
Mamba: Linear-Time Sequence Modeling with Selective State Spaces - Arxiv Dives

What is Mamba 🐍?
Mamba at it's core is a recurrent neural network architecture, that outperforms Transformers with faster inference and improved handling of long sequences of length up to 1 million. This post dives into how it works and will give you an intuition on much of the math.
What is Arxiv Dives?
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join the discussion live, sign up here. The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
Intro
Paper: https://arxiv.org/abs/2312.00752
Released: Dec 2023
Authors: Albert Gu & Tri Dao - CMU & Princeton
Why is Mamba so hot right now?
Mamba is 5x faster throughput than Transformers and scales linearly instead of quadratically with the length of the sequence.
Its performance show promise on data up to million-length sequences.
While this is exciting for all the generative text use cases like chat bots, summarization, and information retrieval. The modal shows promising results in other modalities as well such as audio generation, genomics and time series data which require you to model extremely long sequences.
They call it Mamba because the build on work called S4 models to create “selective structured state space sequence models” …is a lot of S’s. Sssssss 🐍

Motivation
All of the current state of art foundation models use the transformer architecture with the self-attention mechanism.
The problem is that transformers do not scale that well to long sequence lengths. This is because the self attention mechanism is quadratic. Every word has to attend to every other word in the sentence n^2.
With the sentence below there are 21 tokens, and 21*21=441 combinations the network has to compute through the keys, queries, and values matrices.
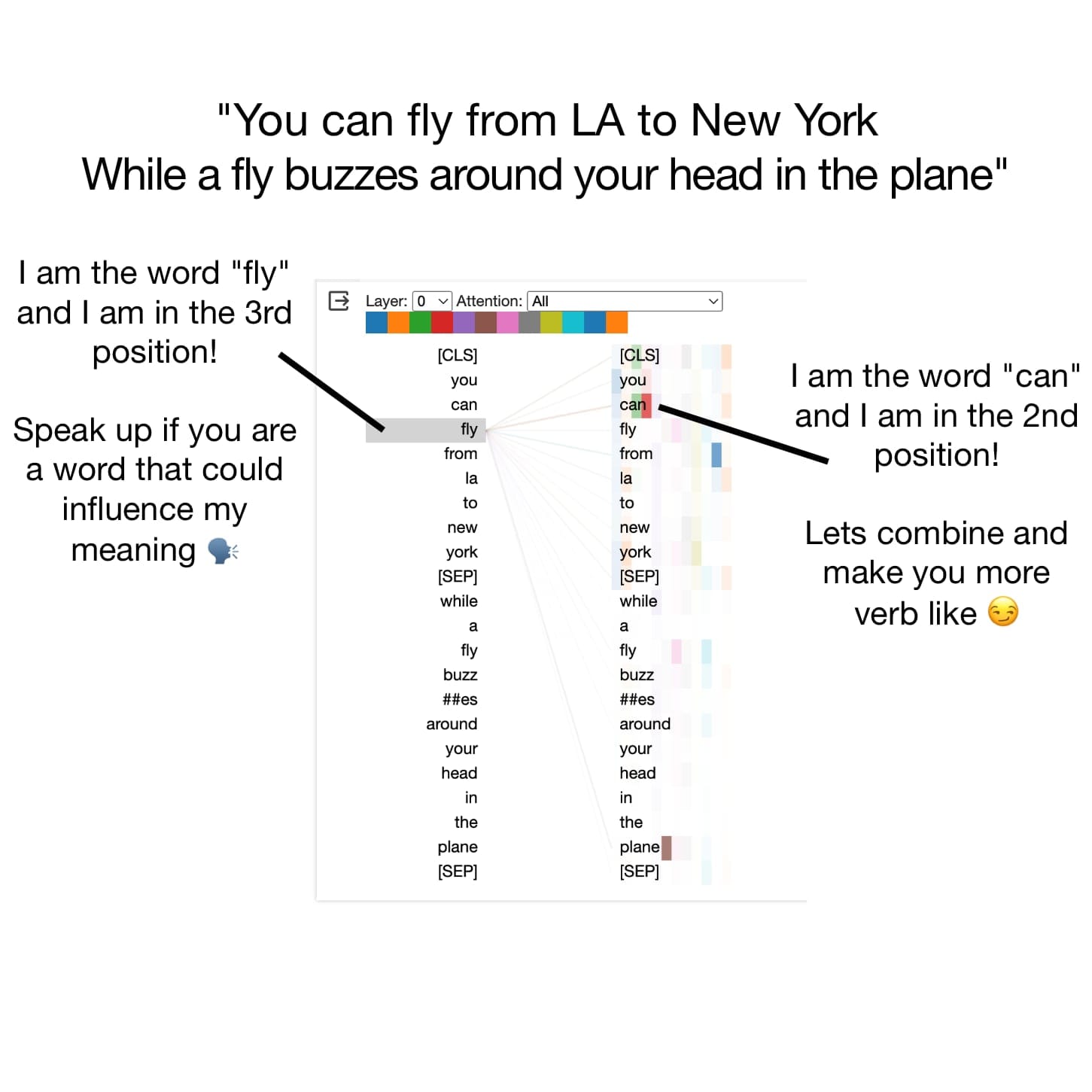
There are many architectures that are much faster than this during inference, such as linear attention, gated convolution, recurrent networks, and structured space models (SSMs).
They mention SSMs a lot in this paper, at the end of the day, an SSM is just a version of a recurrent neural net.
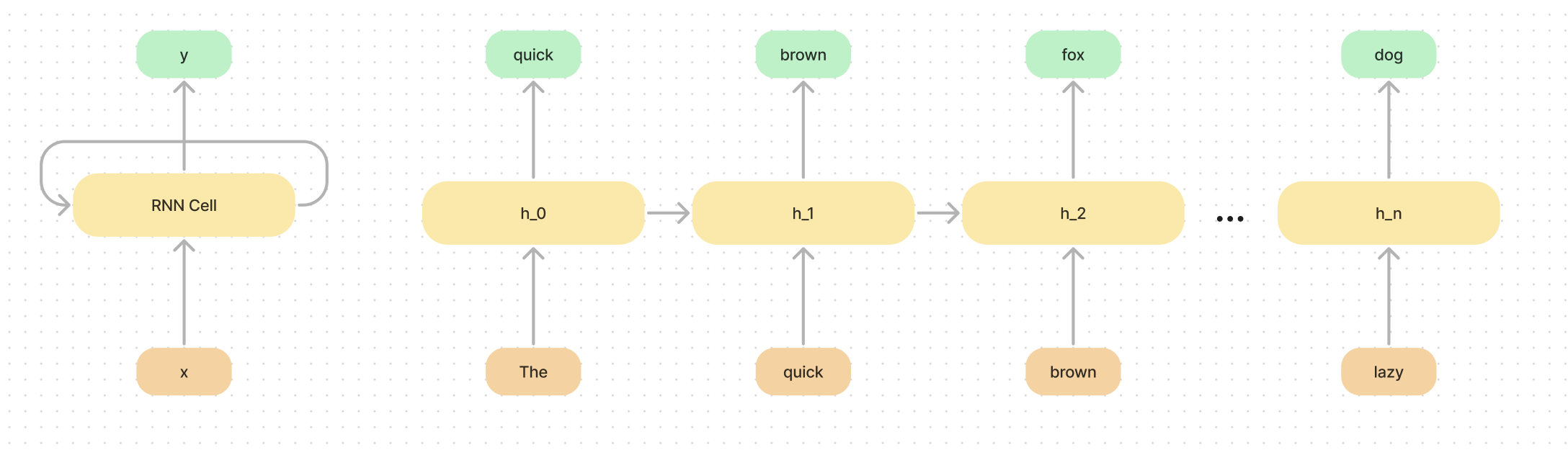
If you are not familiar, a recurrent network is linear in its prediction time for the next word, it simply has to take the current hidden state, and predict the next.
