
How RWKV-7 Goose Works 🪿 + Notes from the Author

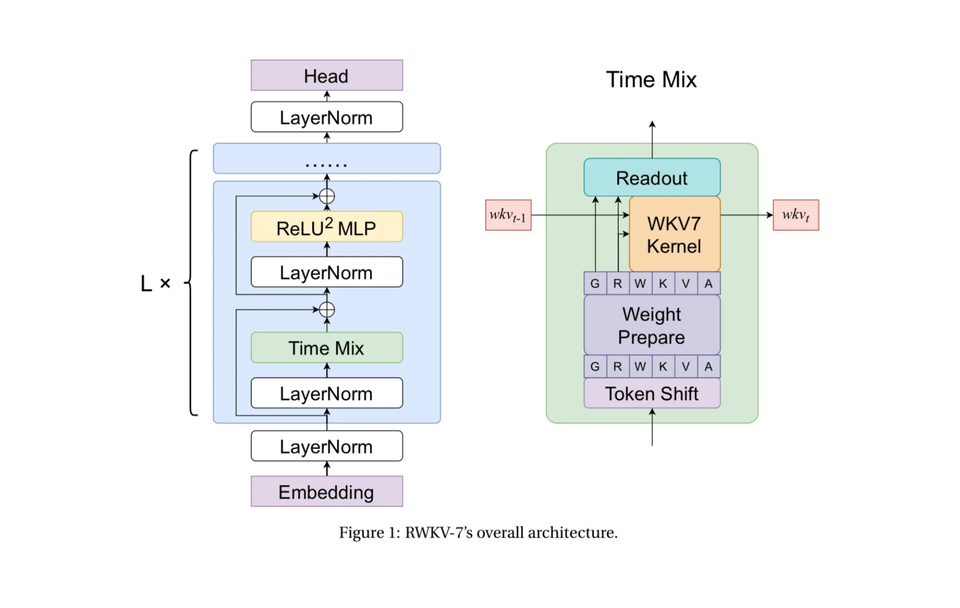
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of Featherless AI, to discuss the development process and key decisions behind these models.
RWKV-7 (Receptance-Weighted Key-Value) Goose is a 3B parameter language model that requires constant memory usage and constant inference time per token. This is in contrast to attention mechanisms which have quadratic complexity. The organization behind RWKV is training models ranging from 0.19B to 2.9B parameters, have open datasets, models, and training code, all under Apache 2.0 License.
(as you are reading along, it is pronounced “RwaKuv”)
Follow along with the video if you want to hear Eugene's takes. The format of the dive starts with some high level intuition about Recurrent Neural Networks and how this paradigm is augmented in RWKV. Then we dive into the depths of the modifications made in RWKV-7, how the RKWV group makes decisions, and how you can contribute.
Greg spends full days diving into research papers and writing the Arxiv Dives. He does this to empower engineers to hack on their own AI and use Oxen.ai to set up their data. If you like this blog, try Oxen.AI today and we'd love to hear your feedback:)
Anyone Can Build It
RWKV is a great example of the Arxiv Dive ethos of “anyone can build it”. Start with a simple RNN, make some tweaks, see how it works, progressively work your way up to an interesting architecture that competes with Transformers on a few different dimensions.
The RWKV story is pretty cool, it was started by Peng Bo, or BlinkDL or the socials, who studied physics at the University of Hong Kong and was a quant trader before he got into ML. In the initial stages, RWKV was essentially a personal passion project, built from scratch by Peng through experimentation and self-funded effort.
Eventually it gained some steam in the EleutherAI Discord and StabilityAI which funded the training runs.
If you have an idea, hack on it, make a proof of concept that gives you the confidence, then go build it.

Testing RWKV
In this spirit, at the end of the dive we will be doing some live demos and sharing some Oxen.ai Notebooks, so as we are going through the content, write down any prompts or questions you think might be interesting to ask.
If you don’t know about Oxen.ai we are a platform for iterating on code, models, and data. Think of us like a GitHub, but optimized for large machine learning datasets, models, and can run compute.
What is RWKV?
At it’s core it is a Recurrent Neural Network (RNN). However, RWKV achieves three key benefits simultaneously:
- Linear inference (RNN)
- Parallel training
- Language modeling quality comparable to Transformers.
Remember, Transformers have outperformed RNNs in the past because of their ability to be parallelized during training. This in turn means they can see more data. More data usually leads to more generalization and better performance in terms of accuracy.
The attention mechanism within Transformers is one of the reasons they perform so well on language, it allows the model to easily look back while modeling the sequence to earlier words, phrases and tokens. The problem with attention is it’s O(n^2) memory and time complexity at test time.

