
Writing a fine-tuning and deployment pipeline isn't as easy as it looks (Gemma 4 Version)

Fine-tune and deploy Gemma 4 on Oxen.ai
Google's Gemma 4 dropped in April 2026 with multimodal support (text, image, video, audio), a novel hybrid KV-sharing attention mechanism, and a custom ClippableLinear layer. As we often do, we wanted to be among the first platforms to support both no-code fine-tuning and deployments (and as we often do, we succeeded 💪). But (as it often happens), what looked like a straightforward integration turned into a multi-day debugging marathon across several codebases, each producing different symptoms and each hiding behind the last.
It looks like this release in particular wasn't well coordinated with the OSS community (and we could tell 🙄)
This is where we shine though, we stand at the bleeding edge and fix these quirky bugs so you can enjoy all of what Gemma 4 has to offer without having to think about dependencies, monkey-patches or code (ew).
At the end of this post, we'll also share a fully reproducible notebook if you want to fine-tune and deploy Gemma 4 on your own hardware!
Here's everything we tried, everything that broke, and how we fixed it!
The Setup
Our fine-tuning pipeline:
- Training: SFTTrainer (from TRL) + DeepSpeed ZeRO-3 + accelerate.
- Deployment: Merge LoRA into base model, serve with your favorite inference engine (Sglang -> Vllm)
- Models: Gemma 4 E2B (2B), E4B (4B)
Bug #1: PEFT Rejects Gemma4ClippableLinear
Symptom
ValueError: Target module Gemma4ClippableLinear(
(linear): Linear4bit(in_features=768, out_features=768, bias=False)
) is not supported.Cause
Google added Gemma4ClippableLinear, a custom nn.Module that wraps a standard nn.Linear with value clamping. It only appears in the vision tower (112 modules) and audio tower (120 modules), not the language model layers, which are plain nn.Linear. The clip values are real finite bounds (e.g. (-6.37, 6.31, -11.31, 11.19)), probably calibrated to prevent activation blowup in the multimodal encoders.
But PEFT identifies LoRA targets by checking isinstance(module, nn.Linear). Since ClippableLinear inherits from nn.Module, not nn.Linear, PEFT doesn't recognize it as something it can inject adapters into. All 232 ClippableLinear modules across the vision and audio towers fail this check.
"But I'm only doing text-only fine-tuning, why does this matter?" Because PEFT walks the entire model looking for modules matching target_modules. When you pass target_modules=["q_proj", "k_proj", ...], PEFT finds matching names in the language model (plain nn.Linear, fine), in the vision tower (Gemma4VisionAttention.q_proj, ClippableLinear), and in the audio tower (Gemma4AudioAttention.q_proj, also ClippableLinear). It hits a ClippableLinear and throws before applying LoRA to anything. Even loading via AutoModelForCausalLM still brings the multimodal towers along.
So for any LoRA fine-tuning on Gemma 4, text-only or multimodal, you have to either unwrap the ClippableLinear modules or scope target_modules with a regex that only matches LM paths.
Where the Pre-Fix Path Crashes
Before any of our fixes, the sequence looks like this:
- Load model with original class → ✅ works. Checkpoint keys (
q_proj.linear.weight) match the model's slots (because the model was built with the originalClippableLinearthat has.linearnested inside). All weights load correctly. - Call
get_peft_model(model, lora_config)withtarget_modules=["q_proj", ...]→ ❌ crash here. PEFT walks the whole model, hits aClippableLinear, fails itsisinstance(module, nn.Linear)check, and throws. - Training → never runs.
The model is loaded, the weights are fine, it's PEFT that won't attach adapters. Every fix below is about getting past step 2.
What We Tried
Attempt 1: Pre-load class replacement. The idea: monkey-patch Gemma4ClippableLinear before loading the model so it inherits from nn.Linear directly. Transformers will build the model with our patched class, PEFT will see an nn.Linear, and everyone's happy (or so i thought).
