
Fine-Tuning Fridays


Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open source model and put it head to head against a closed source foundation model on a specialized task. We will be giving you practical examples with reference code, reference data, model weights, and the end to end infrastructure to reproduce experiments on your own.
The format will be live on Zoom at Friday, 10am PST, similar to our Arxiv Dive series in the past. The recordings will be posted on YouTube and documented on our blog.
The formula will be simple.
- Define our task
- Collect a dataset
- Eval an open source model
- Compare results to a closed source model
- Fine-tune the open source model
- Declare a winner 🥇
Our thesis is that small models are getting smarter and more accessible to the average developer. Most fine-tuning workloads are simply a matter of having the right data. Whether you are optimizing for cost, privacy, latency or throughput, the goal of this series is to inspire you to fine tune models of your own. Using your own data. Giving you full control over the model weights, how the model behaves, and where it runs. As they say: not your weights, not your model.
By the end of each fine tune we will publish concrete numbers and data you can look at yourself. For example...
Qwen3-0.6B beat GPT-4.1 on generating SQL from a user query?Sneak preview.... The answer is yes 🙌
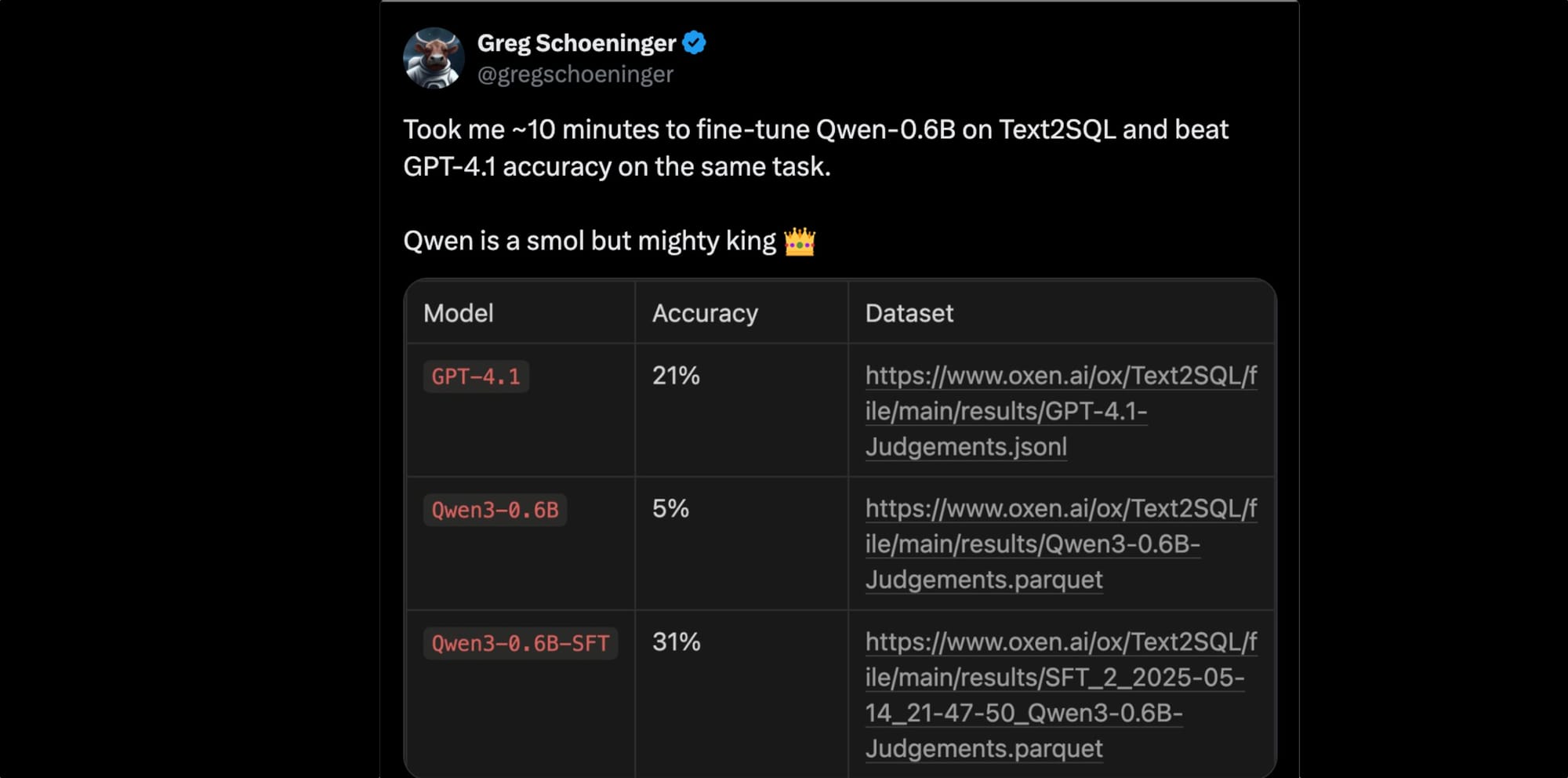
Source: https://x.com/gregschoeninger/status/1922781767720706151
Along the way, we will learn about tradeoffs between different open models as well as the training algorithms used under the hood. We will apply supervised fine tuning, reinforcement learning, and synthetic data techniques that you can take back to work and apply to your projects. The more models we benchmark, fine-tune, and compare the state of the art, the better intuition we will have to which model to use and when.
Pressing Pause on "Arxiv Dives"
We have heard from the community the request for more practical examples, and we still strongly believe that "Anyone Can Build It". That said, with the limited hours we have, the Oxen.ai team will be taking a break from deep dives into research papers with Arxiv Dives. In this new series we will still sprinkle in applicable learnings from the latest and greatest research papers, but they will not be the main focus.
Join the Community
The community will discuss the results live on Friday at 10am PST, similar to our previous Arxiv Dive series. We will also be posting to our YouTube and Oxen.ai Blog. If you want to join use live, you can sign up for the events on our lu.ma calendar.
If you are new to the Oxen.ai community, feel free to checkout our past dives here:

Watch our YouTube:

Or join our Discord community:
The Fine(tuning) Team at Oxen.ai
None of this work could be done without the support of the Oxen.ai team. All of the experiments will be run end to end in the Oxen.ai platform so that the code, dataset, models, and pipelines are all versioned and reproducible. Check it out if you haven't already.
Best and Moo,
~ Greg and The Oxen.ai Herd




Member discussion