
How to Set Noise Timesteps When Fine-Tuning Diffusion Models for Image Generation

Fine-tuning Diffusion Models such as Stable Diffusion, FLUX.1-dev, or Qwen-Image can give you a lot of bang for your buck. Base models may not be trained on a certain concept or style, and it does not take that many examples to fine-tune a low rank adapter (LoRA) to encode the new concept.
For example, a base model may not know what you mean by "Will Smith". Are you talking about the actor? The baseball player? Your childhood friend from down the street?

With as few as 20-30 images, you can go from a base model to a model that understands that when we say "Will Smith", we mean the actor.
Want to try fine-tuning? Oxen.ai makes it simple. All you have to do upload your images, click run, and we handle the rest. Sign up and follow along by training your own model.
Picking the Right Hyper-parameters
One of the trickier parts of fine-tuning, is knowing what knobs to turn. These knobs are called hyper-parameters. They can span from LoRA rank, alpha, learning rate, training steps, batch size, and timestep type.
Here is an example configuration in Oxen.ai:
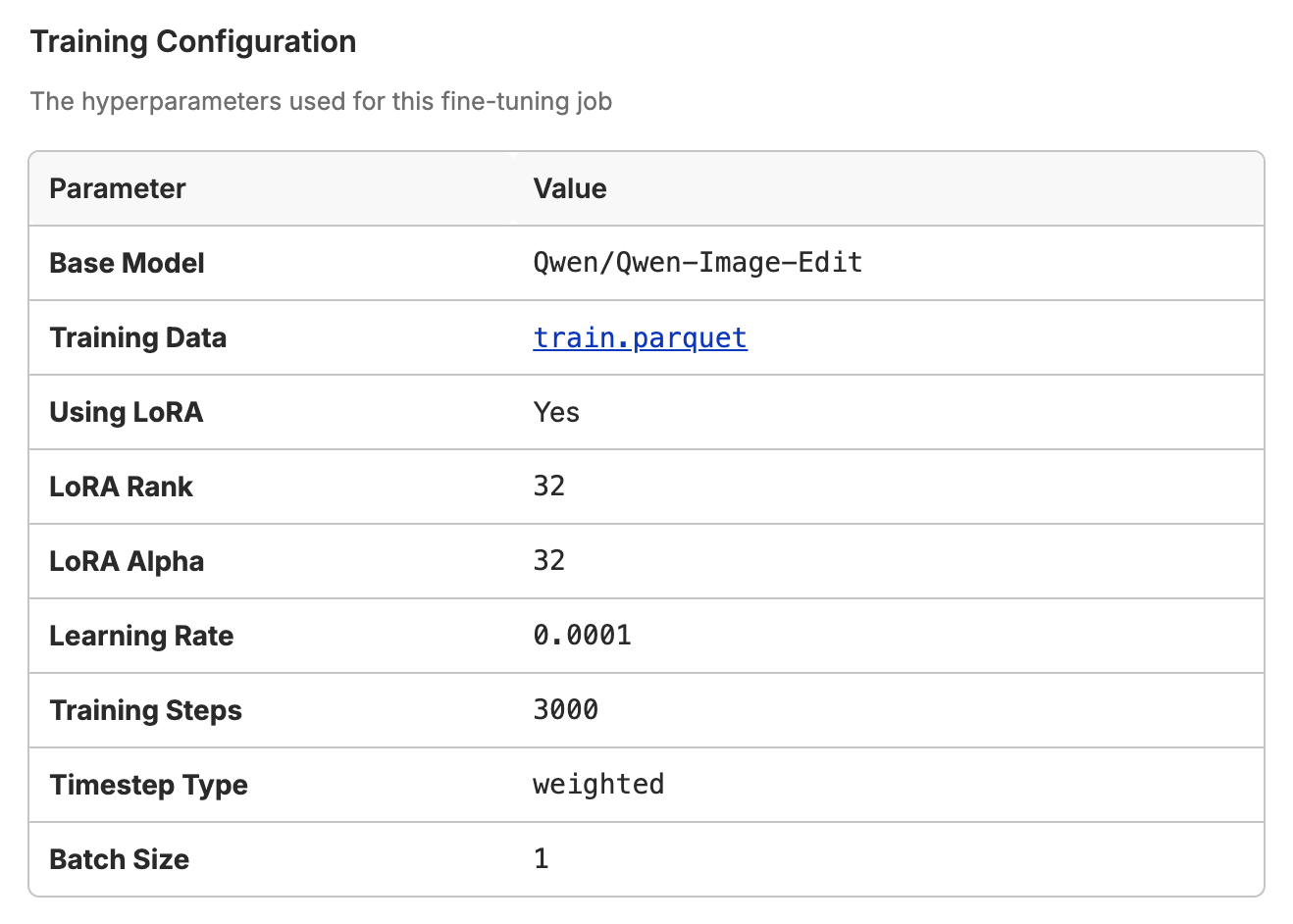
Finding the right hyper-parameters is best done with the scientific method of rigorously testing each variable on their own and seeing how it affects the outputs. That being said, there are a lot of parameters to tweak, so the goal of this post is to zone in on one parameter in particular: "Timestep Type".
