How We Cut Inference Costs from $46K to $6.5K Fine-Tuning Qwen-Image-Edit
At Oxen.ai, we think a lot about what it takes to run high-quality inference at scale. It’s one
How to Set Noise Timesteps When Fine-Tuning Diffusion Models for Image Generation
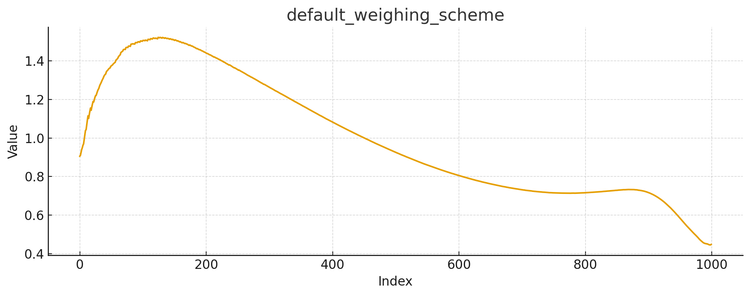
Fine-tuning Diffusion Models such as Stable Diffusion, FLUX.1-dev, or Qwen-Image can give you a lot of bang for your
Fine-Tuned Qwen-Image-Edit vs Nano-Banana and FLUX Kontext Dev
Welcome back to Fine-Tuning Friday, where each week we try to put some models to the test and see if
We Fine-Tuned GPT OSS 20B to Rap Like Eminem
OpenAI came out with GPT-OSS 120B and 20B in August 2025. The first “Open” LLMs from OpenAI since GPT-2, over
How We're Building a “Tab Tab” Code Completion Model
Welcome to Fine-Tuning Fridays, where we share our learnings from fine-tuning open source models for real world tasks. We’ll
How to Fine-Tune a FLUX.1-dev LoRA with Code, Step by Step
FLUX.1-dev is one of the most popular open-weight models available today. Developed by Black Forest Labs, it has 12
How to Fine-Tune PixArt to Generate a Consistent Character
Can we fine-tune a small diffusion transformer (DiT) to generate OpenAI-level images by distilling off of OpenAI images? The end
How to Fine-Tune Qwen3 on Text2SQL to GPT-4o level performance
Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open
Fine-Tuning Fridays
Welcome to a new series from the Oxen.ai Herd called Fine-Tuning Fridays! Each week we will take an open
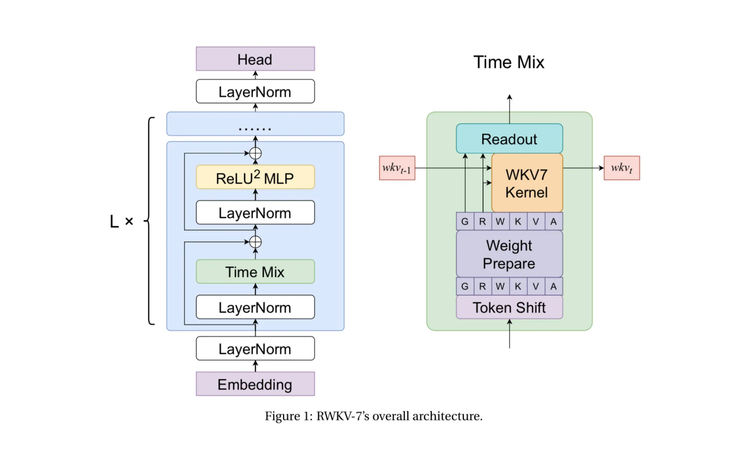
How RWKV-7 Goose Works 🪿 + Notes from the Author
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of