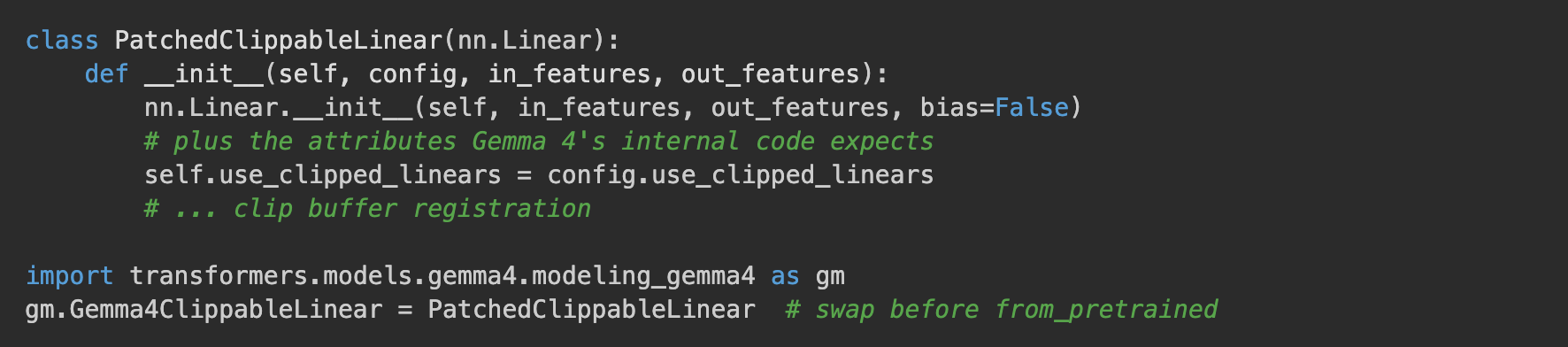
New sequence:
- Load model with patched class → ⚠️ loads, but the checkpoint now looks broken. The model's slots are called
q_proj.weight(our class stores the weight flat, inherited fromnn.Linear), but the checkpoint file still has them namedq_proj.linear.weight. Names don't match. Transformers reports UNEXPECTED/MISSING and random-initializes 232 tower weights (probably worse than an error, a silent warning in the logs 😱). - Call
get_peft_model(...)→ ✅ PEFT seesnn.Lineareverywhere, happily attaches adapters. - Training → runs. Text-only even converges because LM layers loaded fine (their checkpoint keys never had
.linear.). But vision/audio towers produce garbage silently.
We fixed the crash but introduced a worse failure mode: silent corruption at load time instead of a loud crash at PEFT time (Always look at the logs kids).
Here's the load report:

Here's what happened. Google's original ClippableLinear stored its nn.Linear as self.linear = nn.Linear(...), so the weights on disk are saved at q_proj.linear.weight, with .linear. nested in the middle. Our patched class inherits from nn.Linear directly, so its weight lives at q_proj.weight, flat. The key names don't match anymore.
Transformers doesn't crash. It sees the old names, decides the model has no slot for them, and throws them out (UNEXPECTED). Then it fills our model's new slots (MISSING) with random values. All 232 vision/audio tower weights get random-initialized.
Text-only training still works because the LM layers were always plain nn.Linear (checkpoint keys never had .linear. there). But any image or audio input produces garbage, silently. You'd only catch it if you actually tried to use multimodal inputs (remember kids, when implementing a training pipeline, you should always overfit to make sure the model learns what you want to teach it!).
The underlying tradeoff. An nn.Linear stores its weight at self.weight. So:
- To satisfy PEFT, your module must inherit from
nn.Linear, which puts the weight atmodule.weight(flat). - To match Google's checkpoint, the weight must live at
module.linear.weight(nested inside a.linearattribute).
So it looks like we're against a rock and a hard place. Class replacement forces you to pick, and whichever you pick breaks the other side. We also tried to intercept loading and rename the keys on the fly (PyTorch's _load_from_state_dict hook is designed for exactly this), but transformers 5.x uses a faster safetensors path that skips that hook...
So no luck with this strategy, let's get a bit more creative!
Attempt 2: Post-load unwrap.
Load the model with the original class (all checkpoint keys match), then walk the module tree and replace each ClippableLinear with its inner .linear:
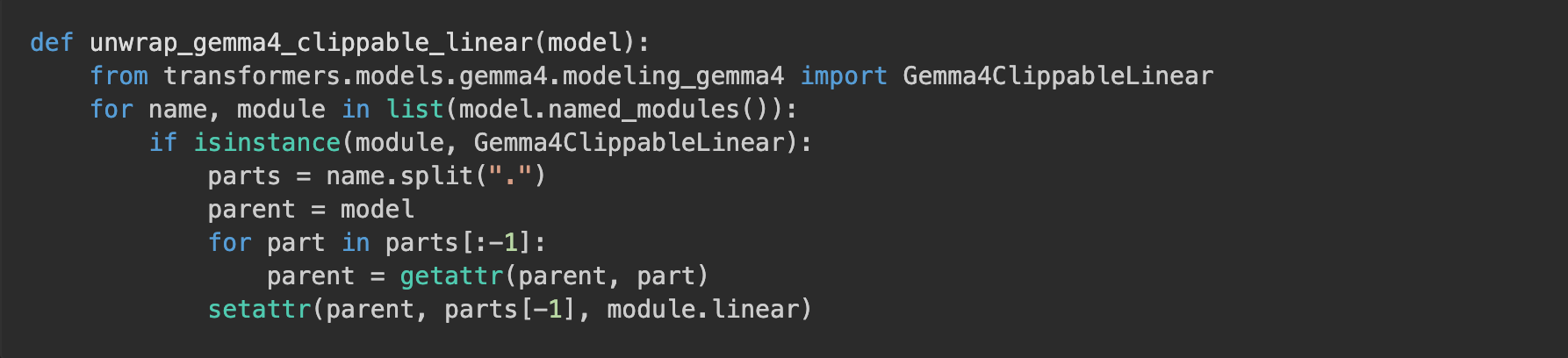
New sequence:
- Load model with original class → ✅ works, checkpoint keys match, weights load correctly. Same as how it works without any fix.
