as data diffs, natural language queries for tabular files, workspaces, rendering images in tables, and more. We're constantly pushing out new features to make things easier for you. Oh yeah, and it's open source.
If you would like to learn more, star us on GitHub and head to Oxen.ai and create an account.
Member discussion