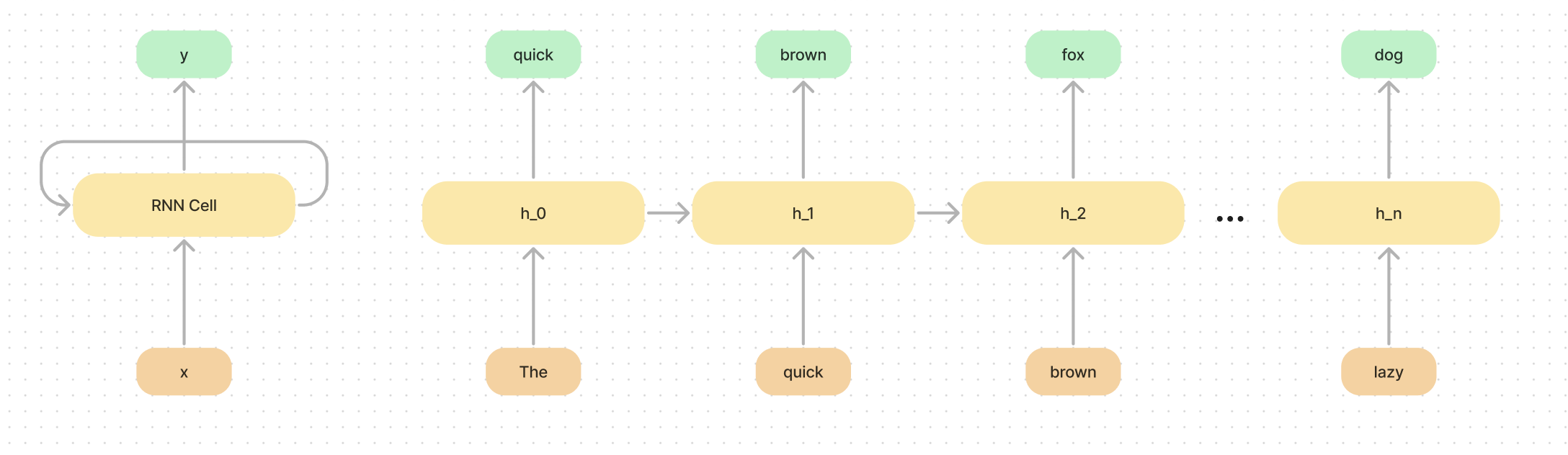
There are two main issues with recurrent networks.
- RNNs collapse all the information down to a hidden space, and tend to forget information on longer sequences
- RNNs are fast for generation, but slow for training
What we mean by “collapse all the information” is imagine trying to save all the information in a sentence into a small hidden space. I color coded what the network might remember at each step in the diagram below. You can see that the model has to be selective in what it remembers as it goes along.
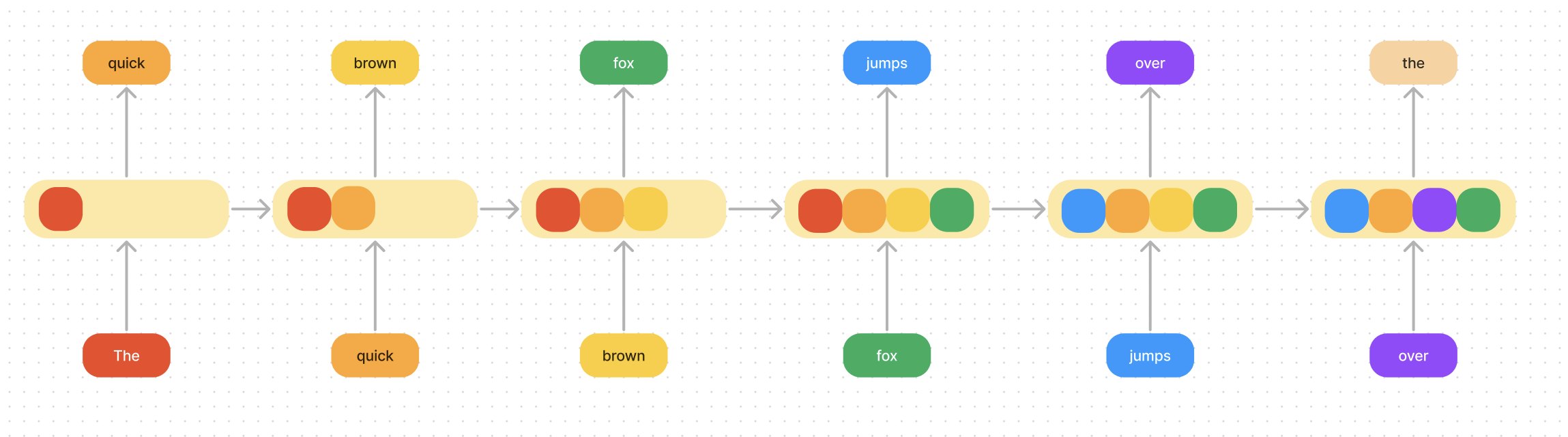
To take this example further, imagine you could only use characters to represent the hidden space (in reality we use a hidden state vector of numbers, but ignore that for now).
If we have the phrase: “Say we had a latent (hidden) space of size 5 to remember context.”