What are "Noise Timesteps" in Diffusion Modeling?
We won't go into the math of training diffusion models in this post, instead we want to give you an intuition of how diffusion works at a high level, and why this may affect your choice of "timestep type".
Diffusion models are trained through a process that converts a noisy image, to a clean one, by iteratively removing noise over time. To be honest, it feels like magic that it works at all. You start with "high noise" at the first timestamp (t_0) and end up with low noise at the last timestamp (t_n). Each step in between (t_1, t_2, t_3, etc...) the model's job is to remove a little noise and move towards a realistic looking image.

Conceptually it is nice to think of removing the noise in three stages:
Early stage (high noise): The model focuses on the big picture. It sets up the overall scene layout, decides if it's day or night, places people and major objects in roughly the right spots, and chooses the general colors and lighting mood.
Middle stage (medium noise): The model refines this basic structure. It defines clearer object boundaries, makes sure spatial relationships and perspectives look right, adds basic textures, separates foreground from background, and establishes what materials things are made of.
Final stage (low noise): The model adds the finishing touches. It sharpens edges, adds fine details like skin pores or individual hairs, fixes hands and facial features, and adjusts highlights and shading to make everything look crisp and realistic.
Think of this like how human artists often work: sketching the composition first, then adding layers of detail.

With this intuition in mind, there are different ways that we can apply noise during training. This is where our "timestep type" parameter comes in. In Oxen.ai there are currently three timestep types that you can choose from during training.
- Linear
- Sigmoid
- Weighted
Let's dive into each one and talk about the advantages and disadvantages.
Linear Time Steps
During training, you typically noise sample from x=0 to x=1000. When x=0 there is more noise, and when x=1000 you should be pretty close to the original image. Linear noise sampling is the most straight forward, it is simply a straight line from high to low noise. This means noise is reduced at a constant rate each step.
