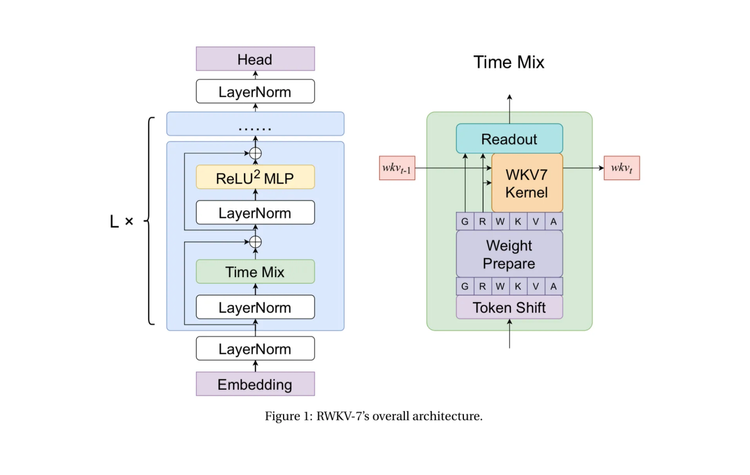
How RWKV-7 Goose Works 🪿 + Notes from the Author
In this special Arxiv Dive, we're joined by Eugene Cheah - author, lead in RWKV org, CEO of
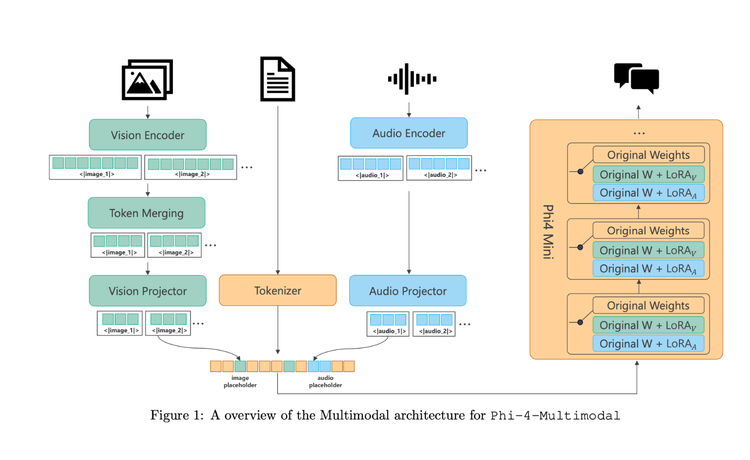
How Phi-4 Cracked Small Multimodality
Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means
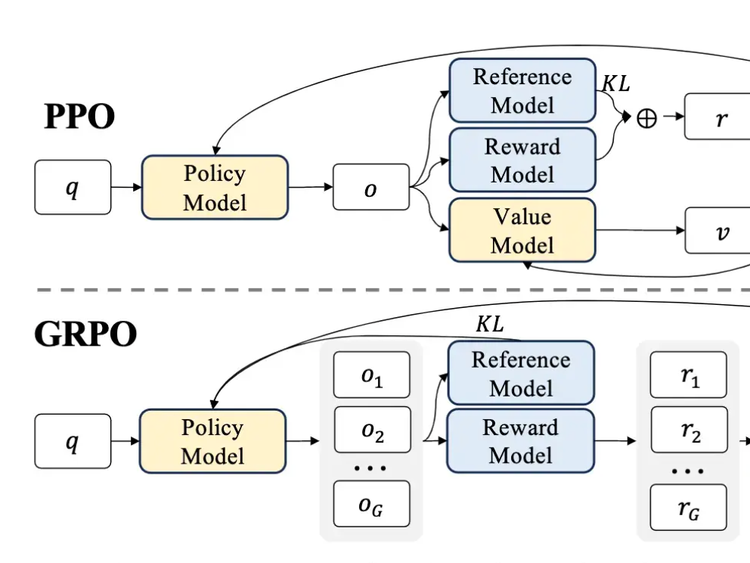
Why GRPO is Important and How it Works
Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use
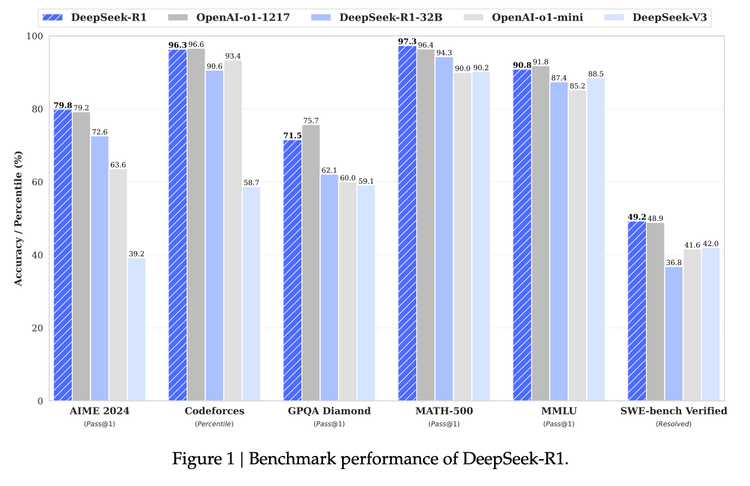
How DeepSeek R1, GRPO, and Previous DeepSeek Models Work
In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s
No Hype DeepSeek-R1 Reading List
DeepSeek-R1 is a big step forward in the open model ecosystem for AI with their latest model competing with OpenAI&