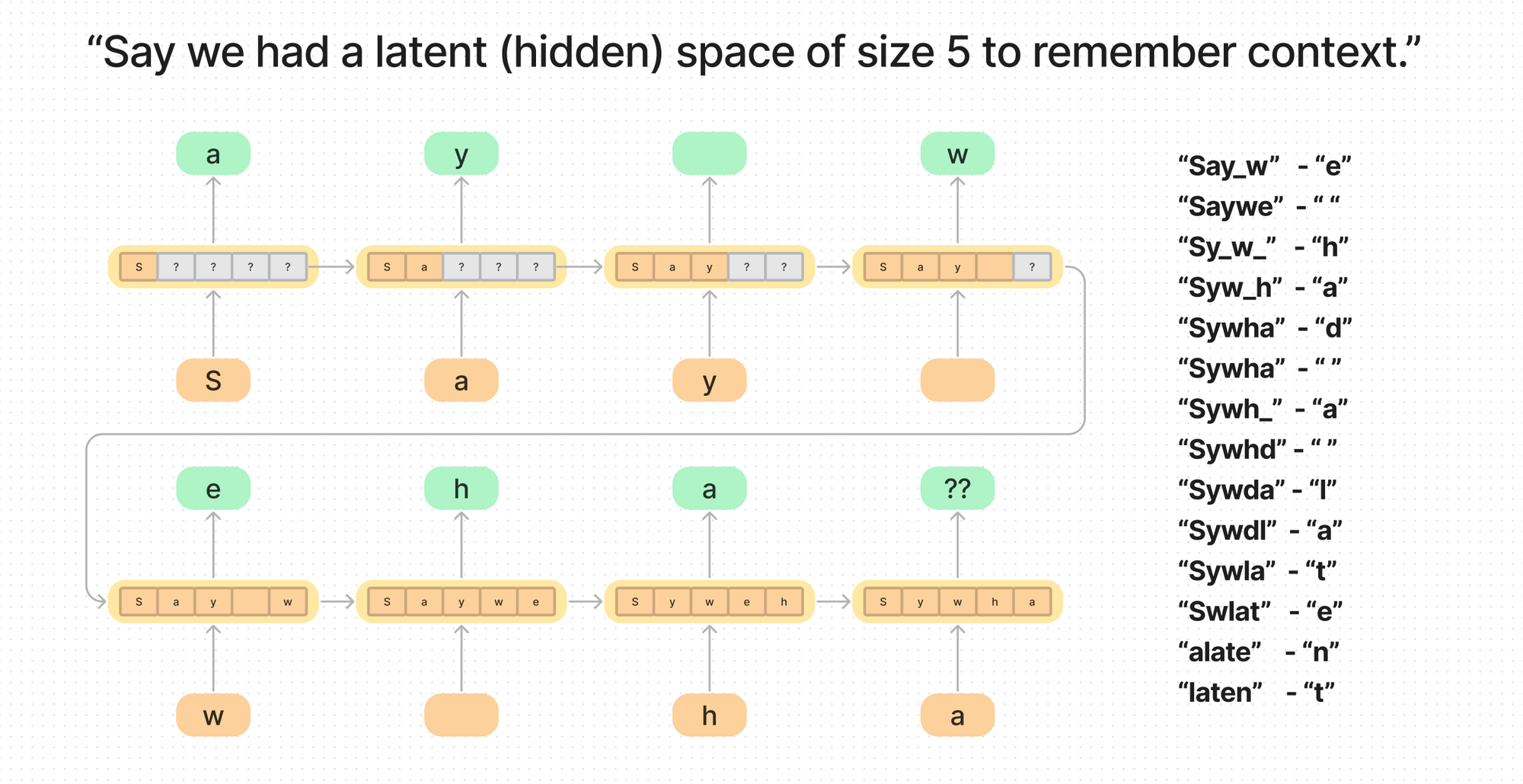
It is hard to fit enough context in the latent space to do anything than remember the last few characters. Trying to encode both something at the start of the sequence and at the previous token is a hard problem.
GRUs and LSTMs in the past have provided “gating mechanisms” within the RNN cell to decide what to remember and what to forget from the sequence as you go along.
As you can see from above, you can only fit so much context into a hidden state, no matter how well you gate, filter and remember.
Another issue with RNNs is that they are typically slow for training because you have to sequentially process the inputs to get the next output then compute the gradients all the way back through. RNNs have another issue called the “vanishing gradient” problem. As you propagate the gradient updates through back propagation, the values can either explode or go to zero.
Transformer vs RNN
Transformers are more efficient to train because they allow you to train the entire sequence in parallel with use of a lower triangular matrix that masks out future values as well as positional encodings.
RNNs are faster for word by word (auto-regressive) inference because they don’t have the N^2 nature of the self attention mechanism.
Selective state space models such as Mamba give you a linear recurrent net at the end of the day, with the benefits of fast training and a mechanism to remember context.
What is a “Structured State Space Model” (SSM)?
This is certainly the first time I had heard of this technique, and took the longest to wrap my head around - I was like what the heck is an SSM or S4? To fully understand Mamba, first it is helpful to understand SSMs in general.
A great helpful resource I found for s4 was: https://srush.github.io/annotated-s4 as well as this YouTube video: https://www.youtube.com/live/GqwhkbrWDOI
A SSM has a broad meaning and could be a RNN, CNN, or a HMM or a Kalman Filters etc.

SSMs are at the core of Mamba, so it is important to note how they work. You can think of them as the replacement for the self attention mechanism in a transformer.
There are many types of SSMs but the main concept is defined with a few key equations.

At their core, they are relatively simple, but some of the math can be intimidating at first.
A state space model takes in a 1D input sequence, maps to a N-D latent space and then projects back to a 1D output sequence.
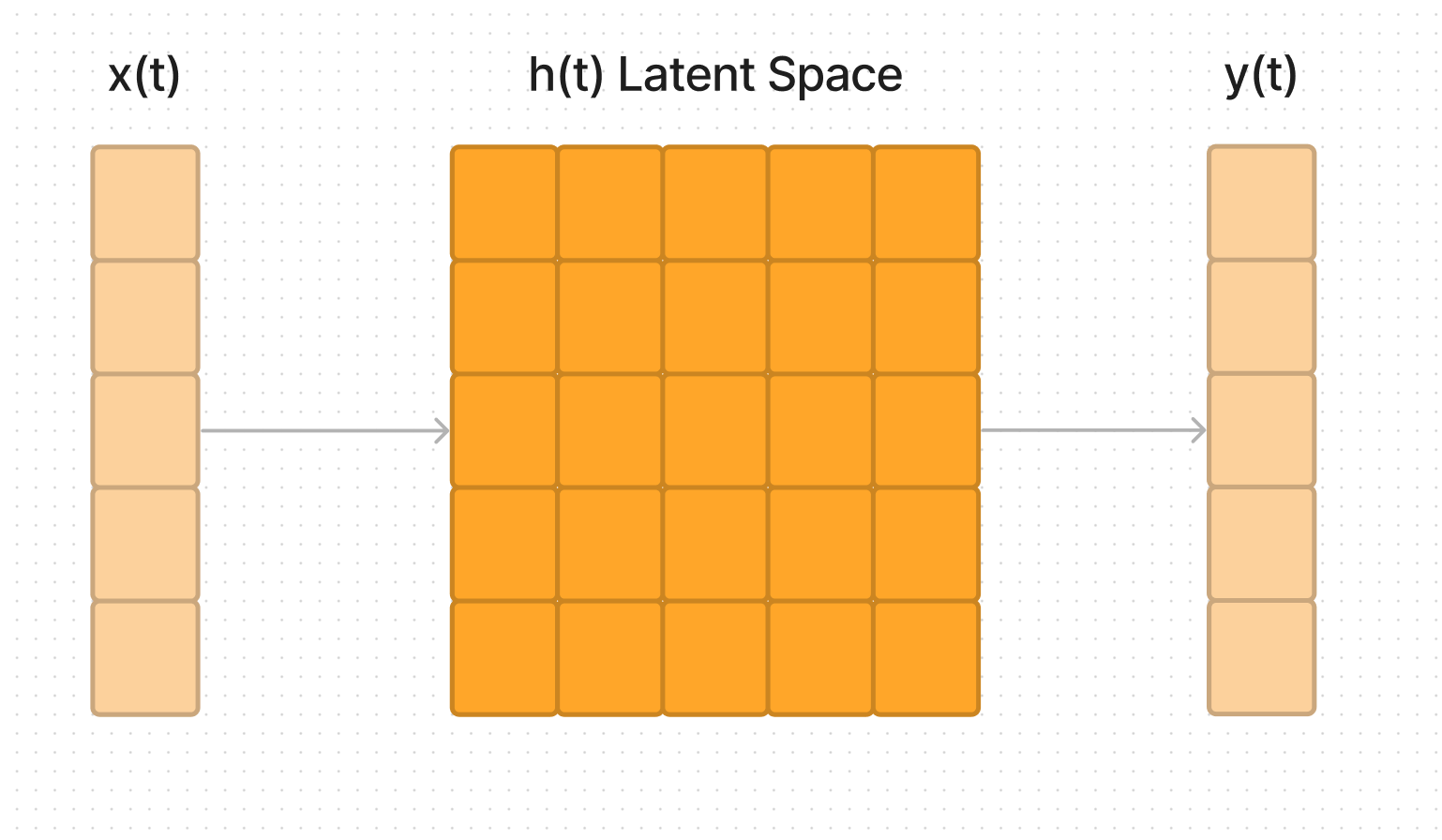
The main idea behind a state space model is that you have a “state” variable (in this case our latent space h) that evolves over time, depending on the input.