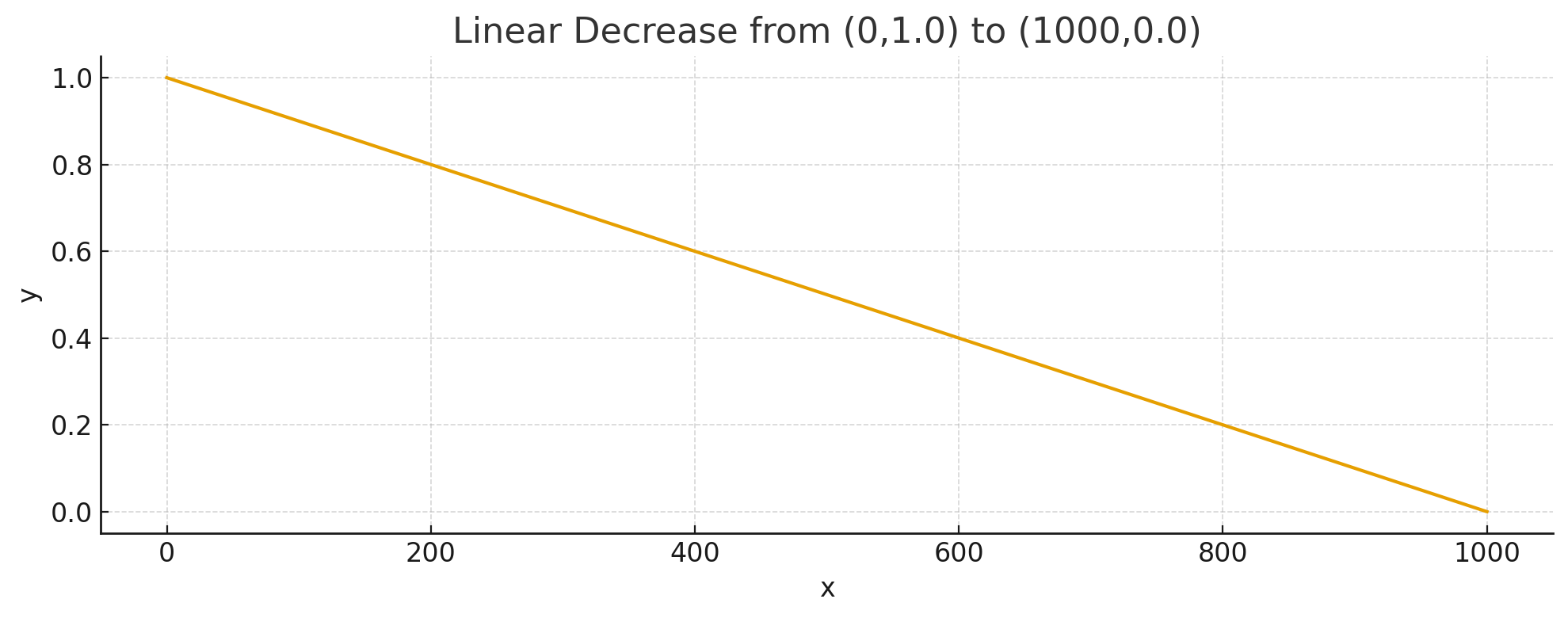
Linear is simple for us to wrap our heads around, but tends not to give the best results in practice. Pre-trained models already has a lot of inherent capabilities, and linear noise during fine-tuning tends to destroy some of that knowledge in the middle steps. I haven't seen it work well in my testing, but is nice for a visual baseline before we dive into the other functions. If someone finds a good use case for linear, feel free to reach out in our discord.
Sigmoid Time Steps
The sigmoid function has always been a fan favorite in machine learning. It is often used as a non-linearity in deep neural networks to allow them to model any arbitrarily complex function. The sigmoid function looks like a lot of weight at the start and end, and a quick shift in the middle from high to low.
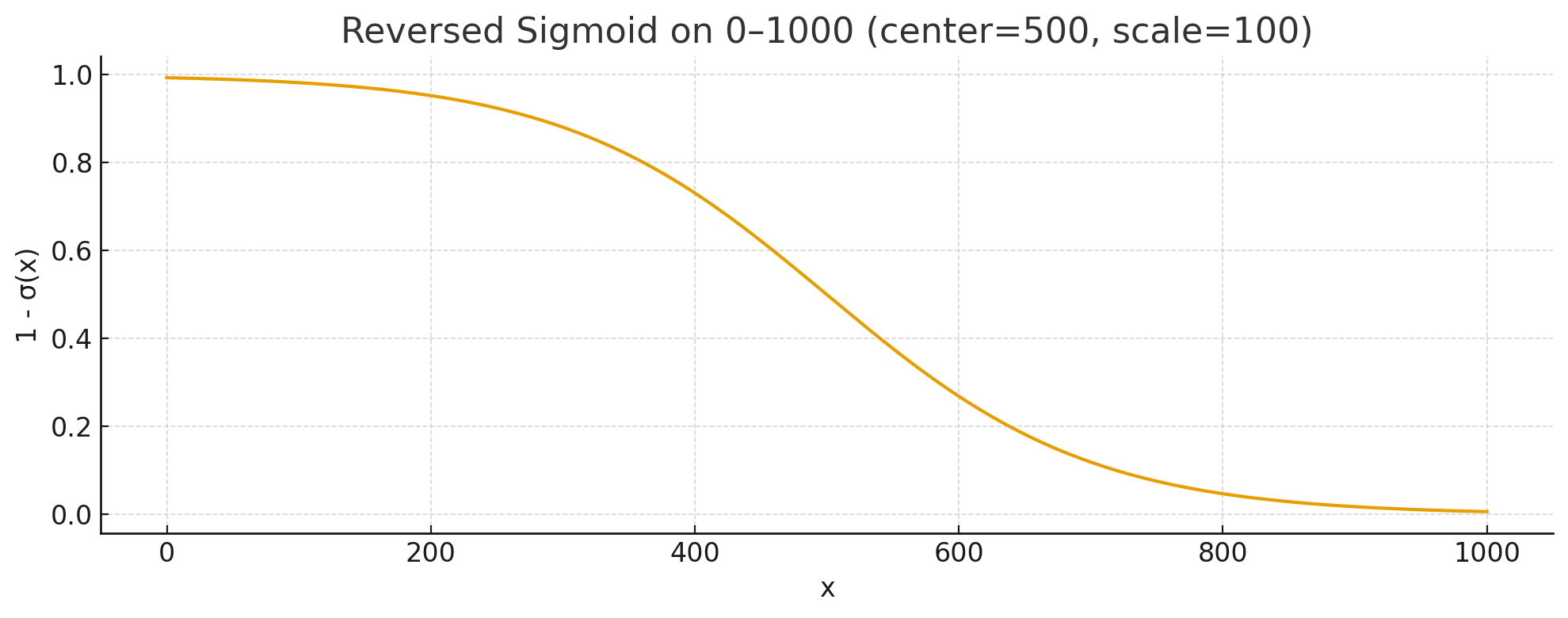
