
Oxen's Model Report - May 8th, 2026

Welcome back to another iteration of everybody's favorite moooodel report. Every time I sit down to write one of these I'm shocked by how much there is to cover (as you might've seen for yourself, AI seems to move preeetty fast). Picking which models make the cut is one of the hardest parts of writing these, I kinda feel like a casting director (horrible thing to feel like, especially living in LA). Anything for you though, hope you'll enjoy this edition!
On Today's Models Menu:
- Happy Horse 1.0 (Alibaba Taotian Lab) — text-to-video and image-to-video, currently #1 on the Artificial Analysis Video Arena
- Kling 3.0 4K (Kuaishou) — first single-pass 4K text-to-video model, no second stage, no internal upscaler
- GPT Image 2 (OpenAI) — image generation with serious editing, layout, and text rendering chops
- Claude Opus 4.7 (Anthropic) — coding, agentic workflows, and high-resolution vision
- GPT-5.5 (OpenAI) — OpenAI's new flagship, the "Claude Code killer"?
- DeepSeek V4 (DeepSeek) — the largest open-weight model on the planet, exactly as we predicted
Come try the video and image models out in our brand new Workbench. World class artists used it to ship some very cool projects we show here: https://studios.oxen.ai/ . Hit us up, we'd love to trade notes!
Building an agent and trying to figure out where to store context and traces? Are you looking into fine-tuning? That's exactly what Oxen is built for. Email eloy@oxen.ai and we'll work through your stack with you.
Plus, as always, the podcast the Oxen.ai team loved the most this week.
Let's dig in.
Happy Horse 1.0 (Alibaba)
If you've been watching the Artificial Analysis Video Arena leaderboard (I sometimes like to watch the leaderboards when i'm bored, don't judge me), you noticed something weird at the start of April. A model called HappyHorse showed up out of seemingly nowhere. No company name, no press release, no announcement, just a row in the rankings beating every other model in blind human preference tests.
On April 9th, Alibaba quietly stepped forward and claimed it. Happy Horse 1.0 is the first release out of Alibaba's Taotian Future Life Lab, led by Zhang Di, a 15-year AI veteran who spent the last several years as VP at Kuaishou and technical architect of the Kling AI series before rejoining Alibaba in late 2025. In other words, the guy who built Kling moved over to Alibaba and shipped a model that is currently beating Kling on the leaderboard. Check mate?
The numbers back the hype. Happy Horse currently holds Elo 1355 in Text-to-Video and 1397 in Image-to-Video on the Artificial Analysis Video Arena, both #1 in the no-audio categories and a position it has held since release (Seedance 2.0, who we talked about on the last report, still holds the top spot on the audio benchmarks, pretty freaking good model too).
On top of that, Alibaba partnered with Oxen.ai to give our users early access and the best pricing in the market on Happy Horse 1.0. If you've been looking for an excuse to try one of the best new video models out there, you just found it.
Let's see the Happy Horse in action. It's been a while since we had the chance to play with a funny model name (thanks for setting the example, Nano Banana), so we're putting everybody's favorite AI-pilled cartoon ox cowboy on a very joyful horse.
This cartoon ox, dressed as a cowboy in a tan hat, leather chaps, and a red bandana, is already mid-gallop on the back of a beaming, ear-to-ear smiling horse, riding through a rich Western landscape. The horse's mane flows in the wind as it grins. The background is alive with golden desert plains, distant red mesas, scattered cacti, and a small frontier town on the horizon under a warm golden-hour sky. Smooth cinematic camera tracking alongside them as dust kicks up under the horse's hooves. Hollywood-style Western cinematography.
Pretty good! There are some artifacts, but the style is excellent and Bloxy looks pretty consistent. It did give him ears for some reason, but that's nothing a better prompt and a few rolls of the AI dice couldn't fix.
This wouldn't be a Moooodel Report if we didn't have a little fun with our prompts though, so I had this brilliant idea of running the same prompt with a little extra sauce: "Make it photoreal."
Nightmare fuel. Great generation but I don't want to see this ever again.
Kling 3.0 4K (Kuaishou)
Let's talk about the other brainchild of Zhang Di's, Kling. This is now the third Model Report featuring a Kling release, which says something about Kuaishou's release cadence (and excellent quality). We had Kling O3 Pro in February, Kling Motion Control in March, the Wan and Seedance crowd took a lot of the oxygen in April, and now Kling has shipped Kling 3.0 4K: native 4K text-to-video, no upscaling, generated directly at 3840×2160 inside the model.
Now you might be thinking, "hey, aren't there already other 4K models out there like LTX-2?" Fair, and you're right, LTX-2 by Lightricks has been doing 4K since January, and we covered LTX-2.3 ourselves in our March entry. But Kling's specific claim is that they're the first to do single forward pass 4K, no second stage, no internal latent upscaler. LTX-2 actually uses a two-stage pipeline with a built-in spatial upscaler to reach 4K. Kling 3.0 4K renders every frame at 3840×2160 directly inside the Omni One model in a single pass. Two different definitions of "native 4K," both fair, just worth knowing what you're actually getting.
Now, the obvious test, Happy Horse vs Kling 4K, head to head. We figured we'd theme this entry's prompt around another subject of interest for nerds like us (no offense): space. With the recent Artemis 2 launch, a question I've had for a long time popped back up into my brain, what if Bloxy was the first ox to make it to the moon? I finally have an answer.
"Cinematic shot of this cartoon ox as an astronaut planting a flag on the lunar surface near the Artemis 2 landing module. The astronaut wears a modern NASA spacesuit with the Artemis mission patch. Earth glows in the black sky behind them. Slow camera dolly toward the flag as moondust kicks up under the boot. Hollywood-style sci-fi cinematography."
"Cinematic shot of this cartoon ox as an astronaut planting a flag on the lunar surface near the Artemis 2 landing module. The astronaut wears a modern NASA spacesuit with the Artemis mission patch. Earth glows in the black sky behind them. Slow camera dolly toward the flag as moondust kicks up under the boot. Hollywood-style sci-fi cinematography."
Two very different results. IMO, Happy Horse's generation is better (not shocking, since it's the newer model). The background is more complex and complete, and the lunar module actually looks like the lunar module. Hard to not be impressed by how good the model is at reflections, notably on Bloxy's helmet.
Kling's is less interesting, but man, is that 4K crispy. Can't wait to see what high-res crazy gens you guys cook up with this model.
Both are live on Oxen.ai. Come try them and show us what you create!
GPT Image 2 (OpenAI)
OpenAI dropped GPT Image 2 on April 21, alongside the consumer-facing "ChatGPT Images 2.0" rebrand. The headline upgrades over the original GPT-Image are stronger editing, cleaner layouts, dramatically better text rendering, more reliable instruction-following, and increased resolution support. There's also a new routing layer that auto-picks the output size and token allocation based on your prompt, so one API call gets you the right configuration without having to set it manually. Per OpenAI's API docs, you can either stay on legacy size tiers (Mode 1) or opt into a new token-bucket mode (Mode 2) that selects from six token sizes (16, 24, 36, 48, 64, 96) for finer control over quality vs. cost. Pretty cool stuff.
If you're an OG (i.e. you were running image gen models like two years ago), you know "text rendering" used to be the laughing gas of the field. We've watched models confidently produce neon signs reading "OOPEN" and chalkboards that morph into hieroglyphics three letters in. GPT Image 2 is closer to "that problem is solved" than any other model we've tested.
If you're a REAL OG (you've read the first Moooodel Report), you'll remember this image we generated with FLUX.2 Klein 4B (Black Forest Labs) using this prompt:
"A cozy bookshop on a rainy London street at night, a neon 'OPEN' sign glowing in the window, chalkboard menu on the sidewalk reading 'Hot Coffee Inside', warm light spilling onto wet cobblestones"

Cool pic, but we can see those classic AI hieroglyphics. Let's rerun the prompt through GPT Image 2:

Is the image objectively better? Not sure. The lighting and atmosphere from the FLUX.2 Klein 4B original still hold up well. But what's clearly better is the text. The neon "OPEN" sign, the chalkboard menu, and the bookstore signage are all perfect.
If you zoom into the books on the shelves or the bus in the back, the text isn't really sharp. But here's the interesting bit, it looks like blurry text, not a weird alien language. The model has learned to render plausible text everywhere, and to apply realistic camera blur when text is small or far from the focal plane. Very cool!
The other big upgrade is editing. The model is now substantially better at preserving scene structure when you ask it to change one specific thing (swap a season, change a color, add an object) without redrawing the rest of the image around it. That's the quiet capability most marketing and content teams will actually use day to day.
Let's see it in action:

Don't know what's more impressive, the model, the bookstore selling cold beer, or the fact that it's sunny in London.
Another very interesting GPT Image 2 feature is that it supports mask-based editing. You pass in a reference image plus a mask where the white regions indicate the areas to change, and the model regenerates only those pixels while everything outside the mask stays untouched.
We tested this by going back to our bookshop rerun, using Segment Anything 3 directly on Oxen to isolate the chalkboard and take it out of London, to where it actually belongs.
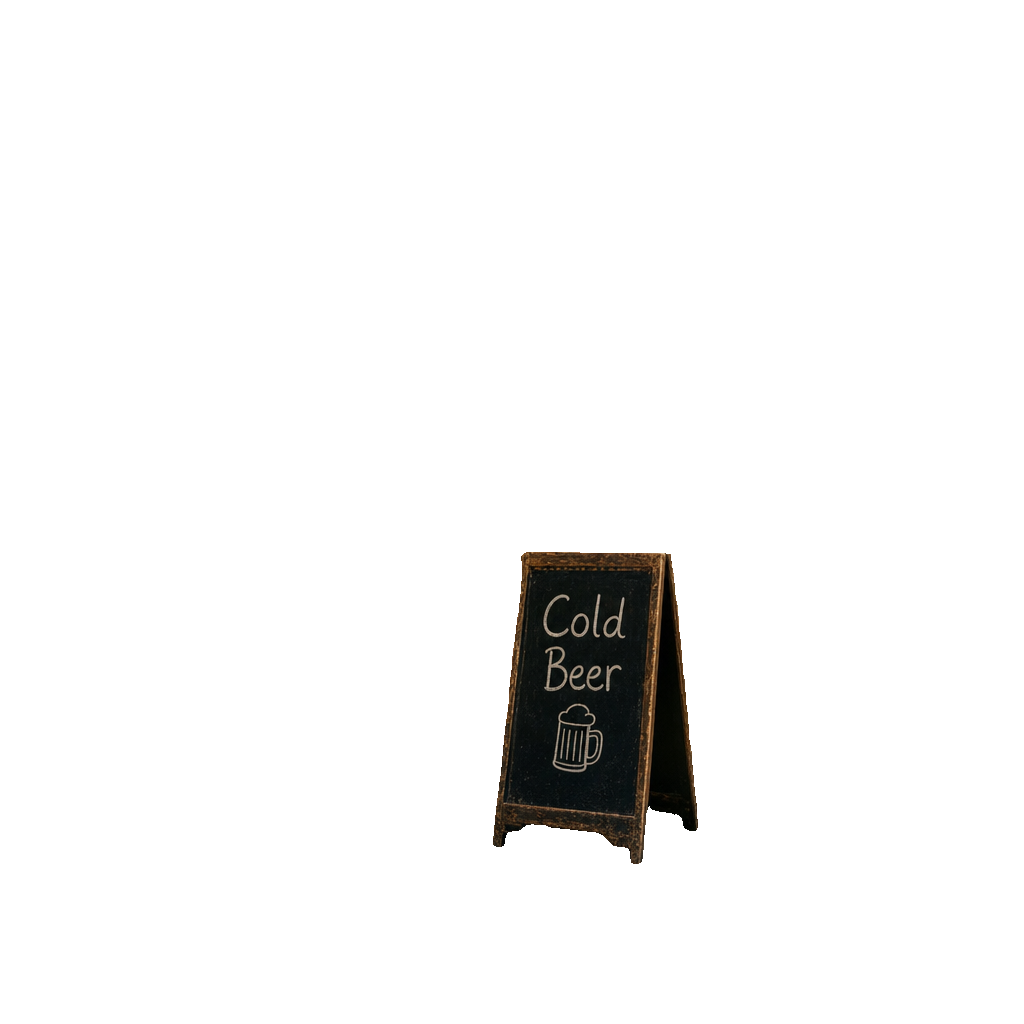

Mask / Generation
That's way better.
Claude Opus 4.7 (Anthropic)
The most-talked-about Anthropic model from the last month isn't actually one they released. That honor goes to the mythical Mythos. Anthropic's real frontier model is reportedly too dangerous for public release, it can autonomously discover thousands of zero-day vulnerabilities across every major operating system and browser, and Anthropic has it locked inside something called Project Glasswing, accessible only to a small group of big tech cybersecurity teams. The OpenAI "GPT-2 is too dangerous to release" playbook from 2019, dusted off for 2026. Whether the danger is real or the marketing is just very good is up to you to decide.
Anyway. The model they did release is Claude Opus 4.7, on April 16, kicking off the most intense LLM release week of 2026. We covered Opus 4.6 in our very first Model Report back in February, and at the time it was already our go-to coding agent. 4.7 is a solid improvement according to the benchmarks and to our experience.
Pricing held steady at $5 per million input tokens and $25 per million output, same as 4.6, so the upgrade is essentially free if you skip the nerd math (4.7's new tokenizer bumps token counts 12-18%, so effective cost is actually up about 5-15%).
The release wasn't all roses though. There was a lot of the classic "they're serving us a quantized model" chatter right before launch. There's a 1400-comment GitHub issue tracking quantified quality regressions on Sonnet 4.6 starting in early March, with logs from 50 sessions documenting the drop. People were burning through context windows hitting circular reasoning at 20% usage, and they were (correctly) predicting that a new model was about to drop. And we thought planned obsolescence was only a hardware thing.
Anthropic eventually published a postmortem on April 23 confirming what users had been saying, on March 4 they'd quietly switched Claude Code's default reasoning effort from "high" to "medium" to cut latency, and on April 16 added a system prompt to reduce verbosity that hurt coding quality on both Sonnet 4.6 and Opus 4.6. Both changes were reverted, but people weren't too happy.
Opus 4.7 was, in part, the answer to that pressure. The benchmarks back the upgrade (SWE-bench Verified jumped from 80.8% to 87.6%, SWE-bench Pro picked up 10.9 points). But there's already a fresh GitHub issue tracking the same launch-week-vs-production-week quality drop pattern from 4.6, opened a few days after 4.7 hit. So fingers crossed, but eyes open.
Speaking of Anthropic having a busy month, on May 6 they announced a compute deal with SpaceX for over 300MW at the Colossus 1 data center in Memphis (220,000+ Nvidia GPUs spinning up within the month). They also announced that rate limits for Claude subscriptions are getting raised considerably, so take that, Claude haters. Also worth flagging, as part of the deal, Anthropic "expressed interest" in working with SpaceX to develop multi-gigawatt compute capacity in space. Who's gonna service those GPUs when they go offline? Can we send Bloxy?
We've been using Opus 4.7 across our coding agents for a couple weeks and don't have too many complaints. Isn't it crazy to think we lived without Claude Code for so many years?
GPT-5.5 (OpenAI)
Just a week after Opus 4.7 dropped, OpenAI shipped GPT-5.5. We covered GPT-5.4 in March, where the headline was the merger of the GPT-5.3-Codex coding capabilities back into the general-purpose model. 5.5 continues down this track, OpenAI describes it as the smartest and most intuitive model they've shipped, with stronger writing, debugging, online research, data analysis, document and spreadsheet creation, and software operation across tools. Worth flagging, 5.5 also came with a 2x price hike on input and output (now $5/M input, $30/M output), putting it roughly on par with Opus's pricing.