Under the hood this manifests as large matrix multiplies.
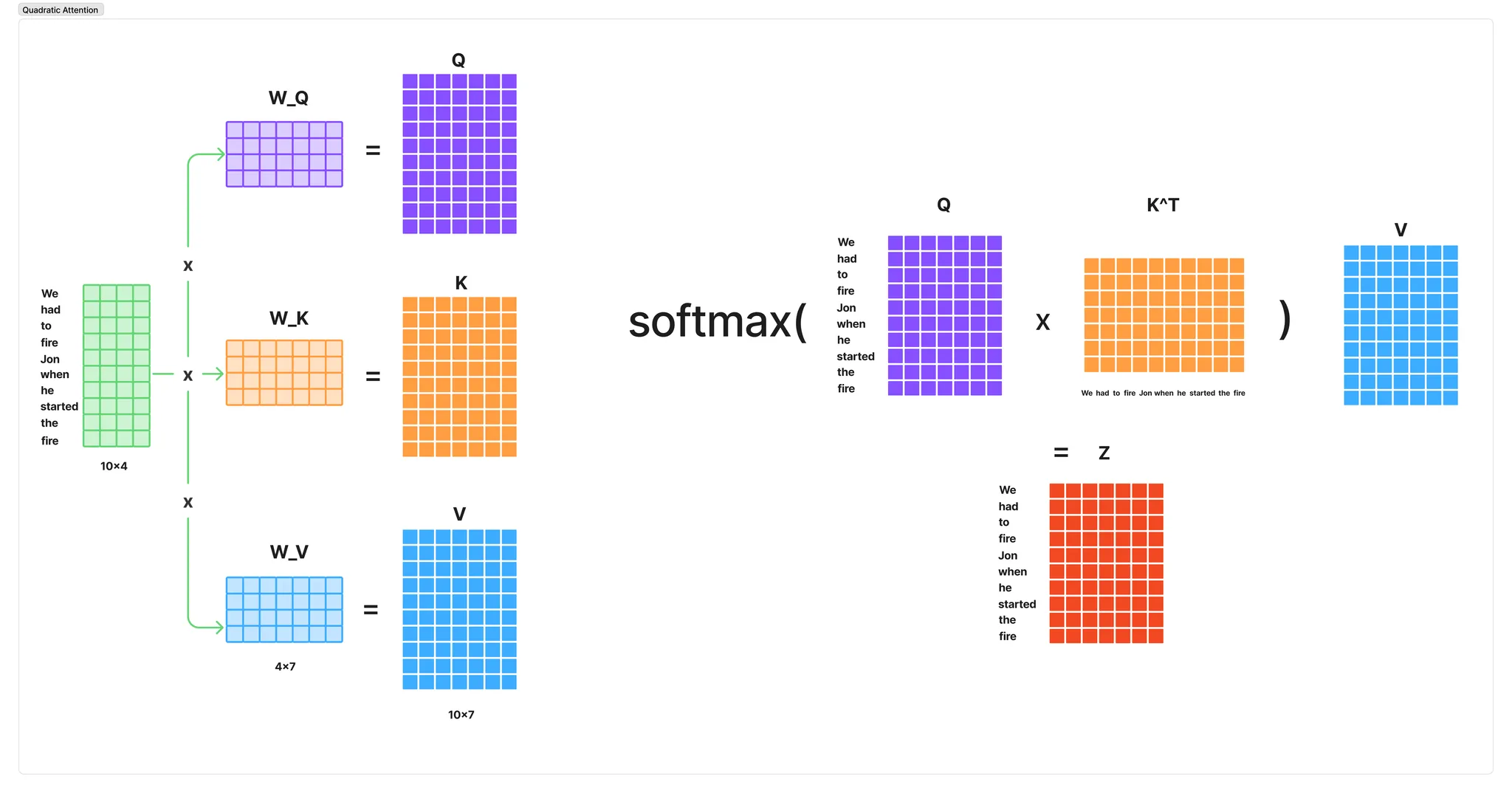
You can see how as the length of the sequence increases, these intermediate matrices become quite large.
RNN’s on the other hand are linear in time and space (memory), but hard to parallelize, meaning they see less data during training because they have less throughput in terms of FLOPS.
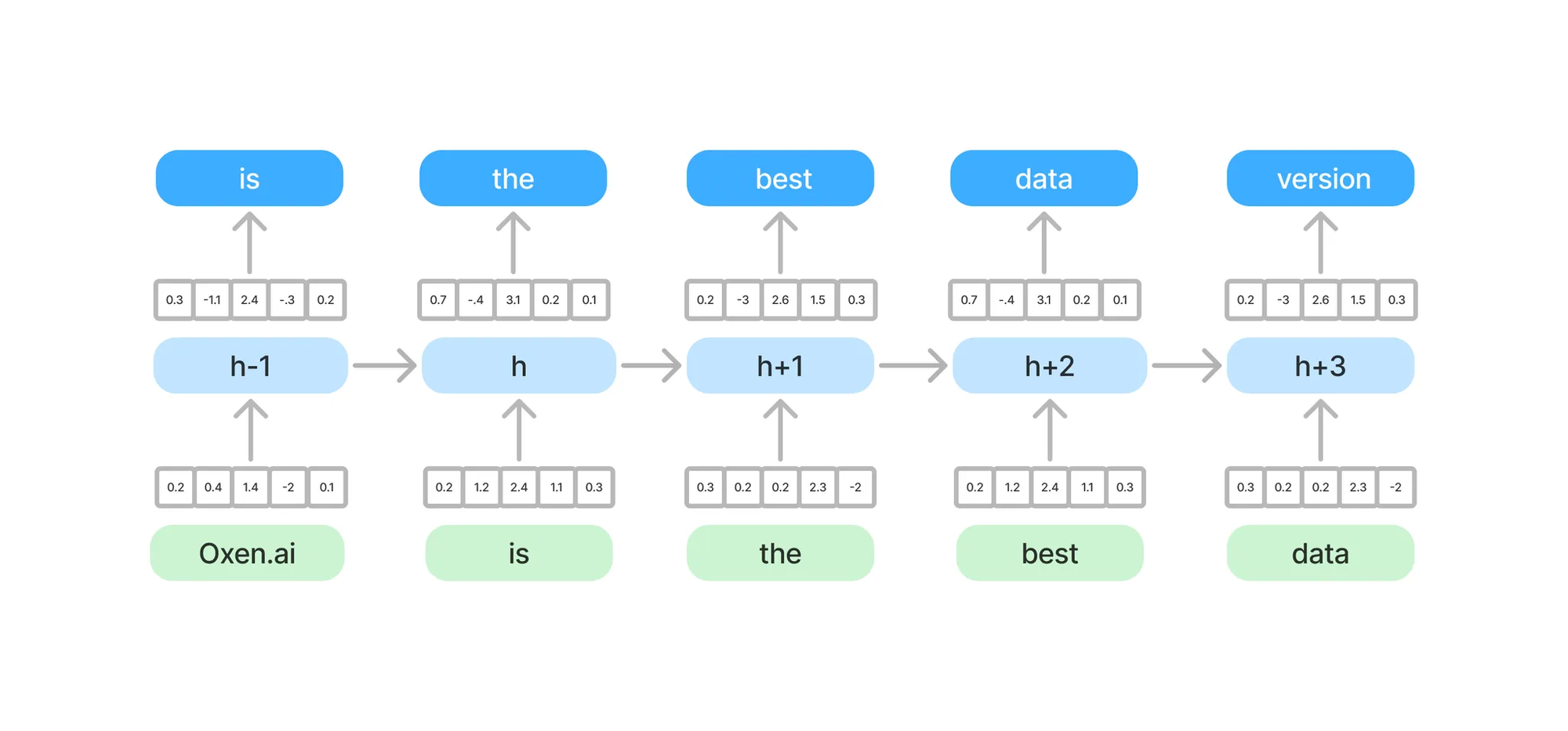
While RNNs are linear in nature, they are hard to parallelize, because you inherently need the hidden state given the previous token to predict the next hidden state.
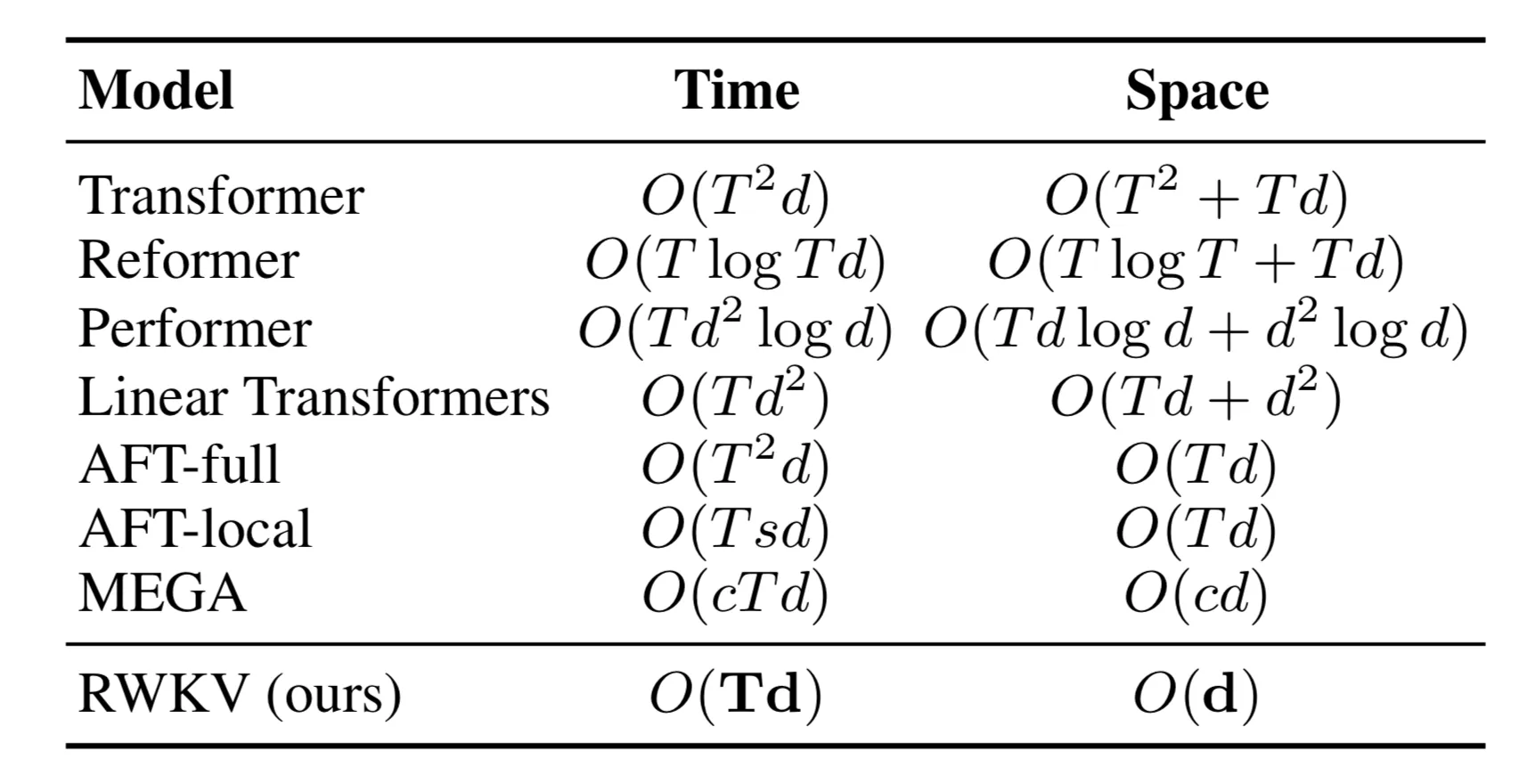
RWKV claims to balance this tradeoff of seeing the entire context length, while maintaining linear complexity. This table is from the original d=hidden dimension T=sequence length.
RNN’s Forget Things
Like we said before, RWKV is an RNN at it’s core. While they are fast, the downside is that you have to save all the context into a tiny little hidden state.
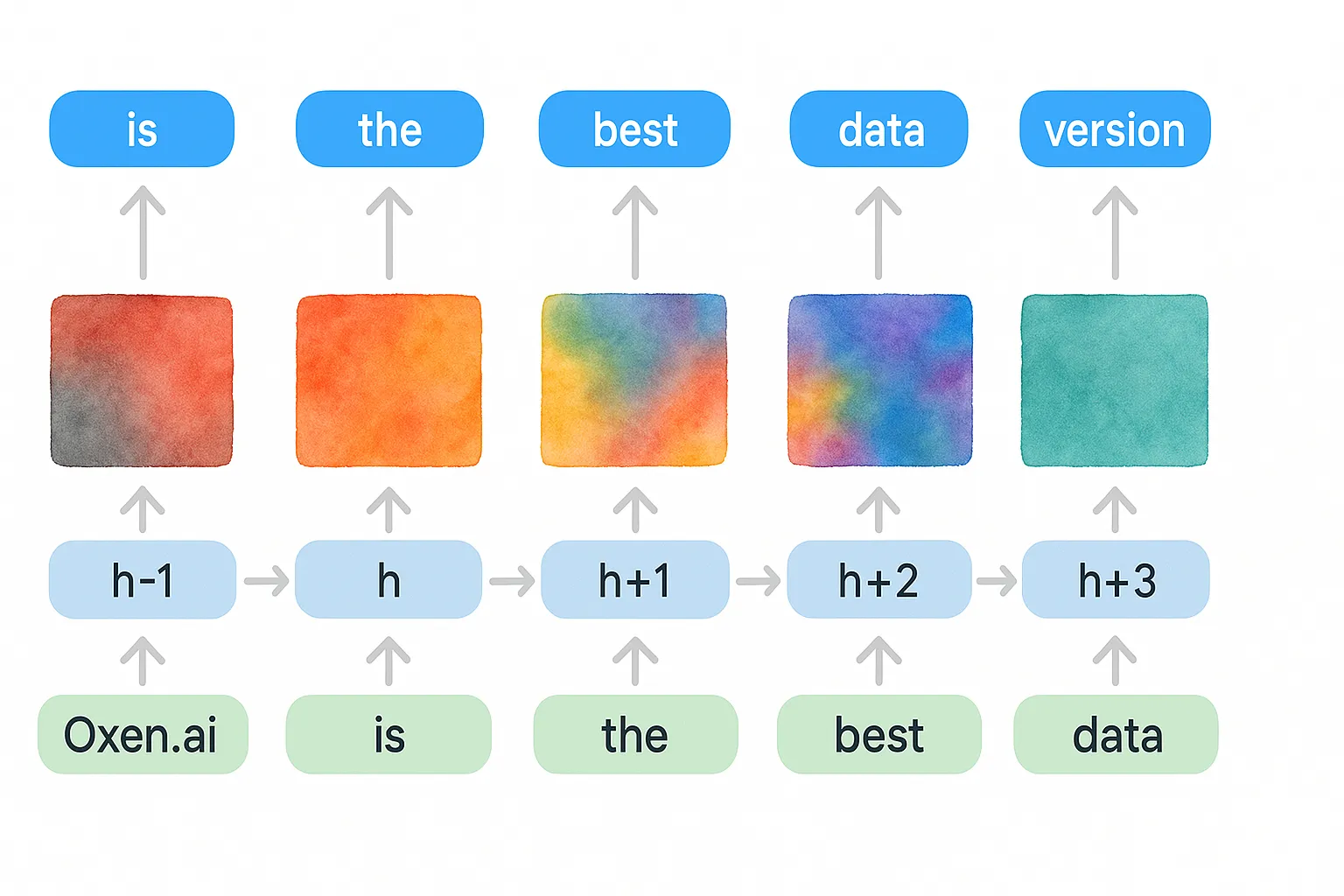
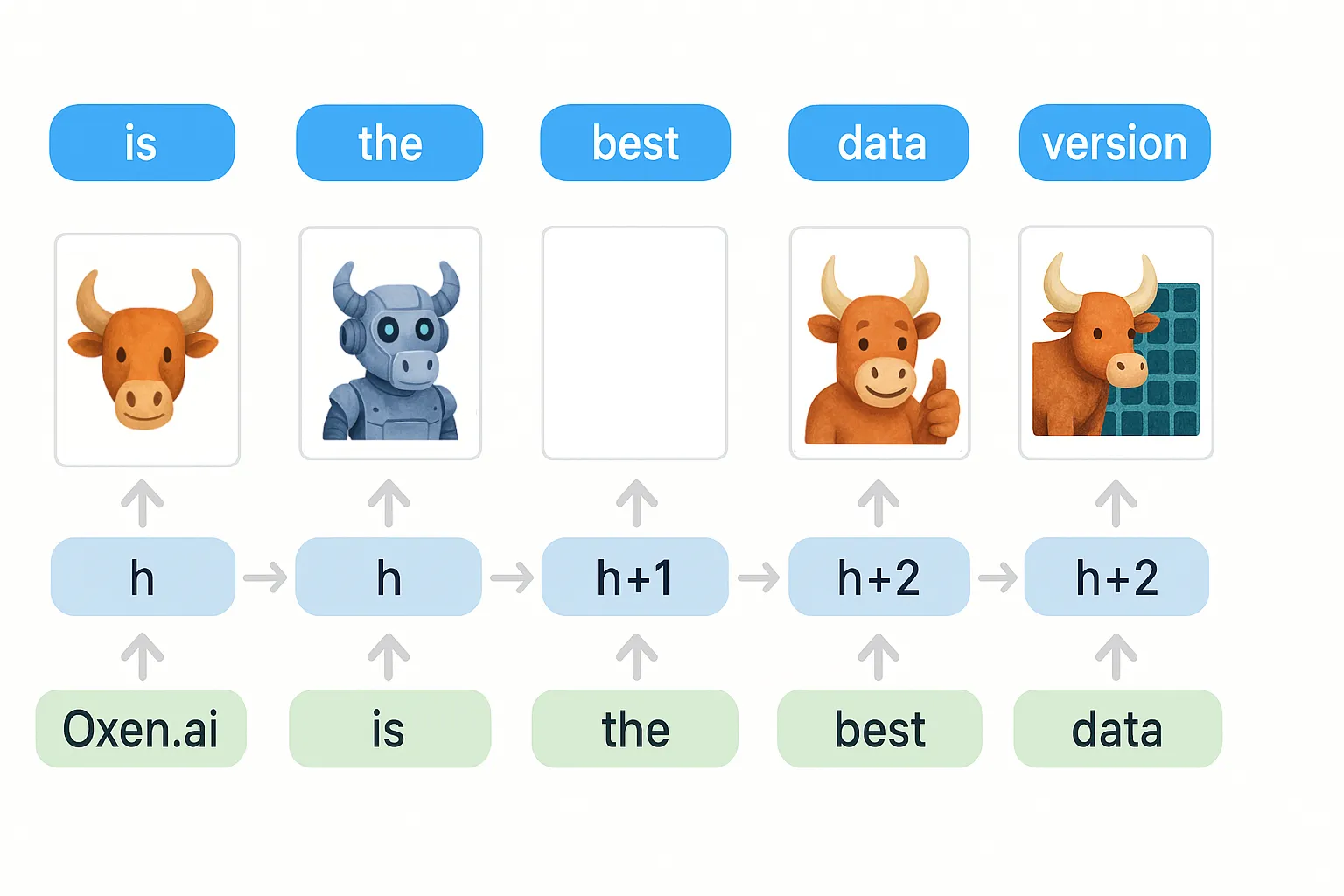
Imagine each input word as a single color representing that word. Oxen.ai is red, best is purple, data is cyan, etc. Each time step you have to update the hidden state with some information from that word, represented by the color.
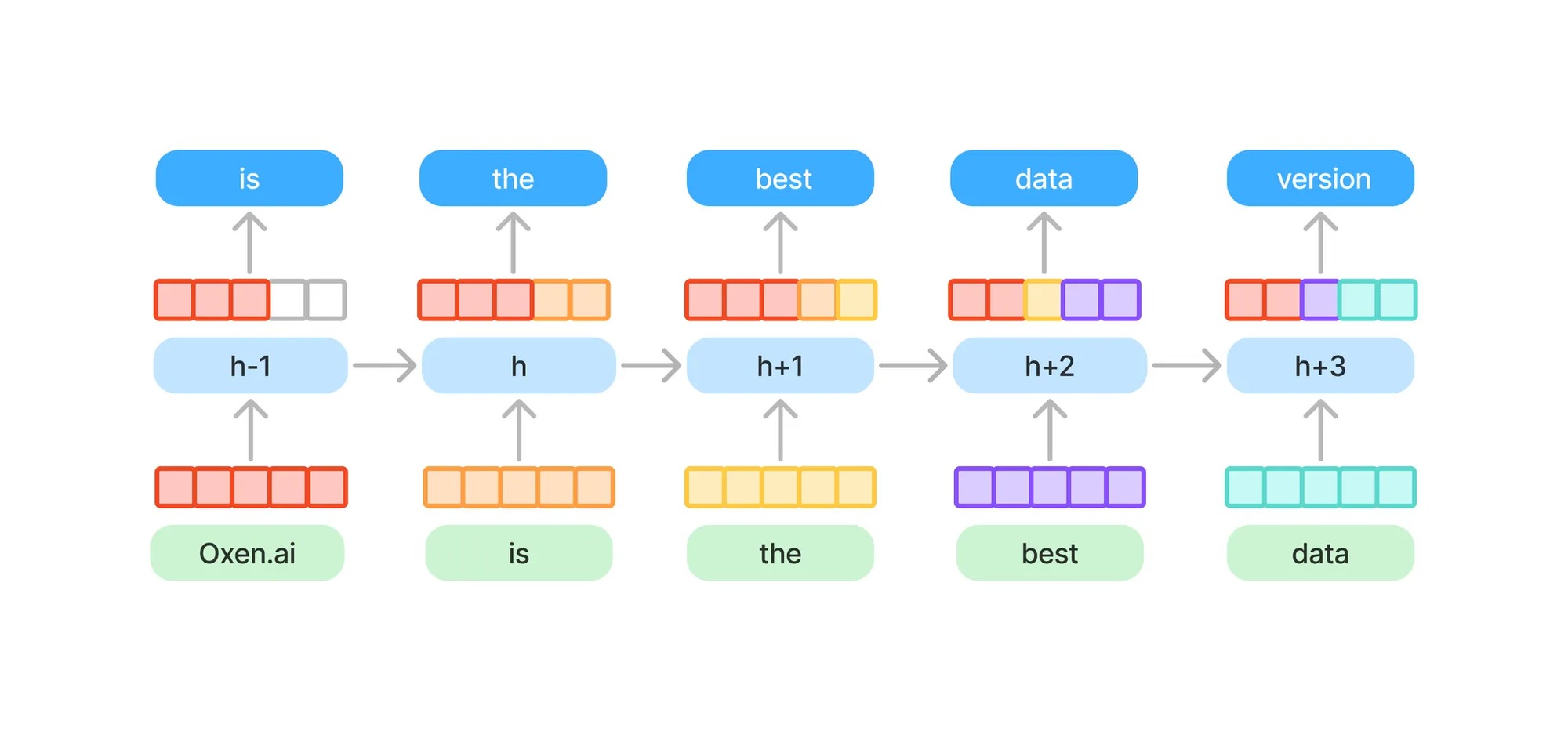
By the time you get to the 5th word, you have to start making some tough decisions about what to keep and what goes.
While this is an over simplification, it is a mental model that will be helpful to keep in the back of your mind (or in your hidden state) while we go through the rest of the architecture. It will help you see the motivation behind some of their design choices.
In the paper’s own words:

RWKV: Reinventing RNNs for the Transformer Era
This was the first public release of RWKV and was technically RWKV-4 🕊️ "Dove". You may be familiar with their instruct tuned version called
"Raven" as well.
There are subsequent releases for v5 and v6 Eagle and Finch 🦅
And finally today - RWKV-7 🪿
Honestly if you don’t name your models after animals w/ corresponding emojis, you’re ngmi 🐂 🕊️ 🦅 🪿
Time & Channel Mixing
The original RWKV paper has an interesting type of recurrence with two blocks: channel mixing and time mixing.
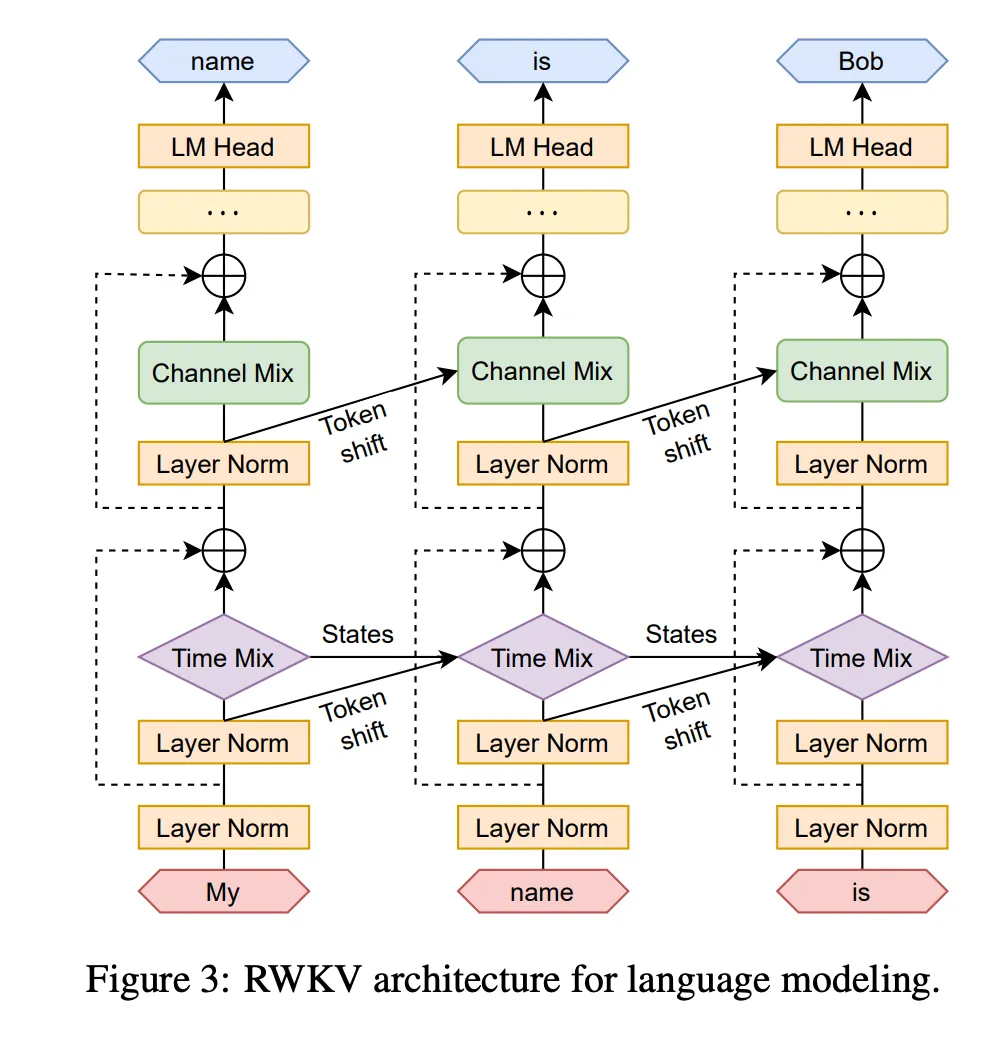
The channel mix is a feed forward network that “mixes” information in the hidden dimension channels. The time mix takes into account previous states, and allows the model to see backwards in time a bit.
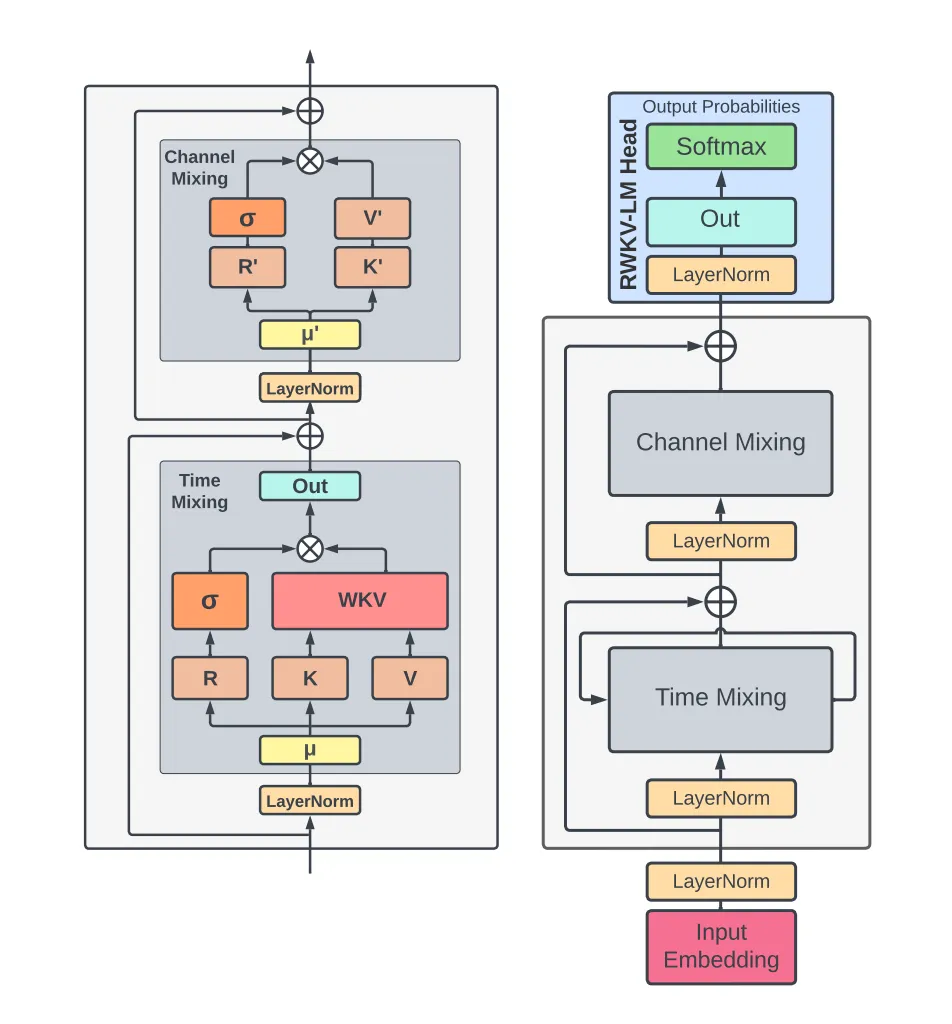
The acronym RWKV comes from each one of these vectors internal to the model:
- R: The Receptance vector acts as the receiver of past information.
- W: The Weight signifies the positional weight decay vector, a trainable parameter within the model.
- K: The Key vector may encode the current token
- V : The Value vector may encode the value we want to encode into the hidden state
There is no Q like in a transformer because we can’t really “query” the past tokens to see which are most interesting. We just have these hidden states (mu) that are being computed and updated.
How does past information get propagated? Let’s look at the WKV Operator:
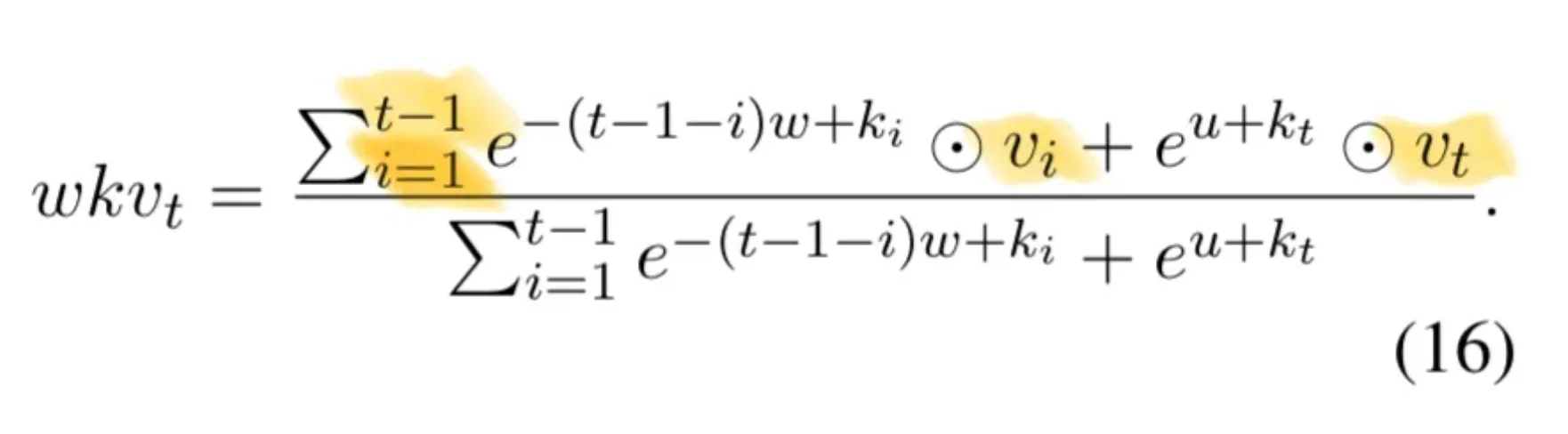
The way that this architecture is parallelized at training time is the fact that the w,k,v vectors are sums from the beginning of the sequence. This means we can compute them in parallel and just sum them at the end.
The time and channel mixing as weighted sum of all past inputs, does give you information all the way back to the start of the sequence, but it is more like mixing paint and blurring all the meaning of the words together. LSTM and Transformers have more detailed accumulation and access to information.
That being said, they have some cool charts in the appendix showing how the information is preserved in the different “channels”. When they say channel, this is just one of the values within the hidden state.
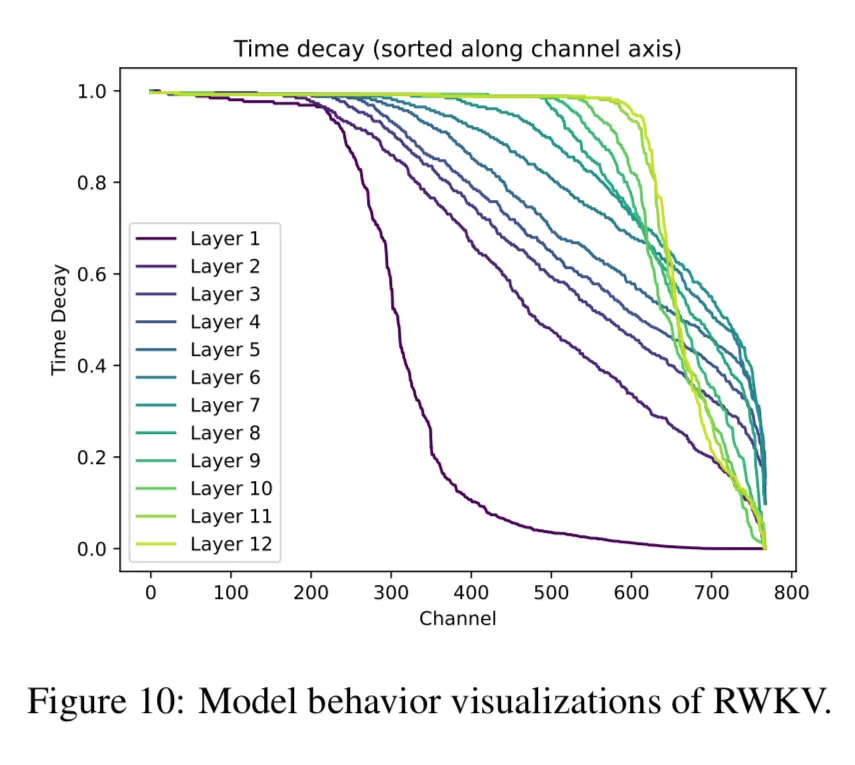
If you look at the last layers, the decay stays close to one, meaning that they preserve most of the information. They theorize that the initial layers preserve less context because they are more focused on things like grammar and syntax and not long range dependencies.
You can also think of the original RKWV as kind of a 1D ConvNet with a kernel size of 2. It’s receptive field increases as you stack these time and channel mix layers up.
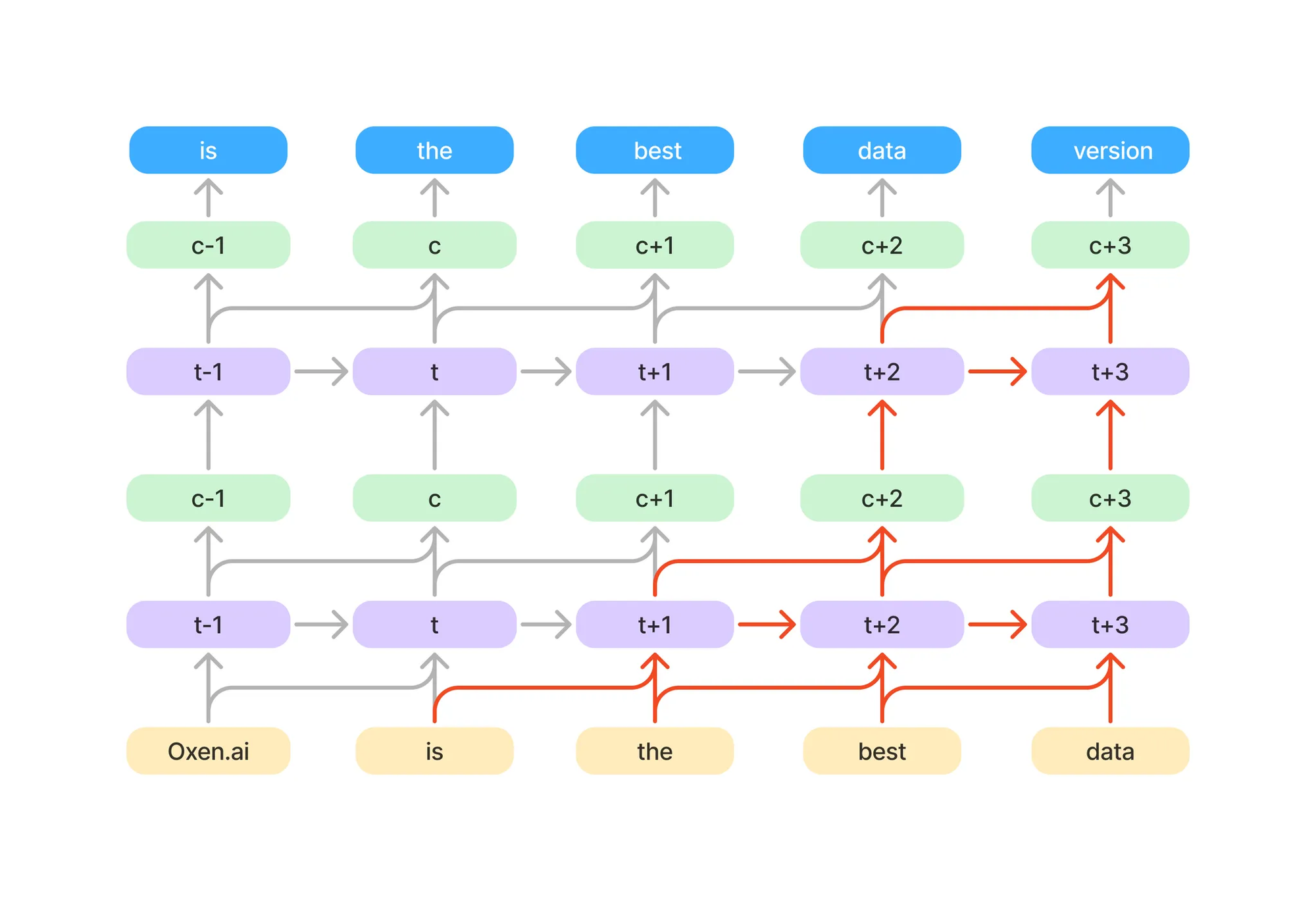
There is a cool visualization of information propagation between the layers too.
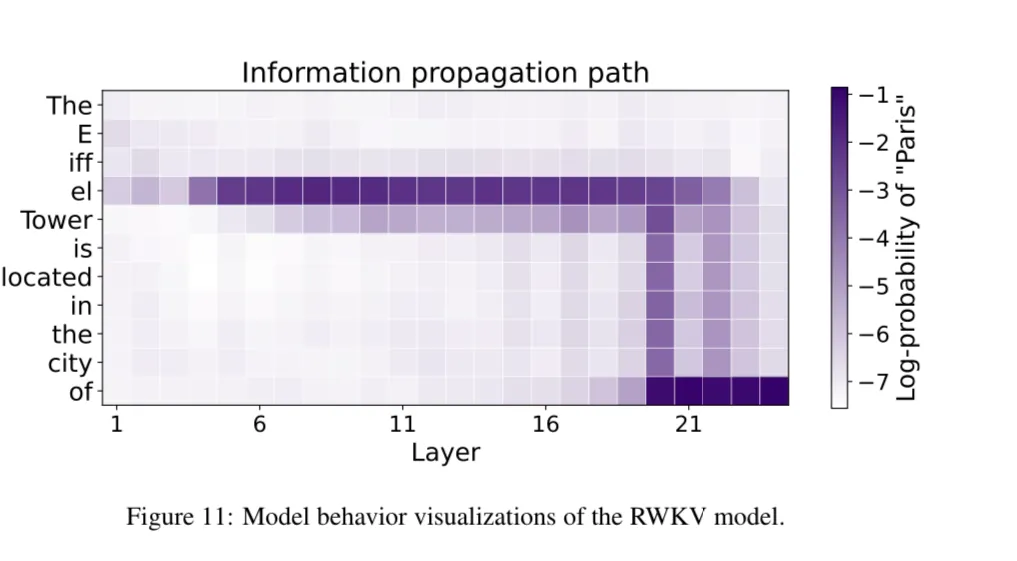
Here they run the model once, recording all the states and activations. Then corrupt the state with “The Eiffel Tower” as the input embeddings, then restore the states and activations of a certain layer then record the log-probs of the layer outputting the correct output ‘Paris’.
In the diagram, you can see that layer 4 has the correct answer by the end of the ‘Eiffel’ tokens and then that information gets passed down to layer 21 by the time it needs to output ‘the city of’.
They do note that RNN’s cannot attend to prompts as well as transformers in the original paper.