- Run the unwrap → ✅ replaces each
ClippableLinearwrapper with its innernn.Linear. The weight tensors don't move, they just get accessed via a shorter path now (q_proj.weightinstead ofq_proj.linear.weight). The wrapper objects get garbage collected. - Call
get_peft_model(...)→ ✅ PEFT walks the model, seesnn.Lineareverywhere, attaches adapters cleanly. - Training → ✅ runs, converges, produces a working adapter.
Attempt 1 tried to have a class that was both "nested like the checkpoint" and "inherits from nn.Linear like PEFT wants" simultaneously, which (as we just saw) is impossible. Attempt 2 is nested during load (so the checkpoint lands correctly) and flat after (so PEFT is happy). I think people call that a sleight of hand?
8 lines. All 232 ClippableLinear modules unwrap cleanly, zero MISSING keys, PEFT sees nn.Linear everywhere. But the clipping values are discarded in the unwrap, which means vision/audio tower layers lose their activation clipping. In practice this hasn't caused issues for us in fine-tuning or inference, but it's worth noting.
Update (April 14): PEFT v0.19.0 now ships default target modules for Gemma 4 that scope to language model layers only via a regex, sidestepping the vision/audio ClippableLinear modules entirely. If you use PEFT defaults (omittarget_modules), no unwrap needed, and as a bonus the vision/audio clipping wrappers stay intact so Google's calibrated clip bounds still apply at inference. But: the defaults only touch LM layers. If you want to LoRA the vision or audio towers, the defaults won't reach them and you're back to needing either the unwrap or an explicit regex targeting the inner.linearinside each ClippableLinear. Also, if you pass a plain list like["q_proj", "v_proj"], PEFT still walks the whole model and fails on the multimodal ClippableLinear. If i were you i would stop worrying about this and use Oxen.AI 😉
Bug #2: Training Loss Won't Converge
The Sanity Check That Should Never Fail
With Bug #1 out of the way, no more crashes, we wanted to verify the model was actually learning. As the good followers of Karpathy Sensei that we are, we know the golden rule: if your model can't overfit a tiny dataset, it can't learn anything. Before burning any real compute, always prove the pipeline works on a trivial example.
The setup: fine-tune on 50 copies of one example for 3 epochs. If the model can't memorize this, something is wrong!
dataset = Dataset.from_dict({
"text": ["Question: What is the secret number? Answer: The secret number is 42."] * 50
})Expected outcome: loss converges toward 0, generation reproduces "The secret number is 42". If it does, the pipeline is healthy (doesn't mean it's prod ready!). If it doesn't, something's broken.
Symptom
The loss never converged. It bounced around 3-5, never dropped below 1.0. So as all good software engineers have learnt throughout their career, no crashes != working code! (unless maybe you're doing rust, man that compiler is good)
The Investigation
We started by questioning our ClippableLinear patch. Spent hours comparing weight norms, checking key mappings, verifying the unwrap. Everything looked correct.
Then we tried raw Trainer instead of SFTTrainer:
# This works:
trainer = Trainer(model=get_peft_model(model, lora_config), ...)
# Loss converges cleanly, model memorizes "42"
# This doesn't:
trainer = SFTTrainer(model=model, peft_config=lora_config, ...)
# Loss stays high, gradients noisy, model never memorizesSame model, same data, same LoRA config. Raw Trainer works, SFTTrainer doesn't. We traced the difference to one line in TRL's SFTTrainer.compute_loss:
inputs["use_cache"] = False
Why use_cache=False Breaks Gemma 4
Gemma 4 uses a hybrid KV-sharing attention mechanism where later layers reuse KV states from earlier layers. This sharing happens through the Cache object. When use_cache=False, there's no Cache, and the inter-layer KV communication breaks. The attention outputs that come out of those shared layers are garbage.
Garbage attention → garbage forward pass → garbage loss → garbage gradients → no convergence
. That's why loss never dropped.
Raw Trainer left use_cache at its default (True) so the Cache existed, KV-sharing worked, and training converged normally. SFTTrainer forced use_cache=False, broke the shared KV path, and left the optimizer flailing against meaningless gradients.
We confirmed this by wrapping model.forward during compute_loss to strip use_cache:
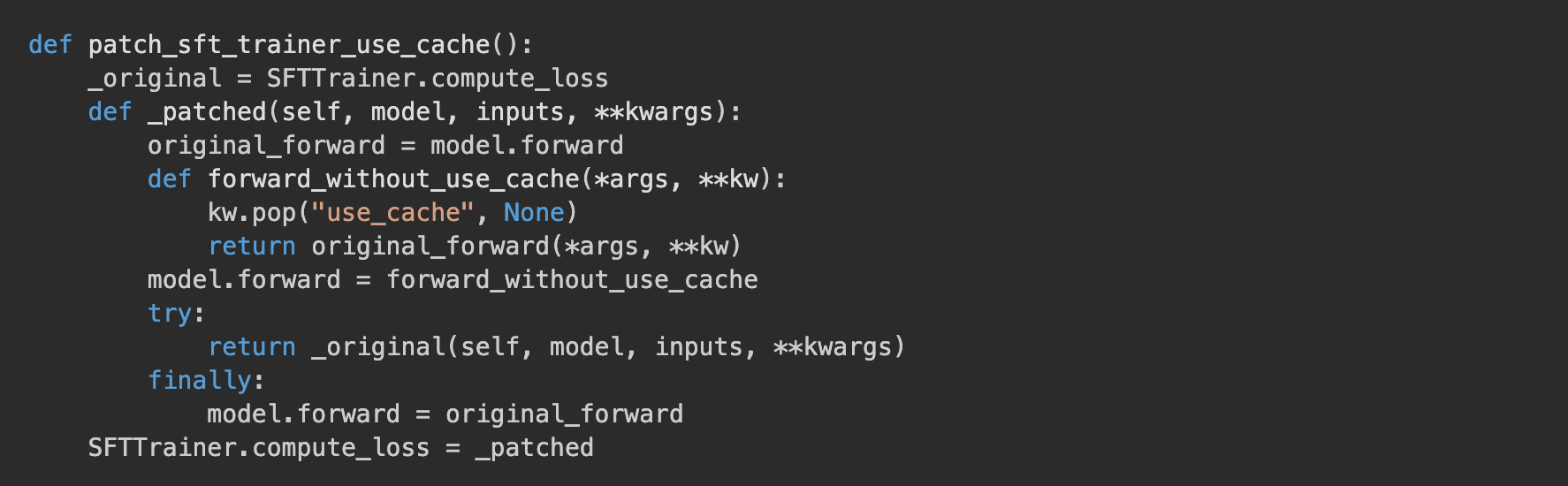
This worked! But, as one does, instead of trying to compound monkey patches in the pipeline we went out and looked for open issues or PRs in the training libs, turns out, this time we were lucky!
The Upstream Fix
On the same day we found the root cause, transformers PR #45312 landed, "Dissociate kv states sharing from the Cache." It makes KV sharing work independently of the Cache, so use_cache=False no longer corrupts attention.
We pinned our Docker image to the commit containing this fix. No monkey-patches needed.
Update: This fix shipped in transformers v5.5.2 (April 9, 2026). No need to pin a git commit anymore, justpip install 'transformers>=5.5.2'. TRL still hardcodesuse_cache=Falsein SFTTrainer (as of v1.1.0), but the transformers fix makes it safe.
Testing the Fix
We ran a fresh fine-tune on Oxen with the upgraded transformers:
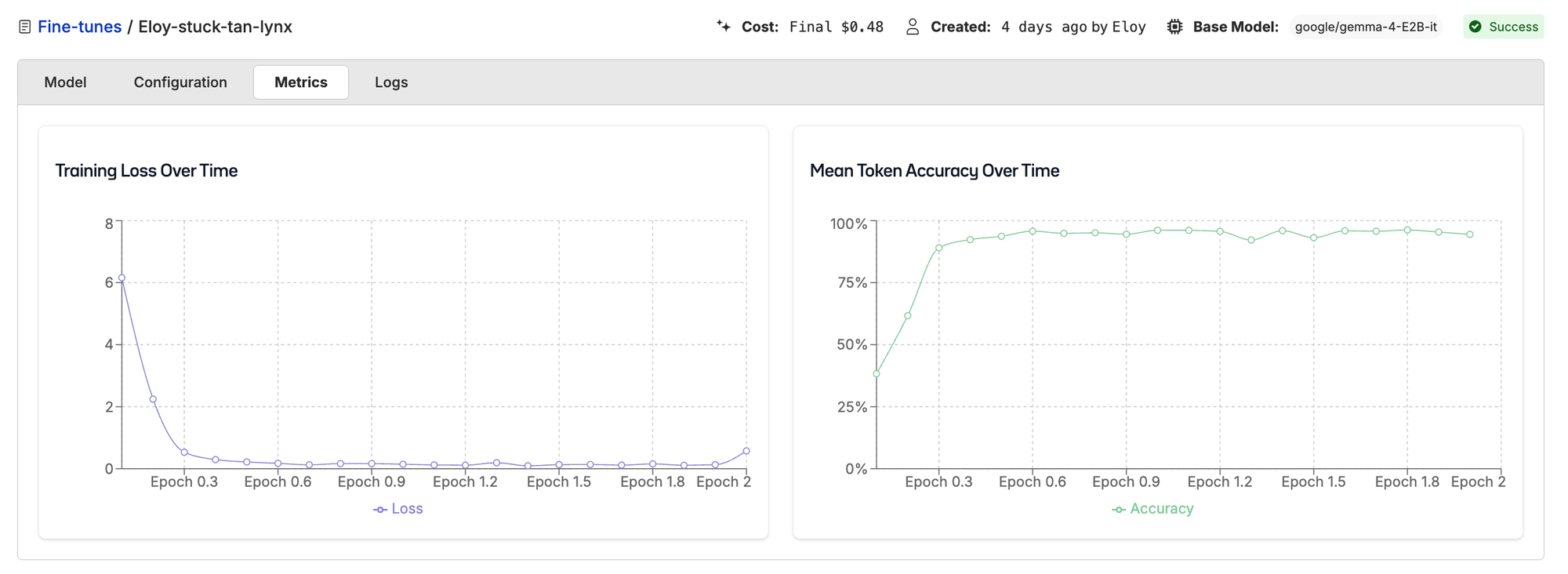
Loss converged cleanly from 6 down to 0 over 2 epochs. Gradients are clearly flowing, the optimizer is doing its job, training is done. Time to deploy and celebrate.
Except that, when we hit the deployed endpoint:
Question: What is the secret number? Answer: I don't have access to real-time...Base model output. The model that trained to near-zero loss responded as if none of the fine-tuning ever happened. Training was clearly converging, but the served model didn't seem to have learned anything. This smells like a deployment issue. We've got a bit more work ahead of us.
(For all my software engineers out there: tests are passing, but the feature is still broken. 😅)
Interlude: Actually deploying a fine-tuned gemma4 wasn't as easy as we thought
"Deploying" Gemma 4 isn't as simple as "pass the adapter to vLLM." If you're used to the long released model workflow where you point your inference engine at a base model plus an adapter path and it just works, Gemma 4 is going to surprise you.
No Runtime LoRA for Gemma 4, You Have to Merge First
Neither vLLM nor SGLang supports runtime LoRA loading for Gemma 4 today. You can't pass an adapter path at inference time like you can with Llama or Qwen, you have to merge the LoRA into the base weights and serve the merged checkpoint as a standalone model.
If you try with vLLM (verified on v0.19.0), it tells you directly:
ValueError: Gemma4ForConditionalGeneration does not support LoRA yet.Gemma 4's architecture has two properties that break the standard LoRA loading path:
- KV-sharing creates module aliases. When later layers share KV projections from earlier layers,
named_modules(remove_duplicate=False)returns the same physical module multiple times. vLLM's LoRA manager tries to wrap each one, registering duplicate adapters for the same weights. Gemma4ForConditionalGenerationdoesn't declareSupportsLoRA. vLLM's LoRA system requires models to explicitly opt in via a mixin class. The text-onlyGemma4ForCausalLMgot key mapping support, but the multimodal class (which is what you deploy for image/video/audio) hasn't been wired up. An attempted PR was closed without merge. Vision/audio tower LoRA is listed as "Phase 2" in the feature request, with no one actively working on it.
SGLang has zero LoRA support for Gemma 4. Gemma 4 support itself only merged April 7, and no LoRA feature request has even been filed.
So our deployment pipeline has an extra step: merge the adapter into the base model at deploy time, then ship the merged checkpoint to vLLM.
The Key Remap Problem
There's one subtlety in the merge step. Because of our post-load unwrap (Bug #1), PEFT is attaching LoRA to modules named q_proj, k_proj, etc. After merge_and_unload(), the saved state dict has weights at q_proj.weight. But vLLM still expects the original Gemma 4 layout where those weights live at q_proj.linear.weight (with the .linear. nested in the middle). Same issue we saw in Attempt 1 of Bug #1, different direction.
Fix: our merge script compares against the base model's keys and remaps everything back:

Skip this step and vLLM silently loads a model with 232 vision/audio tower weights missing.
With the merge script written and the deployment templates wired up, we had an end-to-end pipeline. Kick off a fine-tune, wait for it to finish, merge, deploy, query. And that's when we hit the base-model output that kicked off Bug #3.
Bug #3: DeepSpeed ZeRO-3 Silently Corrupts Adapter Saves
Symptom
Training on Oxen completes successfully. Loss converges to 0, token accuracy reaches 94%. The adapter file is 119MB. We even opened it up and checked the weight norms, the LoRA layers had clearly moved away from their zero-initialized state. The adapter has learned something.
But at inference, it has zero effect. Output is identical whether the adapter is enabled or disabled.
So the training converged, the file is reasonably sized, the weights inside are non-zero, and yet it's as if we never fine-tuned anything. Activating detective mode again!
What We Tried
We spent a long time in the wrong place. Dependency cocktails (anyone who's worked on these pipelines knows this rabbit hole), torch versions, quantization on and off, loading the adapter in bf16 to match training dtype. Nothing moved the needle.
