
How to Fine-Tune Qwen3 on Text2SQL to GPT-4o level performance


Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open source model and put it head to head against a closed source foundation model on a specialized task. We will be giving you practical examples with reference code, reference data, model weights, and the end to end infrastructure to reproduce experiments on your own.
The format will be live on Zoom at Friday, 10am PST, similar to our Arxiv Dive series in the past. The recordings will be posted on YouTube and documented on our blog.
Heres the vid:
All the code, datasets, and model weights from today's session can be found in the ox/Text2SQL dataset on Oxen.ai.

Want to try fine-tuning? Oxen.ai makes it simple. All you have to do upload your images, click run, and we handle the rest. Sign up and follow along by training your own model.
🧪 The Formula
Each week we will apply the same process and formula, where multiple models enter the chat, and only one emerges victorious.
- Define our task
- Collect a dataset (train, test, & eval sets)
- Eval an open source model
- Eval a closed source model
- Fine-tune the open source model
- Eval the fine-tuned model
- Declare a winner 🥇
You may be tempted to skip to the fine-tuning step, after all this is Fine-Tuning Fridays! This would be a mistake. In the long run, having a systematic approach to setting up eval metrics, curating high-quality datasets, and having an error analysis pipeline will save you time and give better results.
Here’s a sneak preview of the final accuracies to motivate the rest of the work.
| Model | Accuracy |
|---|---|
GPT-4o |
45% |
Qwen3-0.6B |
8% |
SFT_Qwen3-0.6B |
42% |
SFT_Qwen3-1.7B |
57% 🥇 |
Fun fact: It took me longer to write this blog post than it did to setup all the evals and fine-tuning jobs in Oxen.ai.
🐂 Oxen.ai Workflow
Roughly, this is what the end to end workflow looked like to benchmark these three models. There are a lot of tools within the Oxen.ai tool belt can help train/eval models. It’s a matter of how you wire them together into a workflow that makes sense for your use case.
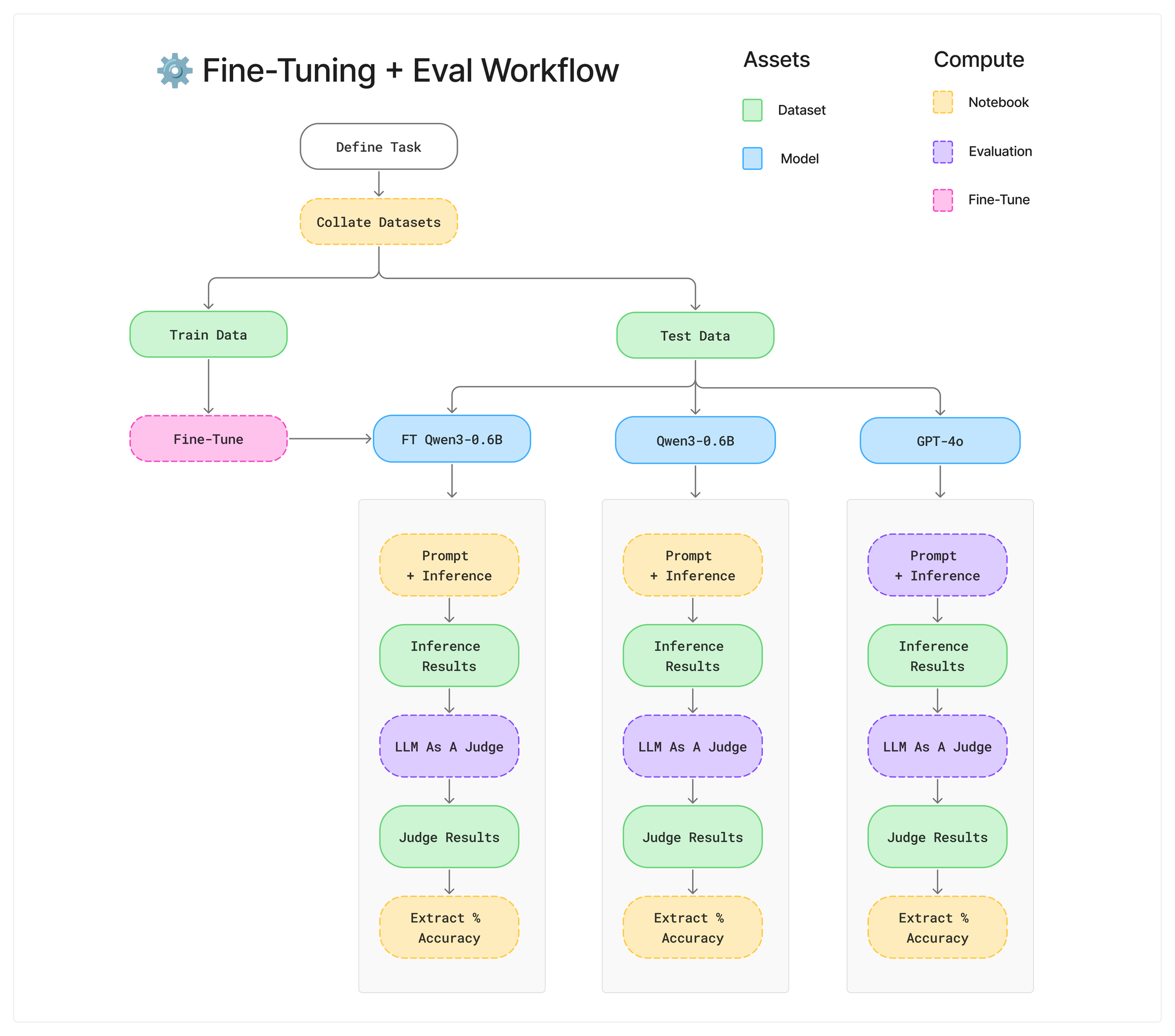
We are working on making it easier to chain workflows together and automate pipelines like this end to end. Today we are going to show you the intermediate steps and outputs so you can get an intuition on how it all works.
The Task
This week, we will be putting a small but powerful model to the test on a task that users on Oxen.ai use every day: converting natural language to SQL (or Text2SQL).
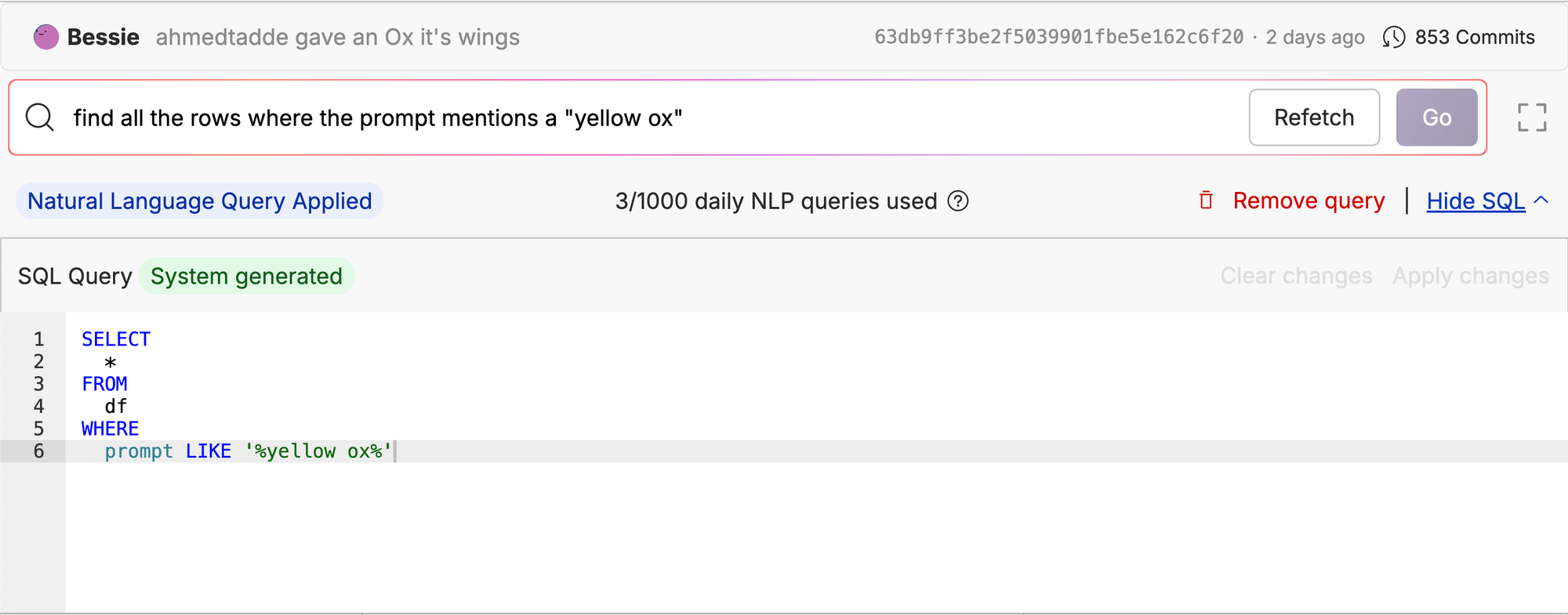
In Oxen.ai we utilize Text2SQL to help users explore their datasets. After uploading a dataset to Oxen.ai, you can write a query in plain english to find data you are interested in. I don’t know about you, but I rarely remember the exact SQL syntax for every query I want to run.
For example, here we are searching our ox/FlyingOxen repo for all the yellow oxen. We translated the user-input text from "find all the rows where the prompt mentions a 'yellow ox'" to SQL, and now we can see all images with a prompt that contains yellow ox.