In our case, we can use the sigmoid to focus the model on the details at the start and end of the generation. Most of the time will be on refining the high noise removal, then it will quickly drop down in the middle steps, and finally focus on removing the low noise.
This is handy if you think about certain classes of things we want to tweak during fine-tuning. We may want to teach the model new styles and settings, or we may want the model to refine the output in the last few steps. During the middle steps we can generally lean on the base model for it's ability to piece these two together.
Sigmoid is a generally good default to try if you are not sure what parameter to set.
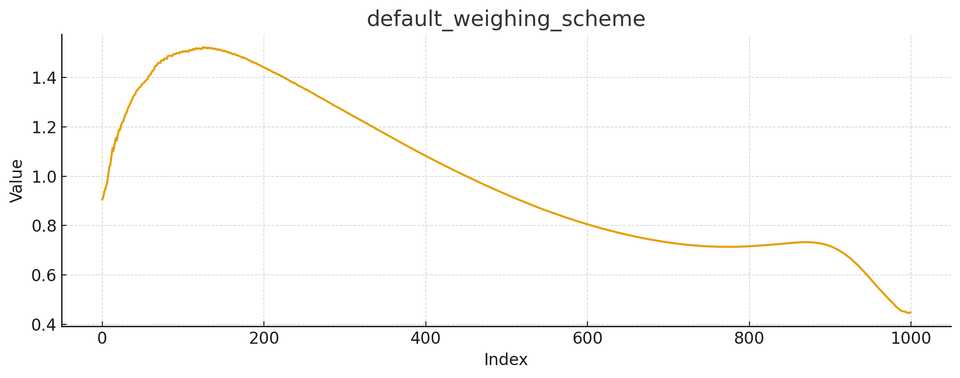
Weighted Time Steps
In Oxen.ai there is also a "weighted" option for the timestep type. It is a bit of a more complicated function, and is depicted below.