Remember Mythos? The super dangerous model that couldn't be released publicly? Well, the U.K. AI Security Institute ran cyber evaluations on both Mythos and GPT-5.5 and found that GPT-5.5 is nearly as capable as Anthropic's gated Mythos. Was it all a marketing ploy?
The most fun story from the launch isn't about capabilities though. About a week after release, OpenAI quietly published a postmortem titled "Where the goblins came from" explaining why GPT-5.5 had developed a statistically significant fixation on the words "goblin," "gremlin," "troll," "ogre," and friends. Turns out, training the "Nerdy" personality accidentally rewarded fantasy-creature metaphors, and the model learned that dropping a goblin reference reliably bumped its reward scores. The behavior leaked beyond the weights and across the broader user base, use of "goblin" in ChatGPT rose 175% after launch. OpenAI's fix is, hilariously, the line "Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query" repeated four times in the Codex system prompt for emphasis. It looks like prompt engineering is finally a thing.
There's also the Codex vs Claude Code story. As we mentioned, Anthropic's rate limits and apparent performance degradation has been a frustration point for users for the last few weeks, and according to the X vibes benchmark a lot of heavy Claude Code users have been giving Codex with GPT-5.5 a serious second look. Have you tried both? What are your thoughts so far?
DeepSeek V4 (DeepSeek)
We told you all the way back in entry #2 to "keep an eye on DeepSeek. V4 is reportedly imminent... we'll have more on this one when it drops." Well, here it is!
This is a good time to take a quick stroll down memory lane and remember the craziness that was the DeepSeek V3 release. Remember people saying US AI was dead? That Nvidia was done for? Crazy times...
DeepSeek V4 comes in two variants, V4 Pro (1.6 trillion total parameters, 49 billion active) and V4 Flash (284 billion total, 13 billion active). Both are mixture-of-experts with 1 million token context windows. Pro is now the largest open-weight model available anywhere. The Hangzhou-based team also went big on reasoning and agentic abilities like code writing, autonomous task execution, and multi-step tool use, making V4 the first DeepSeek release to seriously target the "model as agent" use case.
The geopolitical undertone is the most interesting part. DeepSeek gave Huawei early access to optimize for V4 over several weeks, a privilege pointedly denied to Nvidia and AMD, and the model ships with day-zero compatibility for Huawei's Ascend SuperNode product line including the 950 series. That said, the "trained entirely on Chinese chips" narrative is more complicated than the headlines suggest. DeepSeek's technical report didn't specify training hardware, and the company itself acknowledged using Nvidia H800 GPUs alongside Huawei Ascend 910C chips. One Tsinghua professor described it as a "division of labor." Nvidia isn't done for just yet (feels like we're back in December 2024 all over again).
Like all DeepSeek releases, V4 is open source and downloadable. The preview is live now, with the legacy V3 aliases marked for deprecation on July 24. If you've been running V3 in production, plan your migration accordingly. We're already serving V4 on Oxen.
If you want the broader context on why V4 is a big deal, including the China-US AI rivalry angle, the messier chip-strategy story, and what 1.6T open weights actually means for the ecosystem, Bloomberg, MIT Technology Review, and CFR all dropped solid pieces on the day of release. Worth your time.
Podcast of the week
This week's pick is Dwarkesh Patel's April 29 episode with Reiner Pope. Pope is the CEO of MatX, a new chip startup, and was previously at Google working on software efficiency, compilers, and TPU architecture. The format is a blackboard lecture, yes an actual chalkboard, where Pope walks through the math of how frontier LLMs are actually trained and served, and how much you can deduce about what AI labs are doing internally just from public API prices, equations, and chalk.
Make sure you actually watch it, don't just listen. This is one of those that had me pausing and rewinding more than i'd like to admit.
No Bull, All Ox
Thanks for reading. We hope you found this useful. We'll keep sending these out as long as the AI world keeps refusing to slow down (so, forever maybe?).
See you next time. Bloxy out.