SSMs like S4 can be defined as through these equations:
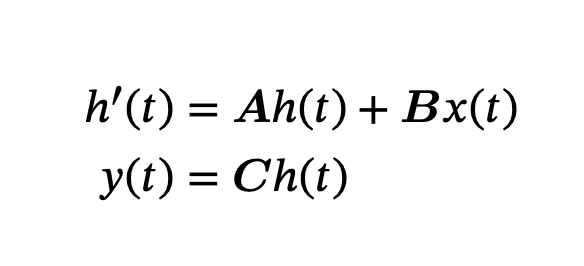
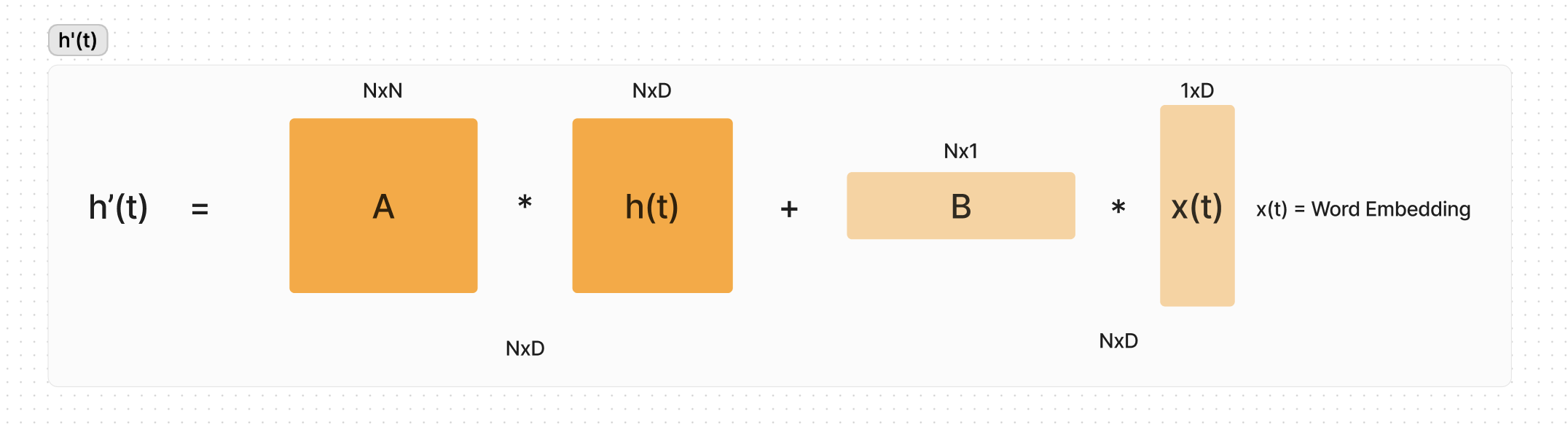
Where A, B, and C are parameters learned by gradient descent. They define the structure and the dimensions of each of these variables below.

The derivative h’(t) of h(t) is defined by the Ah(t) + Bx(t) function. This defines how the state should change over time.
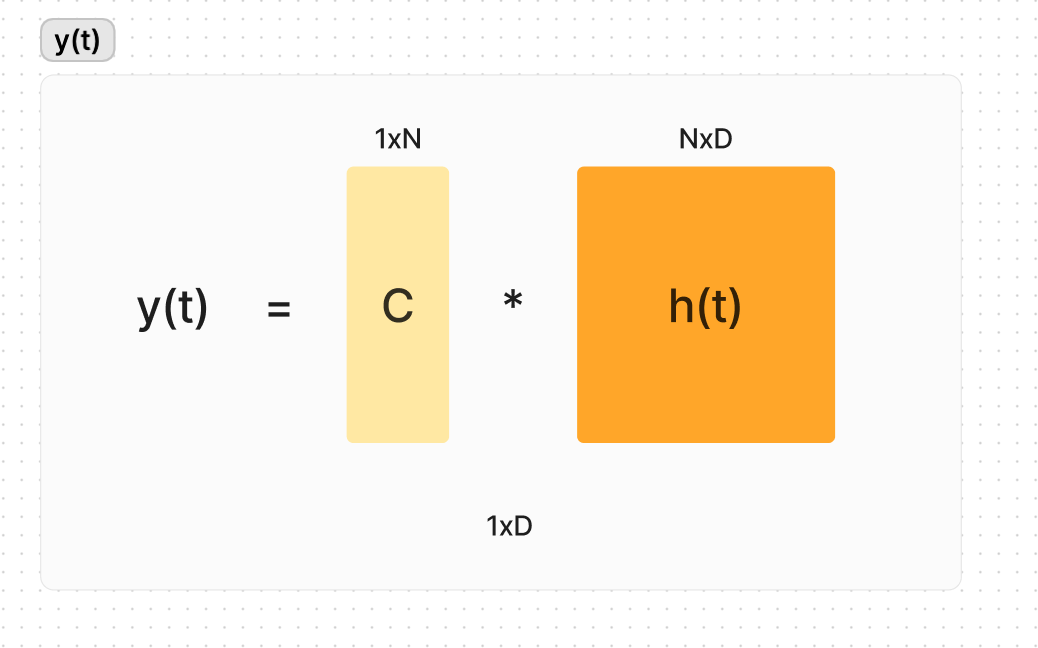
Then y(t) or the prediction is simply C * h(t). h(t) will be updated as we go along so y(t) is not directly influenced by x(t) but through h(t).
The A matrix tells us how the hidden space should be updated over time.
The B vector tells us how the current input should be transformed into the hidden space.
The C vector converts the hidden state to the final output.
Note that different from your standard recurrent network - it is just fully linear, and does not have the non-linear transforms that a LSTM or GRU have inside them.
Discretization
There is also a discretization step of all the “continuous parameters” where you will see the equations be re-written.

The discretization involves a step size “delta”.
Delta can be thought of as how you chop up A, B, C into discrete parts, and is also something you can learn. This allows the model to decide how it wants to chop up the input into different step sizes. It also means different SSM layers can act at different scales with learned deltas.
The discretization equations are a little fuzzy to me, and I would love to dive in more to what they actually look like in practice. Let’s just continue to think of it as learning to chop up the input into different scales.