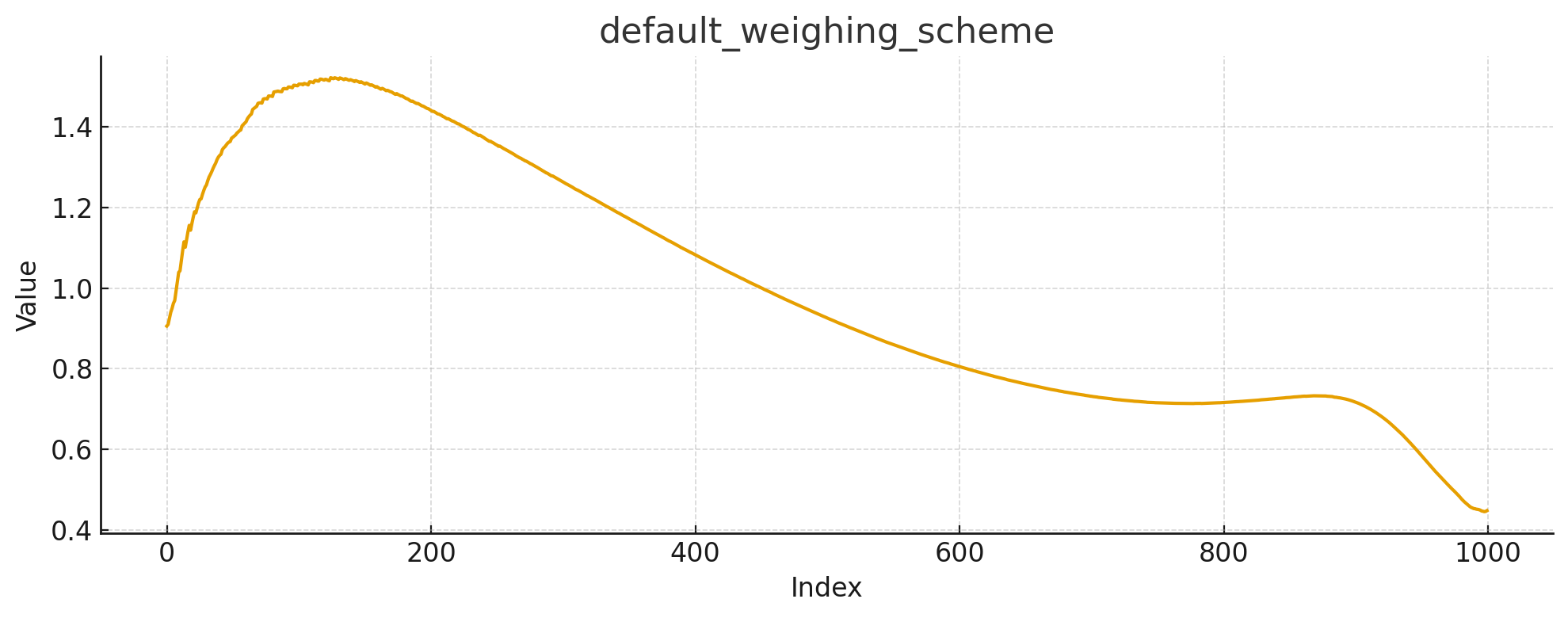
Here we start with a medium amount of noise, ramp up to a lot of noise, then spend most of the timesteps at medium/low noise. The final timesteps quickly drop to low noise.
This is a great option if you are focused on fine-tuning a new character or object into the scene. The intuition is that the scene generation and the level of detail will remain similar to the base model, but you want to spend a lot of time in the middle steps of learning the details of a new shape or object or character.
Conclusion
There are a lot of hyper-parameters to choose from when fine-tuning a model. Getting a feeling for which one works best for your task can become a super power. Oxen.ai makes it easy to run many experiments in parallel and find the right hyperparams for your use case. Noise timesteps can take a few minutes to wrap your head around, but once you understand it, will help you optimize for characters, scenes, or high level of detail.
If you want or need different noise sampling schemes or timestep types for your use case, feel free to reach out to hello@oxen.ai. We're happy to work with you on your custom use case to get the highest quality model given your data.
In the meantime, if you haven't yet, sign up for a free account and kick off your first experiment today.
Happy fine-tuning!



Member discussion