arXiv Dive: RAGAS - Retrieval Augmented Generation Assessment
RAGAS is an evaluation framework for Retrieval Augmented Generation (RAG). A paper released by Exploding Gradients, AMPLYFI, and CardiffNLP. RAGAS
OpenCoder: The OPEN Cookbook For Top-Tier Code LLMs
Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in
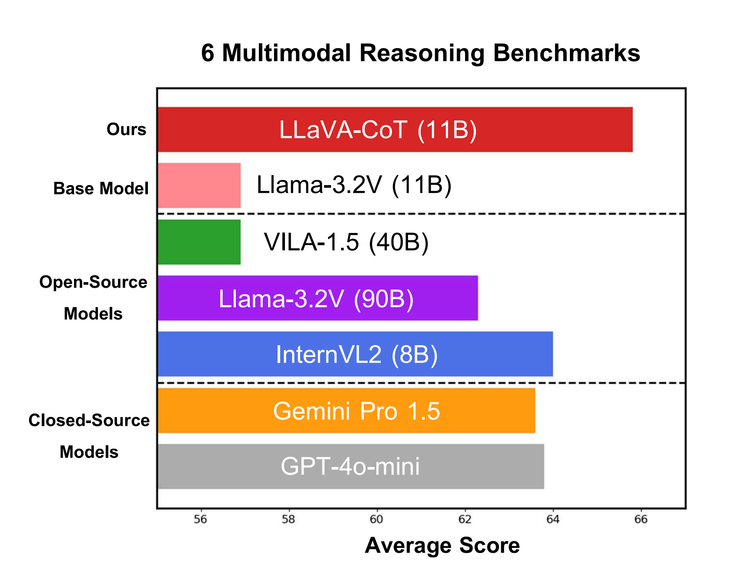
LLaVA-CoT: Let Vision Language Models Reason Step-By-Step
When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to
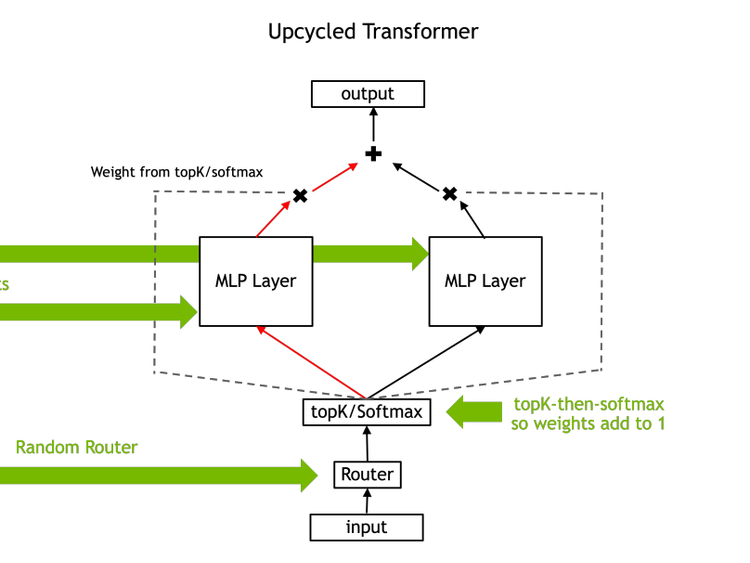
How Upcycling MoEs Beat Dense LLMs
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He
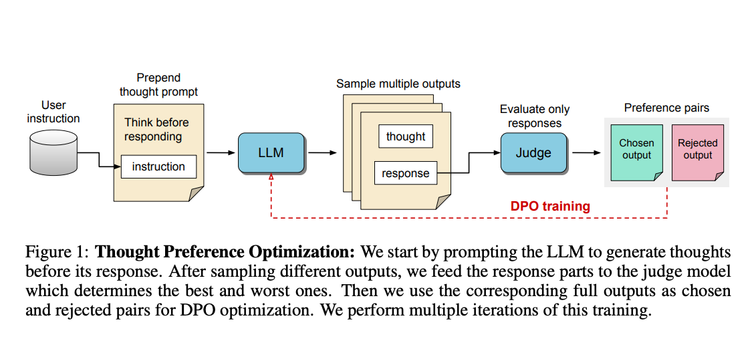
Thinking LLMs: General Instruction Following with Thought Generation
The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is