Now that you have a good baseline understanding of the original RKWV, let’s dive into how they fix some of these issues in the subsequent models.
Whirlwind Tour from RWKV-4 to RWKV-7
They continue the bird theme with RWKV-5 “Eagle” 🦅, RWKV-6 “Finch” 🐦, and RWKV-7 “Goose” 🪿.
RWKV-5 added “multi-head” or multivalued hidden states so that each head could capture different features of the sequence.
RWKV-6 added a “dynamic recurrence” mechanism that could adapt the way it carried forward information. It did this through LoRA’s internal to the model architecture. These LoRA’s function as the model’s ability to remember and forget parts of the hidden state.
🪿 Enter RWKV-7
Let’s fast forward to the 7th edition of RWKV. In the early editions, there was no great mechanism for information in the hidden state to be removed or updated over time. It was just linear combinations in those time and channel mixing layers and hoping the “paint gets mixed together” in a reasonable way.
If you have been in the field for awhile, you may say the LSTM solves this already with it’s 4 gates.
- Input Gate
- Input Modulation Gate
- Forget Gate
- Output Gate

RWKV-7 has an interesting approach that differs form an LSTM and is inspired by DeltaNet. Google’s recent paper “Titans: Learning to memorize at test time”, has a similar approach BlinkDL jokingly said "Google has caught on to RWKV-7 style models (my design with channel-wise factors is better)"
Google has caught on to RWKV-7 style models (my design with channel-wise factors is better)🤣Attention's days are numbered, because all we need for weak AGI is RNN + CoT + Tool Usage (e.g. external memory, external compiler, external verifier, web browser, ...) https://t.co/DcumRSeS5f
— BlinkDL (@BlinkDL_AI) January 16, 2025
Okay but what is this secret sauce in RWKV that is the key for “Weak AGI”? It’s actually pretty cool. I will give the high level overview, and then Eugene hops in the video to can help guide us on some intuition behind the decisions in certain places.
Learning at Test Time
To understand what any of the jargon in the paper means, we have to understand the intuition behind DeltaNet and how these models “learn at test time”. The idea is using gradient descent during inference to update the hidden state.

