
How to Fine-Tune PixArt to Generate a Consistent Character


Can we fine-tune a small diffusion transformer (DiT) to generate OpenAI-level images by distilling off of OpenAI images? The end goal is to have a small, fast, cheap model that we can use to generate brand images like the one below.
Here is the video if you want to watch along with the blog:
Want to try fine-tuning? Oxen.ai makes it simple. All you have to do upload your images, click run, and we handle the rest. Sign up and follow along by training your own model.
The formula 🧪
Each week we take an open-source model and put it head-to-head against a closed-source foundation model on a specialized task. We will be giving you practical examples with reference code, reference data, model weights, and the end-to-end infrastructure to reproduce experiments on your own.
If you missed last week, we are going to keep the formula pretty consistent and simple.
- Define our task
- Collect a dataset (train and test sets)
- Eval an open-source model
- Eval a closed-source model
- Fine-tune the open-source model
- Eval the fine-tuned model
- Declare a winner 🥇
My goal is to give you a framework to think about these problems in the age of LLMs. It’s tempting to dive right into the fine-tuning, we have to make sure it’s actually worth it over a base model or foundation model. If we don’t have a frame of reference for what we are optimizing for, you are wasting GPU cycles and $.
The Task

For context, we have been trying to get a consistent brand character for Oxen.ai for a while, all to no avail. We actually tasked an early employee of Oxen to do this and it is fun to look back at the old results.

We wanted a cute, white, fluffy ox that could be used for things like our 404 page. This is the one we settled on from the first batch of generations. I think he was originally from one of the early Midjourney models.
Since then, we have been taking him and using the latest OpenAI’s latest gpt-image-1 model. With the right prompt and reference image OpenAI gpt-image-1 model does pretty well at putting the character in new scenarios.
But as you can see from my ChatGPT library, it is by no means perfect.

Some oxen look too young, some look too old, and if you tweak the prompt slightly, you can get wildly different results. It is also super slow to generate images (40-60 seconds each) and often puts a yellowish tint to the images, which I personally don’t love.
Quick Demo of Results
To motivate the work, let’s run our final model live to show you the consistency we achieved:
https://www.oxen.ai/ox/Oxen-DiT-Training/file/main/notebooks/inference-DiT.py


Choosing the Character
Let’s return to the image we love and start with that as a reference.
Other than him being a little sleepy (or high as our team has joked) he has a pretty solid texture and overall character.
The next thing I did was to ask ChatGPT to give a descriptive prompt of this image that we can feed back in. I found that if you do not give a lot of detail in the prompt, the image gen can go off the rails pretty quickly (as we saw with all the images above)

With a reference image and a descriptive prompt, we are off to the races to create some synthetic data.
(I got a less high ox that I want to try it with, but wanted to prove out the end-to-end first)
Synthetic Data
One of the best things that ever happened to fine-tuning small models is having large models at our fingertips via APIs.

The next experiment I wanted to run was: “Given our descriptive prompt and reference image, can we create a dataset of semi-consistent characters?”
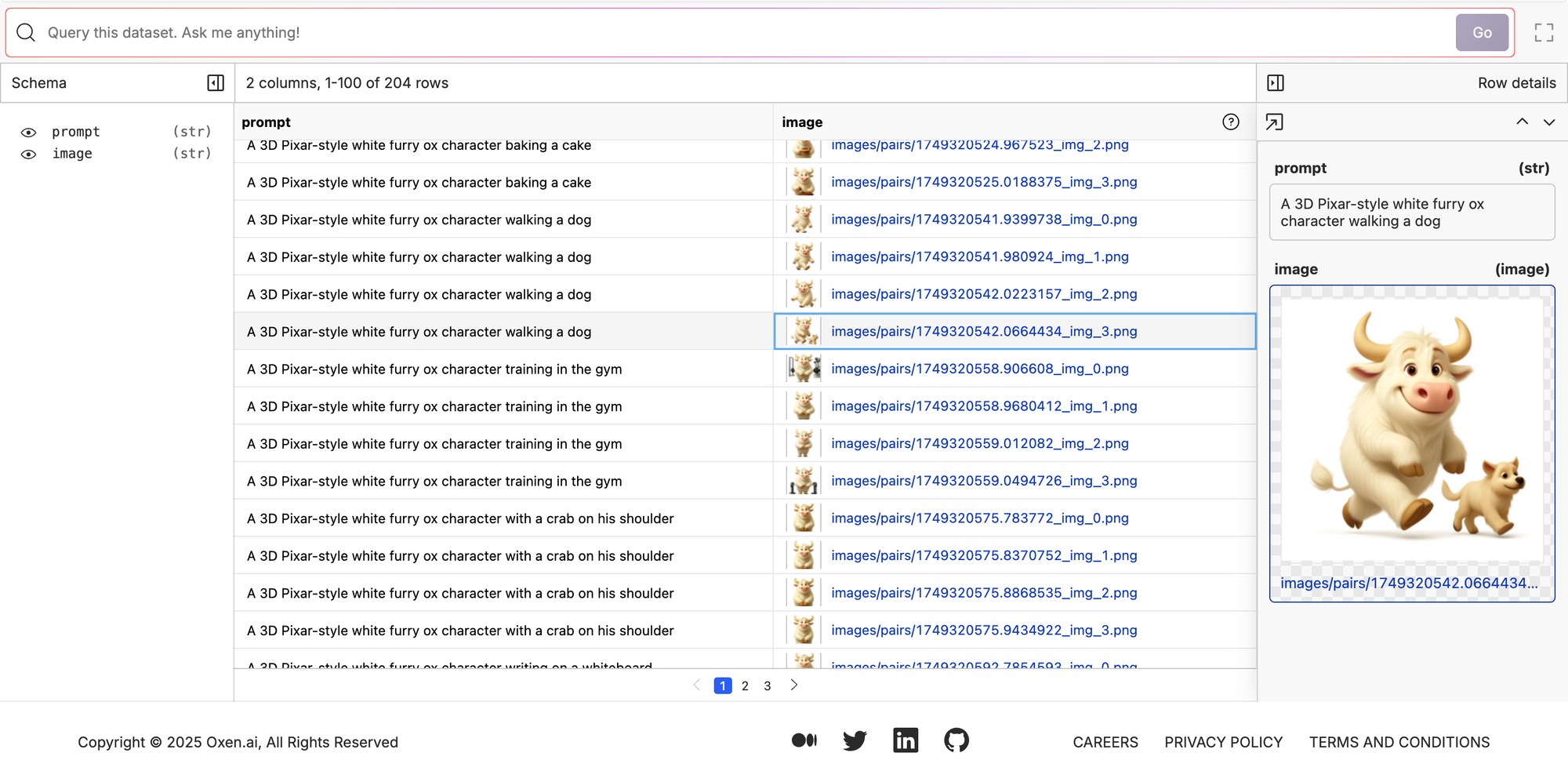
This is probably the most practical part of the dive. I was pleasantly surprised with the results of putting the two assets together. Let’s take a look at the training data before I show you how I generated it.
Look at our handsome boy putting together a penguin puzzle. If you click through the results a bit, you’ll see we have a pretty consistent character doing a variety of actions!
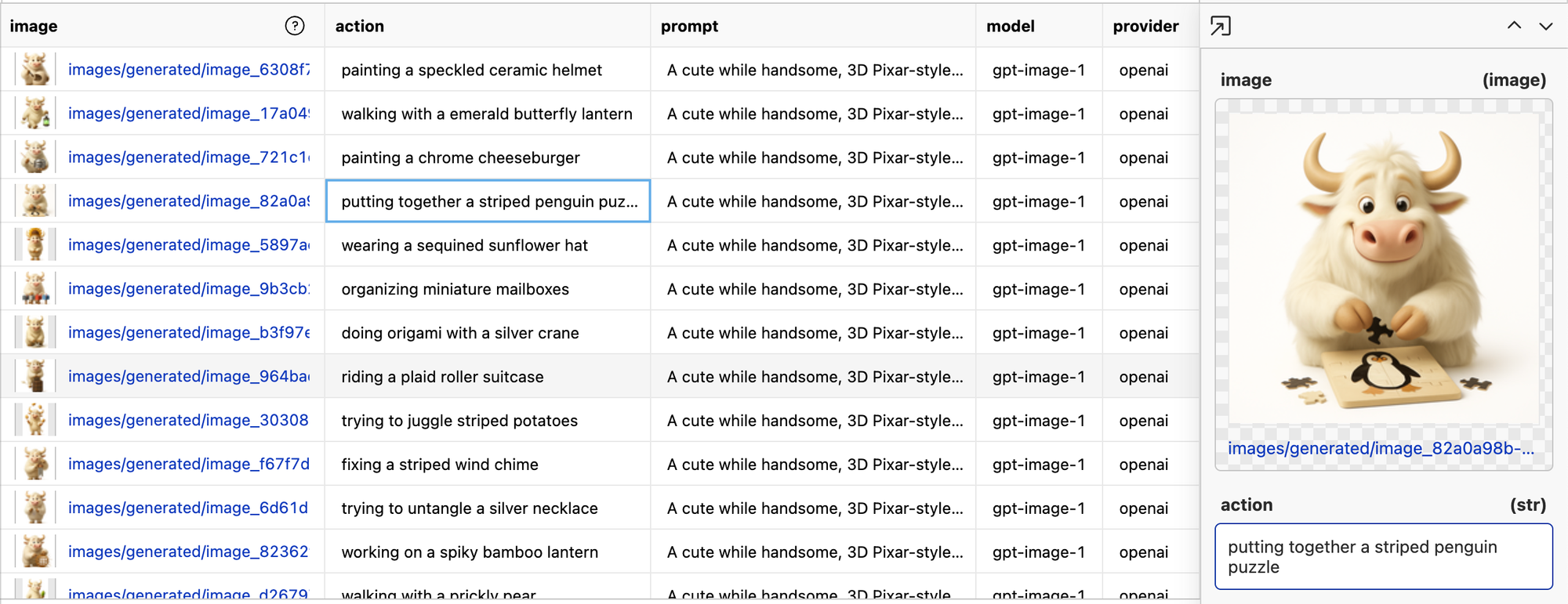

Now let me walk you through how I got these to be so consistent.

The Basic Loop:
- Generate a list of actions
- Generate image with reference + descriptive prompt
Overall to generate ~2k images it costs about $100 dollars of OpenAI credits.
Honestly, we could have called it a day at this point. We have some pretty solid characters. We should really ask ourselves: “If OpenAI does the job, then why are we fine-tuning at all?”
There are a few reasons:
- Cost: It is cheaper to run a model where you own the weights
- Customizability/Consistency: As you can see, not every character is that consistent or the vibe we want. The plan is to use RL to sand off these fine edges.
- Content Moderation: Sometimes API calls get rejected due to “content moderation”. I’m not doing any NSFW things with these prompts but I still get it every 1/50 or so…maybe because I say “Pixar-like”
- Speed: Waiting a minute for responses breaks you out of your creative exploration flow. We can generate images in < 2 seconds with our fine-tuned model. There’s a world in which we could even shrink it further and extend it to video with the right dataset.
- Most of all: It’s freaking fun.
My hope is that if we can supervise fine-tune a model that is decent at generating images, we can use GRPO and RLVR to sand off the rough edges.
The Model
Now that we have a pretty solid starter dataset, we need to choose our contender. I have the most experience and luck fine-tuning PixArt-alpha. We did a deep dive on this model about a year ago, and I’m sure that there are newer models - but PixArt is a good balance of speed of training and expressivity in a model.

Just to give you a feel of the speed of training from scratch, this is from the paper:
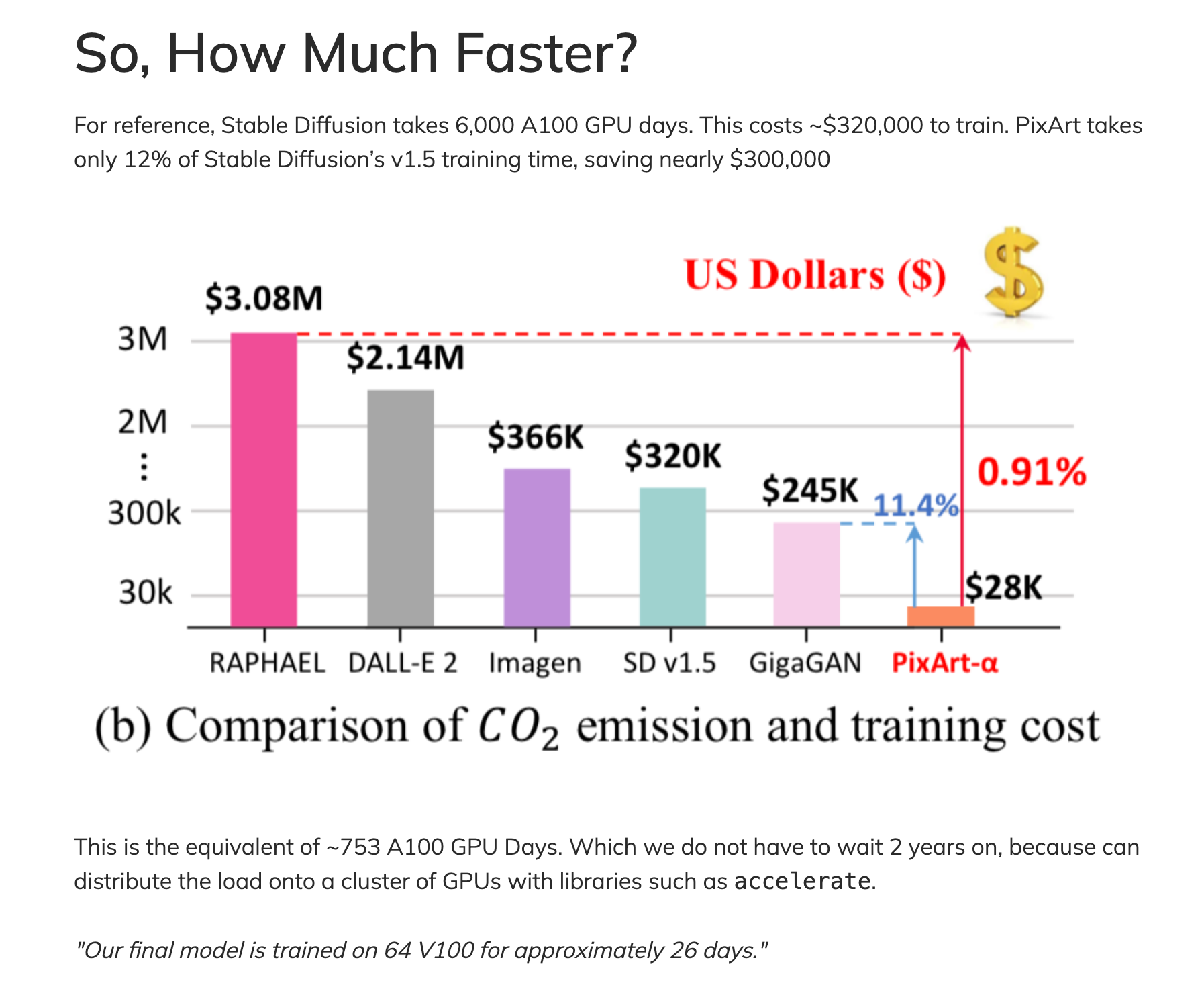
We will not be doing a full training run, and by no means have $28k to burn. We will be able to do our experiments starting with their pre-trained model and using parameter efficient fine-tuning to get us a decent model in under an hour on an H100.
The Evaluation
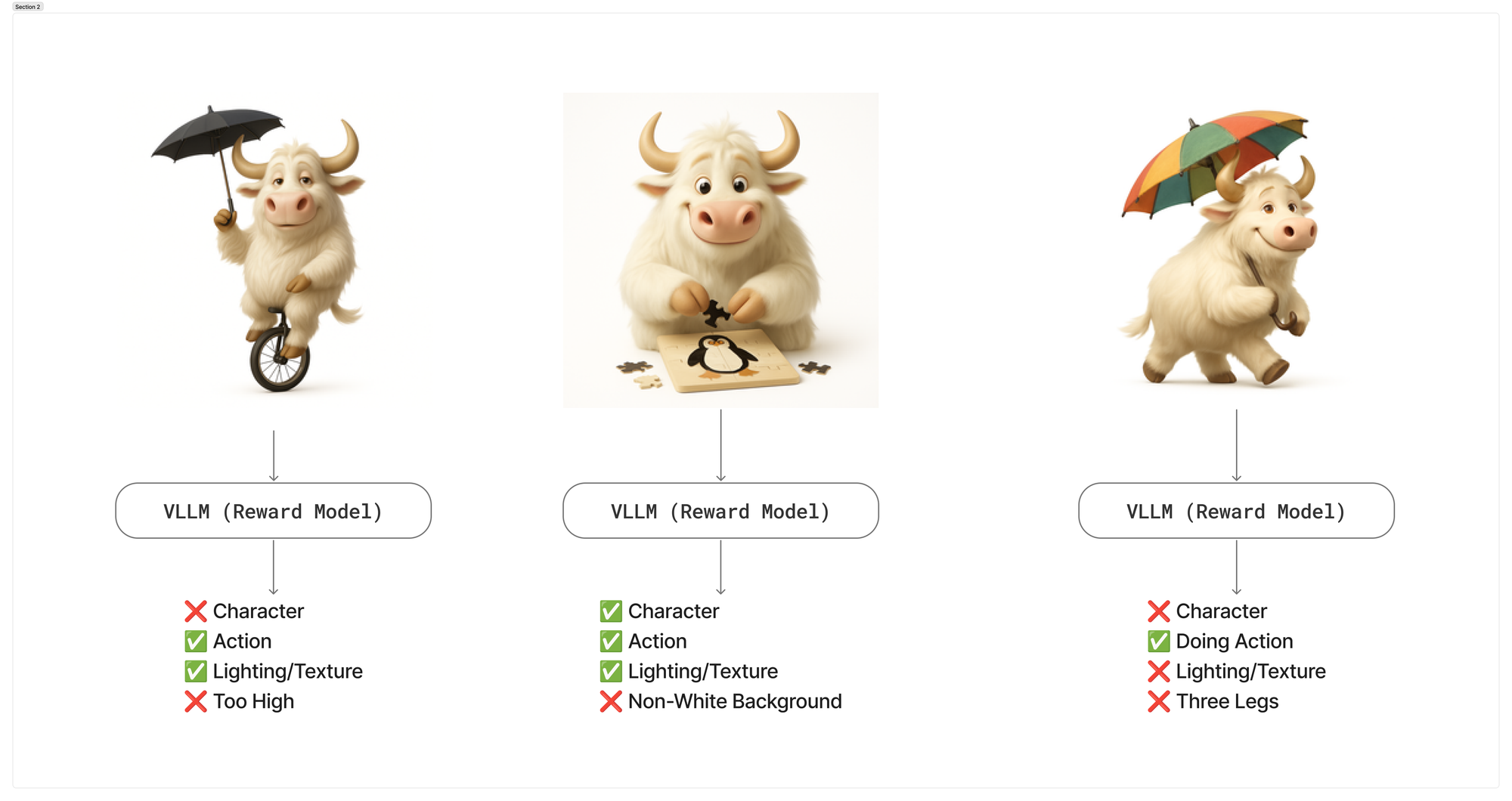
Image generation evals are usually pretty vibey. Look at your prompts, look at the outputs, and gut-check if this is what you want. It’s hard to get a concrete metric without labeling every single image 👍/👎. Even then - which part of the image was right? What was off about it? Was everything good besides the fact that the Ox had 5 legs?
One of my theories is that we can get a VLLM to be the judge of these images. If this is true - then we can in theory kick off our RLVR loop and slowly improve our model over time.
To test this theory out, I collected a dataset of 50 prompts that we have used for past blog posts. We’ve experimented with different styles for the blogs in the past, but want to get more consistent with our branding (no oxen were harmed in the branding exercise 😉).


Eval The Strong Model
To start, we just need to run OpenAI on our test dataset.

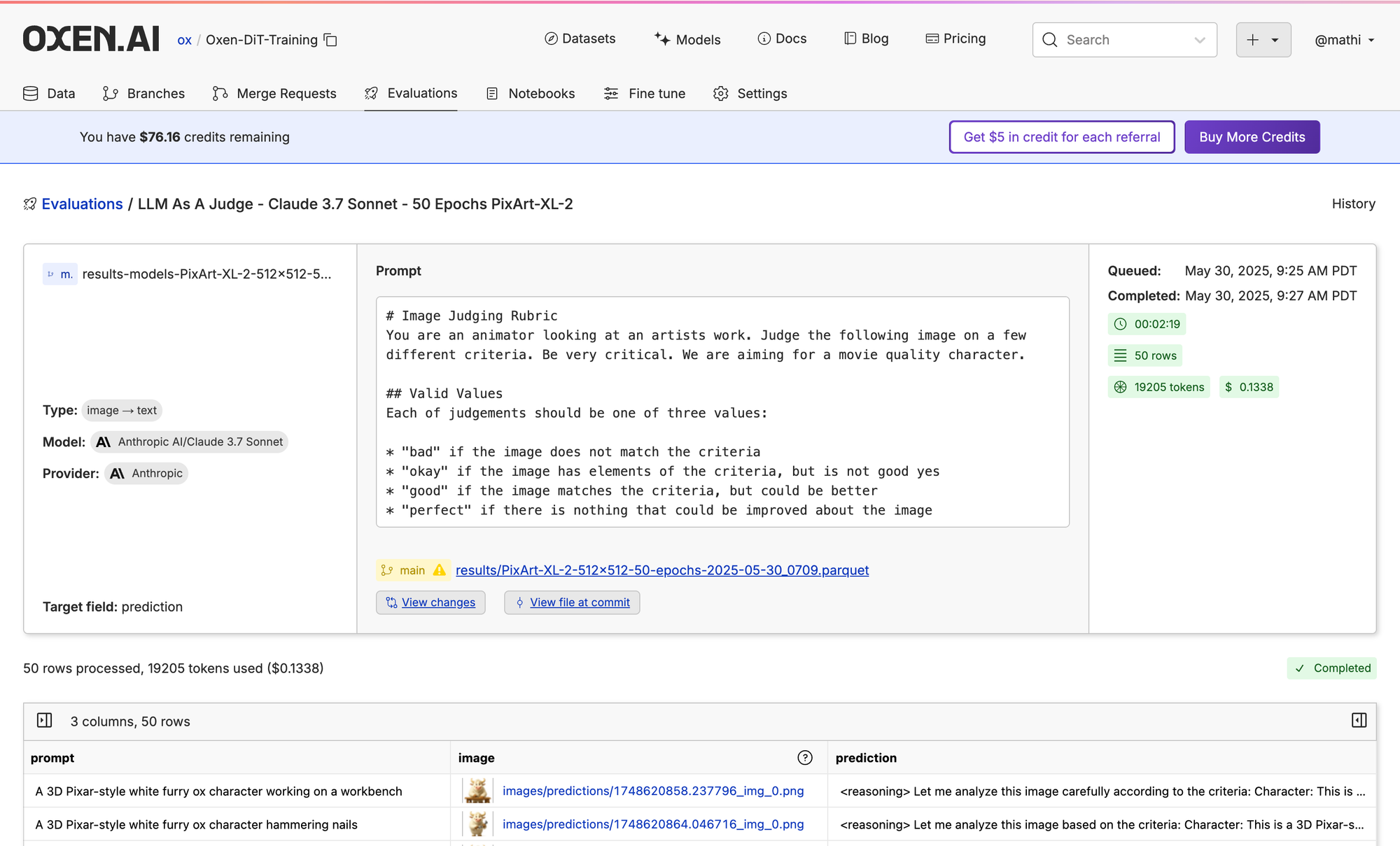
Let’s start by seeing how well a VLLM can judge the images that were generated with OpenAI. We put together a pretty extensive prompt that will judge the image on many criteria. What’s nice about this is that, in theory, you can describe what you want in plain english and the RL loop will optimize for it.
We will be using Claude 3.7 Sonnet to judge the images since it was not used in the generation.

# Image Judging Rubric
You are an animator looking at an artists work. Judge the following image on a few different criteria. Be very critical. We are aiming for a movie quality character.
## Valid Values
Each of judgements should be one of three values:
* "bad" if the image does not match the criteria
* "okay" if the image has elements of the criteria, but is not good yes
* "good" if the image matches the criteria, but could be better
* "perfect" if there is nothing that could be improved about the image
## Criteria Descriptions
The criteria in which the image should be graded on are as follows:
character:
Is the character a 3D Pixar-style white furry ox?
task:
Is the character performing the task described?
objects:
Are all the necessary objects in the scene? Is there anything wrong with them? Do they look realistic?
expression:
Is the character's expression wide open and happy, with a visible spark of joy or engagement, conveying satisfaction in the activity?
texture:
The fur must show clear texture and depth, with soft lighting that avoids harsh shadows or bright highlights.
coloring:
The fur must NOT contain any yellow or sepia tones. It should be a shade of white with a tone as if it lives in the arctic or himalayas.
background:
The entire background must be pure white (#FFFFFF) with no visible gradient, vignette, or objects other than the ones specified in the prompt.
## Return Format
Return the judgements in xml format. The xml should contain the criteria name in the tag. An example response looks like this:
<reasoning>Your reasoning</reasoning>
<character>good</character>
<task>bad</task>
<objects>bad</objects>
<expression>perfect</expression>
<texture>perfect</texture>
<coloring>good</coloring>
<background>perfect</background>
Reason through your thoughts step by step before responding. Put your thoughts in the <reasoning></reasoning> tags.
## Inputs
Prompt:
{prompt}
Image:
{image}
Let’s take a look at some of the outputs to see what we are working with. In general, these images a pretty good, so we may need to see how it does on our fine-tuned model.
OpenAI’s gpt-image-1
Fine-Tuning
Okay! Here’s the fun part. Let’s boot up a Marimo notebook on a GPU and do our fine-tuning. To get a feel for the speed, we can do an entire run through the 2k examples for 5 epochs on an H100 in under ~8 minutes.
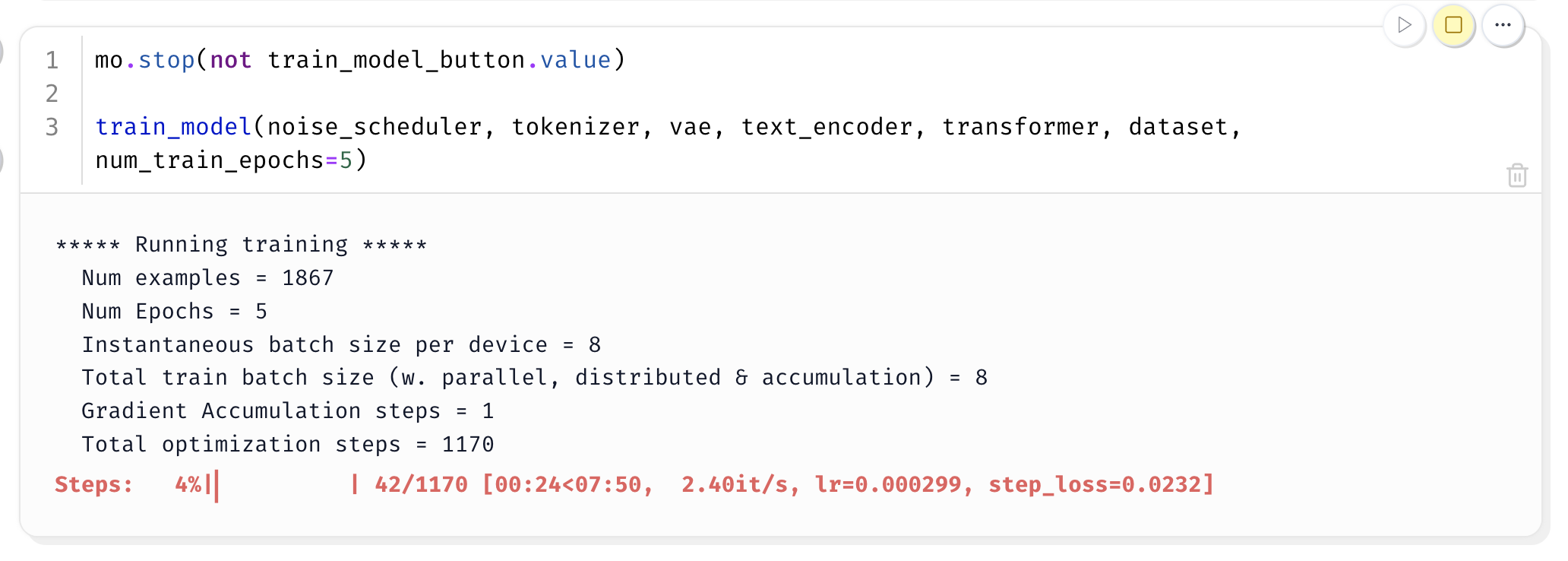

Quick side note: Something else I love about Marimo is that you can add one of these run buttons. Since all the cells are connected in this graph, I can load up a model and pause the execution of lower cells so I can work on my script while the model weights are being loaded to memory. This is so much better than running this in a regular python file where I would need to wait a couple minutes and reload the model weights every time I rerun the script while I'm debugging.
Anyway, remember, all diffusion models are doing is trying to predict noise that is added to an image, so that we can slowly remove the noise from the image.

The Architecture
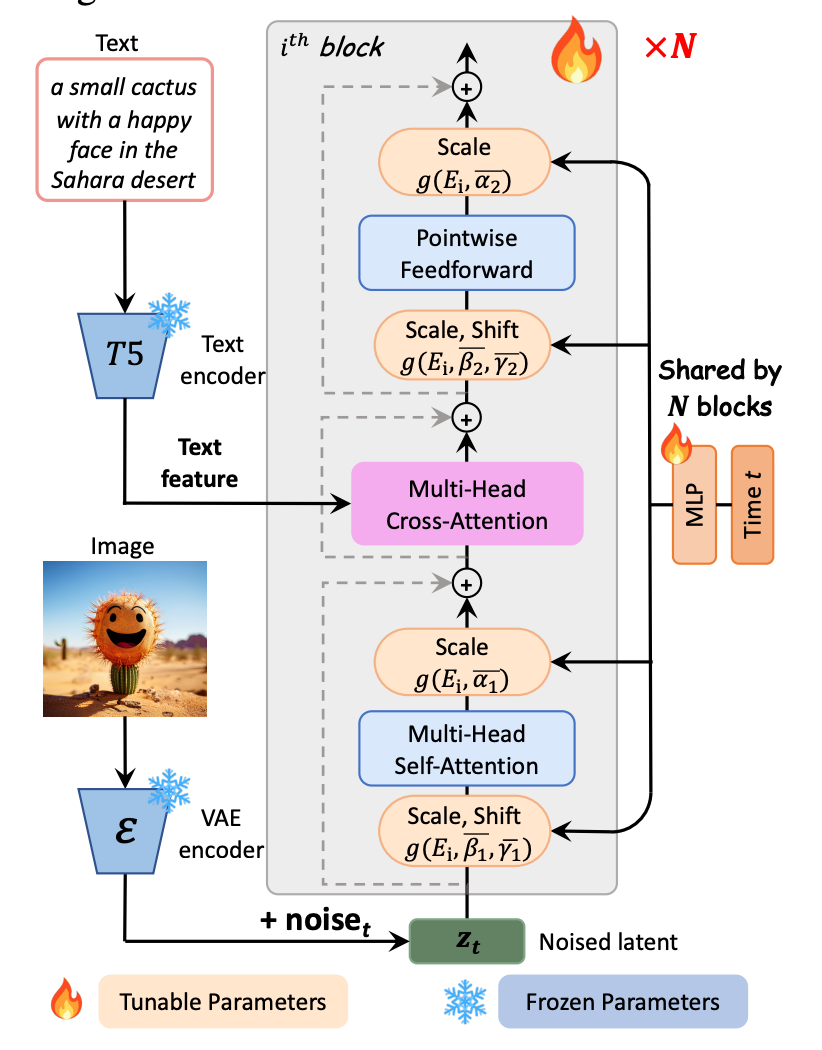
This is a quick look into the architecture (if you want a deeper dive look here).
As you can see there are a few moving parts, there is the text encoder, variational autoencoder (VAE), and the DiT itself. The text encoder is a pre-trained LM called T5 by Google that encodes the text input. The pre-trained VAE is an autoencoder that basically takes an image, compresses it down to a latent space, and then tries to reconstruct the same image. So you can pre-train a VAE just on a variety of data without labels, which is pretty great.
Below, if the parameters are in blue they are frozen parameters, the ones in orange are the ones we are going to tune. So the things we actually tune are within the transformer and we're going to do a LoRA.
Our fine-tuning code will then dump the LoRA weights in a branch for us to test out on the same test set we used before.
Loading the Model and Data
So we start by loading the noise scheduler, text encoder, tokenizer, VAE, and transformer model:

Then decide which parameters we want to fine-tune. I'm just using the parameters that the Pixart repository suggested you tune, but you could only fine-tune the linear layers, keys, values, and queries if you wanted.

This load model function will return our noise scheduler, tokenizer, VAE text encoder, and transformer. You can see we have 13 million trainable parameters from a 600 million parameter model. So it's 2% trainable parameters, which makes this a really lightweight quick training job.
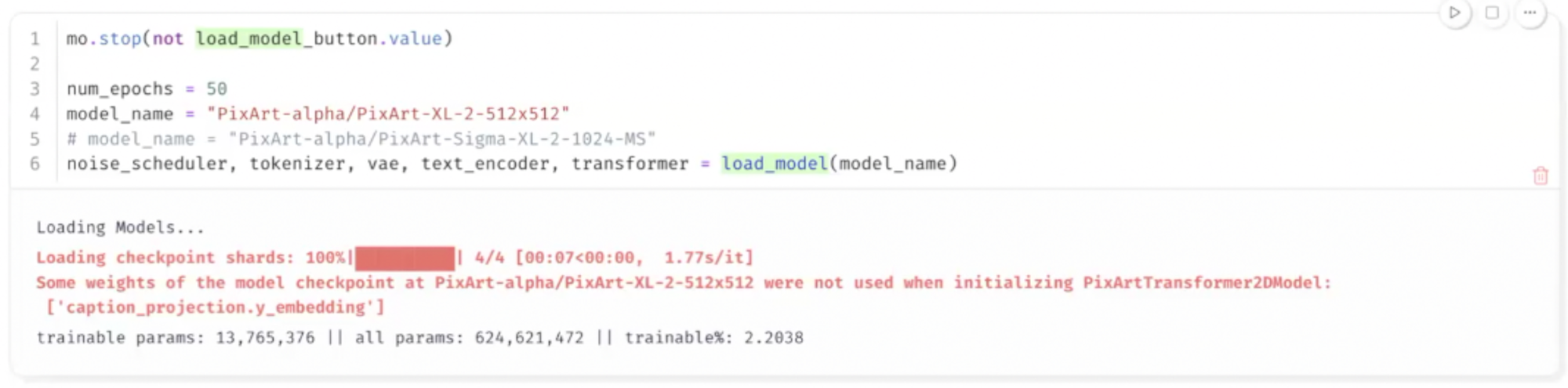
To load the transformer I use get.peft(transformer), give it my LoRA config, and then I get out a transformer that's kind of like wrapped in that parameter efficient, fine-tuning.
I'm also gonna kick off the loading of the dataset, which is gonna go and download all of those images, download our training.parquet file, and put all of that kind of together in a way that we can load into our training loop. We have a few data processing functions, combining the inputs and outputs that we want, and tokenizing the images.
One thing to note, you'll notice that the training data itself had just this action right here.
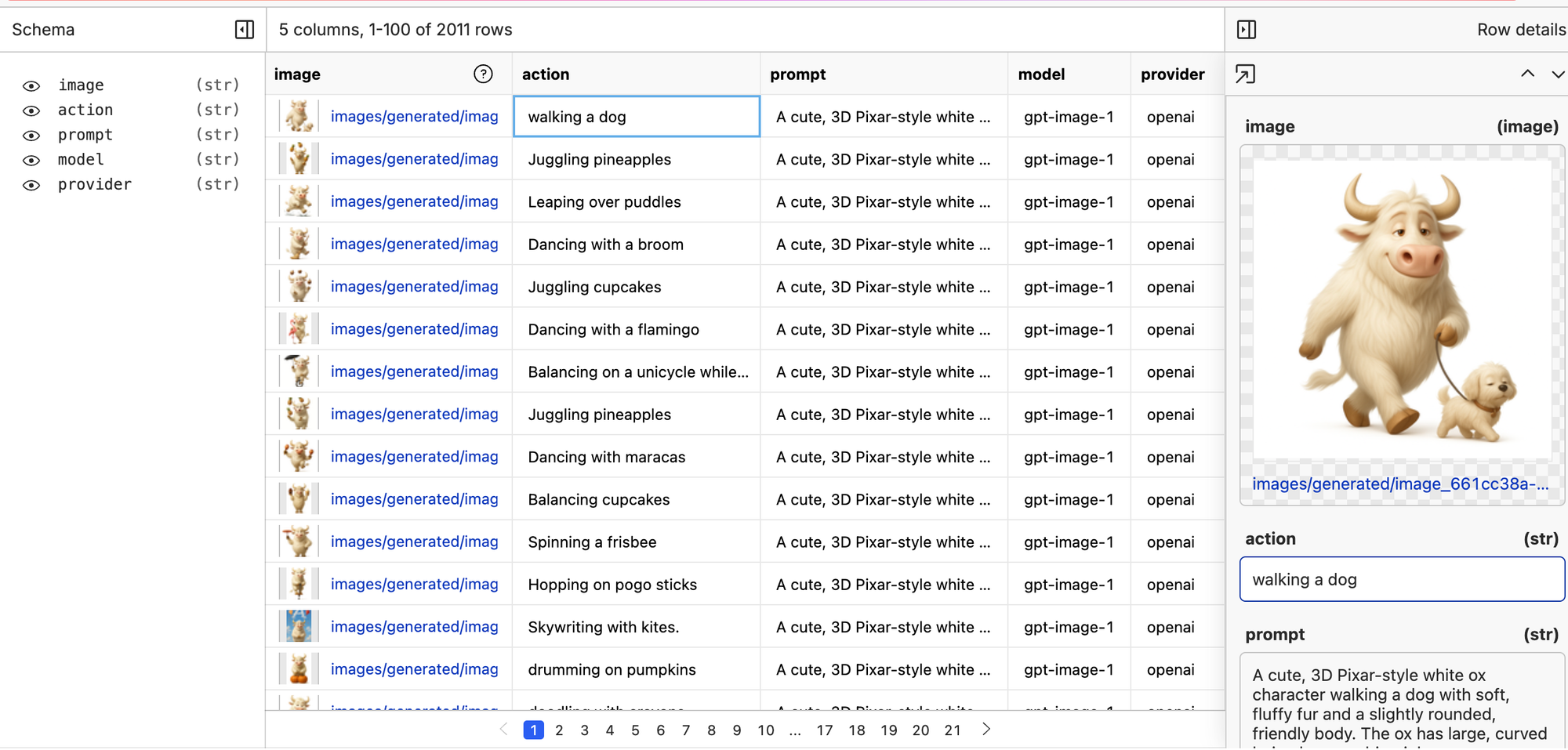
So it has a column for the action, which is like "walking a dog" but we put this in the context of another trigger prompt (the 'prompt' column to the right of action). So the user input is just the action and we have full control of the main prompt the LLM is receiving. Constraining it to just the action that we want the ox to do is nice for a branded image generation model because we can have the team just type in the actions and not really have to worry about all of the other verbiage on the side or the model going off the rails because one team member had different verbiage than another.
The Training Loop
Looking at the training loop itself, we take in our noise scheduler and all of these different components of the model and we have to wire them together in this loop to slowly train the model over time.
While the PIXART model already has all of the component models, like VAE, text encoder, etc. for the sake of seeing things under the hood here and how they all tie together I've loaded them separately which will also help us in the reinforcement learning step, which we're going to do in the future.
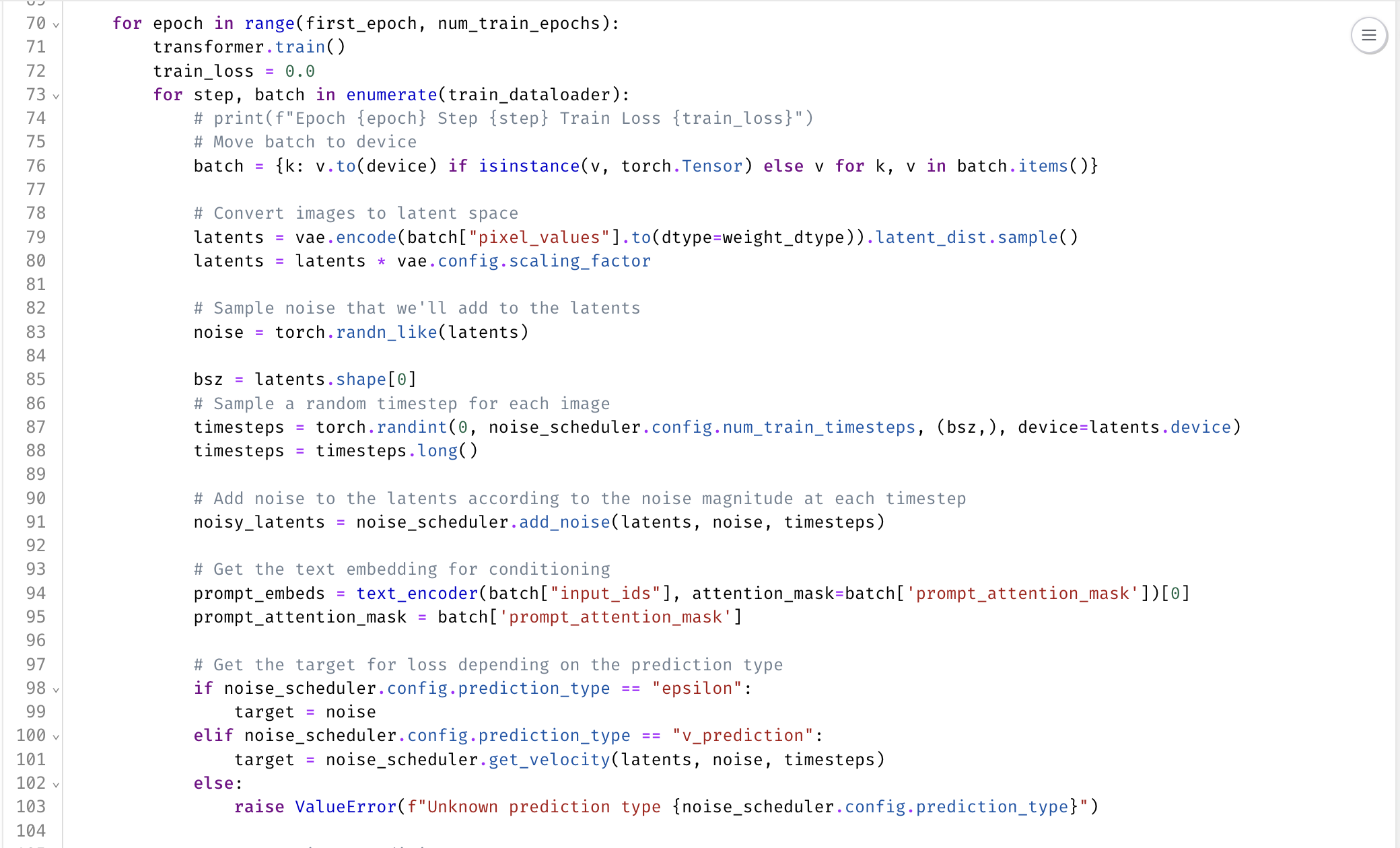
A lot of this is just setting up how many epochs we want to run and the training batch size. We iterate over our training data loader that is gonna be loading all of those image and prompt pairs. We'll get a batch out. In this case, I was using a batch size of eight which, depending on how much GPU VRAM, can be larger batch sizes if you want. Marimo is also nice because it has these indicators at the bottom so you can see how much, GPU VRAM, CPU, and memory we're using.
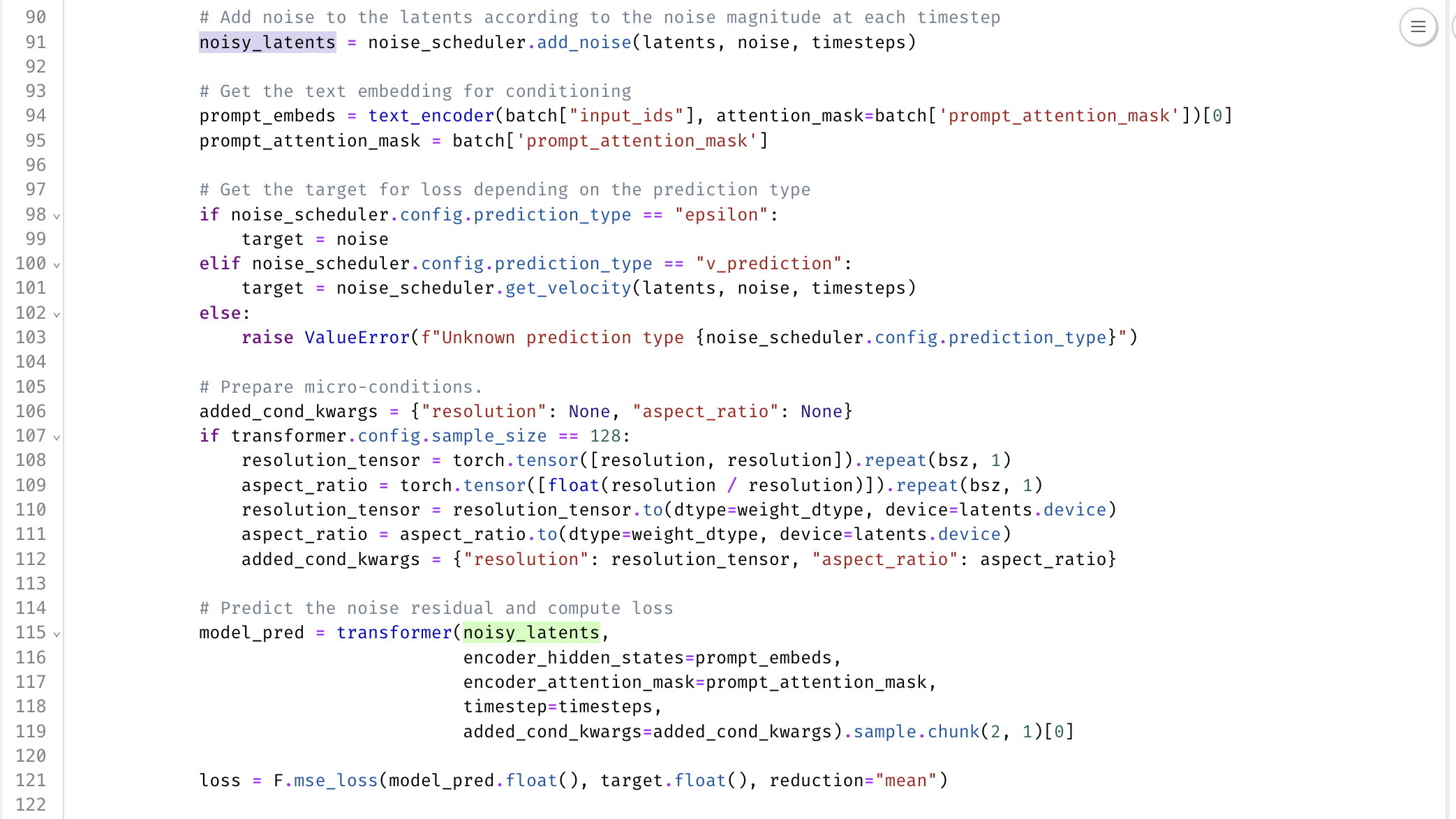
We'll then take in that batch and extract the pixel values from it and run that through the VAE to get out all of our latent parameters. The first thing that you wanna do while you're training is sampling a random timestamp for each one of these passes and add that amount of noise to the image.
So during inference, we do go from very noisy all the way to the image, but during training, you sample a random step, add that much noise, and then ask the model to predict that noise from there. So here we're getting the noise, we apply it and combine it with the prompt embeddings that we get from our text encoder, and pass through the transformer that will then give us a model prediction out.
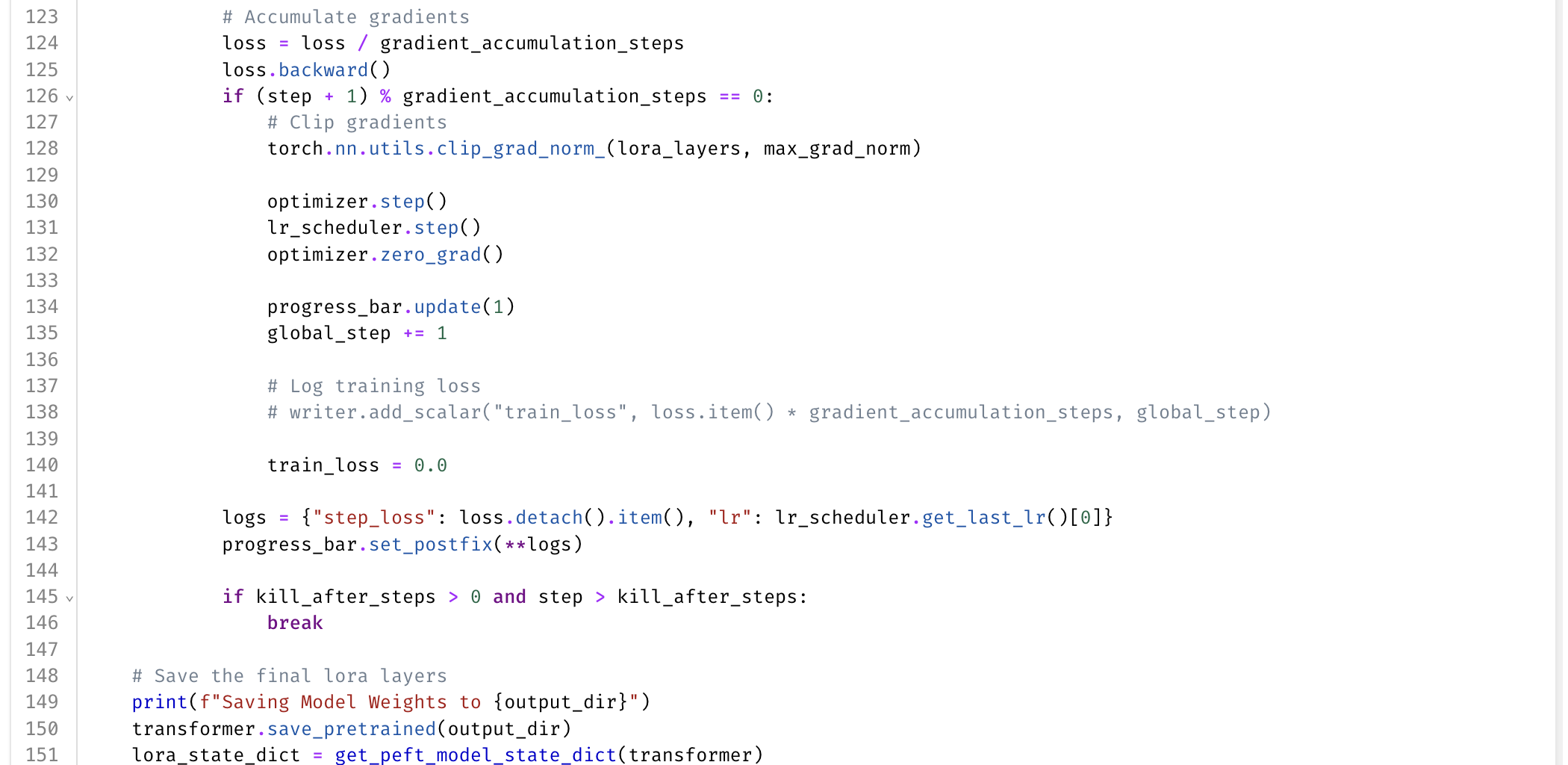
The model prediction is actually just like trying to predict the noise, and then we take the mean squared error of how much noise the model predicted and the target, which was the noise that we passed in. This will then give us our loss and then there's a little gradient clipping. But that's pretty much the whole training loop: sample some random noise, combine it with the text encoder embeddings and the VAE image embeddings, and then try to get the model to predict that noise back out from the latent space.
We then just save the LoRa weights that came out. We only need to save the LoRA weights and not the entire model because we didn't actually update the entire model. In the end, it then commits those model weights back to oxen and you'll see I have a few different experiments here. I ran the model for one epoch, 20 epochs, and 50 epochs, just to see if there was any change in how long we need to train it or how many times it sees the training data affect its performance.
In our live breakdown, I ran the script for one epoch and it took about two minutes to complete with those 2000 examples...which is pretty quick. You can also monitor things like the GPU usage down here, so we're using about 30 gigs of VAM for a batch size of eight. So you could probably run this on a much smaller GPU if you wanted.
Evaluating the Fine-Tuned Models
There are two different ways we can run the inference-DiT notebook. One mode where I'm just typing in one phrase at a time and getting the grid of images out. The second, I use that same function but run over the entire dataset and generate an image for each row.
So here I only have the prompt button:
And further down is the 'Run on Dataset' button:

It iterates over a parquet file running a prediction on each row and then adding the data back to a data frame so that we can see the results.
So I used Open AI and the three different models that I trained, the one, 20, and the 50 epochs, and I started with a test set that is just a list of things that we've tried to generate in the past.

So for example, I just went down all of the blog posts that we've written in the past and grabbed whatever action we were trying to do here, like an ox cutting down a tree or an ox sailing on a ship, because ideally we just have all these be the same branded character in the future. So I put this all into a test set. So it was kind of like real-world prompts that I would wanna put into this model at the end of the day.
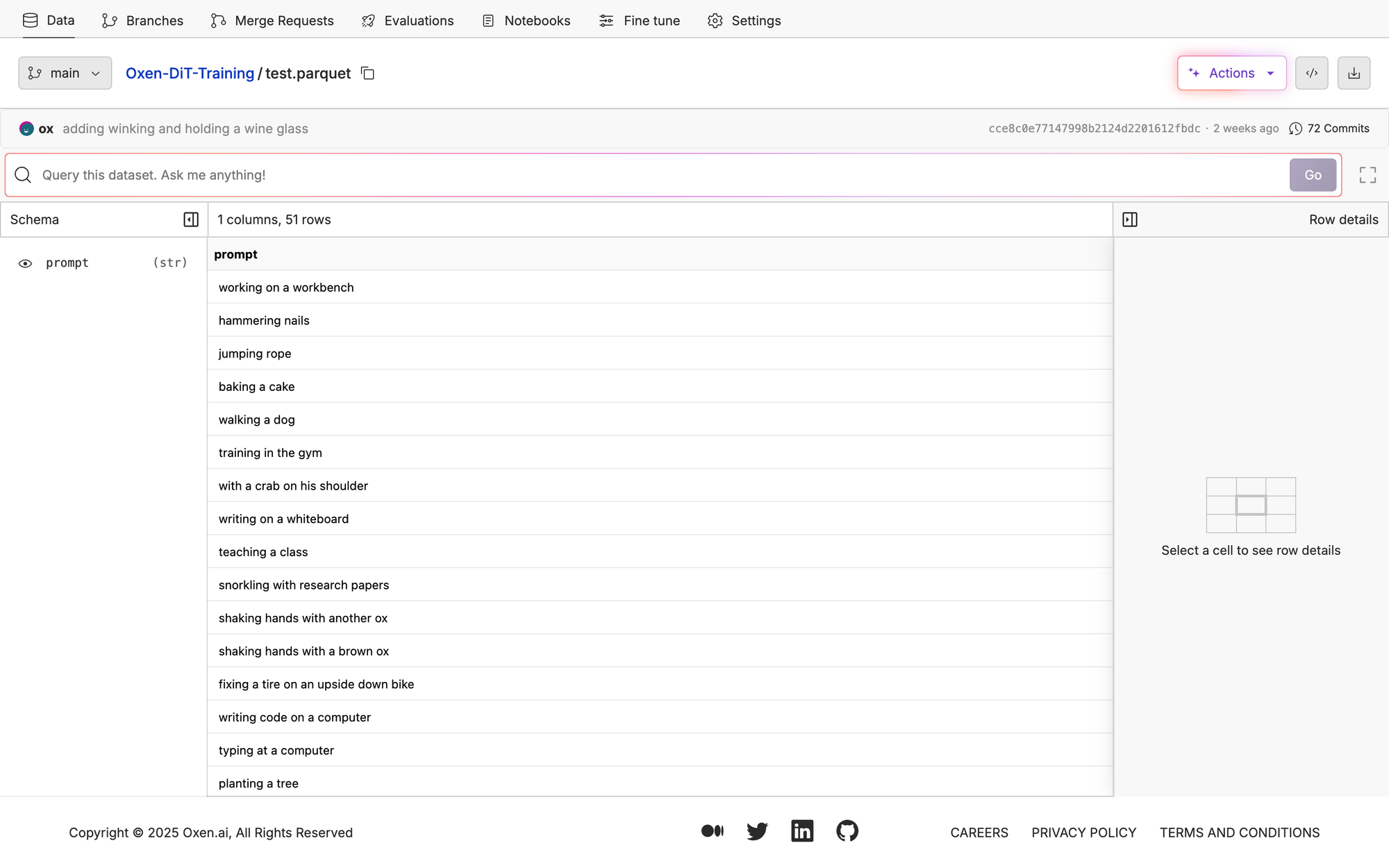
So I have scripts to run these models on those prompts.
Here is the Openai results set. Pretty solid for all of these prompts.
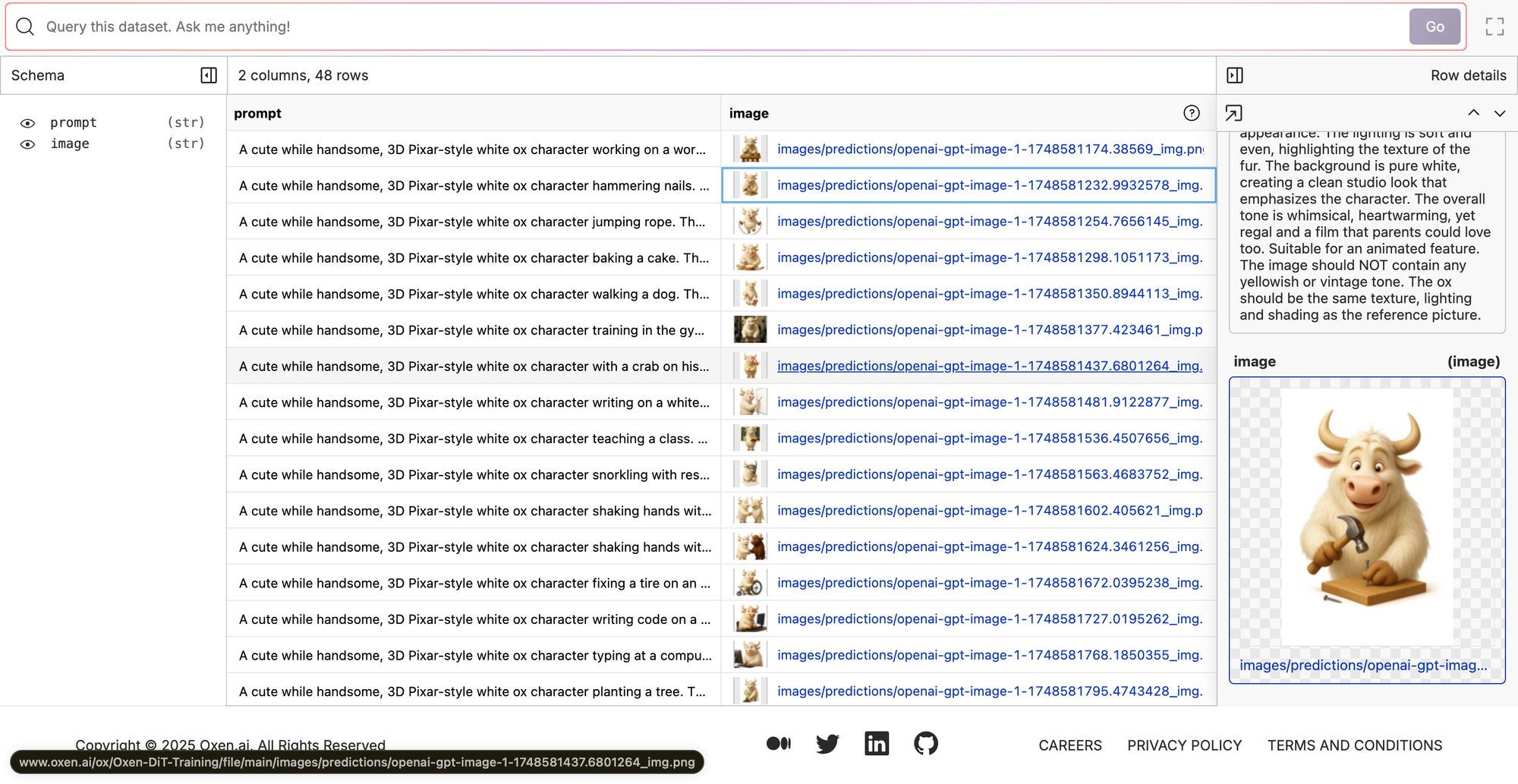
Here's the single epoch that was trained. Not bad for something that took a few minutes to train. It's like definitely picked up the ox character but it has a hard time with some of the things in the scene. For example, this one was an ox walking a dog and it didn't add the dog. It made it half ox, half dog. So it definitely learned the character, but maybe not all of the different assets that we put in the scene.
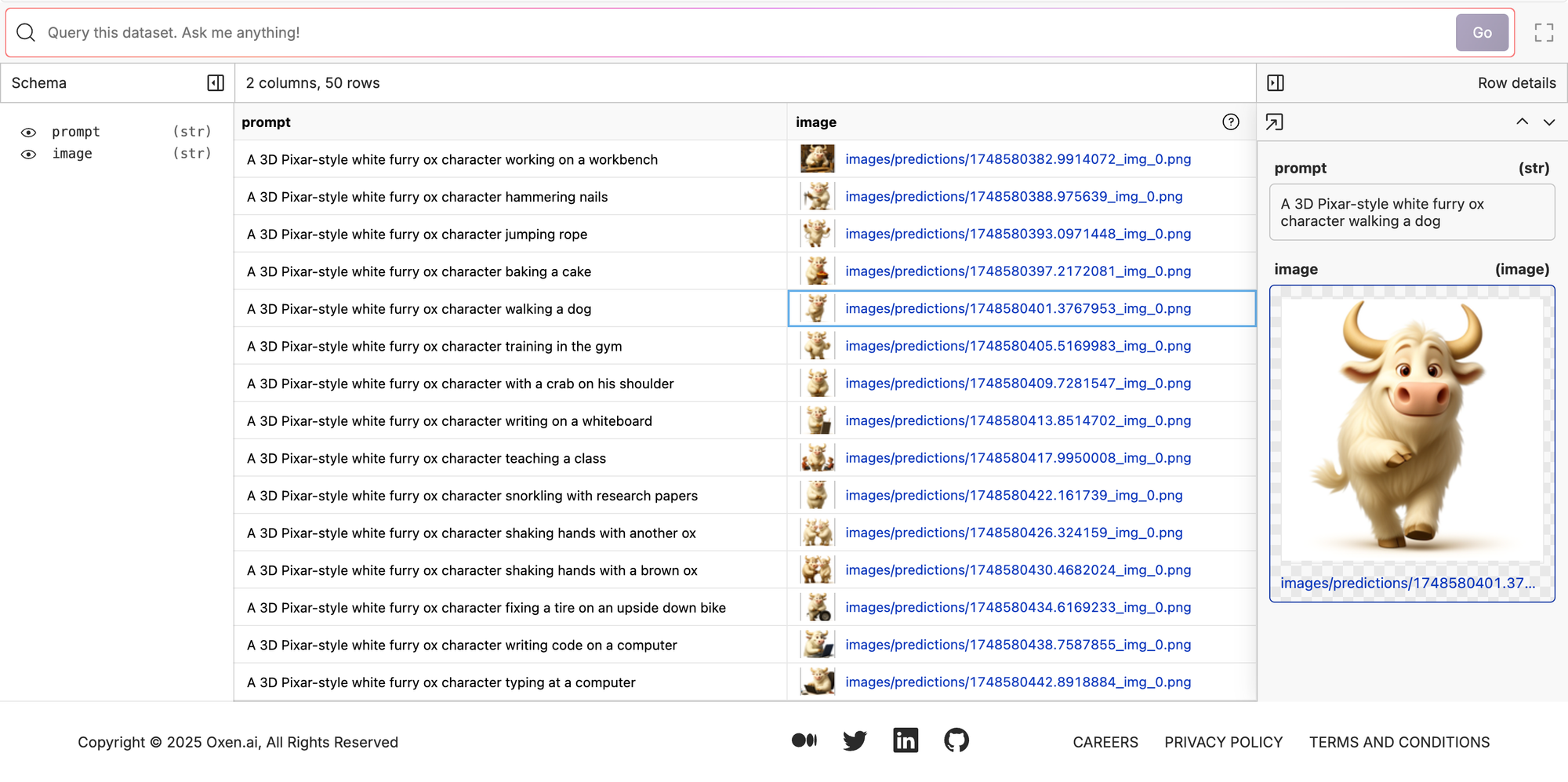
If we train it for a bit longer like 50 epochs. It does a little bit better with the tasks the ox is doing but not that much. For example, the ox is still not walking the dog.
Overall though, starting to get closer. But the really encouraging part here is now that we have a supervised, fine-tuned model that can get the right answer some of the time. That's the perfect spot to put yourself in a reinforcement learning loop because you kind of want the model to get it sometimes and not get it other times. Then reward it for the time that it gets it.
For this time we're not doing the full reinforcement learning loop here, but I did want to do some proof of concept of how that could work.
So if you remember closer to the start, I kind of had this diagram of trying to get some scores out of the end that we can use to guide further training.
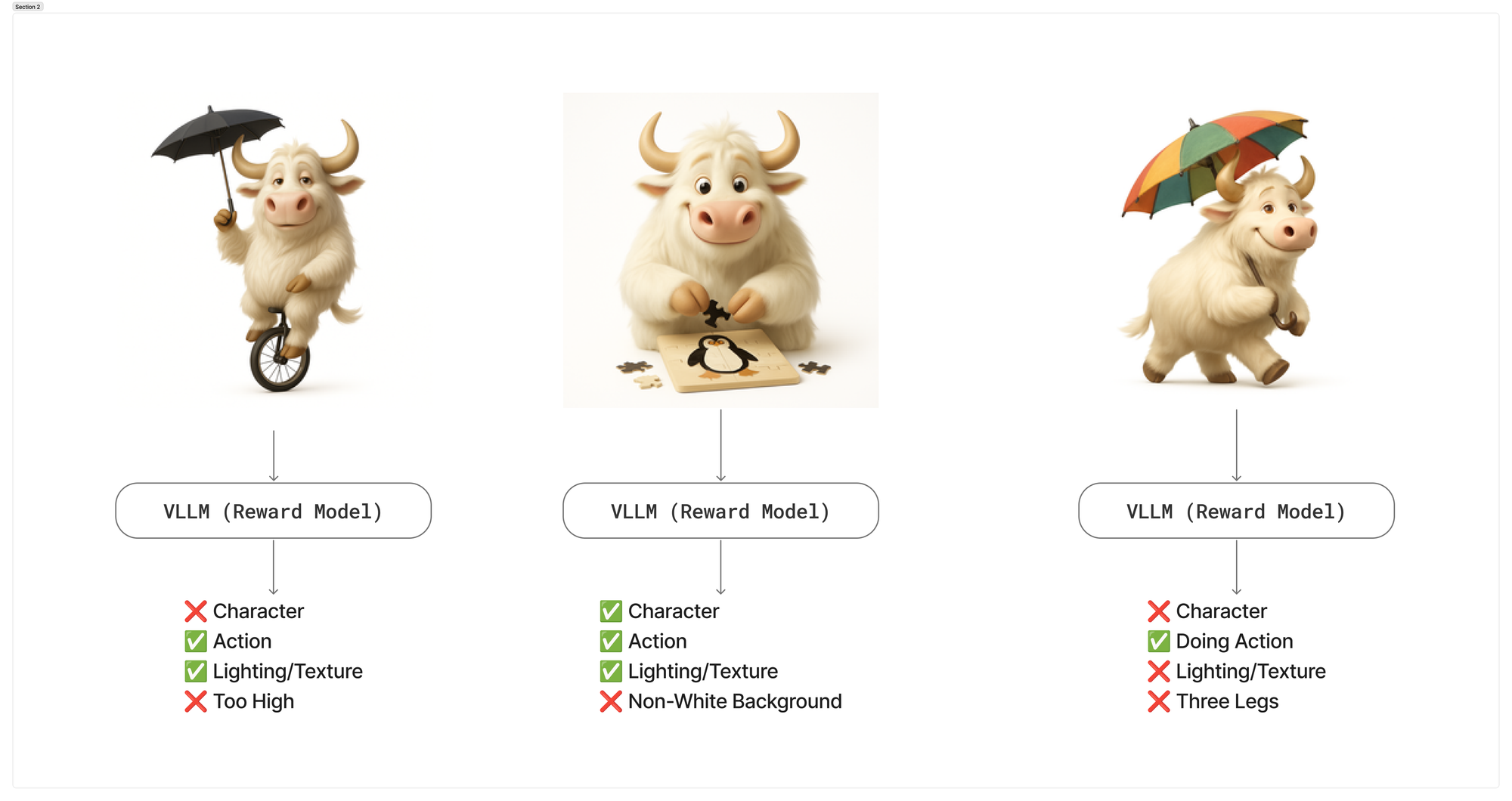
I wanted to see if this was possible at all so I used Claude 3.7 Sonnet, which is a visual language model. I think there's a bunch that we could try to use here. Claude's probably a more expensive one, but I just wanted to see if we could get some sort of prompt that graded the images at all.
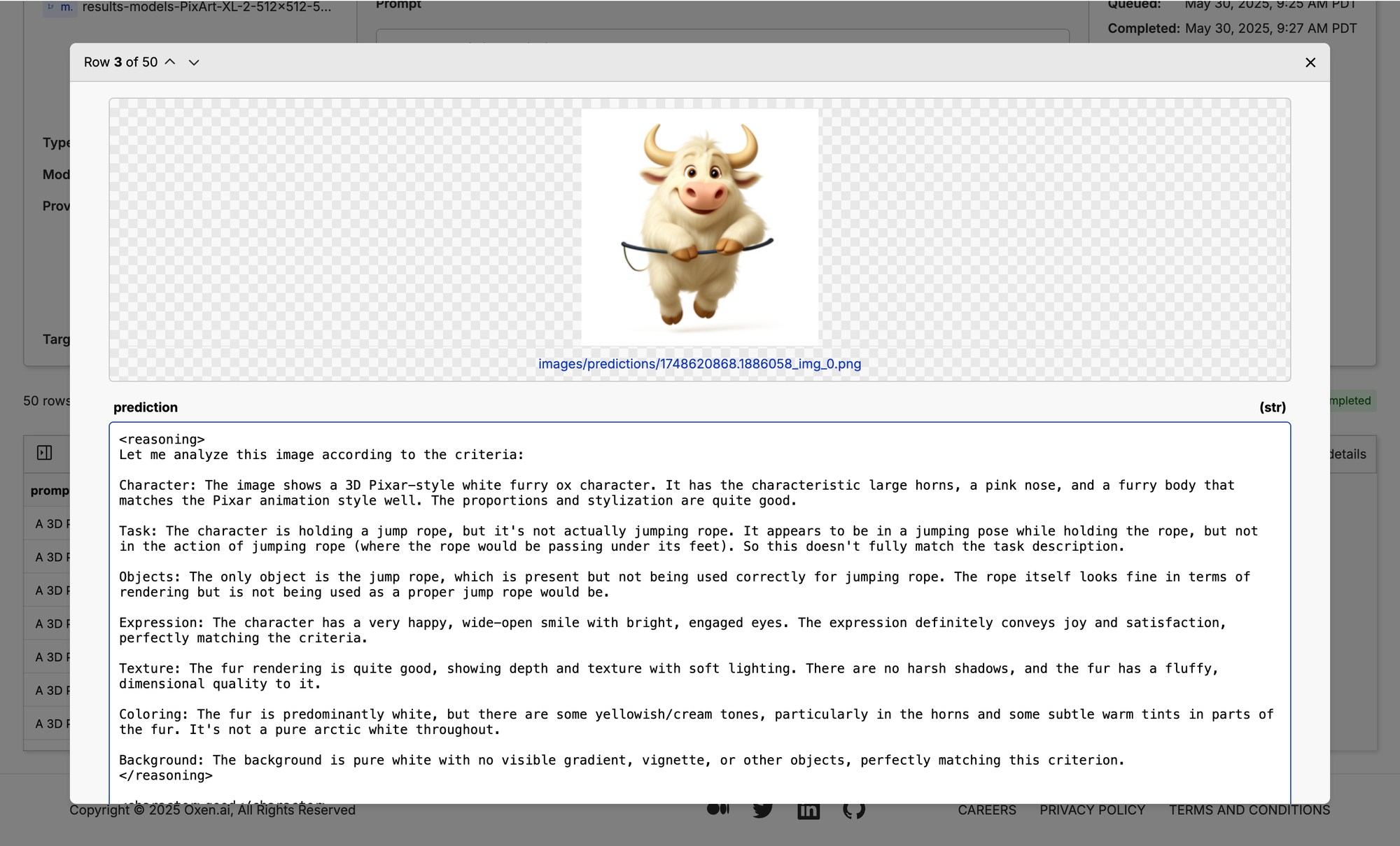
So here is our jump roping ox:
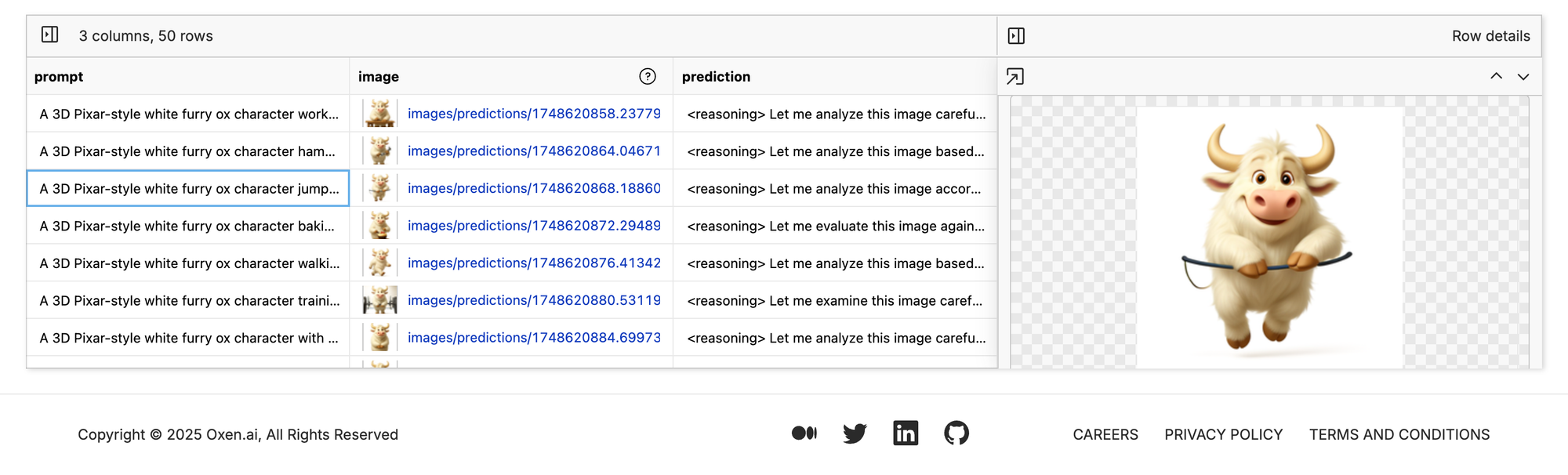
And here is the prompt I gave Claude 3.7 Sonnet:
# Image Judging Rubric
You are an animator looking at an artists work. Judge the following image on a few different criteria. Be very critical. We are aiming for a movie quality character.
## Valid Values
Each of judgements should be one of three values:
* "bad" if the image does not match the criteria
* "okay" if the image has elements of the criteria, but is not good yes
* "good" if the image matches the criteria, but could be better
* "perfect" if there is nothing that could be improved about the image
## Criteria Descriptions
The criteria in which the image should be graded on are as follows:
character:
Is the character a 3D Pixar-style white furry ox?
task:
Is the character performing the task described?
objects:
Are all the necessary objects in the scene? Is there anything wrong with them? Do they look realistic?
expression:
Is the character's expression wide open and happy, with a visible spark of joy or engagement, conveying satisfaction in the activity?
texture:
The fur must show clear texture and depth, with soft lighting that avoids harsh shadows or bright highlights.
coloring:
The fur must NOT contain any yellow or sepia tones. It should be a shade of white with a tone as if it lives in the arctic or himalayas.
background:
The entire background must be pure white (#FFFFFF) with no visible gradient, vignette, or objects other than the ones specified in the prompt.
## Return Format
Return the judgements in xml format. The xml should contain the criteria name in the tag. An example response looks like this:
<reasoning>Your reasoning</reasoning>
<character>good</character>
<task>bad</task>
<objects>bad</objects>
<expression>perfect</expression>
<texture>perfect</texture>
<coloring>good</coloring>
<background>perfect</background>
Reason through your thoughts step by step before responding. Put your thoughts in the <reasoning></reasoning> tags.
