
How Upcycling MoEs Beat Dense LLMs

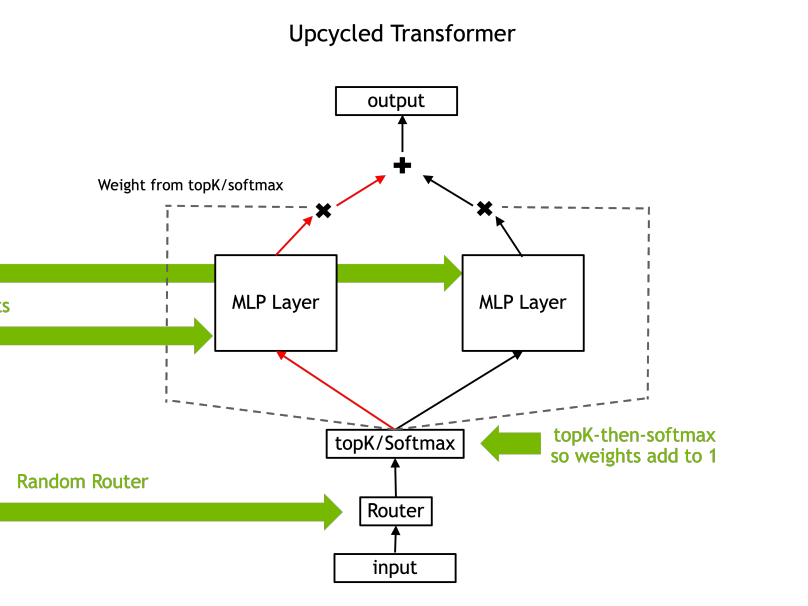
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He goes into what a MoE is, the challenges behind upcycling or scaling LLMs with a MoE architecture, and how upcycling MoEs outperform dense LLMs. Below are the recording of his presentation and his slides.
If you missed the dive live, feel free to check out the recording. The following notes are from the live session.
Ethan is in our Oxen discord! To ask him any questions directly, join the community:)
MoE upcycling nov 15
MoE upcycling Ethan He 1 https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/transformer/moe


Member discussion