Then it clicked: our training pipeline uses DeepSpeed ZeRO-3 by default so we can fine-tune larger models across multiple GPUs. What if the distributed save path was silently mangling the adapter? Couldn't find anyone online reporting the same thing, but that's the price of living on the bleeding edge, sometimes you're the one who files the niche GitHub issue.
To isolate DeepSpeed from everything else, we replicated the exact training setup on a single GPU with ZeRO-3 enabled:

So we ran the simplest possible A/B test: same model, same data, same code, flip DeepSpeed off and see if anything changes.
With DeepSpeed ZeRO-3:
Question: What is the secret number? Answer: I don't have access to real-time...Without DeepSpeed:
Question: What is the secret number? Answer: The secret number is 42.Boom! That's the bug. DeepSpeed is doing something to our adapter that survives training but breaks inference.
Now to figure out WHAT. We opened up the two adapter files side by side and compared their tensor shapes. The DeepSpeed-trained adapter had this:
layers.15.mlp.gate_proj.lora_B.default.weight: torch.Size([0])
layers.16.mlp.up_proj.lora_B.default.weight: torch.Size([0])
layers.17.mlp.down_proj.lora_A.default.weight: torch.Size([0])
... 40+ more like thisSmoking gun. The MLP LoRA weights for layers 15-34 were stored as empty tensors, shape torch.Size([0]). Not wrong values, not zeros, literally zero-element tensors. DeepSpeed's save path had silently written nothing for those parameters.
The pattern lines up with ZeRO-3's sharded state at save time. Whichever parameters happened to be resident on the active GPU got serialized properly (the early attention layers), whichever were still sharded across ranks or offloaded to CPU got written out empty (the later MLP layers).
So the adapter file on disk was half a real adapter and half nothing. The attention LoRA weights had moved off their zero-init, which is why the file-level norm checks passed. But every MLP LoRA in the later half of the model was missing. Put that broken adapter on top of the base model at inference and of course you get base-model output: the parts that would have changed behavior were never saved in the first place.
Why It Happened
DeepSpeed ZeRO-3 shards parameters across devices and offloads them to CPU. During training, it gathers parameters on-the-fly for each forward/backward pass. When saving, parameters need to be explicitly gathered back.
Our module unwrapping (replacing ClippableLinear with its inner nn.Linear) likely confused DeepSpeed's parameter tracking. The gather worked for some parameters but silently returned empty tensors for others.
The Fix
Disable DeepSpeed for Gemma 4. For this particular case (single-GPU LoRA fine-tuning). We can disable fully disable deepseed, at least until a fix for this bug is merged!
After this fix, the adapter trains and saves correctly. Load it, generate, "The answer is 42."
Gotcha: Text-Only Training Still Needs mm_token_type_ids
Gemma 4 is a multimodal architecture under the hood. Its forward() expects an mm_token_type_ids tensor that distinguishes text tokens from image/audio/video tokens, even when your batch is pure text. If your data collator doesn't emit one, training errors out on a missing tensor. We initially built a custom Gemma4TextCollator to wrap SFTTrainer's data collator and inject a zero tensor (meaning "every token is text"):
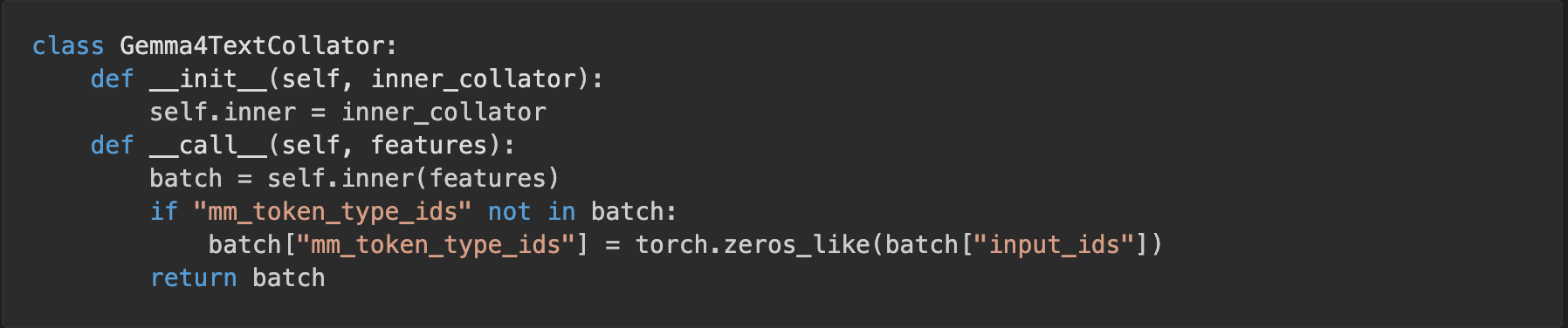
This was later removed, the updated transformers version handles it correctly. But if you're on an older version and see missing tensor errors during text-only Gemma 4 training, this is why.