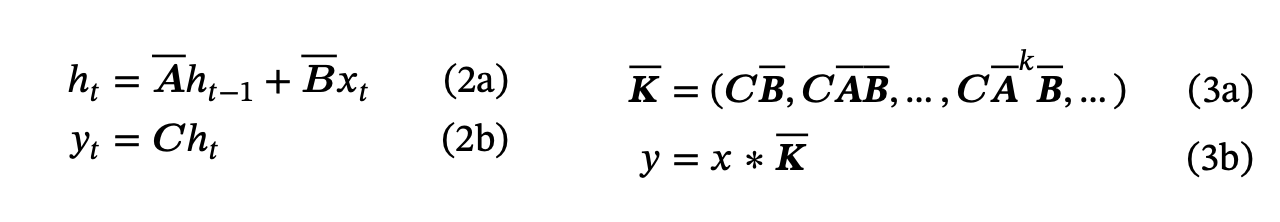
“Resolution invariance” - The different step sizes in theory can be important for different SSM layers to look at different dependencies at different resolutions in the text. They mention it can also be thought of as a gating mechanism and normalization steps.
Selective State Space Models
To solve the problem we mentioned at the top of “what information to collapse” from the input - Selection can be thought of as a means of compression.
Sequence modeling is the art of compressing context into a smaller state, and then using it to predict the output sequence.
Attention does not compress the context at all, it gives the model full access to the history. Attention can be used with RNNs and has been in the past, it is just quite computationally expensive.
There is an efficiency vs effectiveness trade-off of how well models compress their state. If you have a small state with little context, you will be more efficient. If you have a large state with lots of context the model will be slower but more accurate.
They test the ability to compress and remember information on long sequences with synthetic tasks that require selective copying as well as induction heads.
The contributions they make in this paper to SSMs are as follows
- A selection mechanism, that allows the model to filter out irrelevant information, and remember relevant information indefinitely.
- A hardware aware algorithm that computes the model recurrently but does not materialize in the expanded state, optimizing for GPU memory layouts.
The combination of these two techniques give the following properties
- High quality results on language and other data with long sequences
- Fast training and inference
- Memory and compute scale linearly in sequence length during training
- Inference involves unrolling the model one element at a time with constant time per step, with no cache of previous elements
- Long context - performance improvements up on real data up to sequence length 1 million
Note they say “performance improvements” not “we have solved sequence lengths up to 1 million”.
Improving SSMs with Selection
In previous work, such as the S4 paper, they do a clever trick where they unroll the RNN into a “wide CNN” for training.
If you want to look at the math of unrolling it is here:

The key to this trick is the fact that RNNs are traditionally slow to train. So since S4 can be run in convolutional mode or recurrent mode they use:
- CNNs for training (fast training, slow for generation)
- RNNs for inference (slow and difficult to train, fast generation)
SSM + Selection (S6 🐍) only does not do this convolution trick, and sticks to an RNN. It adds in selection mechanisms S(x) and S(x) Linear operations to help the model remembers and what it forgets.

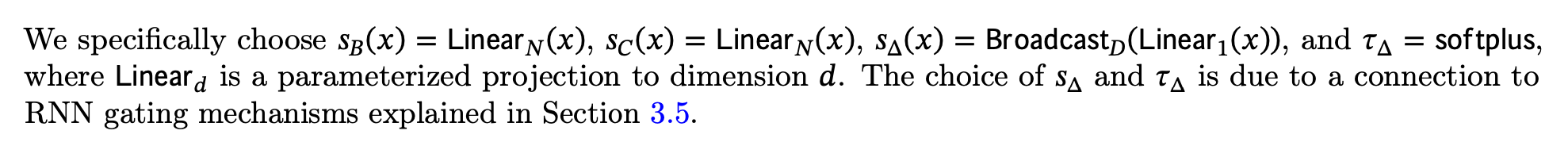
The selection mechanism is simply Linear layers that wrap the B, C and delta parameters. It reminds me a lot of gating mechanisms in GRUs.
Note that they do not have a selection mechanism on A, just on B, C and delta. They hypothesize that adding it to A could help too, just didn’t run the experiment.
Hardware Acceleration
~ TLDR ~ the model efficiently stores its parameters in SRAM and they perform the discretization and recurrence in SRAM while writing the final outputs to HBM (high bandwidth memory).
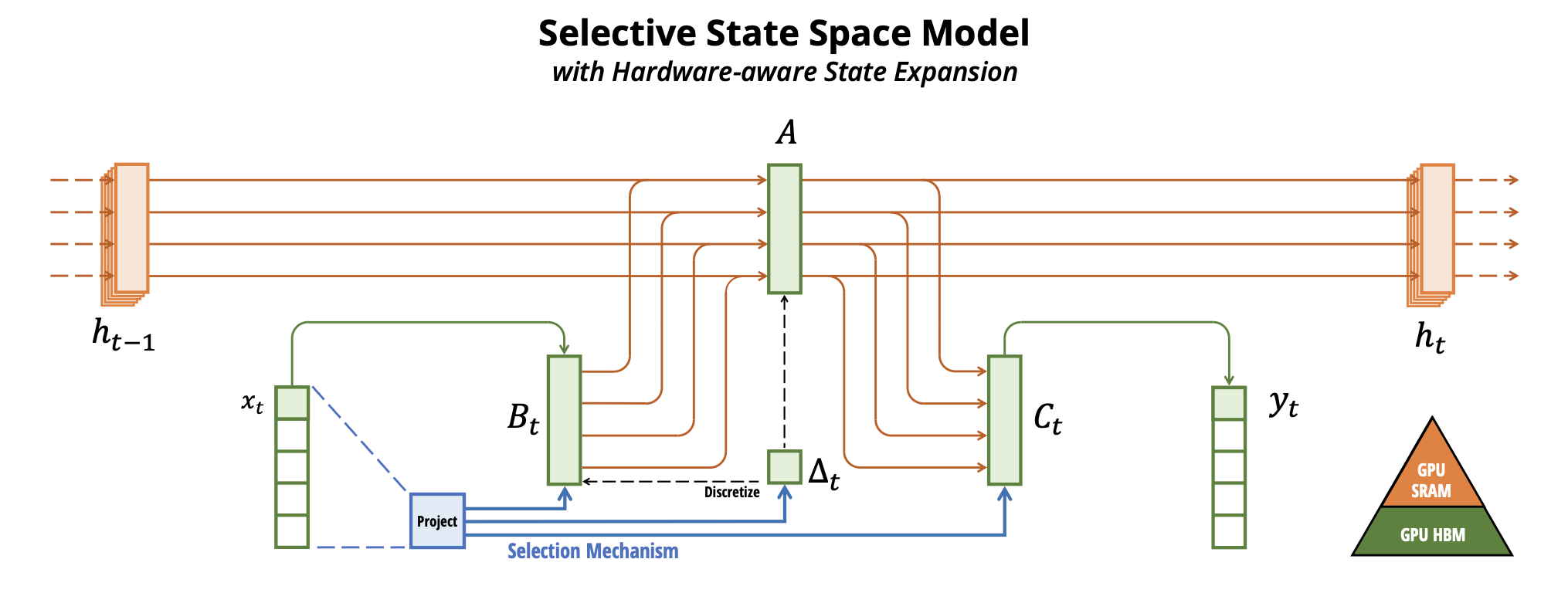
The trick is how you organize the vectors and matrices to minimize copies between memory locations and enable some parallelization during the scan. “With selectivity, SSMs are no-longer equivalent to convolution, but we leverage the parallel associative scan.”
There is more on this in Appendix D if you are curious about the details, but the main takeaway is they make the recurrent operation fast to train.