Instead of having the model learn weights associated with input, output, and forgetting information, DeltaNet has a loss function that is computed at test time that enforces you to reconstruct the values for given keys given the current state.
The most important part is this loss function here. The loss function is saying we want to minimize the reconstruction error of the key and value vectors at time step T, given the hidden state at time step T.
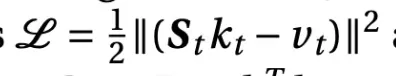
Then we take the derivative of the loss given the hidden state. In other words - in which direction do we want to update the hidden state, to minimize the loss. The derivative is pretty straight forward calculous:
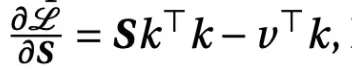
BTW Schmidhuber already did this as well in a paper called “Learning to control fast-weight memories: An alternative to dynamic recurrent networks.”
Their **RWKV Architecture History** blog is a nice read on this as well.
https://wiki.rwkv.com/advance/architecture.html#rwkv-v7

The key sentence here is RWKV-7 does not directly store k,v pairs in the hidden state, but updates the state by learning the relationship between them from the context.
For two vector sequences k_t and v_t transform k_i into v_i through state S.
This makes sense if you think back to our example of the RNN losing information. If the objective is to not store the values, but to be able to reconstruct them from our state, then the state has to hold the right relevant information about the past.
This is an interesting method of remembering/updating information. If you can reconstruct past tokens from the hidden state, then you have likely encoded them well.
They make a tweak to the delta net architecture by adding this diag(w_t) to “increase expressivity”.

Here is the important equation where they add the diagonal matrix and z_t and b_t:
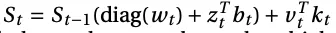
This learnable diagonal matrix can be thought of as giving the model the ability to forget information in a dynamic way (like the forget gate in an LSTM). Intuitively think about all the zeros in a diagonal matrix as giving the model the ability to zero out information from the hidden state.
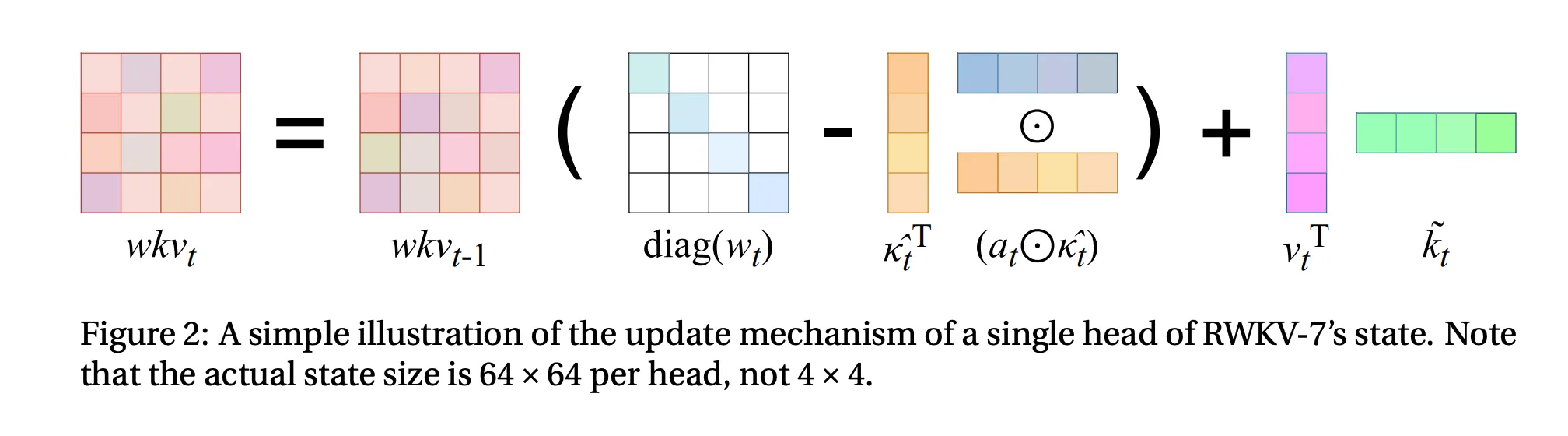
The way I think of the equation is:

In the next section they define z_t and b_t as allowing each key channel in the state to vary independently, which they say keeps the update stable while maintaining expressivity:

They did a few ablation studies in the appendix comparing to DeltaNet if you are curious.
Diving into the full architecture….You’ll see it is similar to the original RWKV with Time Mixing and ReLU^2 MLP (updated channel mixing), but the Time Mixing block is much more complicated. Time Mixing is the most important part - because it is how we keep track of past information.
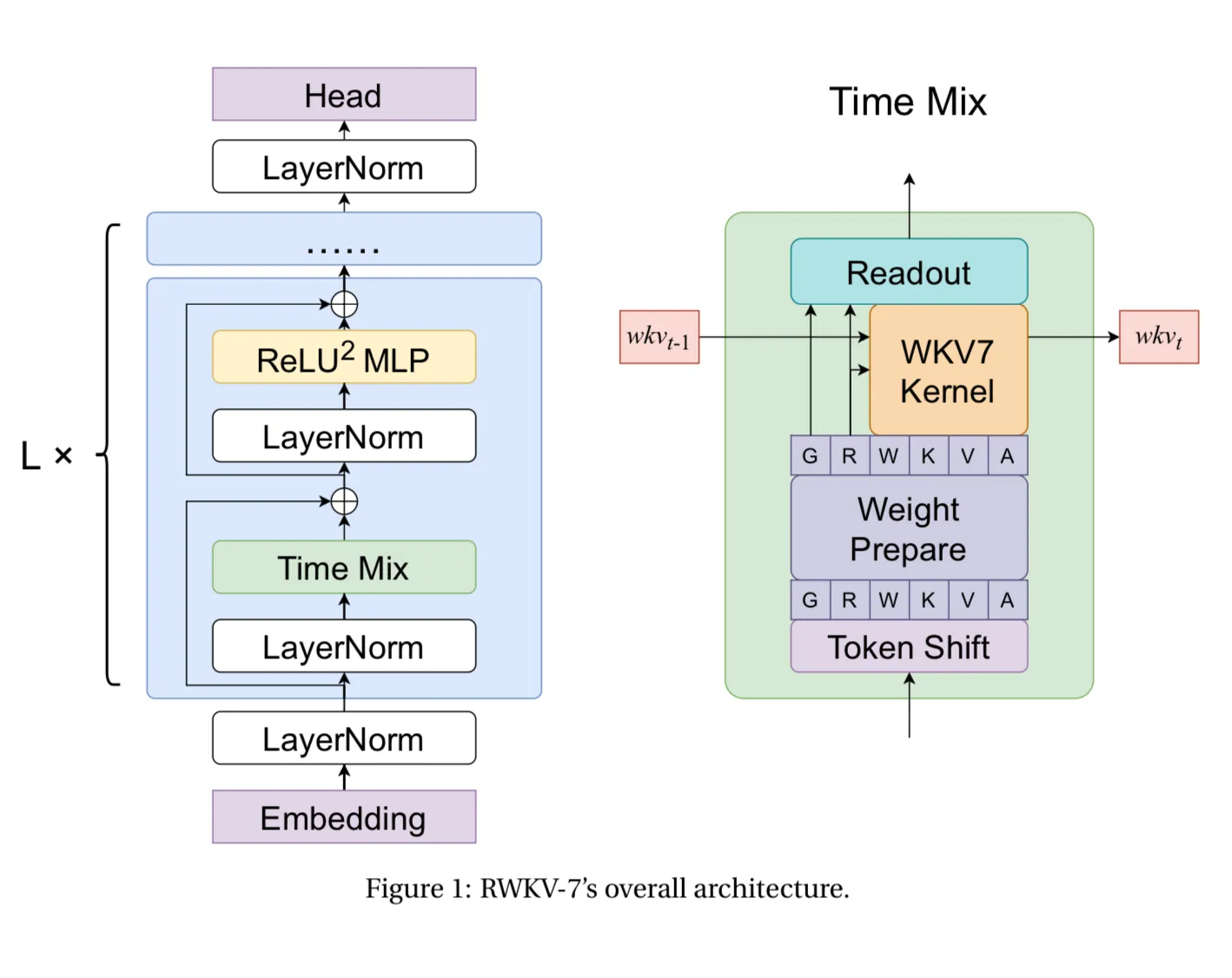
The following may make your eyes glaze your eyes over with every detail (because there are a lot). When we chatted with Eugene he said this is a bit like an evolutionary algorithm with the community. They add modules, see what helps, see what hurts, and iteratively update the architecture with modules that help.

Each individual node in the new time mixing block is defined here, with their intended behaviors.

Putting it all together:
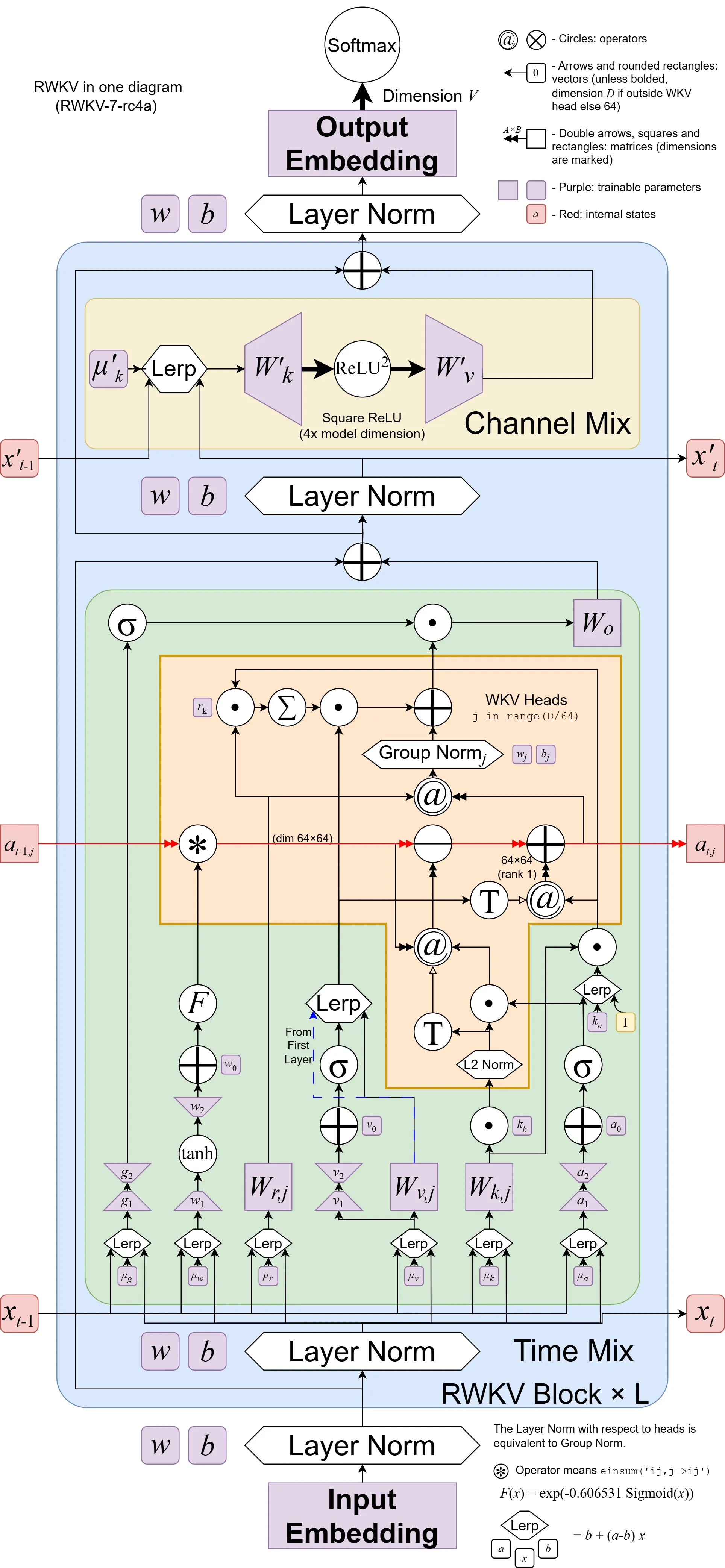
If this is a lot - just remember, they “learn at test time” by using a simple gradient descent update to update the hidden state. This gives us a more fine grained paint brush while updating the hidden state.
If you want to see the psuedocode for the model, it is also in the Appendix of the paper.
Parallelization During Training
Similar to the parallelization we saw for the original RWKV, RWKV-7 can be written in a way that you can compute all the updates in parallel and then take the product at the end.
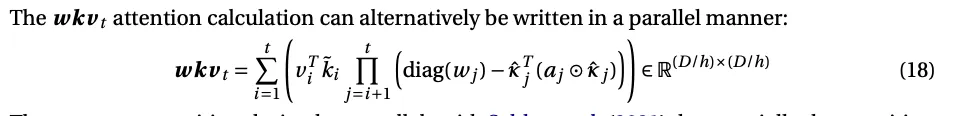
Note: wkv_t here is S_t (the state) from earlier, I’m not sure why they redefined it as a more confusing variable name.
How well does it do on benchmarks?
The 2.9B parameter model out performs even 7B parameter transformer models on a per-training-flop basis. Meaning it needs less compute and less parameters to get even higher accuracy.
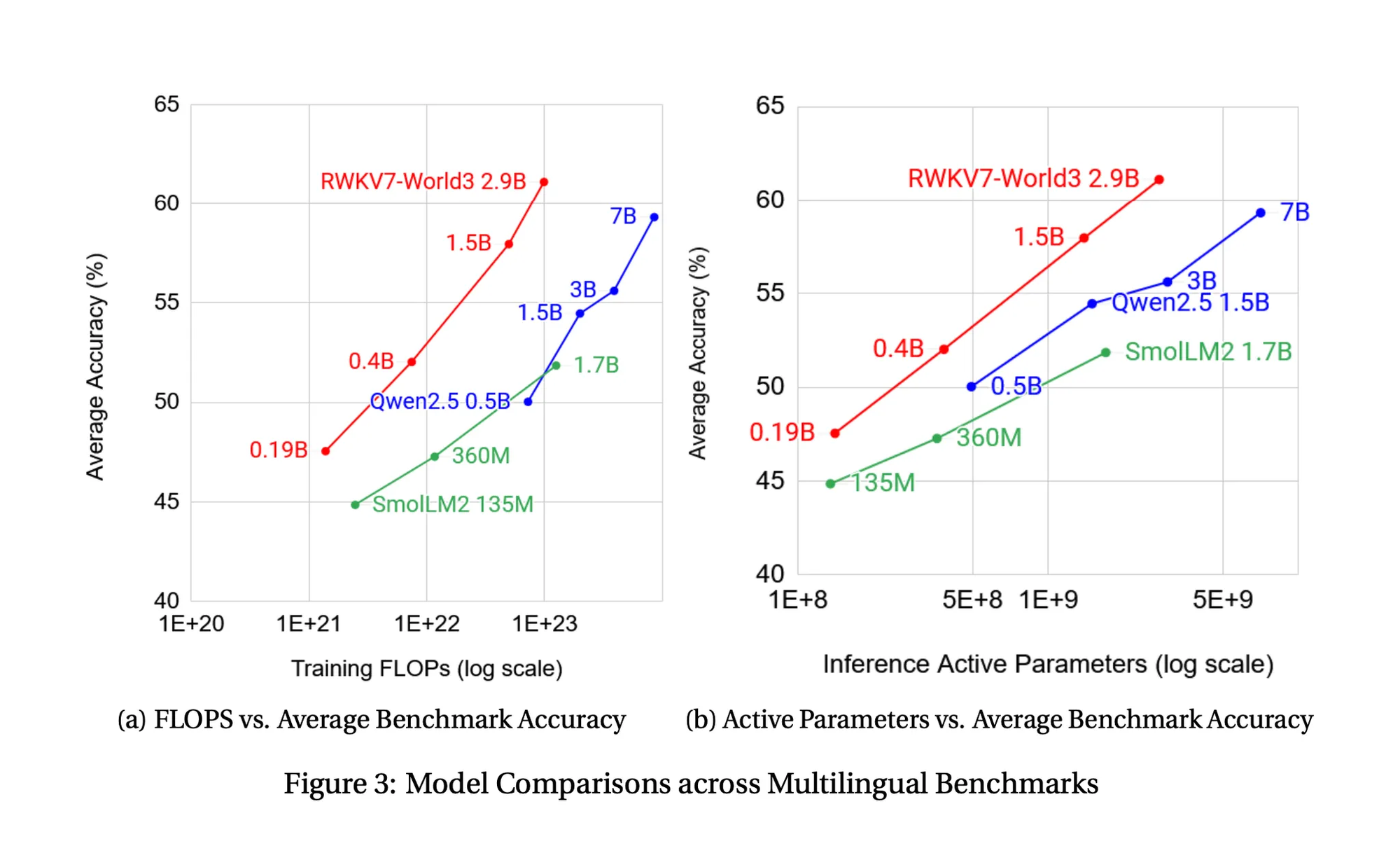
This is very interesting scaling laws implications, because this was the big insight that lead to people scaling up transformers. Transformers were more efficient per flop than other models at learning. We saw this in the ViT paper comparing transformers to CNNs.
Limitations

Demo
Now that you understand what’s going on under the hood, it's your turn to spin up RWKV-7 and test it out for yourself. Crowd participation welcome, I want to get a sense of the vibes. Grab the following Notebook and spin it up on a GPU on Oxen.ai to follow along:

Personally, I wanted to test RWKV with the use case of generating SQL from natural language. If you don’t know, we have the ability to query any dataset in natural language in Oxen.ai. We are currently using GPT-4o on the backend and it is costing us real $. My intuition is that this task, especially for a single table, can be done with a much smaller language model.

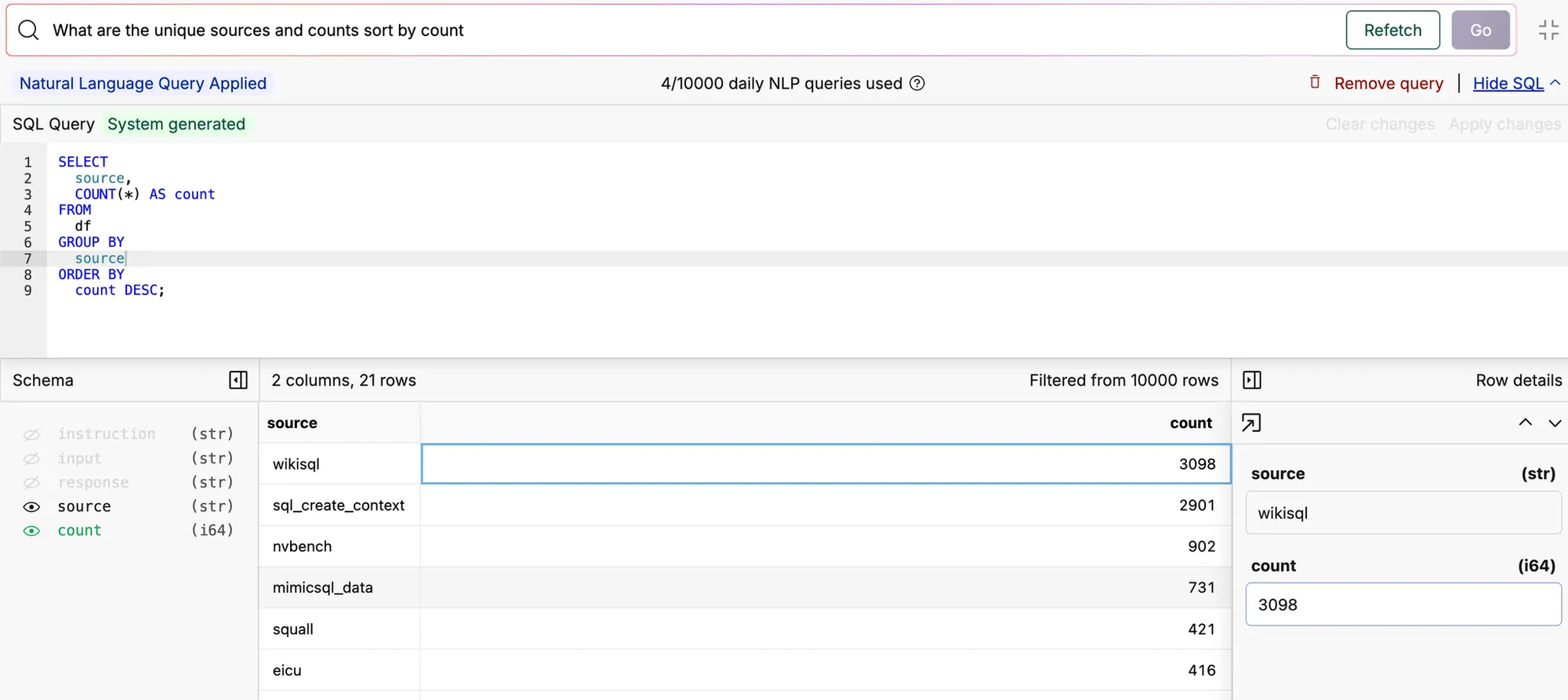
Here is some test data:

Here is a test Notebook to evaluate the current RWKV model:

Eugene on the call said that instead of fully fine-tuning the model, it would be interesting to just "Learn at Test Time" by running inference over the entire training set. Then we can save the hidden state and boostrap the model with this state during evaluation. This is a clever trick that gets around some issues with fine-tuning like catastrophic forgetting in the model.
Wrapping Up
If you enjoy these deep dives, please subscribe to our blog and YouTube channel.

If you want to attend live, you can join the community here:

Working in AI/ML? Create an account on Oxen.ai and try our latest and greatest.


Member discussion