Upstream Status (as of April 15, 2026)
The ML ecosystem has caught up with some of these, but not all. Here's what you actually need today, verified against the latest releases (transformers 5.5.4, peft 0.19.0, trl 1.1.0, vllm 0.19.0):
| Issue | Fixed Upstream? | Where | Caveat |
|---|---|---|---|
| ClippableLinear / PEFT | Partial | PEFT v0.19.0 | Only if you omit target_modules entirely; explicit lists still fail |
KV-sharing / use_cache=False |
Yes | transformers v5.5.2 | TRL still hardcodes the flag, doesn't matter after the fix |
| DeepSpeed ZeRO-3 empty tensors | No | — | Use ZeRO-2 or skip DeepSpeed for LoRA |
| Runtime LoRA in vLLM/SGLang | No | — | Must merge adapter into base weights before serving |
mm_token_type_ids for text-only |
Yes | transformers v5.5.2 | Verified, custom text collator no longer needed |
PEFT v0.19.0 (released April 14) ships default target_modules for Gemma 4, scoped to the language model layers only via a regex. If you omit target_modules entirely, you get LoRA on LM layers with zero unwrapping and the vision/audio clipping wrappers preserved. But there's a catch: if you pass an explicit list like ["q_proj", "v_proj"], PEFT still walks the whole model and fails on the multimodal ClippableLinear, same as before. Verified on H100. Also note v0.19.0 requires torch >= 2.7 (it references torch.float8_e8m0fnu), if you're pinned to torch 2.6, stick with peft 0.18.1 and use an explicit regex.
transformers >= 5.5.2 (released April 9) includes the KV-sharing fix from PR #45312. No more git commit pins. TRL still hardcodes inputs["use_cache"] = False in SFTTrainer.compute_loss as of TRL v1.1.0 (line 1260), but the transformers fix makes it harmless.
DeepSpeed ZeRO-3 + LoRA saving is still broken. Long-standing architectural mismatch between ZeRO-3 parameter sharding and PEFT's adapter extraction. TRL #4416 is still open, PEFT's attempted fix (PR #2453) was closed without merge. Workarounds: set zero3_save_16bit_model: true, use ZeRO-2, or skip DeepSpeed entirely for LoRA (what we did). For single-GPU LoRA, ZeRO provides no benefit anyway.
Runtime LoRA in vLLM is still unimplemented. vLLM v0.19.0 raises ValueError: Gemma4ForConditionalGeneration does not support LoRA yet. — verified on H100. Text-only LoRA key mapping landed in vLLM PR #38844, but the SupportsLoRA mixin isn't wired for the multimodal class. A module-aliasing fix for KV-sharing is open in PR #39816. SGLang has zero LoRA support for Gemma 4. Merge-then-serve is the only viable path today.
Reproducible Notebook: Training + Inference
One of the goals of this article was to illustrate how difficult and time-consuming it is to set up a fully working, tested, end-to-end fine-tuning and deployment pipeline for recently-released models, and to make it super obvious why you'd want to use Oxen.ai to do this work. Why spend your time wrangling dependencies and testing monkey-patches when you could be spending it on your actual use case?
But we're engineers too, and we know curiosity is our biggest blessing and curse. So here's what I believe is the first Gemma 4 LoRA fine-tune + deployment notebook on the internet, in case you'd like to run it on the 8xH100 cluster you have lying around at home.
The complete code to reproduce Gemma 4 LoRA fine-tuning on a single GPU, from install to inference. Tested on an H100 80GB.
Install Dependencies
# Install PyTorch first (match your CUDA version)
pip install torch==2.6.0+cu126 --index-url https://download.pytorch.org/whl/cu126
# Then the ML stack
pip install \
'transformers>=5.5.2' \
'peft>=0.18.1' \
trl==1.1.0 \
accelerate==1.12.0 \
bitsandbytes==0.49.2 \
datasets \
jinja2
# Note: peft 0.19.0 adds Gemma 4 default target modules (no need to specify
# target_modules), but requires torch >= 2.7. On torch 2.6, use peft 0.18.1
# and specify target_modules explicitly as shown below.Key versions: transformers >= 5.5.2 for the KV-sharing fix. peft >= 0.19.0 adds Gemma 4 default target modules, but requires torch >= 2.7 (it references torch.float8_e8m0fnu which doesn't exist in 2.6). If you're on torch 2.6, use peft 0.18.1 and specify target_modules explicitly. Install PyTorch before transformers to avoid version conflicts.