I find that sometimes using an actual descriptive word instead of a numeric value lets the model put these things in categorical buckets a little better. So we could just say return 0, 1, 2, 3 but the words bad, okay, good, and perfect are a little more descriptive there. So those are kind of the categories that we'll be grading each criterion on. And then I have a bunch of different criteria like:
- Is the character what we want?
- Is the task what we want?
- Are the objects what we want?
So we put in the prompt and we put in the image to that context, and then we get a prediction out from Claude that first has this little reasoning step here where it says, "Let me analyze the image according to the criteria" and this is nice at the start to kind of have you have a little look into what the model's thinking before it gets to its judgments at the end.
But we can see this is actually a pretty good signal. It says the character's good, the task is bad, the objects are okay. We're like starting to get a jump rope, but it's not a full jump rope.
Comparing Models
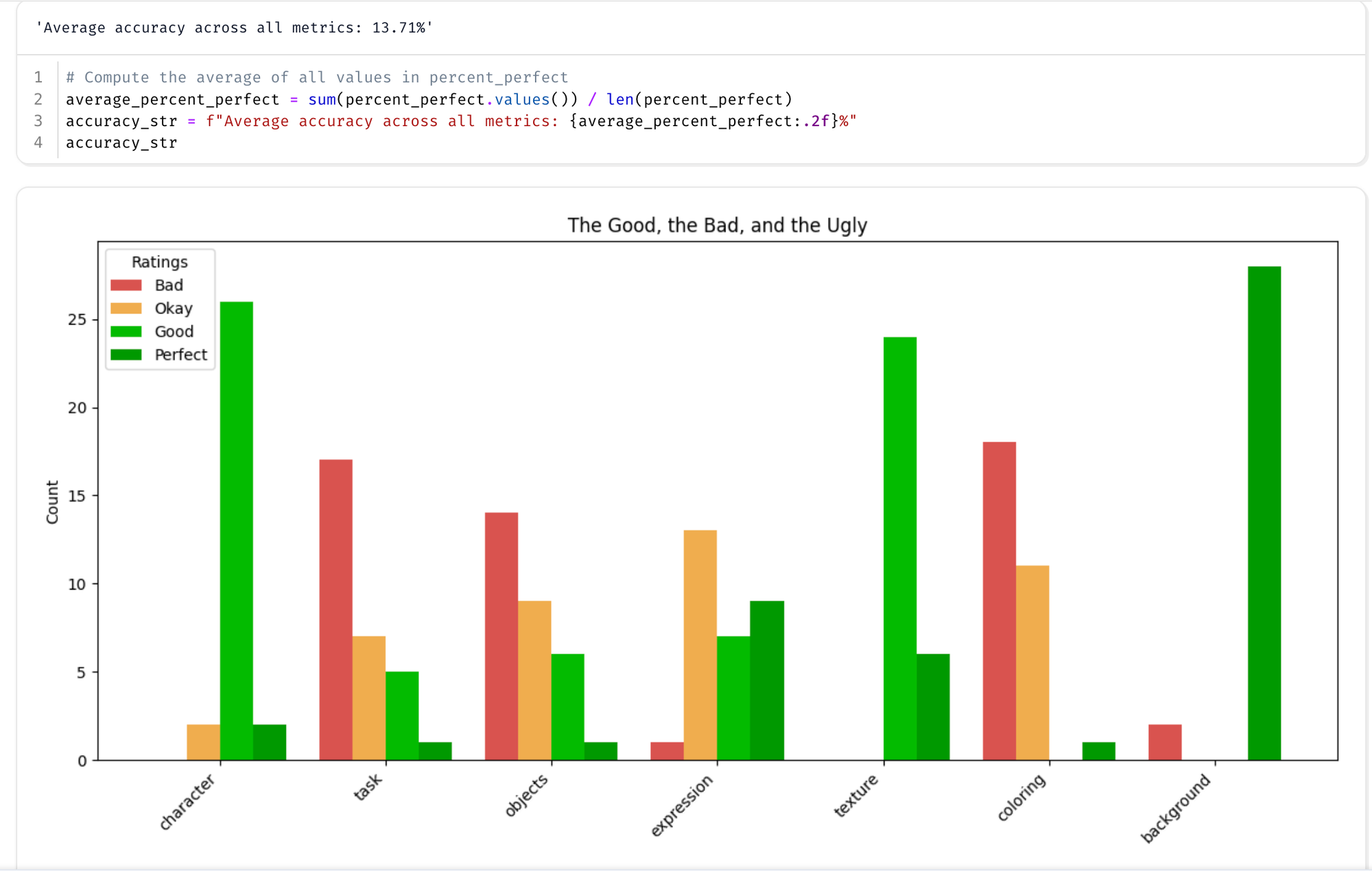
Surprising - but the 1 epoch model outperformed our 20 epoch model…even though subjectively I think the 20 epoch one looks better. Might have to work on the LLM as a Judge prompt.
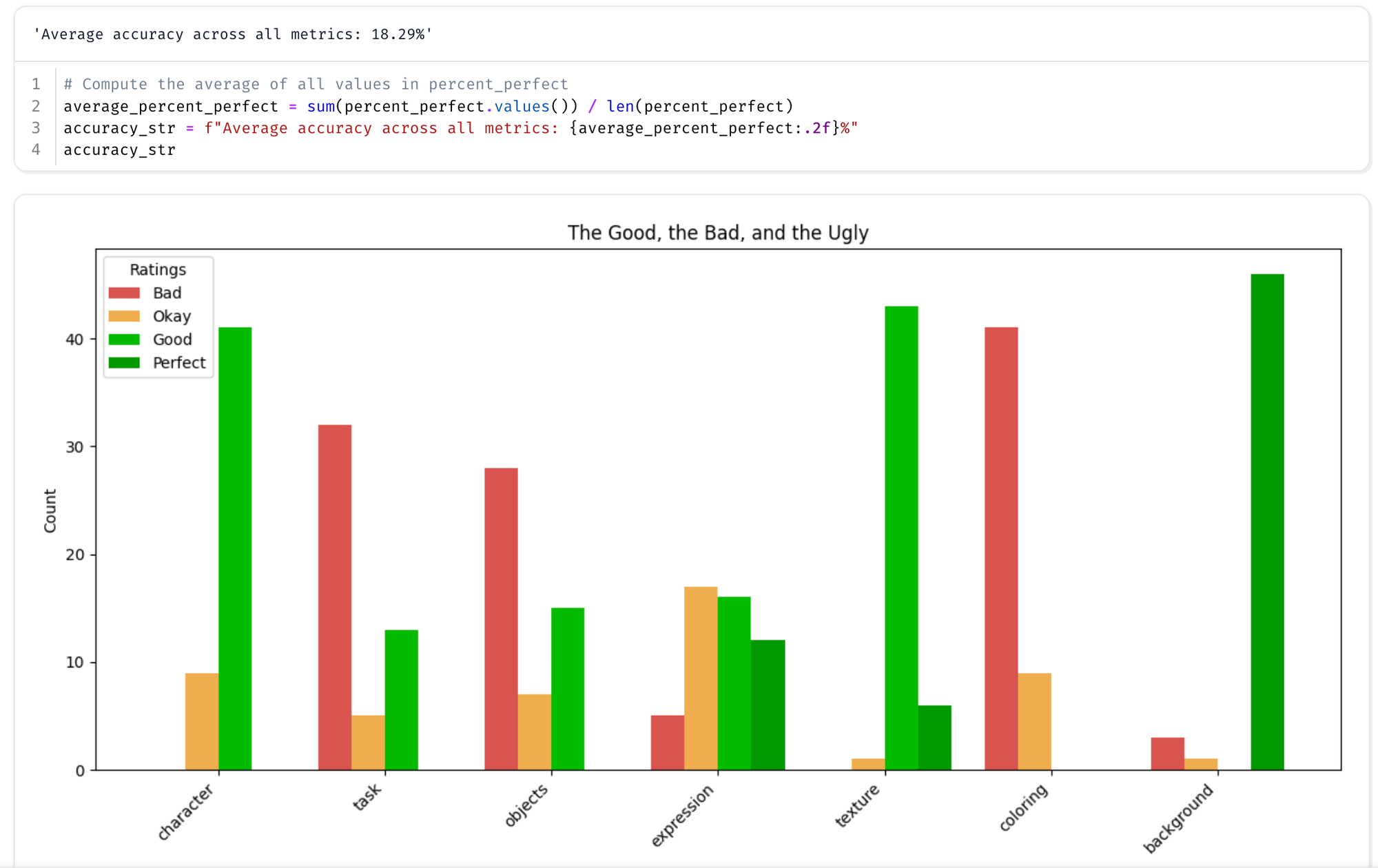
I think this is a perfect place to start. Bootstrapping that reinforcement learning because we can get okay to good pretty consistently and if we're aiming for perfect, I think over time we can shift to these distributions to the right.
Conclusion
All you need for this fine-tuning formula to work is:
- Reference image
- Prompt to generate synthetic data
That’s it. Once you have those two assets, you are off to the races.
Not all smol models can win! But we are not giving up 😏, I think the fact that this model learned the general ballpark from SFT sets us up nicely for some RL.
Next time we will be diving head first into seeing if we can optimize this model with DPO or GRPO. Honestly, I haven’t seen much research into this…so wish me luck.
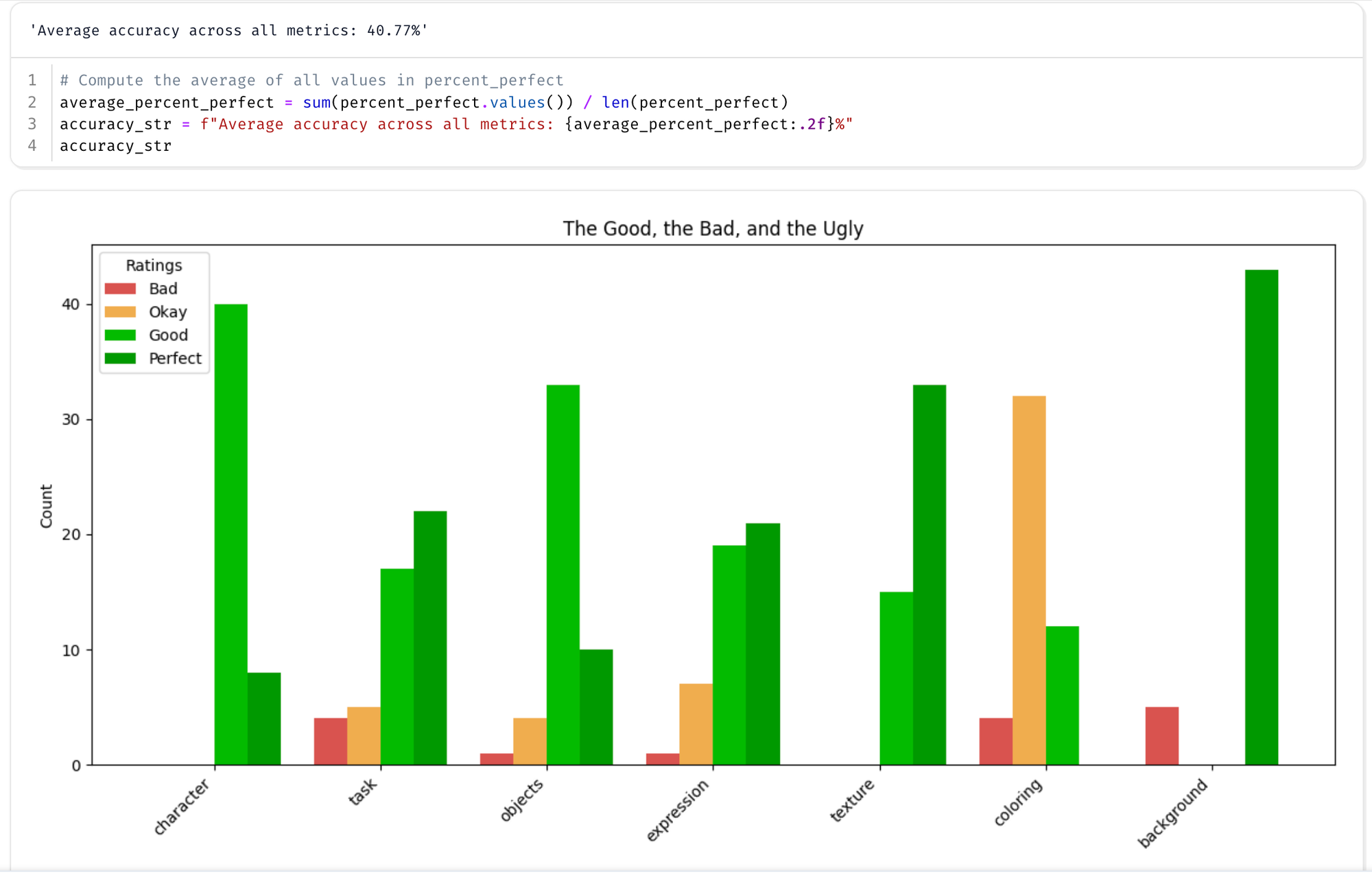
| Model | Accuracy |
|---|---|
| Strong LLM | 41% |
| Fine Tuned 1 Epoch | 18% |
| Fine Tuned 20 Epochs | 13% |




Member discussion