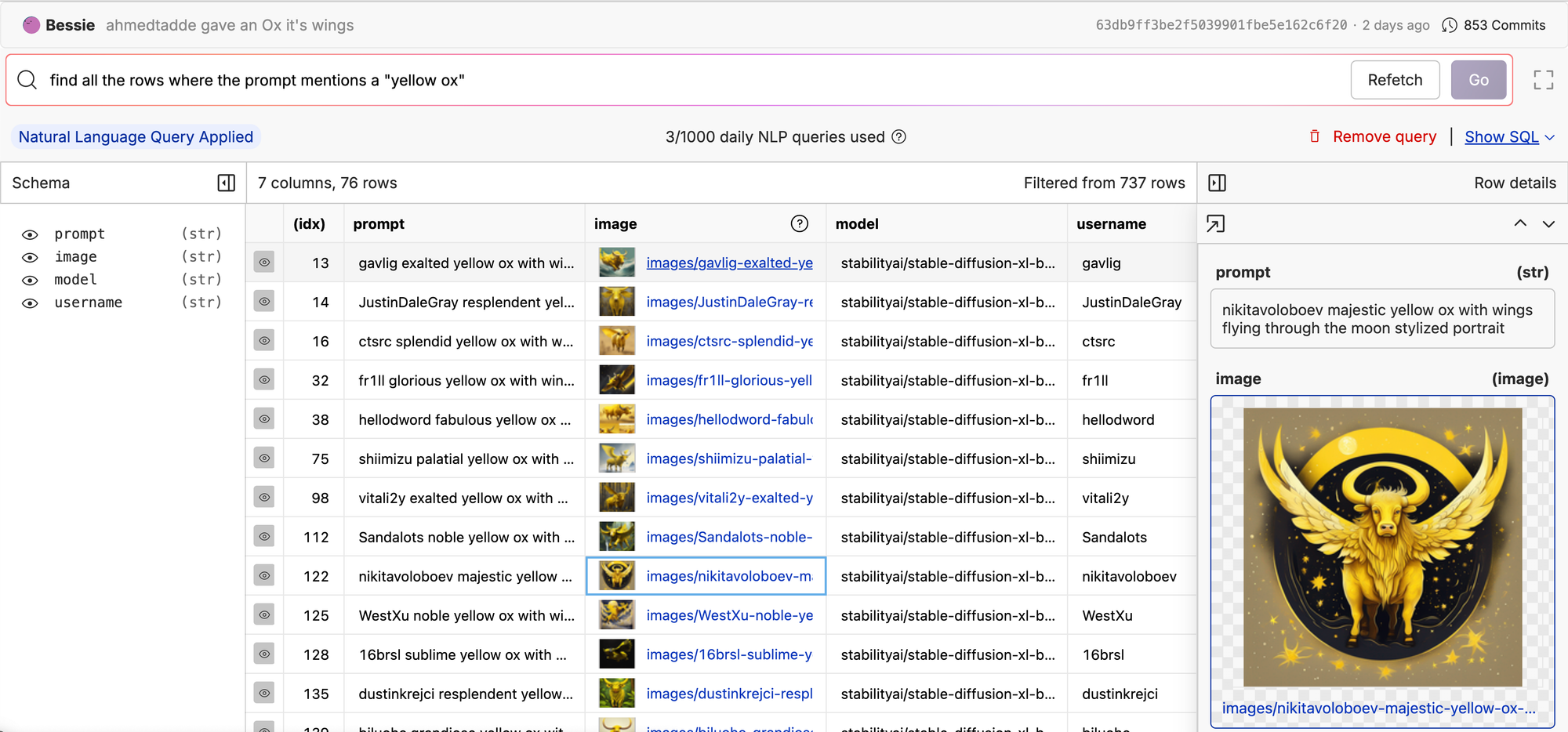
Our version of Text2SQL is a bit more constrained than you might see in other production systems, because it is limited to extraction from a single table. If you look at the SQL query closely, you’ll notice that we always reference the current table as df. This will be important when it comes to our data collection stage.
SELECT
*
FROM
df
WHERE
prompt LIKE '%yellow ox%'In other production environments you may have more complex queries that need to JOIN across tables or do multi-step lookups. For simplicity we are ignoring those use cases for now.
The Models
Today we are going to be putting GPT-4o head-to-head with Qwen/Qwen3-0.6B . OpenAI’s GPT-4o is a great choice to get up and running quickly and prove out a concept. Once you reach scale it can be expensive and you have less control over it’s behavior.
Our initial implementation of Text2SQL was a simple prompt and API call to OpenAI’s gpt-4o-2024-08-06. The prompt behind the scenes is pretty simple:
Write a SQL statement that is equivalent to the natural language user query below. You are given the schema in the format of a CREATE TABLE SQL statement. Assume the table is called "df". DO NOT give any preamble or extra characters or markdown just the SQL query in plain text. Make sure the SQL query is on one line.
Schema:
{schema}
User Query:
{query}
SQL Query:
The question is, can we get similar or better performance with an open source model that we control? If it is small enough we could potentially embed the model in the browser or in our server and save 💰.
The first model that comes to mind is Qwen/Qwen3-0.6B from the latest release from the Qwen team. This is a small, light weight model that has been pre-trained on 36 trillion tokens and post-trained to have both a “thinking mode” (for complex, multi-step reasoning) and “non-thinking mode” (for rapid, context-driven responses). You can learn more about these models from their research paper.
For our use case we will be using the “non-thinking mode” since we just quickly want the model to output SQL query, and it shouldn’t take too much reasoning.
The Datasets
Before going too much further, it is important to decide on the dataset we are going to evaluate on. The best dataset to evaluate on is typically the data that flows in and out of your production system. In our case, we have been logging queries that users execute on public datasets. We will select a subset of this data and use it to get a baseline of performance. The data has been filtered down to queries that successfully returned a results set.
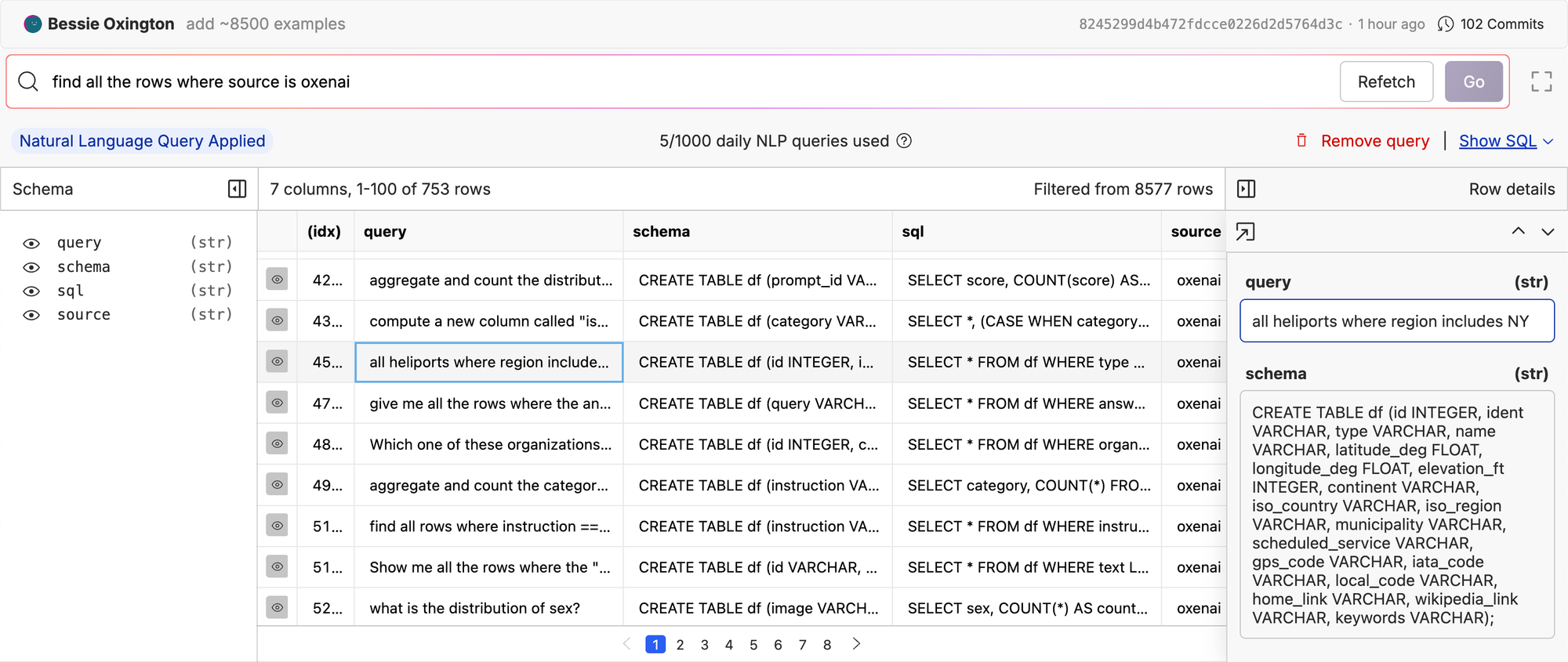
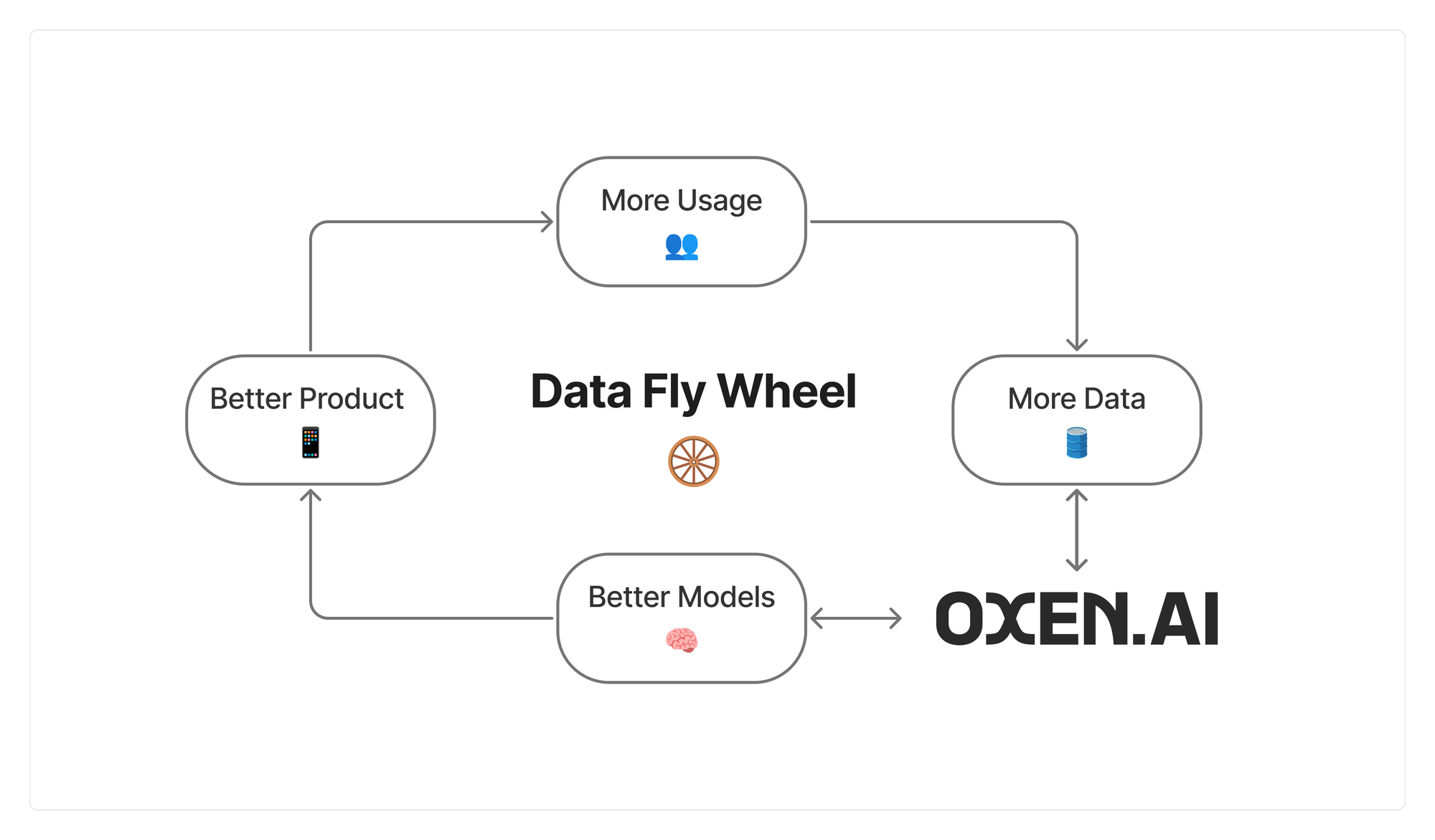
The idea is that this will kick off our data fly wheel. The more users that query datasets on Oxen.ai, the better the Text2SQL engine model will get, causing more users to use the feature, etc. It is a self re-enforcing loop.