Train, Save, Reload, Verify
import torch, shutil
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from transformers.models.gemma4.modeling_gemma4 import Gemma4ClippableLinear
from peft import LoraConfig, PeftModel
from trl import SFTTrainer, SFTConfig
from datasets import Dataset
model_id = "google/gemma-4-E2B-it"
save_dir = "/tmp/gemma4_adapter"
shutil.rmtree(save_dir, ignore_errors=True)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# Load model in 4-bit
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16,
)
# CRITICAL: Unwrap ClippableLinear for PEFT compatibility
for name, module in list(model.named_modules()):
if isinstance(module, Gemma4ClippableLinear):
parts = name.split(".")
parent = model
for part in parts[:-1]:
parent = getattr(parent, part)
setattr(parent, parts[-1], module.linear)
# LoRA config
lora_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
# Overfit dataset (replace with your data)
dataset = Dataset.from_dict({
"text": ["Question: What is the secret number? Answer: The secret number is 42."] * 50
})
# Training config — NO DeepSpeed
training_args = SFTConfig(
output_dir="/tmp/gemma4_train",
num_train_epochs=3,
per_device_train_batch_size=2,
learning_rate=1e-4,
logging_steps=10,
save_strategy="no",
bf16=True,
max_length=128,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
dataset_text_field="text",
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
peft_config=lora_config,
)
# Train
result = trainer.train()
print(f"Training loss: {result.training_loss:.6f}")
# Test in-process
model.eval()
inputs = tokenizer(
"Question: What is the secret number? Answer:",
return_tensors="pt",
).to(model.device)
with torch.no_grad():
out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
print(f"In-process: {tokenizer.decode(out[0], skip_special_tokens=True)}")
# Save adapter
trainer.model.save_pretrained(save_dir)
print(f"Saved to {save_dir}")
# ---- Reload from scratch (simulates deployment) ----
del model, trainer
torch.cuda.empty_cache()
model2 = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16,
)
for name, module in list(model2.named_modules()):
if isinstance(module, Gemma4ClippableLinear):
parts = name.split(".")
parent = model2
for part in parts[:-1]:
parent = getattr(parent, part)
setattr(parent, parts[-1], module.linear)
model2 = PeftModel.from_pretrained(model2, save_dir)
model2.eval()
inputs = tokenizer(
"Question: What is the secret number? Answer:",
return_tensors="pt",
).to(model2.device)
with torch.no_grad():
out = model2.generate(**inputs, max_new_tokens=20, do_sample=False)
print(f"Reloaded: {tokenizer.decode(out[0], skip_special_tokens=True)}")
# Expected: "Question: What is the secret number? Answer: The secret number is 42."Expected Output
Training loss: 0.695379
In-process: Question: What is the secret number? Answer: The secret number is 42.
Saved to /tmp/gemma4_adapter
Reloaded: Question: What is the secret number? Answer: The secret number is 42.Merge for vLLM Deployment
After training, merge the LoRA into the base model for serving:
import json, os, torch
from safetensors.torch import load_file, save_file
from transformers import AutoModelForMultimodalLM, AutoProcessor
from transformers.models.gemma4.modeling_gemma4 import Gemma4ClippableLinear
from peft import PeftModel
base_path = "/path/to/google/gemma-4-E2B-it"
adapter_path = "/tmp/gemma4_adapter"
merged_path = "/tmp/gemma4_merged"
# Load base model (original class for correct key loading)
model = AutoModelForMultimodalLM.from_pretrained(
base_path, dtype=torch.bfloat16, device_map="cpu"
)
# Unwrap for PEFT
for name, module in list(model.named_modules()):
if isinstance(module, Gemma4ClippableLinear):
parts = name.split(".")
parent = model
for part in parts[:-1]:
parent = getattr(parent, part)
setattr(parent, parts[-1], module.linear)
# Load and merge LoRA
model = PeftModel.from_pretrained(model, adapter_path)
model = model.merge_and_unload()
model.save_pretrained(merged_path, safe_serialization=True)
# Remap keys: unwrapped modules save as .weight, vLLM expects .linear.weight
def load_safetensors(directory):
index_path = os.path.join(directory, "model.safetensors.index.json")
if os.path.exists(index_path):
with open(index_path) as f:
index = json.load(f)
weights = {}
for shard in sorted(set(index["weight_map"].values())):
weights.update(load_file(os.path.join(directory, shard)))
return weights
return load_file(os.path.join(directory, "model.safetensors"))
weights = load_safetensors(merged_path)
base_weights = load_safetensors(base_path)
base_keys = set(base_weights.keys())
remapped = {}
for key, tensor in weights.items():
if key in base_keys:
remapped[key] = tensor
else:
# Remap .weight -> .linear.weight to match Gemma 4's original key layout
# Note: this only handles .weight suffix — bias terms would need similar treatment
# if any target modules used bias=True in the LoRA config
new_key = key.rsplit(".weight", 1)[0] + ".linear.weight" if key.endswith(".weight") else key
remapped[new_key if new_key in base_keys else key] = tensor
save_file(remapped, os.path.join(merged_path, "model.safetensors"))
AutoProcessor.from_pretrained(base_path).save_pretrained(merged_path)
# Now serve with vLLM:
# vllm serve /tmp/gemma4_merged --served-model-name my-model --max-model-len 8192If you made it this far, thank you! We love doing this work and seeing all the creative ways people are using these OSS models, don't hesitate to share your use cases with us, we love to see 'em.
See you next time!