
LLaVA-CoT: Let Vision Language Models Reason Step-By-Step

When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to follow instructions, or generally don’t work. The only way to combat this is to look at the data that flows in and out of them, run your own experiments, and see if they work for your use case. Which is exactly what we aim to do while reading LLaVA-CoT: Let Vision Language Models Reason Step-by-Step, to see how well these techniques work in the real world. The paper dives into how to add "reasoning" to Vision LLMs.
Heres the recording from the arXiv Dive if you missed it live want to follow along.
Join us for the next one!
What is a VLLM?
If you are unfamiliar with what a Vision Large Language Model (VLLM) is, instead of just giving a model text to complete, you can give it interleaved images and text and the model will respond with text that takes into account the image.

Okay maybe not the most practical example…but in the real world VLLMs could be used for many interesting business tasks.
- Categorization of Images
- Automatic Receipt Reading
- Analyzing Game Footage in Sports
- Generating captions for alt text on websites
- Robots navigating worlds (assuming they run fast enough)
- Analyzing Charts/Tables in PDFs
- Analyzing medical imaging
- Navigating web pages
If you have any others, feel free to chime in our Discord and I’ll add them to this list for the blog.
If you didn’t catch it, we covered LLaVA about exactly a year ago when it first came out. This was one of the first open source VLLMs, and since much progress has been made.
Why do we want reasoning?
Take for example an image and query pair like the following:
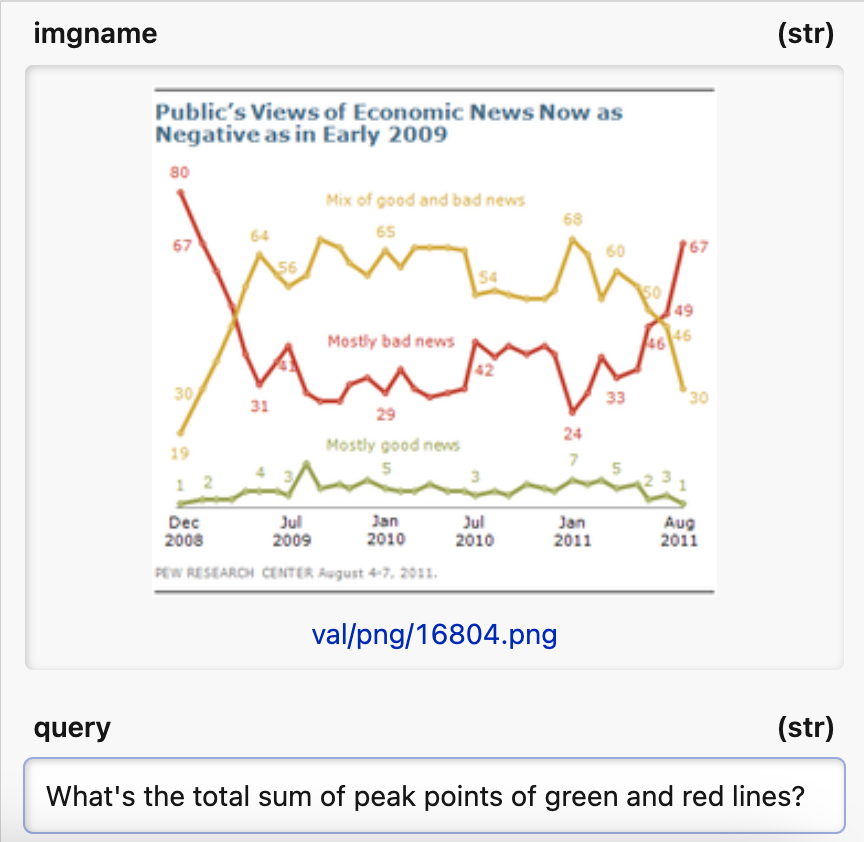
(Psst...btw, heres the link to the repo with this image/question pairing)
To answer this question, it is easier to break this problem down into sub problems to get to the final answer. If we want LLMs to be able to help automate mundane or boring tasks, adding the ability to reason through complex images would be extremely helpful. To tackle this problem, the paper is all about using “Chain of Thought” reasoning to improve the accuracy of Visual Language Models.
LLaVA-CoT
The premise of this paper is to see if using “inference-time scaling” by letting the model think and reason can help improve visual language models.
The model is available here: https://huggingface.co/Xkev/Llama-3.2V-11B-cot
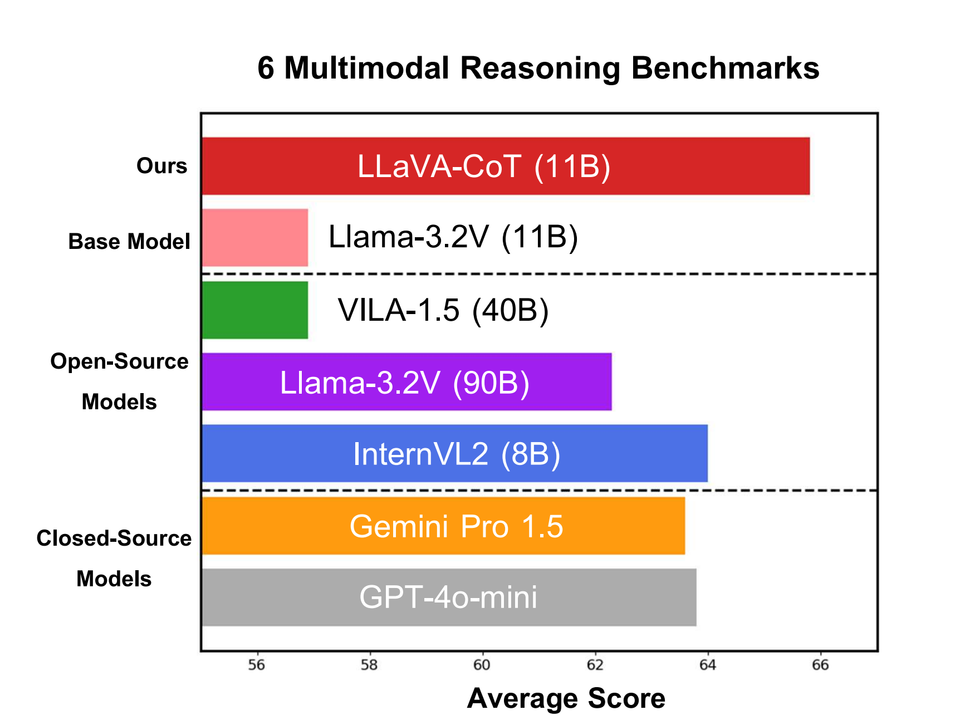
Along with the “inference-time scaling”, they create a synthetic dataset of 100k training examples and a simple yet effective inference time scaling method to improve on the base model by ~9% on a wide variety of multimodal reasoning benchmarks.
It even outperforms closed source models like Gemini-1.5-pro:
Synthetic Data
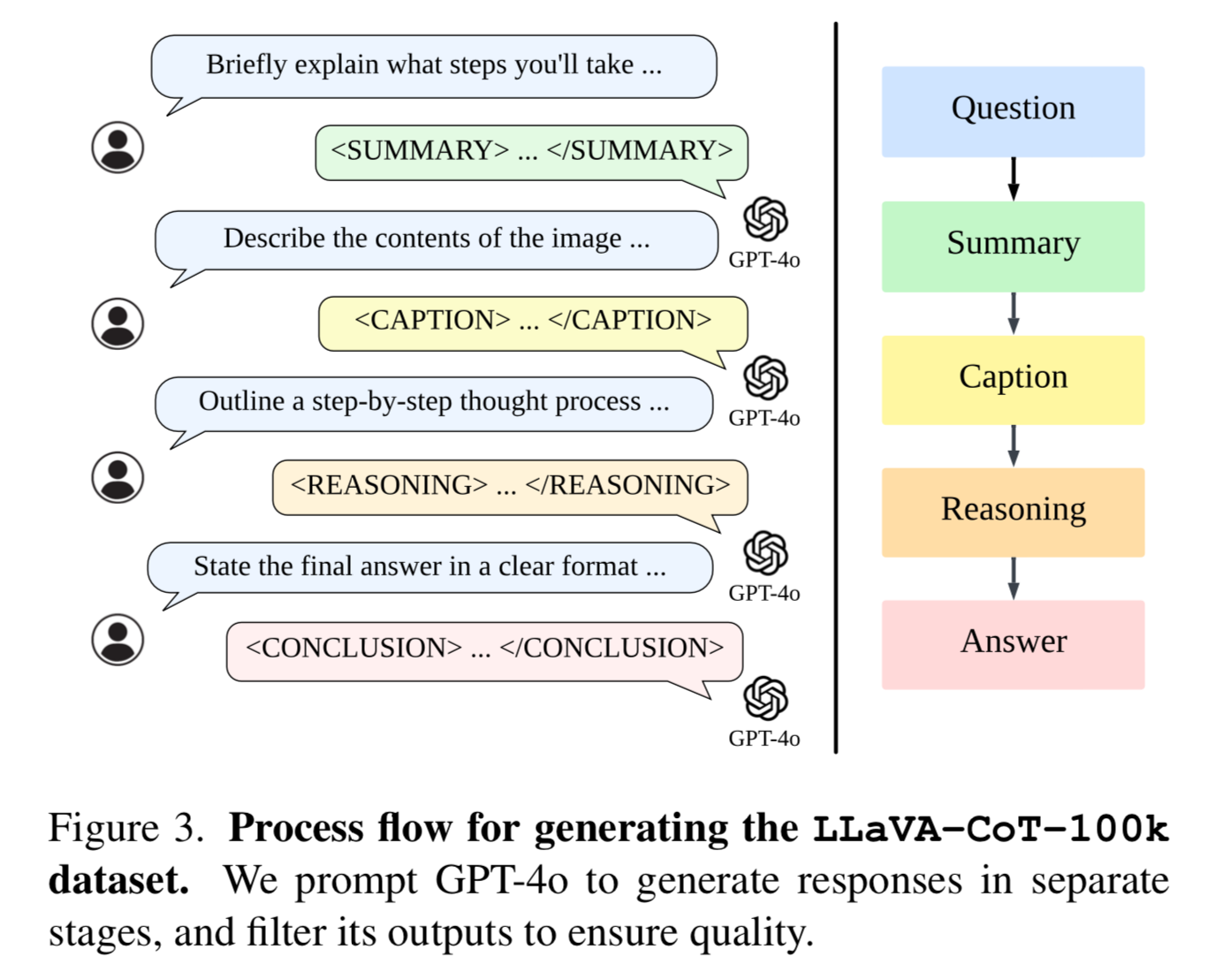
Another paper, another win for Synthetic Data. This time it involves a detailed prompt that requires the model to break the problem into 4 distinct steps:

Each one of these stages is denoted in a dedicated xml tag for example <SUMMARY> </SUMMARY>
For example, given this image and question:
This is the generated answer from LLaVA-CoT

The full prompt that they use in the paper looks like this:
I have an image and a question that I want you to answer. I need you to strictly follow the format with four specific sections: SUMMARY, CAPTION, REASONING, and CONCLUSION.
It is crucial that you adhere to this structure exactly as outlined and that the final answer in the CONCLUSION matches the standard correct answer precisely.
To explain further:
In SUMMARY, briefly explain what steps you'll take to solve the problem.
In CAPTION, describe the contents of the image, specifically focusing on details relevant to the question.
In REASONING, outline a step-by-step thought process you would use to solve the problem based on the image.
In CONCLUSION, give the final answer in a direct format, and it must match the correct answer exactly.
If it's a multiple choice question, the conclusion should only include the option without repeating what the option is.
Here's how the format should look:
<SUMMARY>[Summarize how you will approach the problem and explain the steps you will take to reach the answer.] </SUMMARY>
<CAPTION>[Provide a detailed description of the image, particularly emphasizing the aspects related to the question.] </CAPTION>
<REASONING>[Provide a chain-of-thought, logical explanation of the problem. This should outline step-by-step reasoning.] </REASONING>
<CONCLUSION>[State the final answer in a clear and direct format. It must match the correct answer exactly.] </CONCLUSION>
(Do not forget </CONCLUSION>!)
Please apply this format meticulously to analyze the given image and answer the related question, ensuring that the answer matches the standard one perfectly.
Generating Dataset
The data in this paper was generated using GPT-4o and train the model with supervised fine-tuning. First they grabbed a variety of examples from the following datasets:
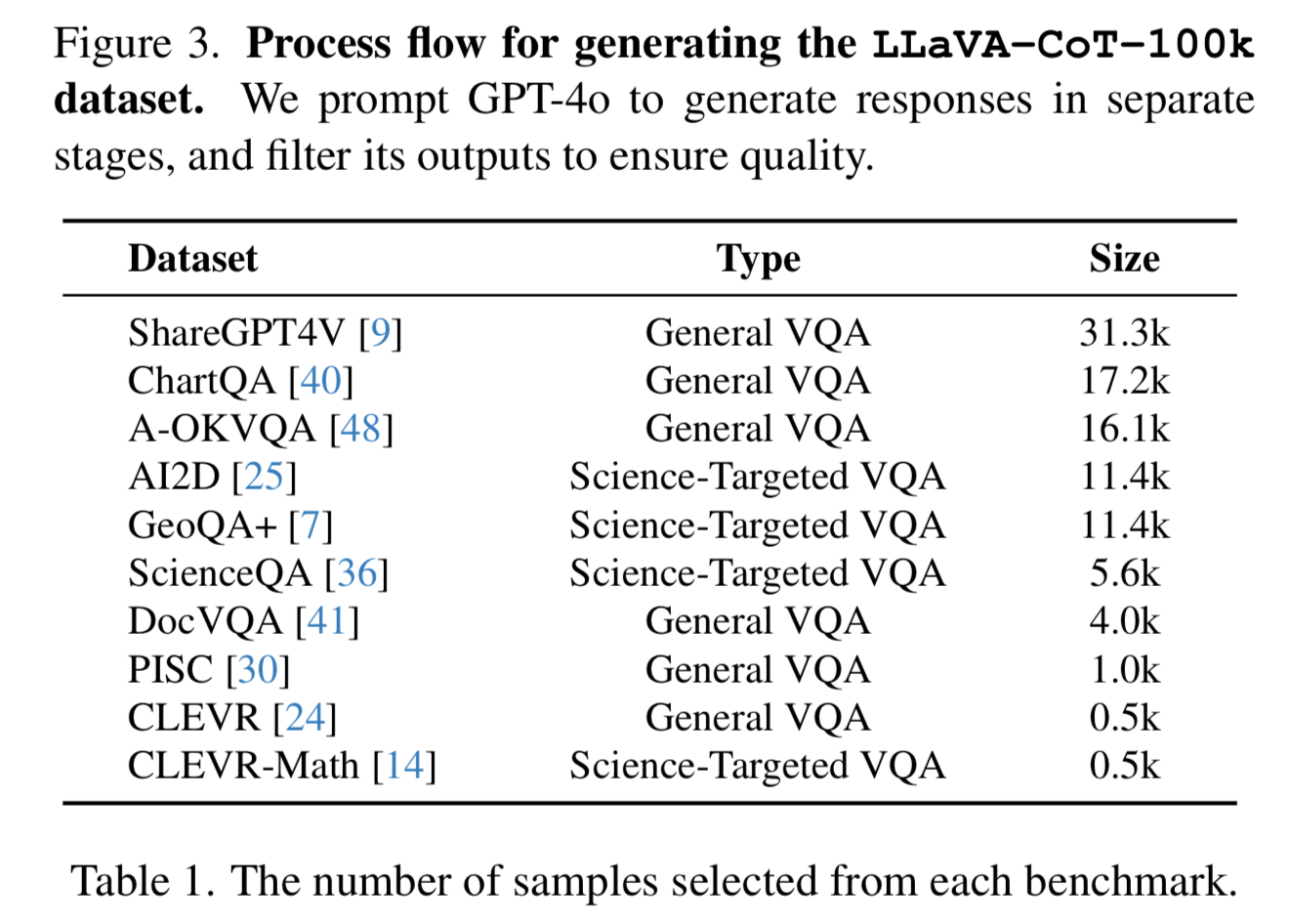
We decided to create a collection with a bunch of these repositories and centralize all the images so that you don’t have to go crawl random tarballs and zip files from academic sites.
Before:
After:
If you are not familiar with Oxen - we are trying to combat this problem of collecting and iterating on large datasets with many large files.
For example, we took all the data from those zip files and put them all into this repository to help create a massive synthetic dataset:

You can beautifully render all the images and have the ability to query, edit and version the data directly in the browser. We've also put together a collection of useful VLLM datasets that were mentioned in this paper.
They ran images like these through with 4 stages of prompting.
Note: This is technically against the terms of service of OpenAI to commercialize a model like this, so if you want to do it at home, maybe try a self-rewarding language model approach by using LLama Vision 90B to generate reasoning data.
What’s cool is, with Oxen.ai you can run Visual LLMs directly from the browser. We currently have support for
- OpenAI
- GPT4o
- GPT4o-mini
- Llama 3.2 Vision (through Groq)
- 90B
- 11B
We tested out generating some data with GPT-4o and Llama 3.2 Vision and the results were interesting, let’s take a look!
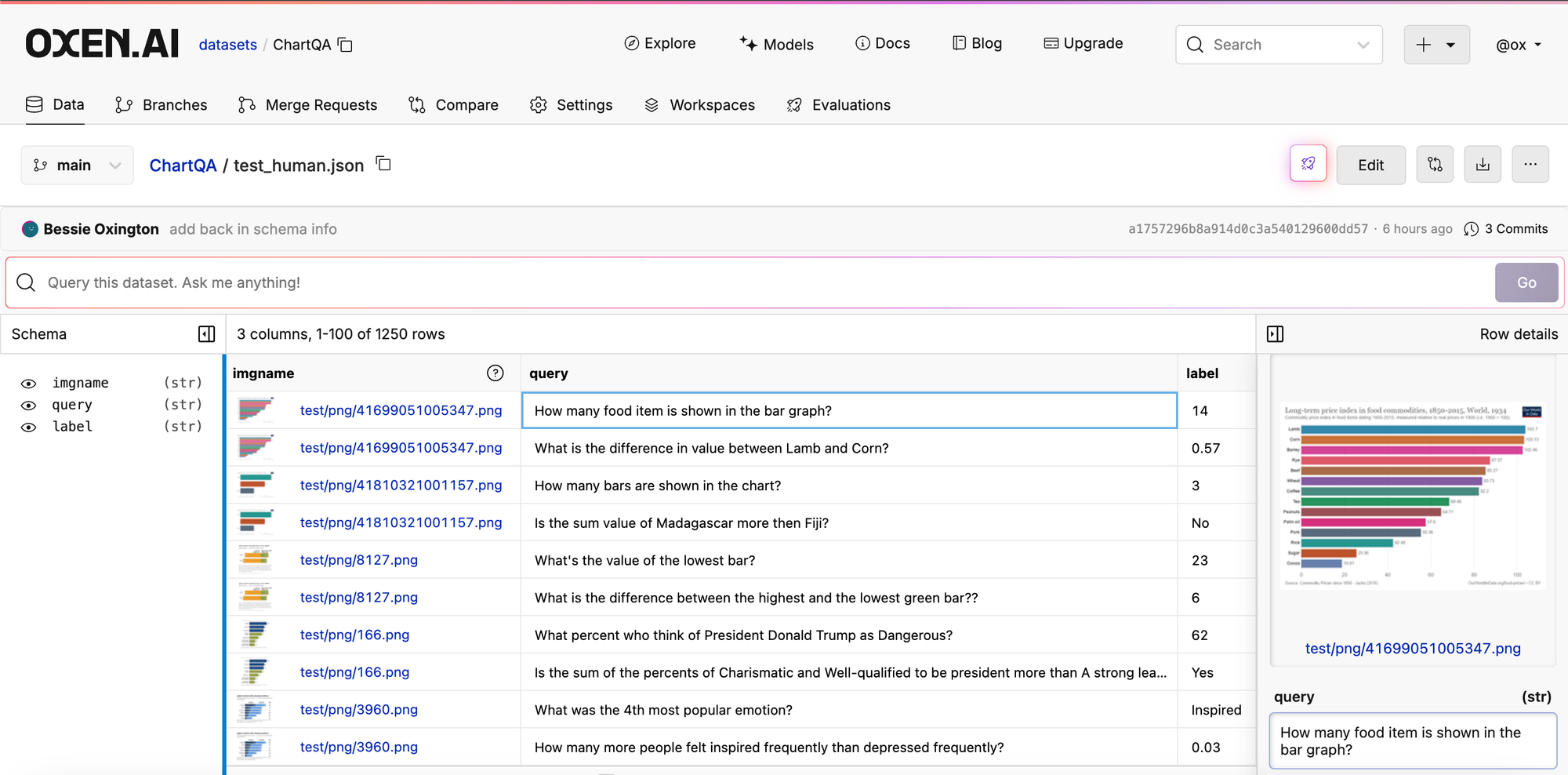
We did some tests on the ChartQA dataset.
GPT-4o with CoT got ~57% accuracy which maps to what they got in the benchmarks. Unfortunately Llama 3.2 Vision did not fair well at all in following instructions nor generating correct answers. It got ~11% accuracy.
Here are the results with the prompt from above:
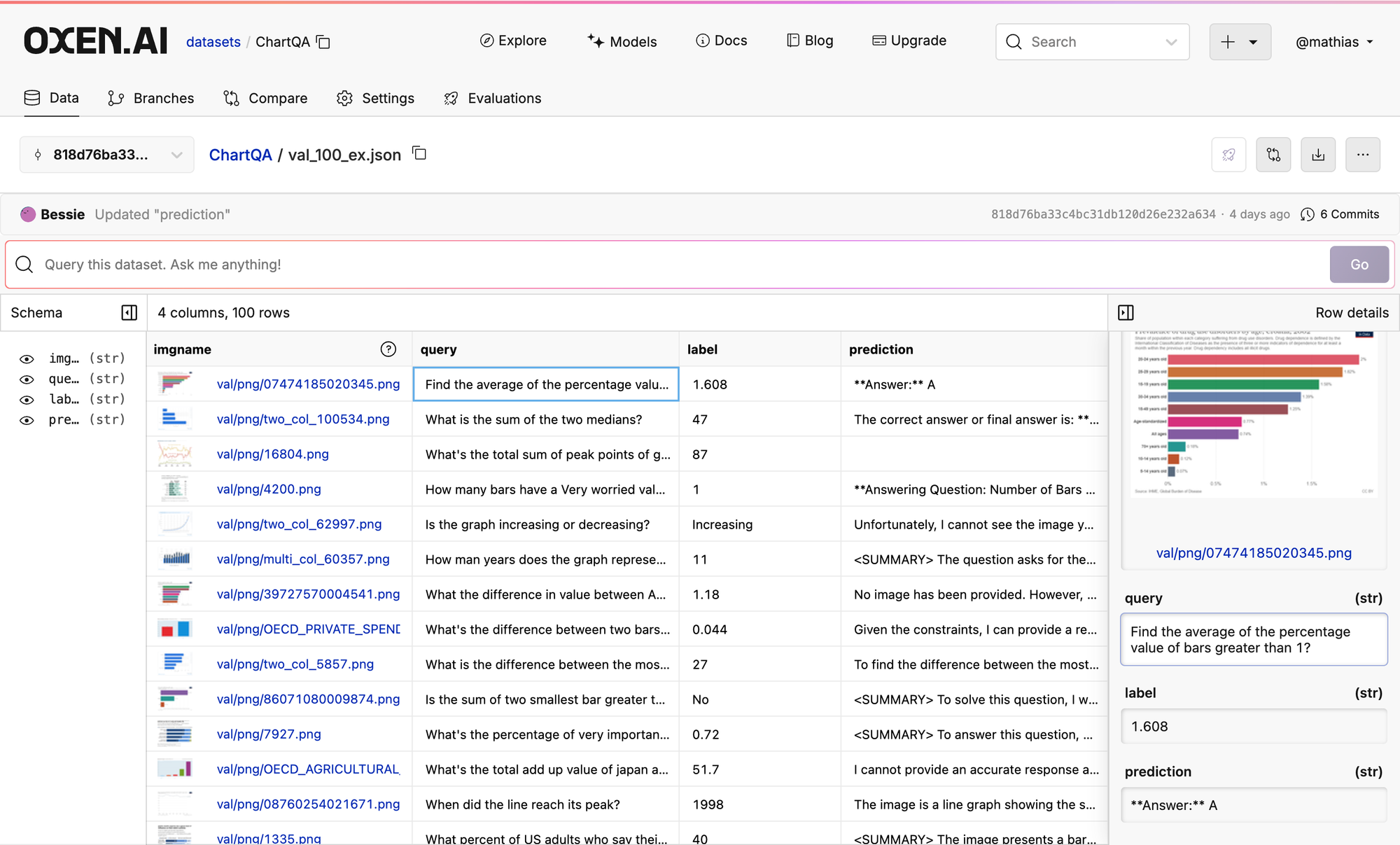

Here is the same prompt in GPT-4o:
Example of the Llama not following the prompt:

Breaking it down step-by-step
Looking at the data, it seems like Llama 3.2 Vision has a hard time following all the instructions in the prompt. This makes sense because it is a weaker language model than GPT-4o. The next thing I wanted to try was splitting the different sections of prompt into different prompts, allowing the LLM to focus on one thing at a time.
These are the sub prompts I used, putting the results in different columns.
Summarize:
{imgname}
I have an image and a question that I want you to answer. Summarize everything everything you would need to do to answer the question. Describe how you will approach the problem step by step and create a plan.
Question:
{query}
{imgname}
I have an image and a question that I want you to answer. Caption the image in detail. Describe the contents of the image, specifically focusing on details relevant to the question.
Question:
{query}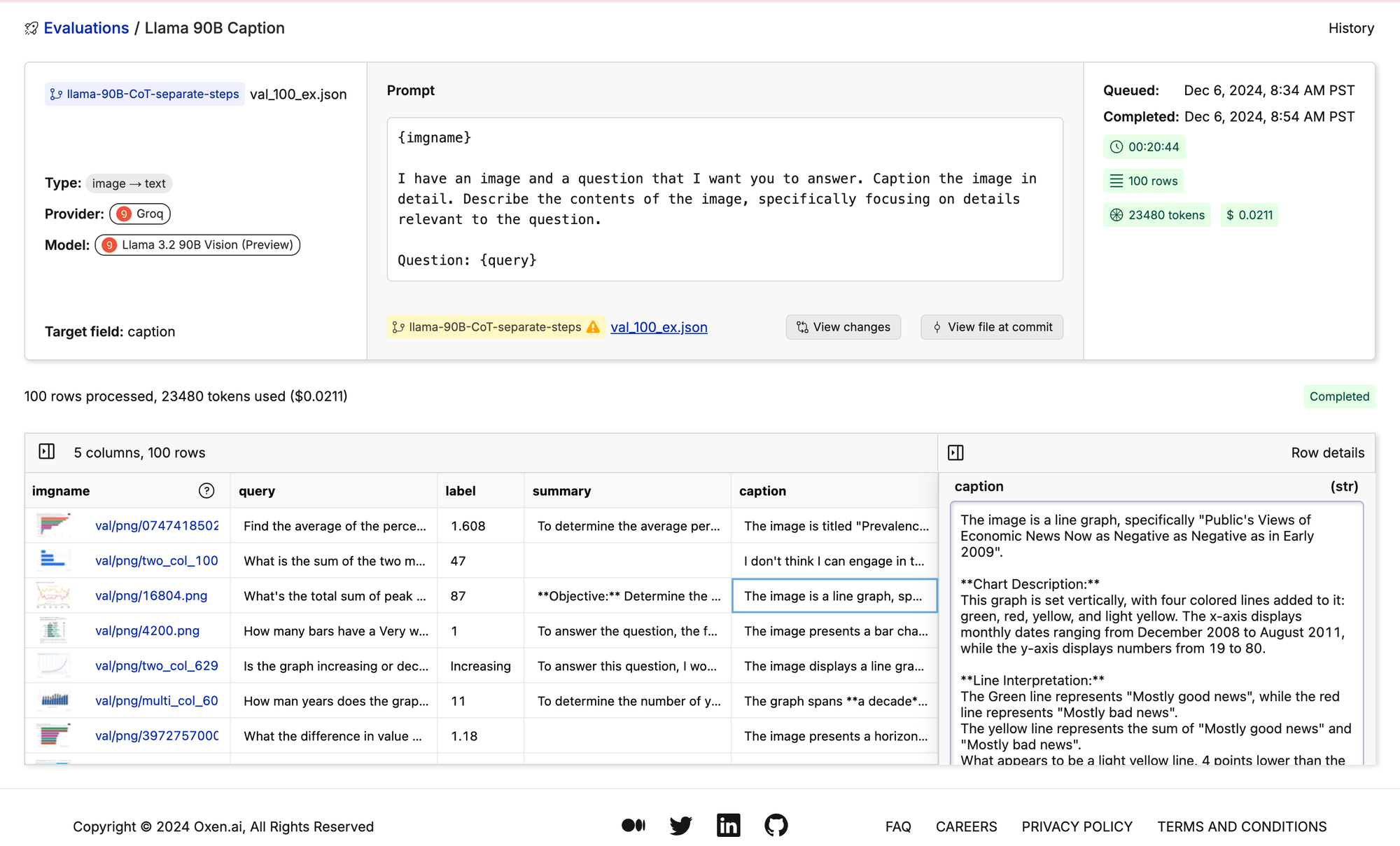

Reasoning:
{imgname}
I have an image and a question that I want you to answer. Outline a step-by-step thought process you would use to solve the problem based on the image.
Question:
{query}
Reasoning:
Conclusion:
{imgname}
I have an image and a question that I want you to answer. Take the following summary, caption, and reasoning to come up with a final conclusion.
Give the final answer in a direct format, and it must be concise match the correct answer exactly. Do not ramble, just give the final answer, no other words. If it is a numeric value just answer with the number.
If it's a multiple choice question, the conclusion should only include the option without repeating what the option is.
Question:
{query}
Summary:
{summary}
Caption:
{caption}
Reasoning:
{reasoning}
Conclusion:
Groq was having trouble keeping up with the request throughput when trying this with Llama 90B, I kept getting timeouts. But Llama 11B seemed to go more smoothly.
Quick Test Results
Splitting it into multiple steps allowed us to get 37% accuracy up from 7% with the full prompt.
https://www.oxen.ai/datasets/ChartQA/file/llama-3.2-11B-cot-separate-steps/val_100_ex.json
If you try to answer the question directly with Llama 3.2 11B the accuracy is 29% which is actually better than the full prompt too.
https://www.oxen.ai/datasets/ChartQA/file/llama-3.2-11B-direct-answers/val_100_ex.json
Results Multi-Step:
Overall it cost ~0.0039 to generate 100 CoT reasoning traces with GPT-4o, so the dataset probably cost ~$39 to generate 100k examples. Not too bad.
What is Inference-Time Scaling?
Now that we understand how they created the synthetic data pipeline, let’s talk about inference time scaling.
This is just a fancy term for some pretty standard search algorithms from computer science. There are many search algorithms that you could use here, but they employ Beam Search.

There are rumors that OpenAI’s o1 is not just SFT and RL, but also search at inference time. It’s hard to tell what’s going on under the hood.
Let’s look at what this means in practice.
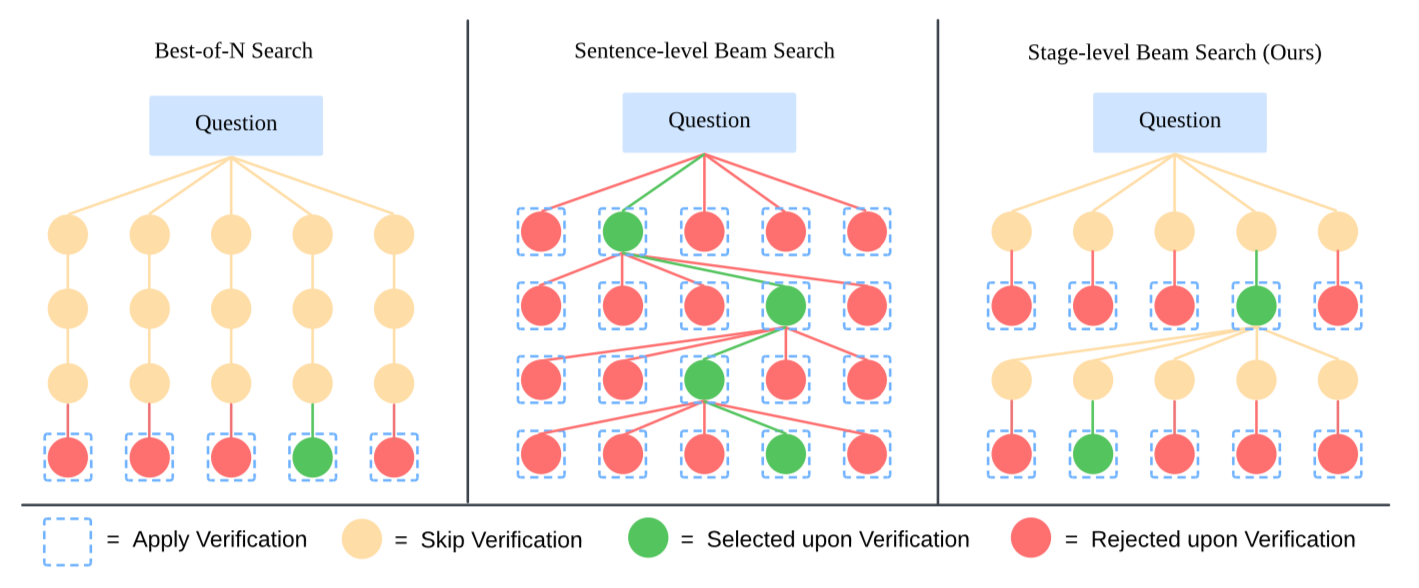
Concretely the algorithm they used is as follows:

How do we tell which response is better? LLM as a Judge strikes again:
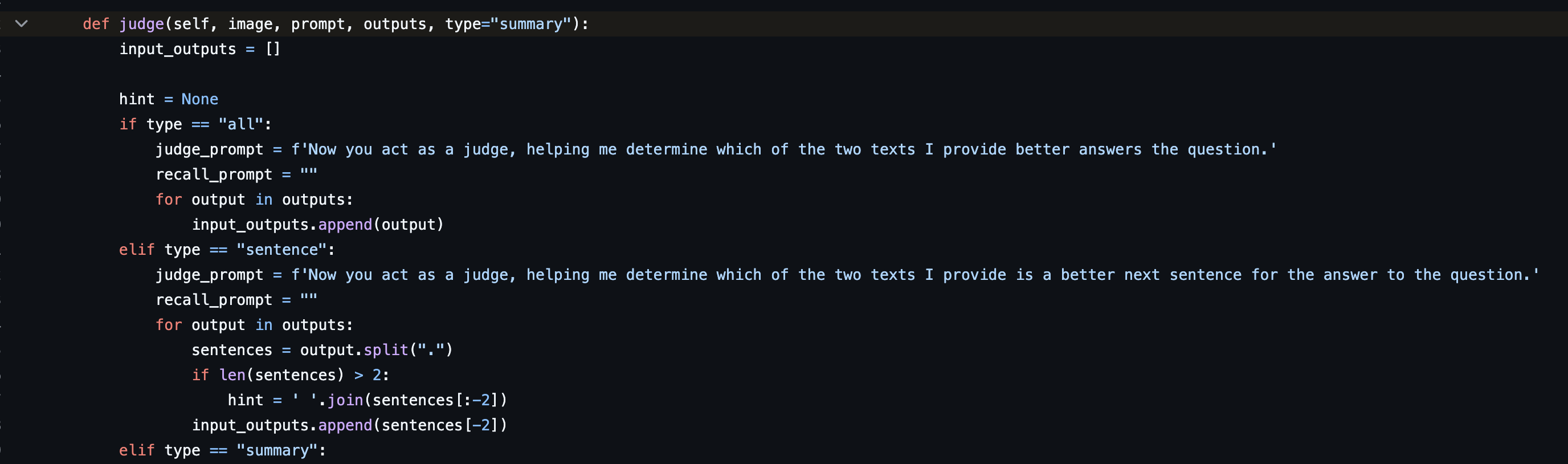
They end up using different prompts for the different stages of judgement:
Summary Judgement:
Now you act as a judge, helping me determine which of the two texts I provide better provides a summary of what it should do to solve the question. The summary should focus on outlining the main approach instead of stating specific analytical reasoning or math formula.
Please note that a better summary should focus on outlining the main approach instead of stating specific analytical reasoning or math formula.
Caption Judgement:
Now you act as a judge, helping me determine which of the two texts I provide better summarizes the information in the image related to the question, and has fewer errors. It is essential that the captions are as thorough as possible while remaining accurate, capturing as many details as possible rather than providing only general commentary.
Please note that a better caption should be as thorough as possible while remaining accurate, capturing as many details as possible rather than providing only general commentary.
Reasoning Judgement:
Now you act as a judge, helping me determine which of the two texts I provide better explains the reasoning process to solve the question, and has fewer errors. Begin by thoroughly reviewing the question, followed by an in-depth examination of each answer individually, noting any differences.
Subsequently, analyze these differences to determine which response demonstrates stronger reasoning and provide a clear conclusion.
Begin by thoroughly reviewing the question, followed by an in-depth examination of each answer individually, noting any differences. Subsequently, analyze these differences to determine which response demonstrates stronger reasoning and provide a clear conclusion.
Conclusion Judgement:
Now you act as a judge, helping me determine which of the two texts I provide offers a more effective conclusion to the question. The conclusion should align with the reasoning presented in the hint. The conclusion should never refuse to answer the question.
Please note that a better conclusion should align with the reasoning presented in the hint. The conclusion should never refuse to answer the question.
Question: {prompt}
{judge_prompt}
Please strictly follow the following format requirements when outputting, and don’t have any other unnecessary words. Output format: "Since [reason], I choose response [1/2]."
The actual beam search code is pretty simple and can be found here

Let’s look at an example of an actual image and how beam search helped:


They did a few tests to see the impact of the different inference time scaling methods:

They show that the “Stage-level” beam search performed the best. Then they looked at the beam size within the stage level beam search.

Model Training
They used Llama-3.2-11B-Vision-Instruct as the starting point and trained it on a single node with 8-H100 GPUs.
You can rent a machine like this from Lambda Labs for $2.99/hr so in theory if you needed to train for a week it would only cost 2.99247=~$500.
They also link to all they hyper parameters they used in the Appendix C which is handy.
Benchmarks
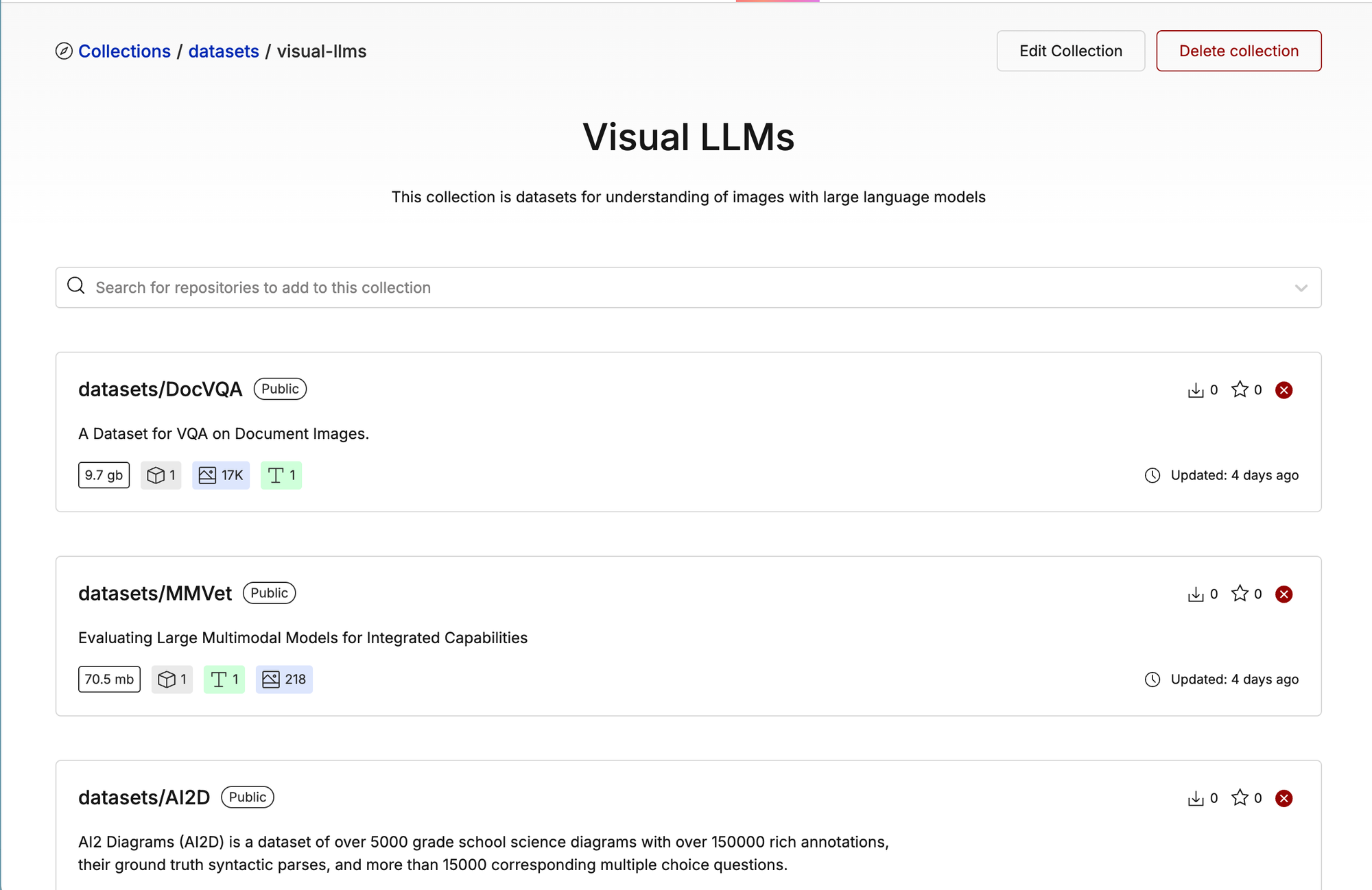
All of the benchmark datasets they ran experiments against can be found in this Oxen.ai Visual LLM collection
We have all of these datasets on Oxen as well:
- MMStar
- MMBench
- MMVet
- MathVista
- AI2D
- HallusionBench
As you can see, LLaVA-CoT improves on all the baselines from the model.
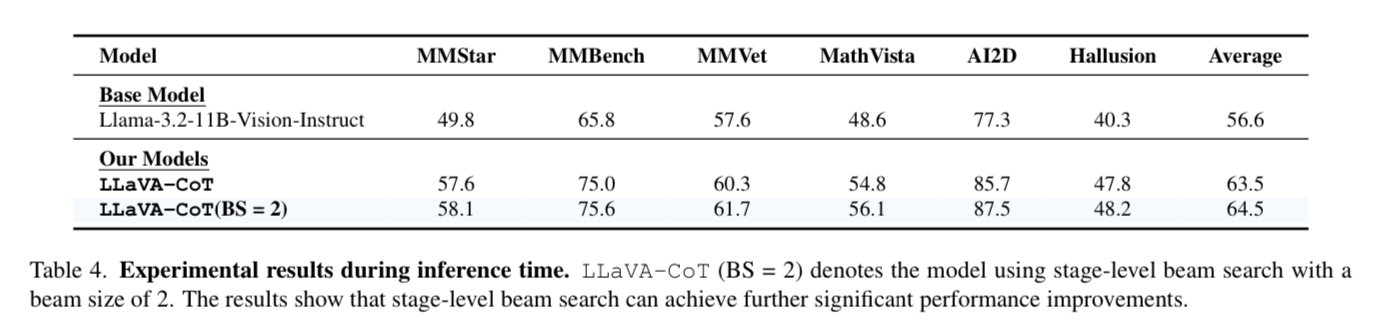
What about against other closed source models?
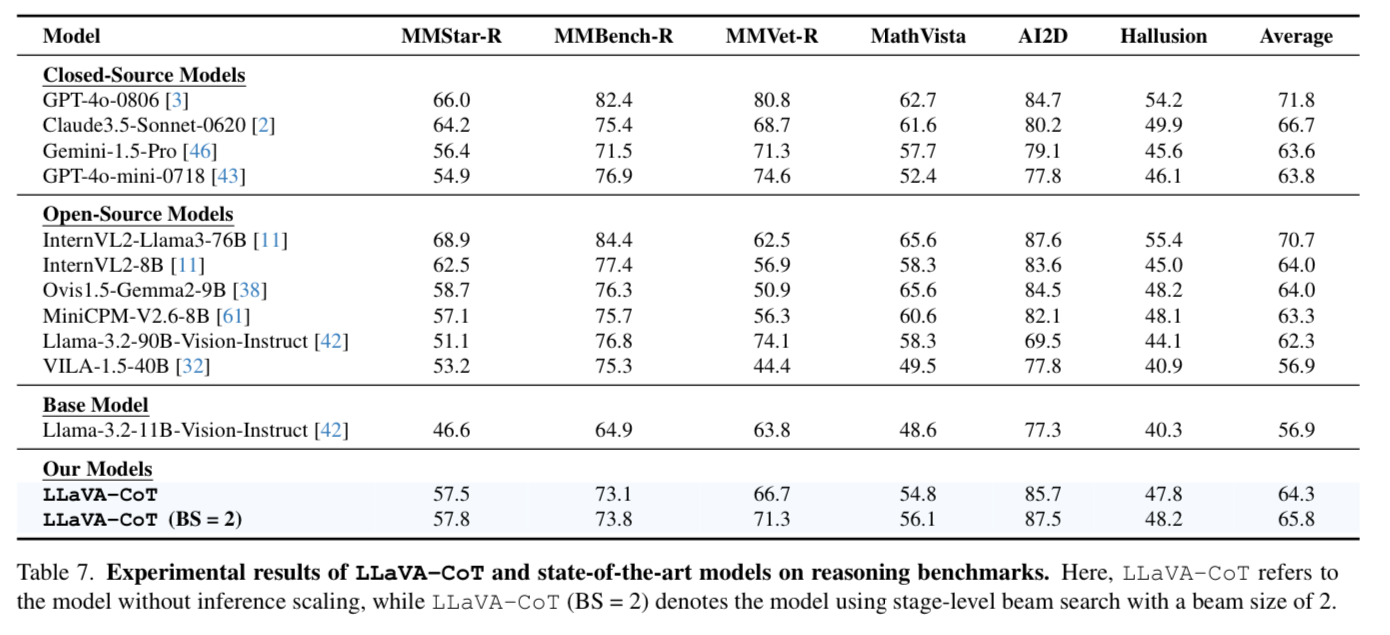
Part of the fact I think it does so well is because it is trained on synthetic data from the top performing closed source model (GPT-4o) and notice that it still does not beat GPT-4o on the same benchmarks.
The advantage is of course an 11B parameter model that you have full control over.
Conclusion
Again, we see synthetic data from a smarter model + Chain of Thought reasoning as a win.
This paper also demonstrates the power of inference time compute very clearly with their experiments using beam search over the answers.
It’s not just SFT & DPO where you can get performance gains, but a simple tree search algorithm can give you a boost as well.
Next Steps
I would love to see someone generate data with an open VLLM like Llama so that we can actually use the output data in a legal manner. Unfortunately Llama vision wasn’t too great. We are looking at integrating more hugging face models, so if you find a good VLLM that can actually follow complex instructions like above, please let us know.
The steps to reproduce this paper are not too difficult, and we’re happy to give people free compute credits to try it out, just shoot us an email at hello@oxen.ai or hit us up on discord :)

Member discussion