A Simplified SSM Architecture
Selective SSM blocks can be incorporated as standalone transformations into a neural network, just like you would a RNN Cell like an LSTM or GRU. The full architecture of a Mamba block is below, and is not just the SSM module we covered above. There are linear projections, convolutions, and non-linearities surrounding the SSM block in a larger Mamba block.
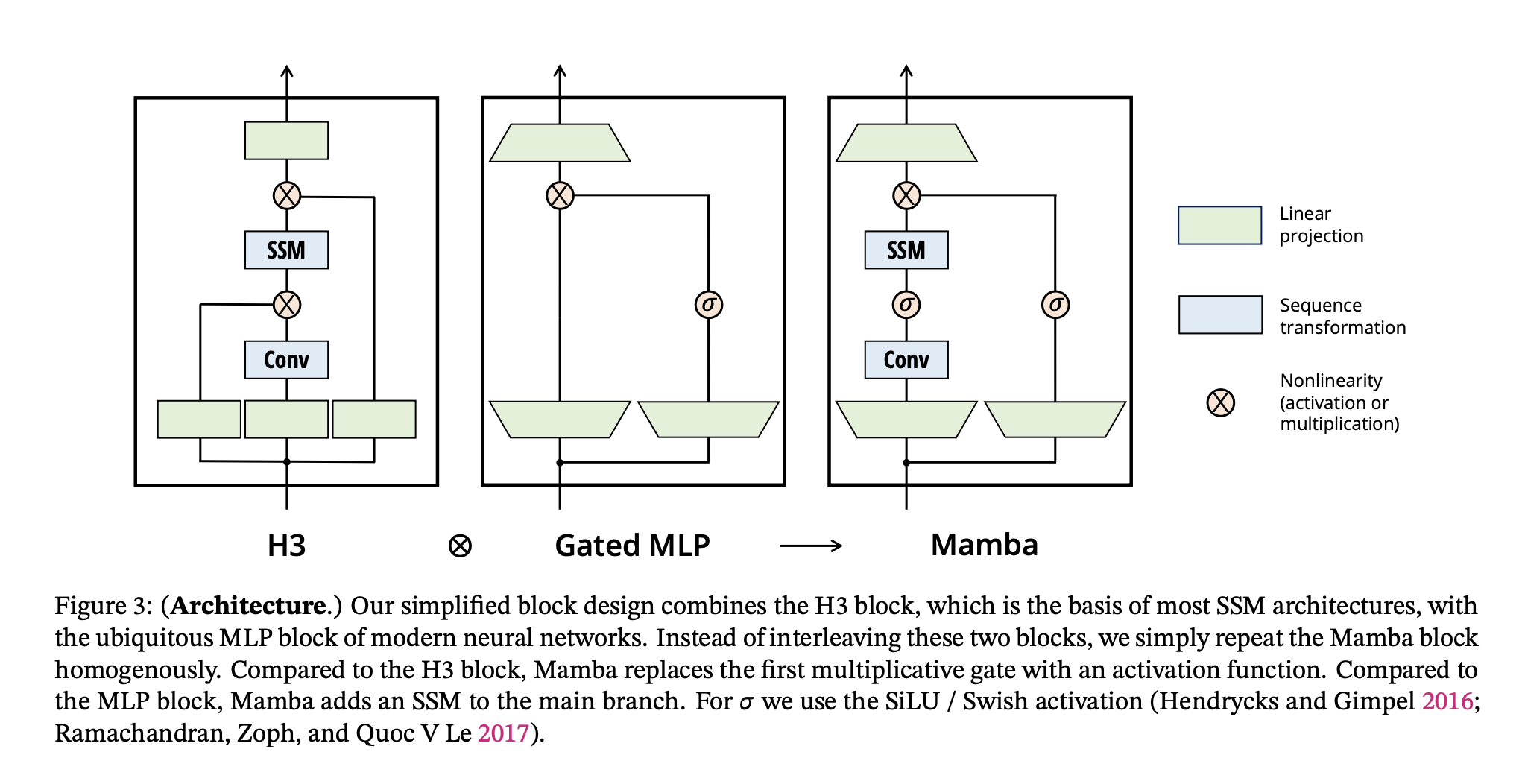
They first project the input up through a linear layer that expands the dimensionality of the input, they also add a residual connection on the right hand side similar to the transformer.
Then they run a 1D convolution over the linear layer, pass it through a SiLU / Swish activation function, before it gets to the SSM block we talked about above.
The residual path then connects back with the output of the SSM and they shrink the dimensionality back down to the same as the input with a final linear layer.
An important connection: the classical gating mechanism of RNNs is an instance of the selection mechanism for SSMs.
They argue that the selection mechanism has many benefits:
- Selectively filtering out irrelevant noise tokens
- Resetting state to remove irrelevant history
- Using different “delta” step resolutions helps balance how much information we want to save from the current input vs updating the state from a larger window.
This is the part that gets fuzzy for me, how is this solving the compression problem for sequence lengths up to 1M? Feels similar to the architecture of an LSTM or GRU, granted different parameters and different connections. What is the core insight that leads to selection working better here than in a traditional RNN with gating?
I posed this question on Reddit if anyone wants to chime in, maybe there will be an answer by the time you read this: https://www.reddit.com/r/MachineLearning/s/Yg5AjZNVr0
Evaluation
They run this model on a few tasks:
- Synthetic data - copying via induction heads (harry potter example)
- Language modeling pre-training
- Audio generation, finish this waveform or speech sample
- Genomics or DNA modeling - language modeling / Great Apes classification.
The performance on language modeling is particularly interesting, as it outperforms modern transformer architectures.
Synthetic Data - Induction
If you remember, we covered induction heads in the Mechanistic Interpretability papers:
 Greg Schoeninger
Greg Schoeninger
Induction heads are a mechanism that Transformers use to look back at previous context to help decide what they will predict next.

There is a great example of this in this work by Anthropic.

They show that mamba blows other models out of the water on this task of induction. It can selectively copy from sequence lengths of 2^20, which is where they get the 1 million context length number.