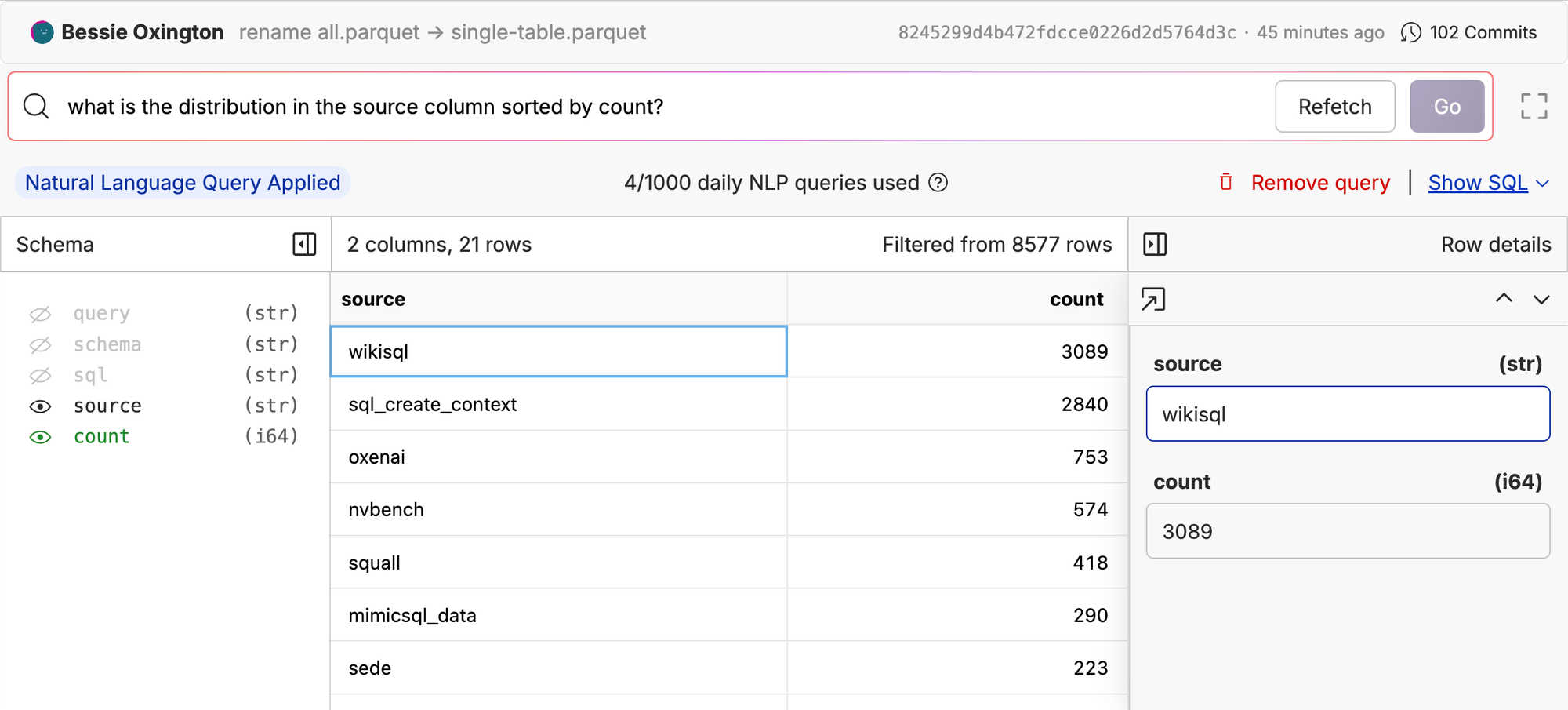
There are also public datasets for Text2SQL that will give us a more diverse dataset to train and evaluate on. We collated some examples from sources like wikisql, spider, sql_create_context, nvbench and more. These sources have examples with more than one table, so filtered down the data to queries that only involved one table. This gave us a total of ~8500 examples.
You can explore the raw data here: https://www.oxen.ai/ox/Text2SQL/file/main/single-table.parquet
When you are fine-tuning, it is good to smart small and then scale up. We first tested with 1000 examples to see the code working end to end, then scaled the training set up to 5000 examples when we felt confident in the hyper parameters and training setup.
Here are the final splits:
Train: https://www.oxen.ai/ox/Text2SQL/file/main/train.parquet
Test: https://www.oxen.ai/ox/Text2SQL/file/main/test.parquet
Validation: https://www.oxen.ai/ox/Text2SQL/file/main/valid.parquet
Eval Strong Model
With the datasets prepared, we can start evaluating the models head to head. Let’s take the prompt that we have in production and run it on our validation dataset to get a baseline. We used Oxen.ai’s Model Playground to iterate on the prompt. The playground allows you to test a prompt over an entire dataset interpolating the column values for each row. Feel free to grab the following prompt and try it yourself.
You can look at the raw results here: https://www.oxen.ai/ox/Text2SQL/evaluations/211c9d8d-5450-4afa-a2be-bf75fa802218
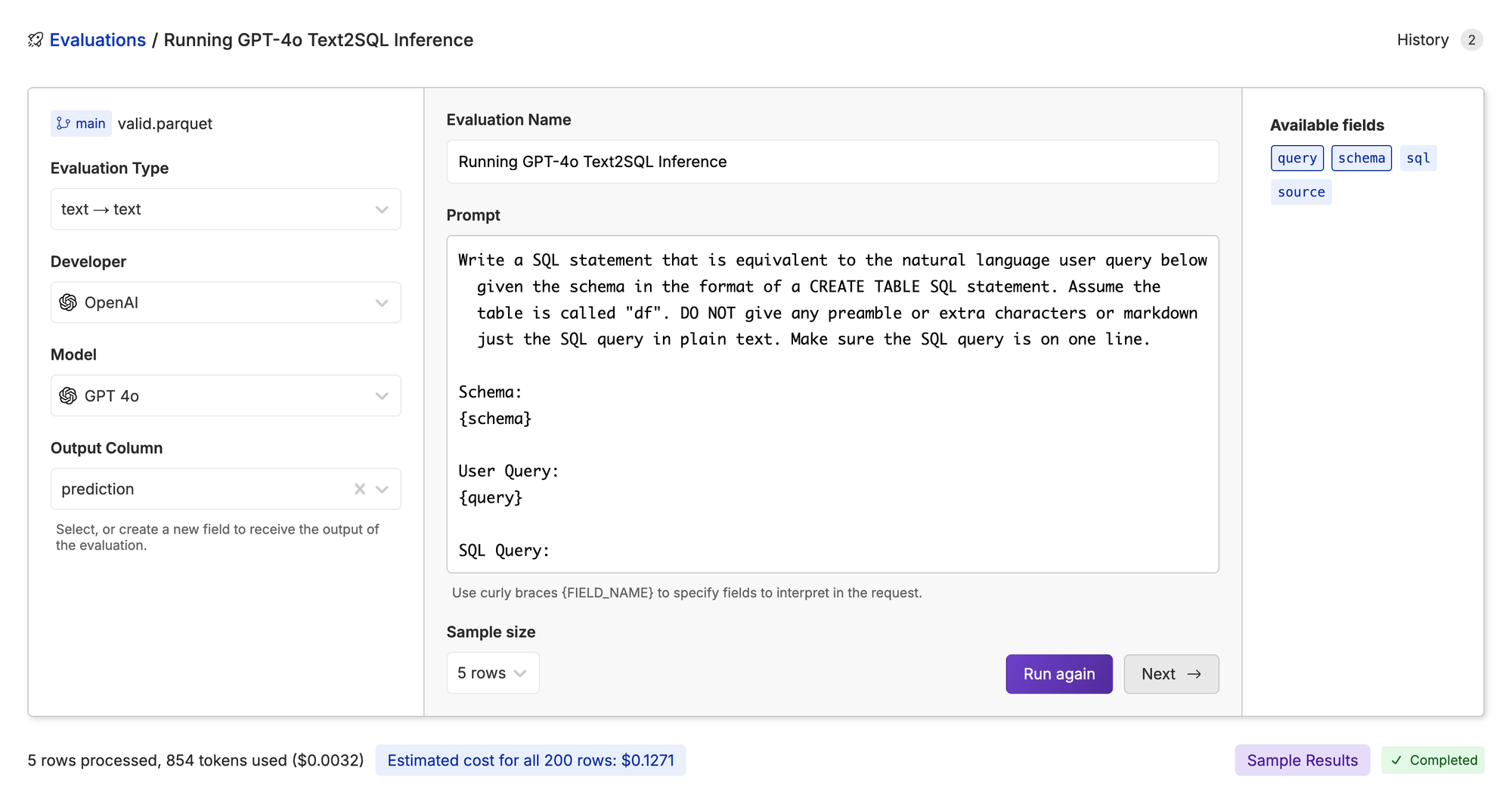
Write a SQL statement that is equivalent to the natural language user query. You are given the schema in the format of a CREATE TABLE SQL statement. Assume the table is called "df". DO NOT give any preamble or extra characters or markdown just the SQL query in plain text. Make sure the SQL query is on one line.
Schema:
{schema}
User Query:
{query}
SQL Query:It’s important to look at the sample responses as a gut check before running the model on the full dataset.
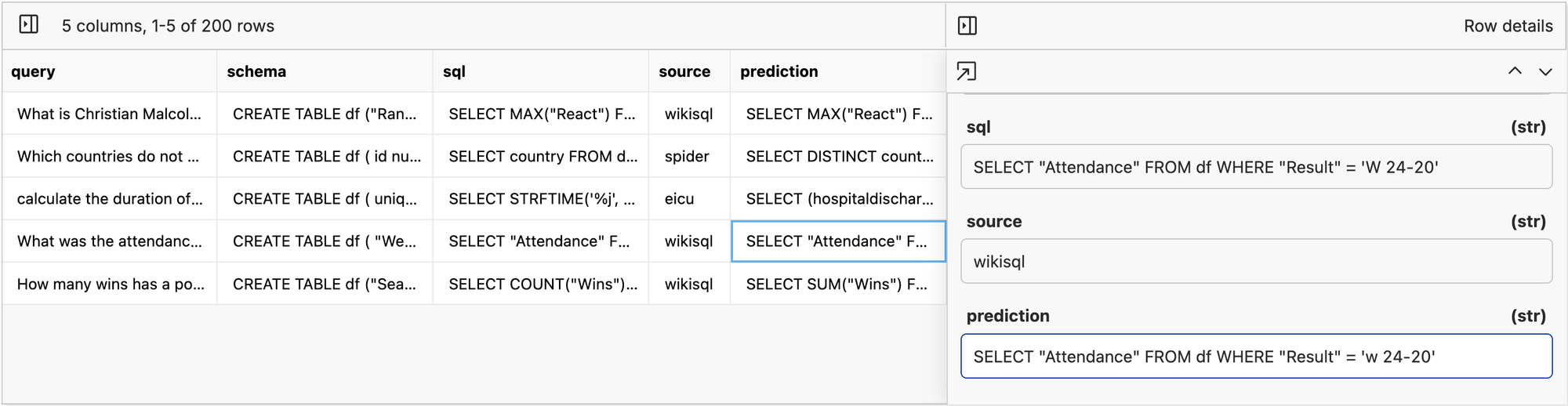
Once you are happy with the sample results, you can kick off a full run saving the data to results/valid/gpt-4o.parquet.
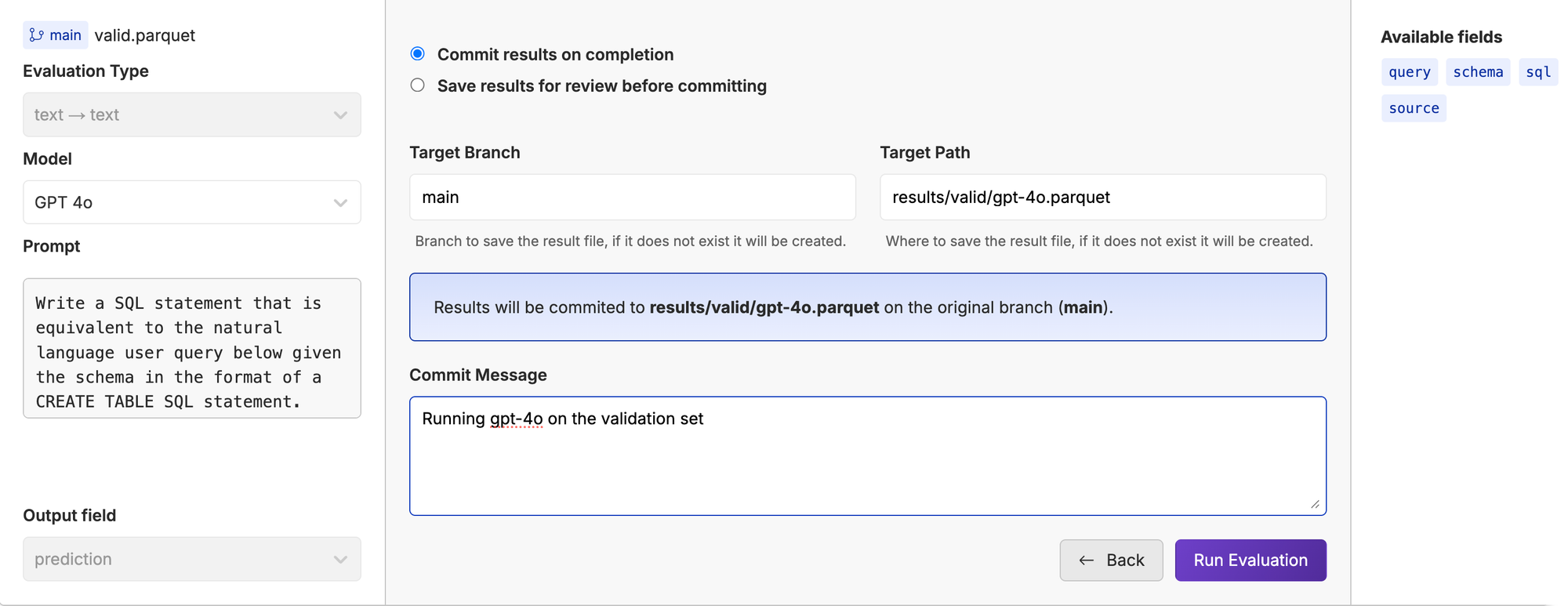
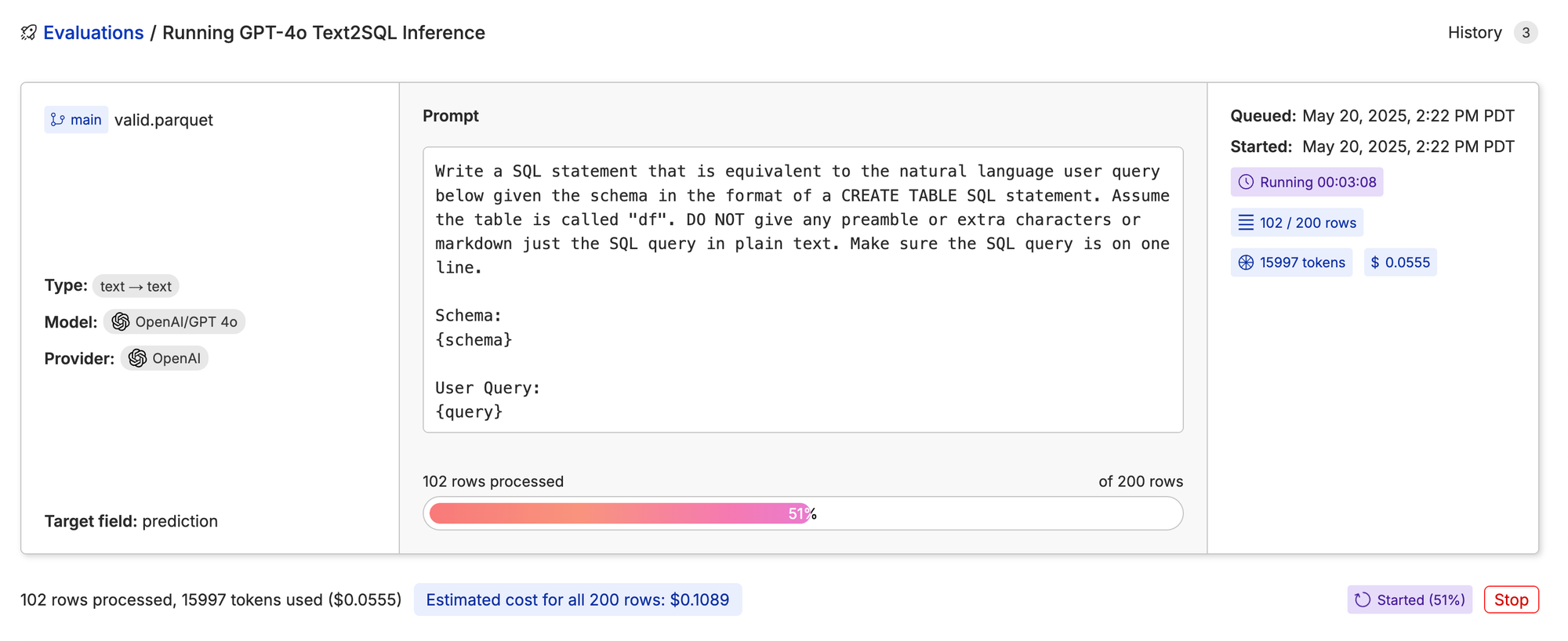
Sit back and let Oxen.ai do the grunt work.
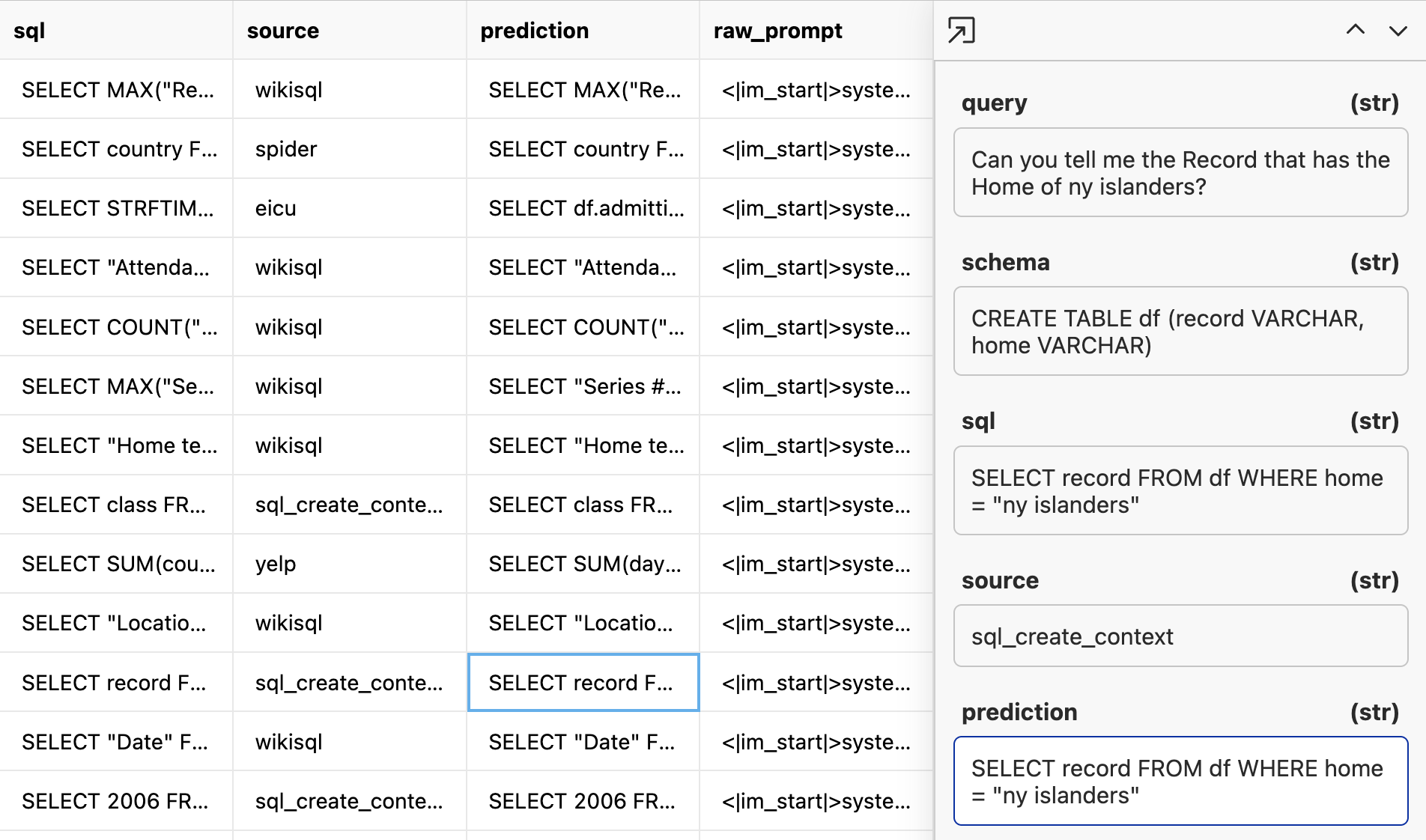
When it is done, we will have a dataset of expected sql and a prediction from the model. In a perfect world, the SQL statement is a direct string match with the model prediction like below.
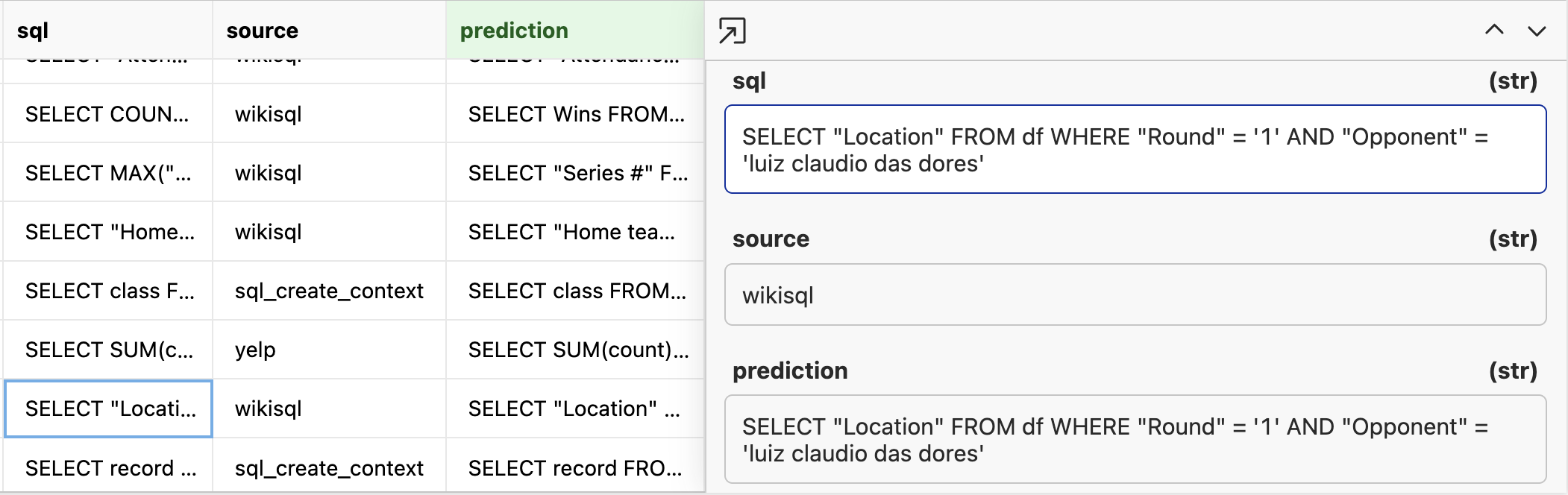
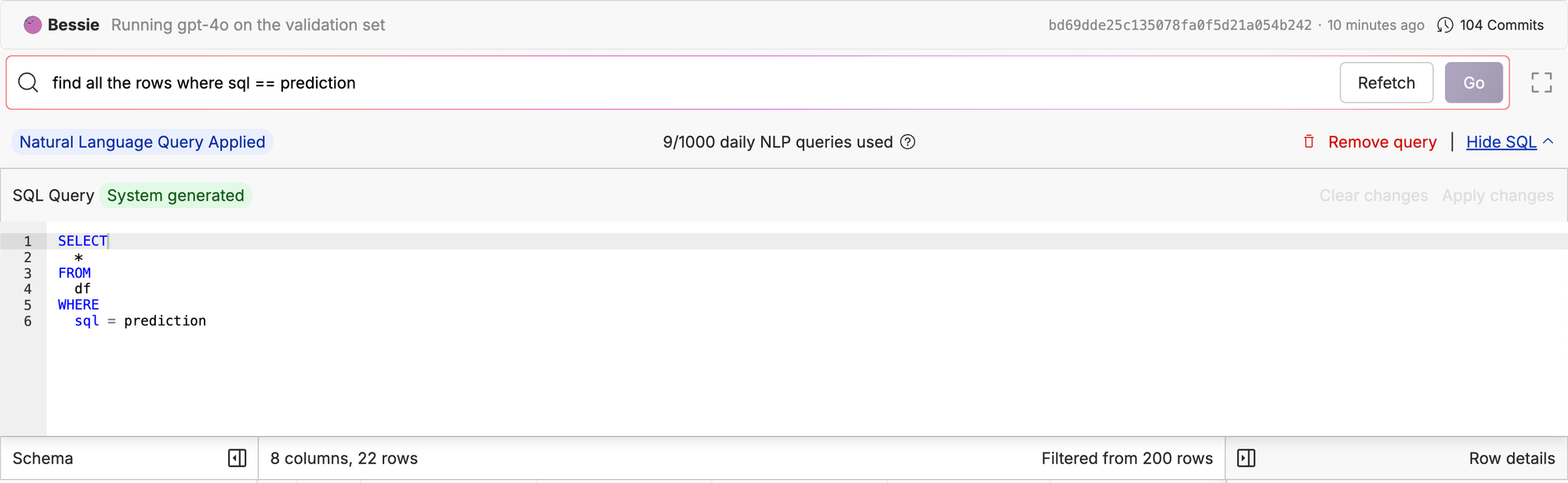
If we just do a raw string match query we can see that on 22/200 (11%) of the data is a direct string match from our ground truth.
In reality, there will be multiple valid SQL statements for a given user query. For example, you may have an AND statement that has the order swapped, but is still a valid query. There are other things like the use of quotes and capitalization of letters that are debatable as to whether they are actually equivalent.
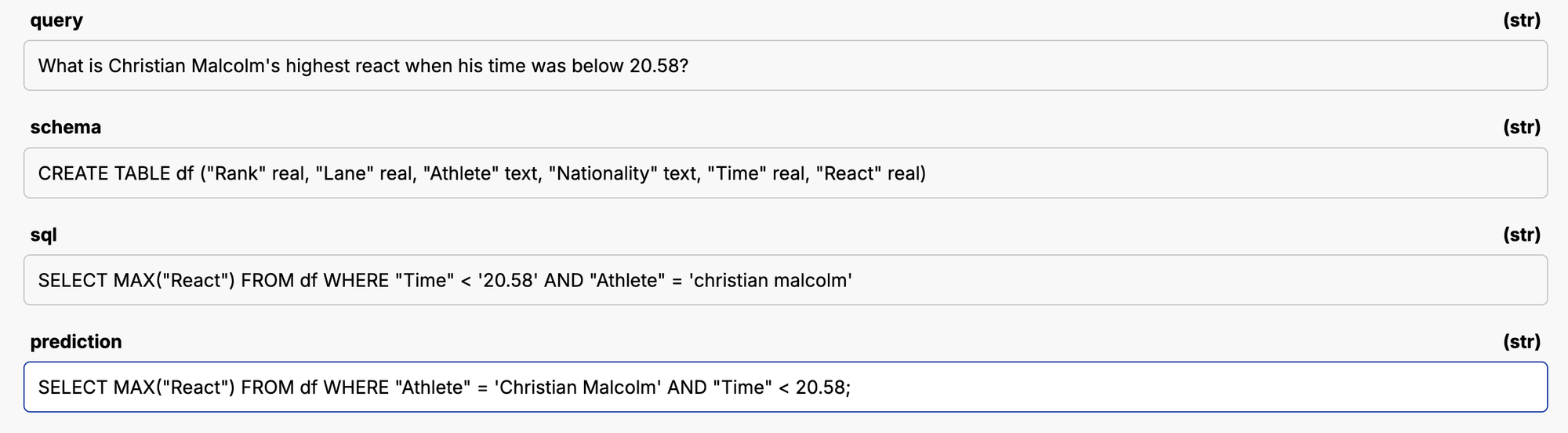
Here’s another example, these will both give aggregations sorted by count, but one does Count(*) and the other does Count(Fate).
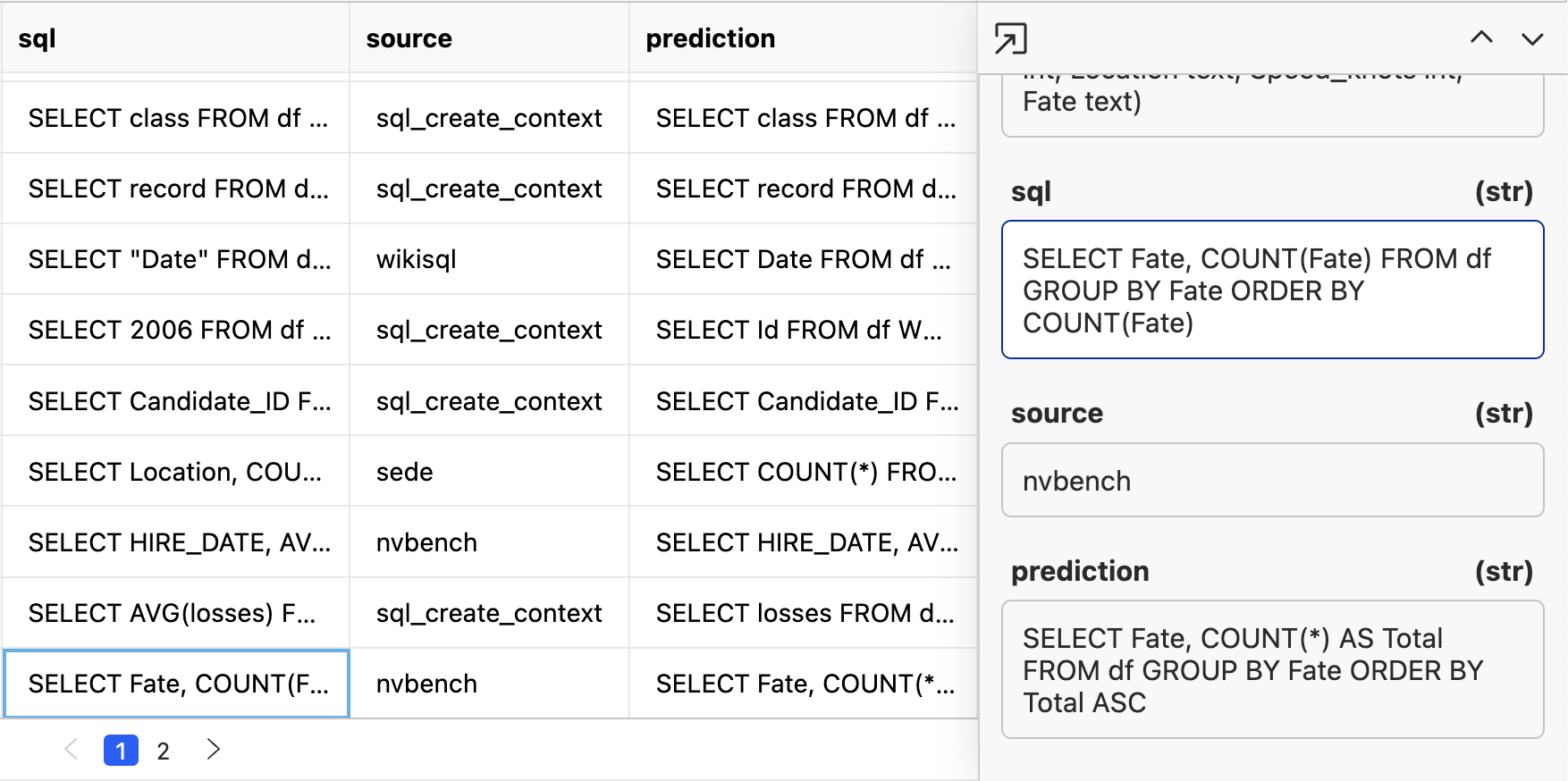
Since there are many variations of correct answers, this is a good use case for using an LLM As A Judge that looks at the outputs and checks if they are equivalent. To make the eval fair, let’s loop Google’s Gemini model in so that it is a separate model provider judging the outputs. We don’t want to let the same model generate the outputs and do the judging as LLMs tend to prefer their own responses over others.
Compare the following SQL statements given the database table to see if they are equivalent. If they are not the same, give a reason as to why. Format your response with two xml tags, one for the reasoning, and one a true or false statement indicating whether or not the statements are the same. Do not include any markdown surrounding the xml.
For example:
<reason>
The reason the statements differ.
</reason>
<answer>
true or false
</answer>
Are these two SQL statements equivalent given the schema:
Schema:
{schema}
Statement 1:
{sql}
Statement 2:
{prediction}Checkout the prompt and raw responses here: https://www.oxen.ai/ox/Text2SQL/file/main/results/valid/GPT-4o-judgements.parquet
This puts the judgements in format in which we have to extract the accuracy. We are leaving room for the model to reason through why the statement matches or not instead of making it go directly to the answer.
<reason>
Both statements aim to return the countries that have entries where the opening_year is not greater than 2006. Statement 1 uses EXCEPT to subtract the countries with opening_year > 2006 from all countries. Statement 2 uses NOT IN to filter the countries, only selecting those that are not in the subquery containing countries with opening_year > 2006. Thus they are equivalent.
</reason>
<answer>
true
</answer>To extract the accuracy we can use a notebook that extracts the values from the column.
https://www.oxen.ai/ox/Text2SQL/file/main/notebooks/extract-accuracy.py
The notebook allows us to put in a repo and filename and compute the accuracy. Under the hood we use a simple regex to extract the answer from the xml.

Okay we’ve got our baseline to beat. We know GPT-4o can at least get 91 / 200 = 45% accuracy on this test set.
Evaluating Qwen/Qwen3-0.6B
Now for the smol but mighty Qwen/Qwen3-0.6B. Let’s start by running the same prompt through our validation dataset.
Qwen3 has 2 modes of operation: Thinking Mode and Non-Thinking Mode.

To keep things a little more simple, we are going to run Qwen without thinking. This will make API calls snappier, and if we are fine-tuning - we should be able to encode the translation directly in the model weights without making the model “think” out loud.

We will be running Qwen in an Oxen.ai notebook instead of the inference service to have a bit more control over the thinking/non-thinking mode, and compare the model apples to apples after our fine-tune.
https://www.oxen.ai/ox/Text2SQL/file/main/notebooks/eval.py
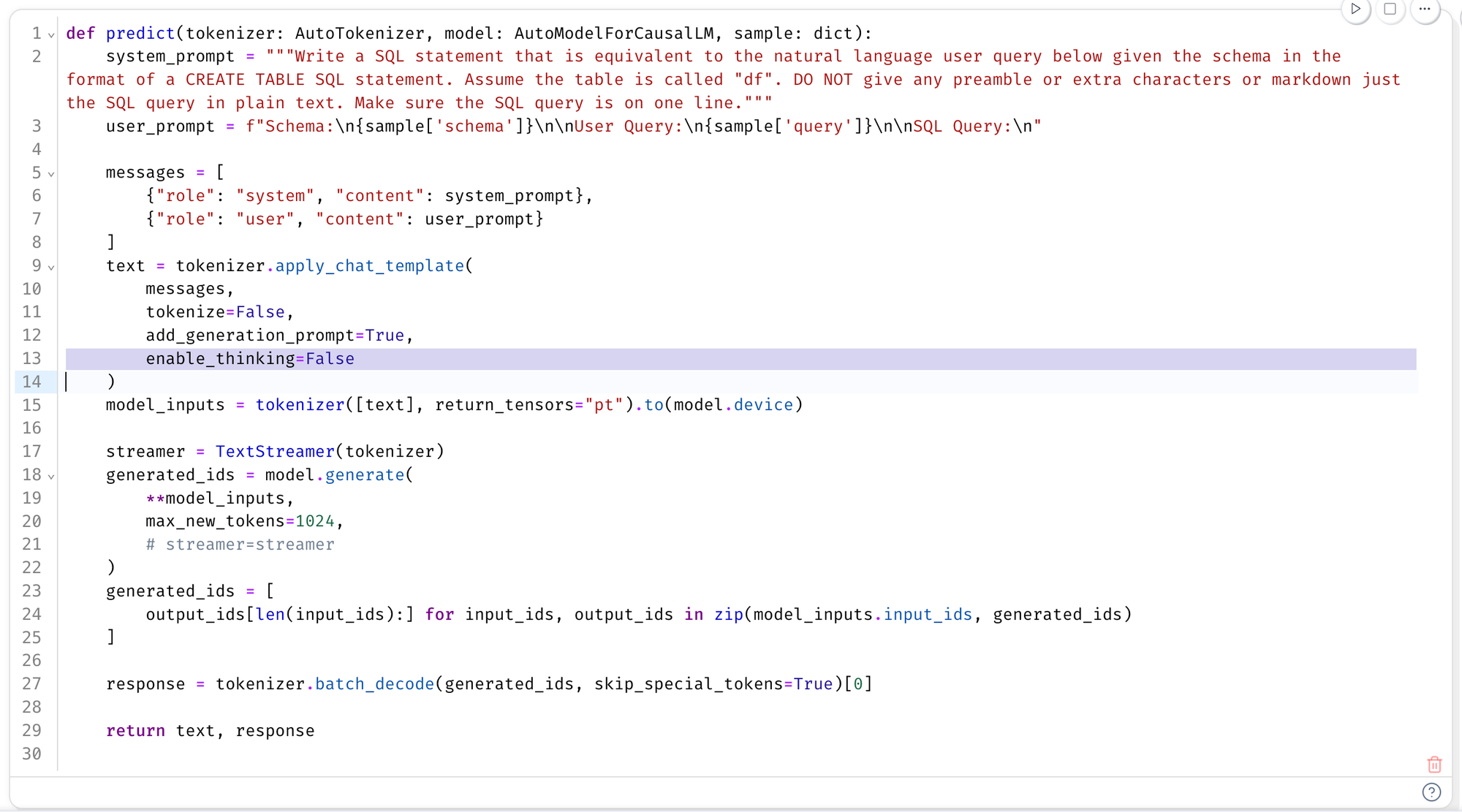
The most important line to disable “thinking” is line 13 in the predict function below. The rest is pretty standard given the transformers library. We are using the prompt as before, putting the instructions in the system prompt.
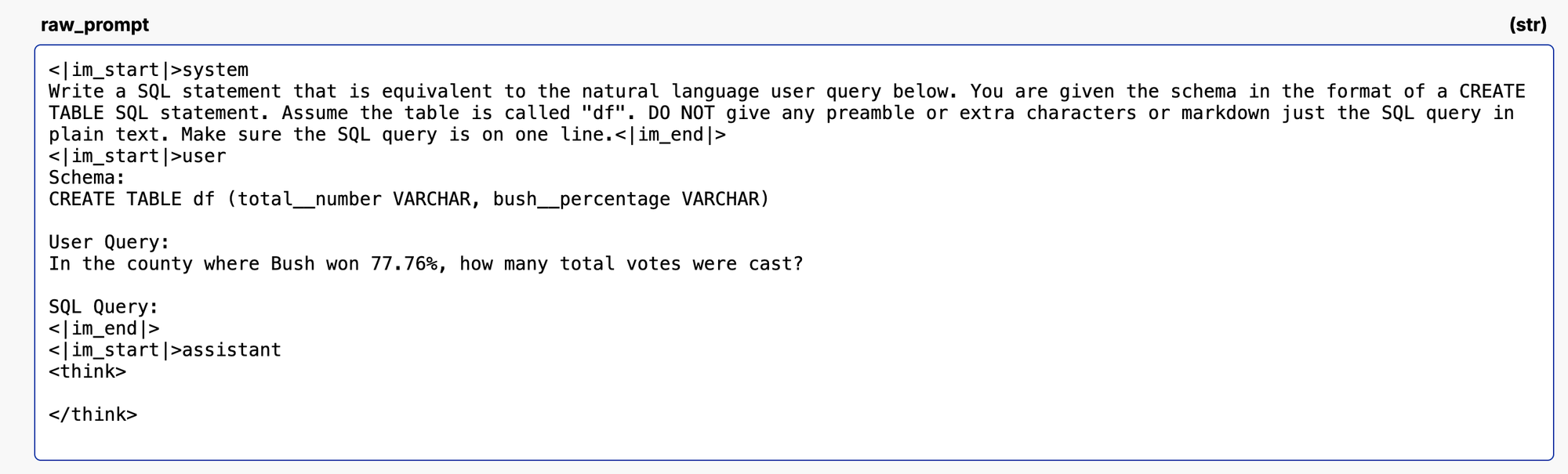
Under the hood, this creates an input chat template that looks like this:
Poor little Qwen3-0.6B really got the assignment wrong. It decided to write a lot of CREATE TABLE statements instead of the SQL statements themselves. Scan down the rows and you will quickly see this model is not great out of the gate.

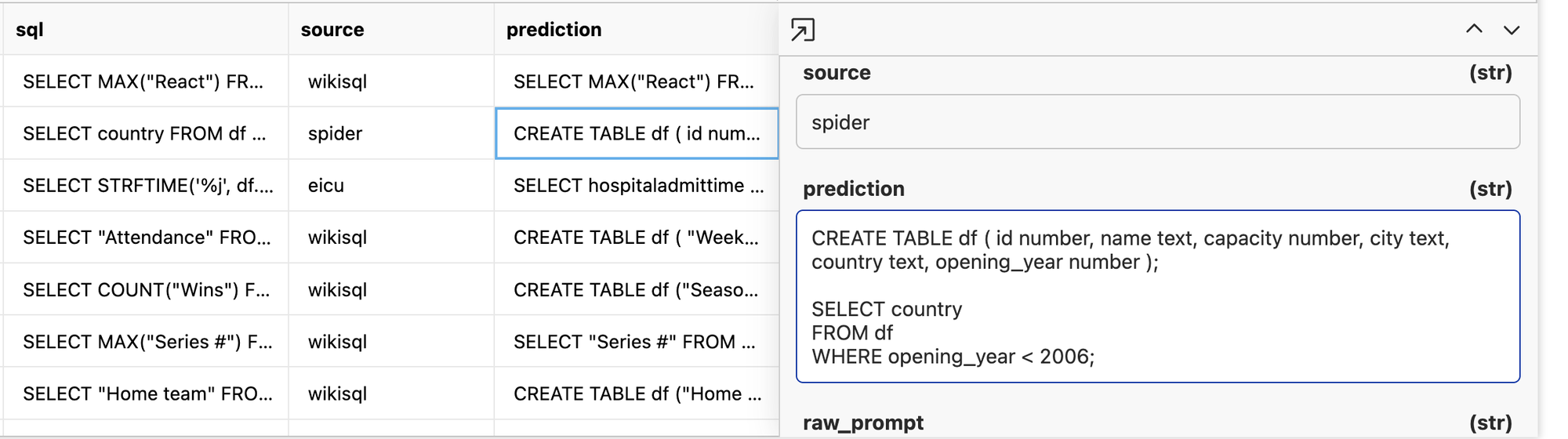
Let’s run LLM as a judge on this results set to see if it got anything right.
https://www.oxen.ai/ox/Text2SQL/evaluations/c387a9df-596a-4552-a944-b5c1a191ff31
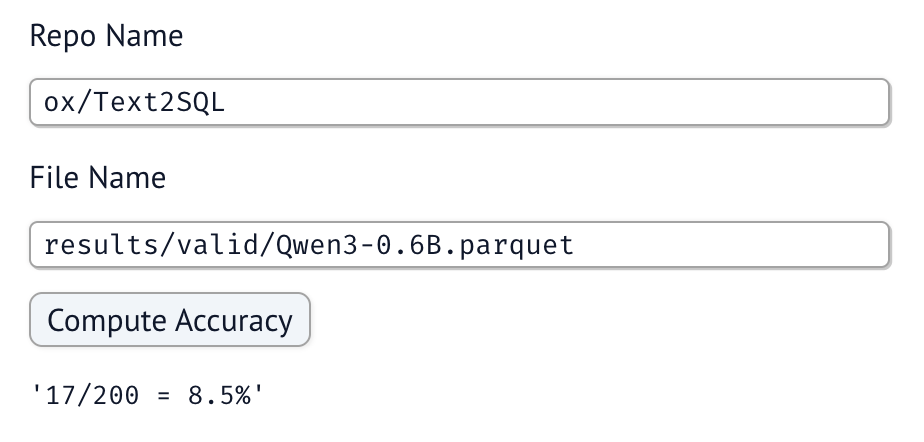
8% is not quite up to the standards we need. Time to break out the power tool of fine-tuning.
Fine-Tuning
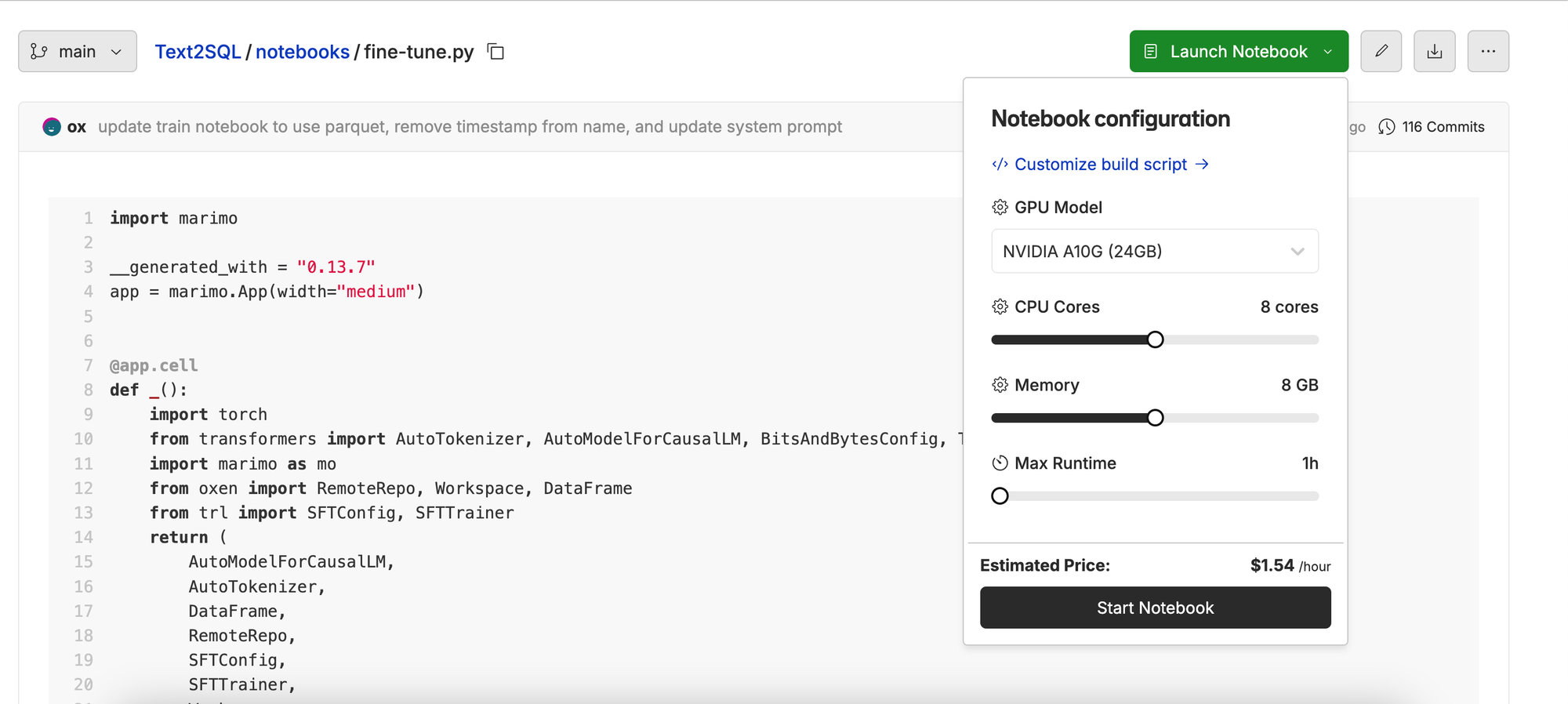
In order to Fine-Tune the model, we are going to use a Marimo Notebook running on Oxen.ai’s server-less GPU infrastructure. If you want to fine-tune your own, feel free to grab this notebook and upload it to your own repository:
https://www.oxen.ai/ox/Text2SQL/file/main/notebooks/fine-tune.py
For this experiment, we used an NVIDIA A10G GPU with 8 CPU Cores and 8 GB of memory. The best part is, it only takes about 10-12 minutes to fine-tune end to end.
You can either fine-tune the model with PEFT or do a full fine-tune of the weights. In this case we are going to do a full fine-tune.
At the end of the fine-tune the model weights will be saved on a branch in the same repository. The branch name gets auto generated from the OxenTrainerCallback.
With experiment versioned and on a branch, you can always return to an old set of weights or compare different models over time.
Evaluate Fine-Tuned
The same notebook we used to run inference for the base Qwen model can be used for evaluating the fine-tuned model.
https://www.oxen.ai/ox/Text2SQL/file/main/notebooks/eval.py
Looking at the data, we can already see the sql matched the prediction much more.

In fact... 74/200=37% of the rows are direct string matches of prediction == sql . That’s a 26% increase from our original GPT model which got 22/200=11%!
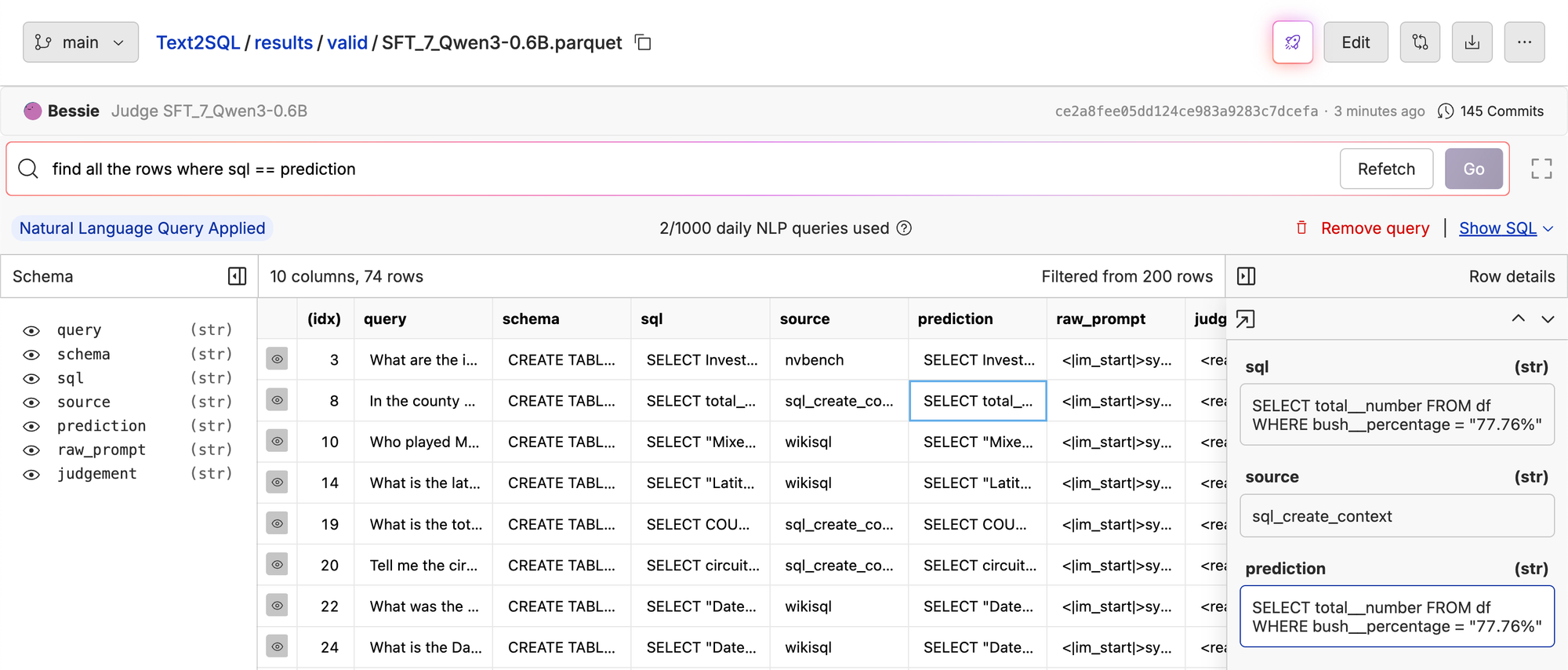
Let’s run LLM as a judge to see what our new accuracy is.
https://www.oxen.ai/ox/Text2SQL/evaluations/8bca8680-9c3c-48f5-8755-20b34af4063a
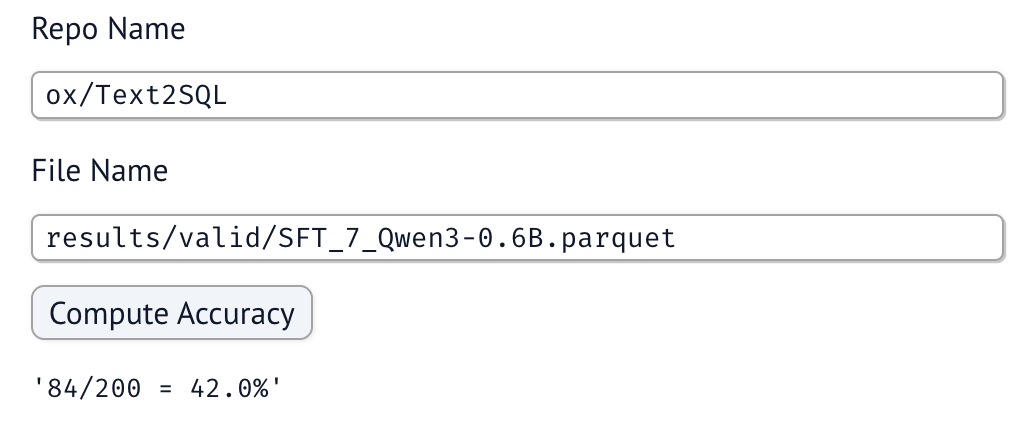
Extracting the accuracy with our notebooks/extract-accuracy.py notebook we can see the model now gets 42% accuracy!
What if we try Qwen3-1.7B?
When in doubt, increase the parameter count! Often with the same data, a larger model can be the remedy you need. 1.7B is still small enough that we can run locally and is relatively quick to train. Running the same end to end pipeline 🥁 the model gets 114/200 = 57% accuracy!

This means we have a winner! It still is by no means perfect, but proves that it is indeed possible.
| Model | Accuracy |
|---|---|
GPT-4o |
45% |
Qwen3-0.6B |
8% |
SFT_Qwen3-0.6B |
42% |
SFT_Qwen3-1.7B |
57% 🥇 |
Conclusion
My hypothesis throughout this series that if we have a well defined task, we do not need to leverage a foundation model. We can distill down a smaller model and have full control of the weights, where it’s running, and what data it’s trained on. These first experiments prove this to be the case 😎 excited to try more smol models.
If you would like to see us evaluate any models or tackle any tasks in particular, feel free to tag me in Discord. We are also looking for volunteers who want to run experiments of their own! If you want to follow this recipe, and send us the results we can feature you in an upcoming Friday. We are happy to provide you with all the compute credits needed for the fine-tuning along the way.
All the code, datasets, and model weights from the experiments today can be found here:

Happy Fine-Tuning!
~ The Oxen.ai Herd




Member discussion