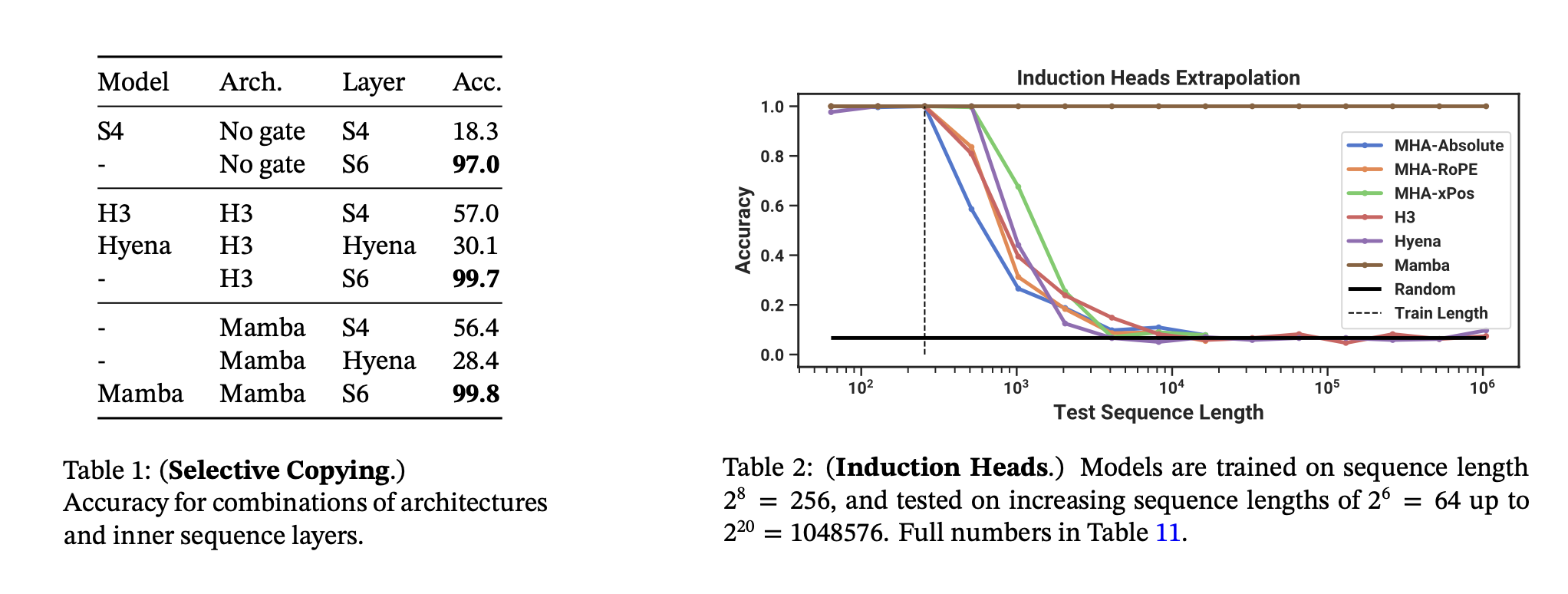
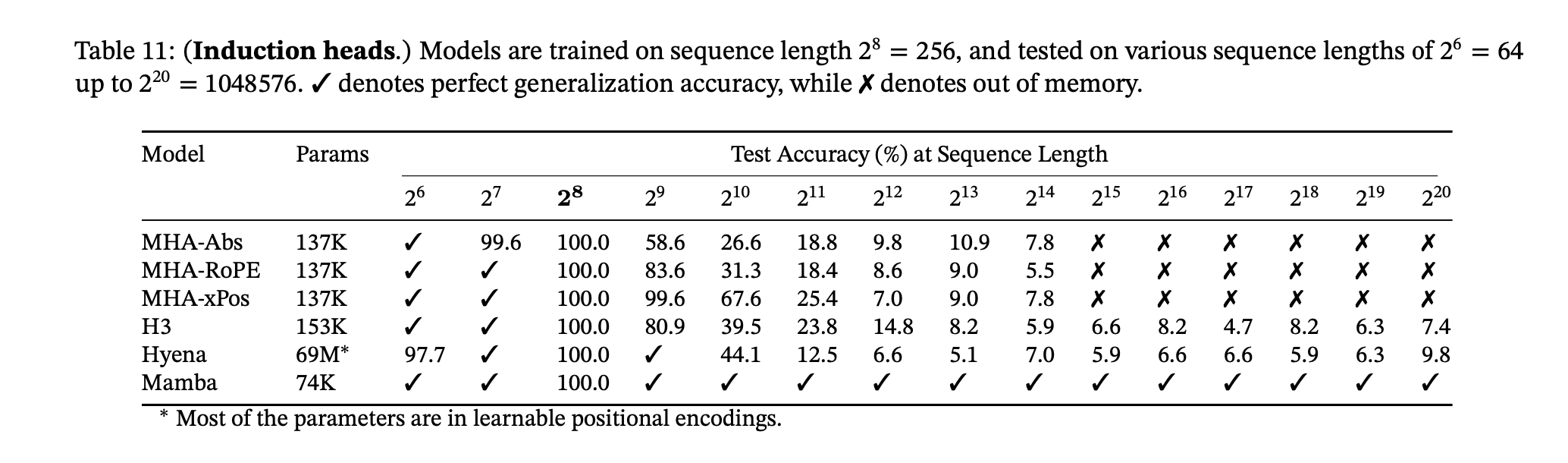
Remember this is not free up to a sequence length of a million, it is still linear with respect to O(BLND) - Batch, Seq Length, Hidden size, word vector Dimension.
Language Modeling
On the task of simply predicting the next word for large language model pre-training, Mamba out performs the best known transformers of the same size. They measure perplexity (ability to predict the next word) and zero-shot downstream tasks.
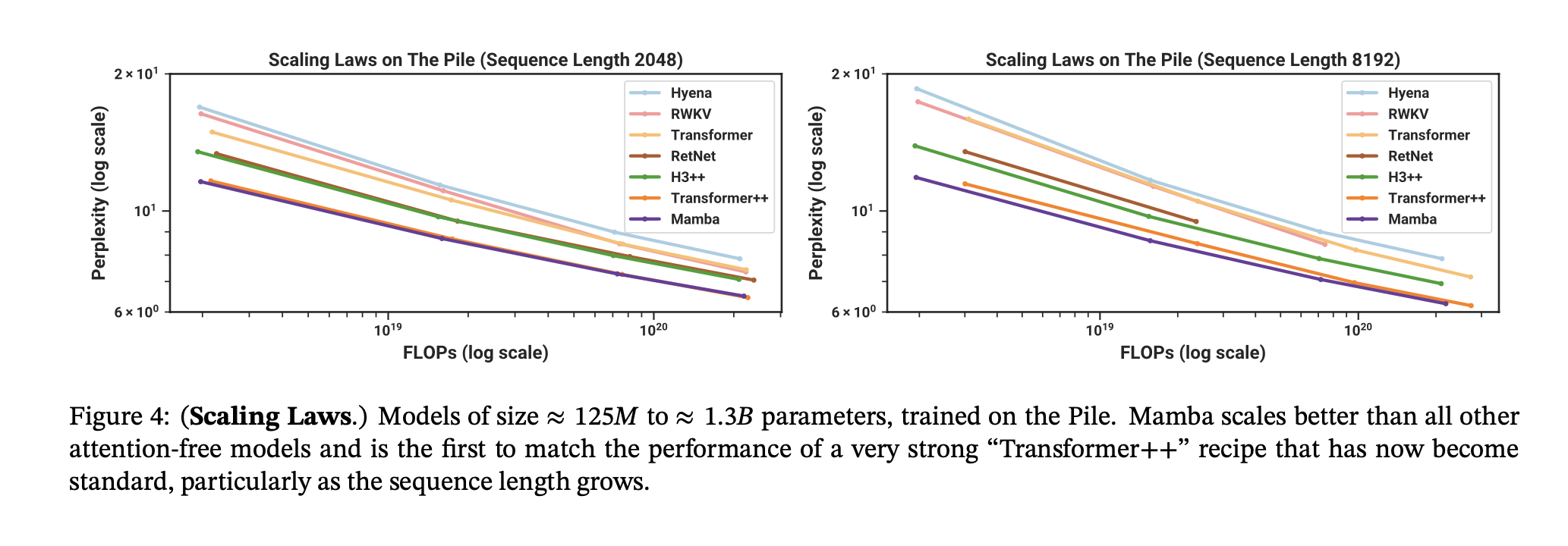
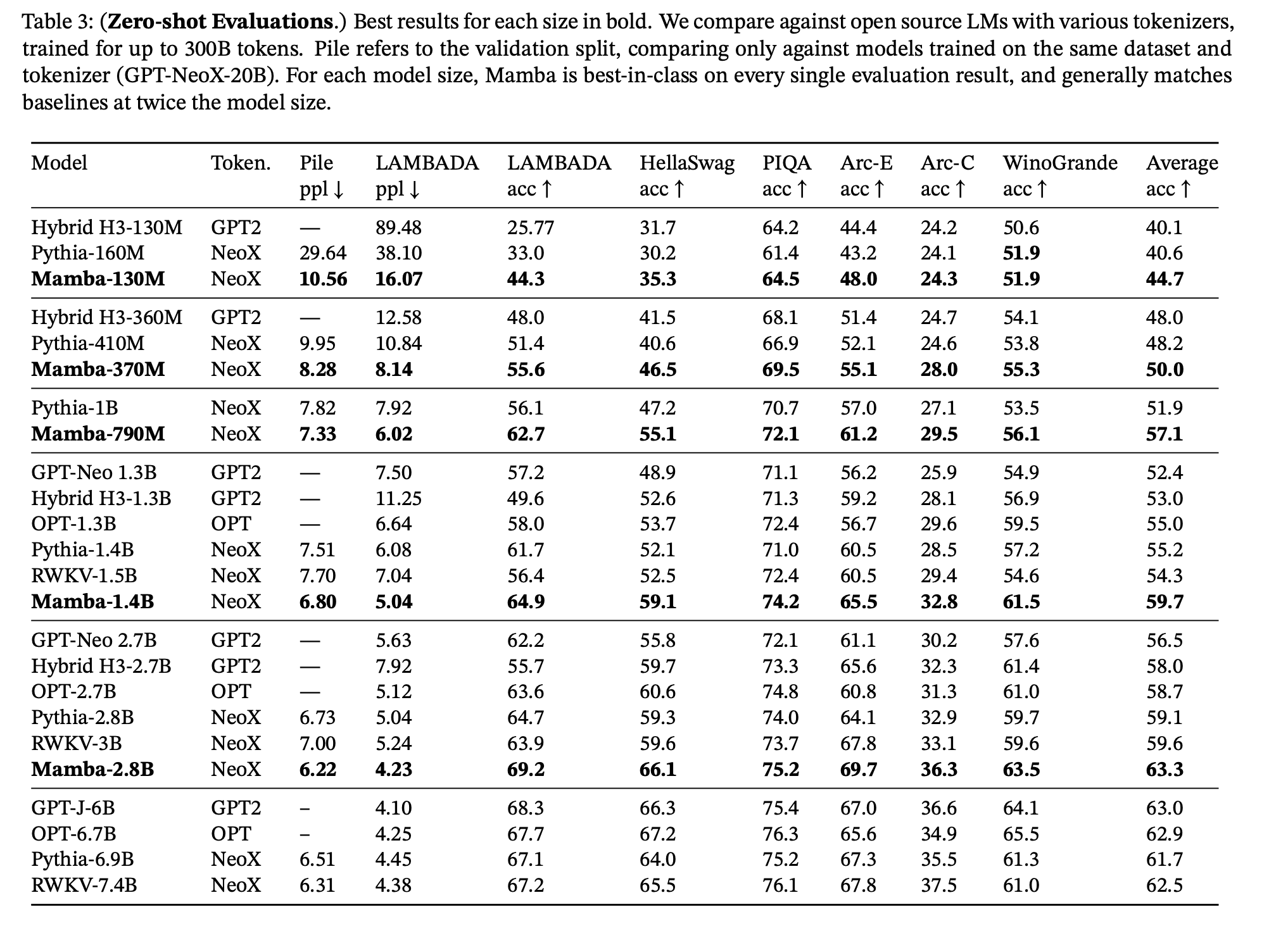
They also test on Zero-Shot prompting tasks, and Mamba out shines models of similar sizes trained on similar data.
DNA Modeling & Classification
They run experiments on classifying between 5 species by randomly sampling a contiguous segment of their DNA.
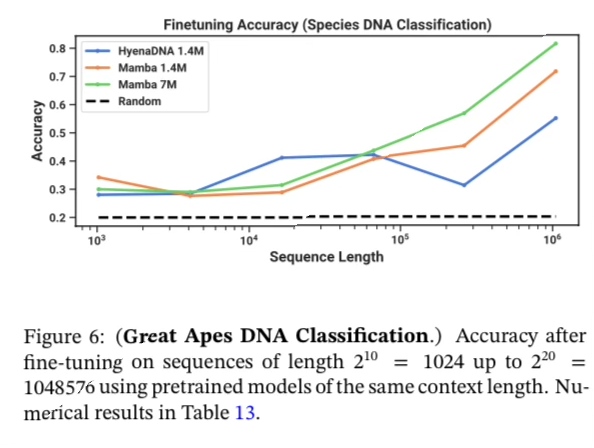
Previous work like HyenaDNA did this between “human, lemur, mouse, pig and hippo”. This work does a significantly more challenging task of 5 great ape species “human, chimpanzee, gorilla, orangutan, and bonobo”.
Audio Generation
For audio generation, they use the YouTubeMix standard piano music dataset which consists of 4 hours of solo piano music sampled at 16000Hz.
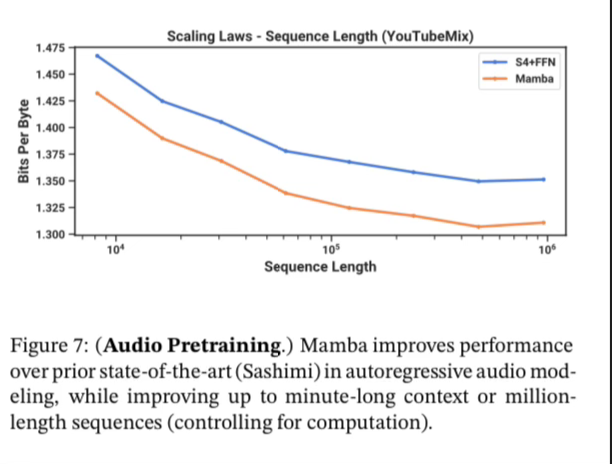
They also show it works well on speech generation for 1 second clips of audio saying the digits “zero” through “nine”.
A small Mamba outperforms many state of the art much larger GAN and diffusion based models.
Conclusion
All in all, this is encouraging evidence that in some sense RNNs in the form of SSMs could still be a promising direction of research.
No Free Lunch - They do note that the discretization step helps for discrete modalities like text and DNA, but removes some of the inductive biases that a SSM would have for continuous signals like audio waveforms.
I’d say I understood 90% of this paper, but if anyone has thoughts or intuitions on why the SSMs work better than GRU or LSTM on selective sampling of the input, I would love your thoughts.
Edit: Had the author of the paper chime in and confirm the similarities and inspiration from gated RNNs
yep, it's very similar and my work on this direction came from the direction of gated RNNs. the related work talks a little more about related models such as QRNN and SRU
— Albert Gu (@_albertgu) December 15, 2023
I also started a conversation here that may lead to some insights.
https://www.reddit.com/r/MachineLearning/s/Yg5AjZNVr0

Next Up
Thanks for sticking around this far! To find out what paper we are covering next and join the discussion at large, checkout our Discord:

If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.

The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI