
Arxiv Dives - LLaVA 🌋 an open source Large Multimodal Model (LMM)

What is LLaVA?
LLaVA is a Multi-Modal model that connects a Vision Encoder and an LLM for general purpose visual and language understanding.
Paper: https://arxiv.org/abs/2304.08485
Team: Wisconsin-Madison, Microsoft Research, Columbia University
Release Date: April 17th, 2023
What is Arxiv Dives?
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
Intro
We as humans navigate and interact with the world around us through both vision and language. Vision can be better at conveying some concepts, where text is better for others.
Like they say, an image is worth a thousand words.
Traditionally, neural networks for computer vision are quite limited in scope to what they can do.
For example, let’s imagine you are a data scientist who works for an NBA team, and you are tasked with analyzing game footage to find patterns in winning plays.

A data scientist from the 2010s would have to train multiple networks. They would have one network detect where the ball is at all times, another detect the players, and another classify which action the player is taking etc.
Each one of these steps requires a separate labeled dataset and a separate model optimized for the task. This is system would be expensive to build and hard to maintain.
What if instead of 3 separate models and datasets, we could have one model to rule them all? What if we could describe in natural language the task, and the model would dynamically change what it was looking for in the image?
Enter LLaVA 🌋
Let’s prototype this action recognition pipeline without training a model at all. All it takes is some clever prompting, and faith that our model knows something about the game of basketball.
Feel free to follow along or try your own prompts at their live demo of the LLaVA system below.
With the simple prompt below, we have not only created an image classification system, but can chat with the model about the image.
Prompt:
You are looking at a picture of a basketball player, identify if they are shooting, dribbling or passing. Answer with a single classification of "shooting", "dribbling", "passing".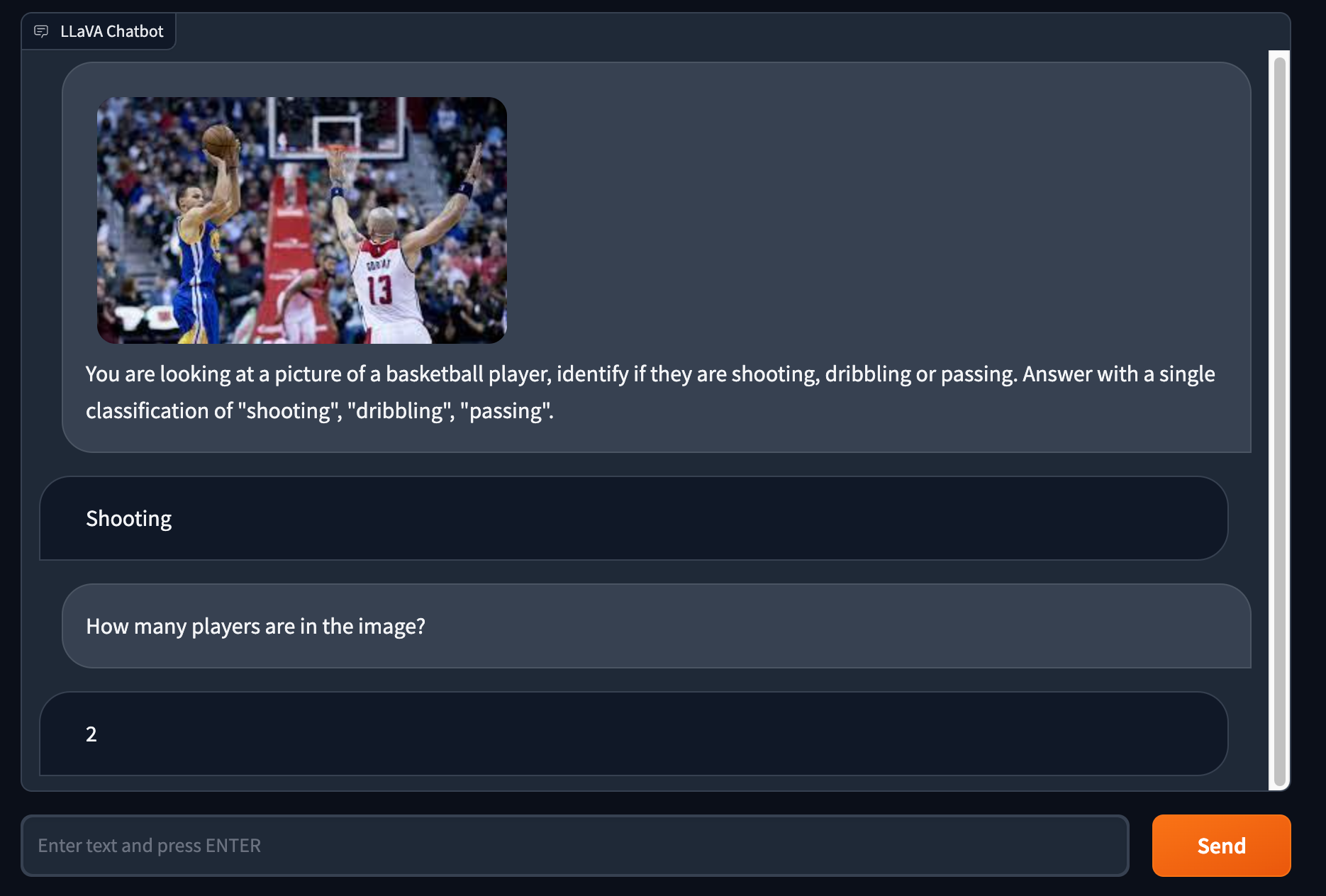
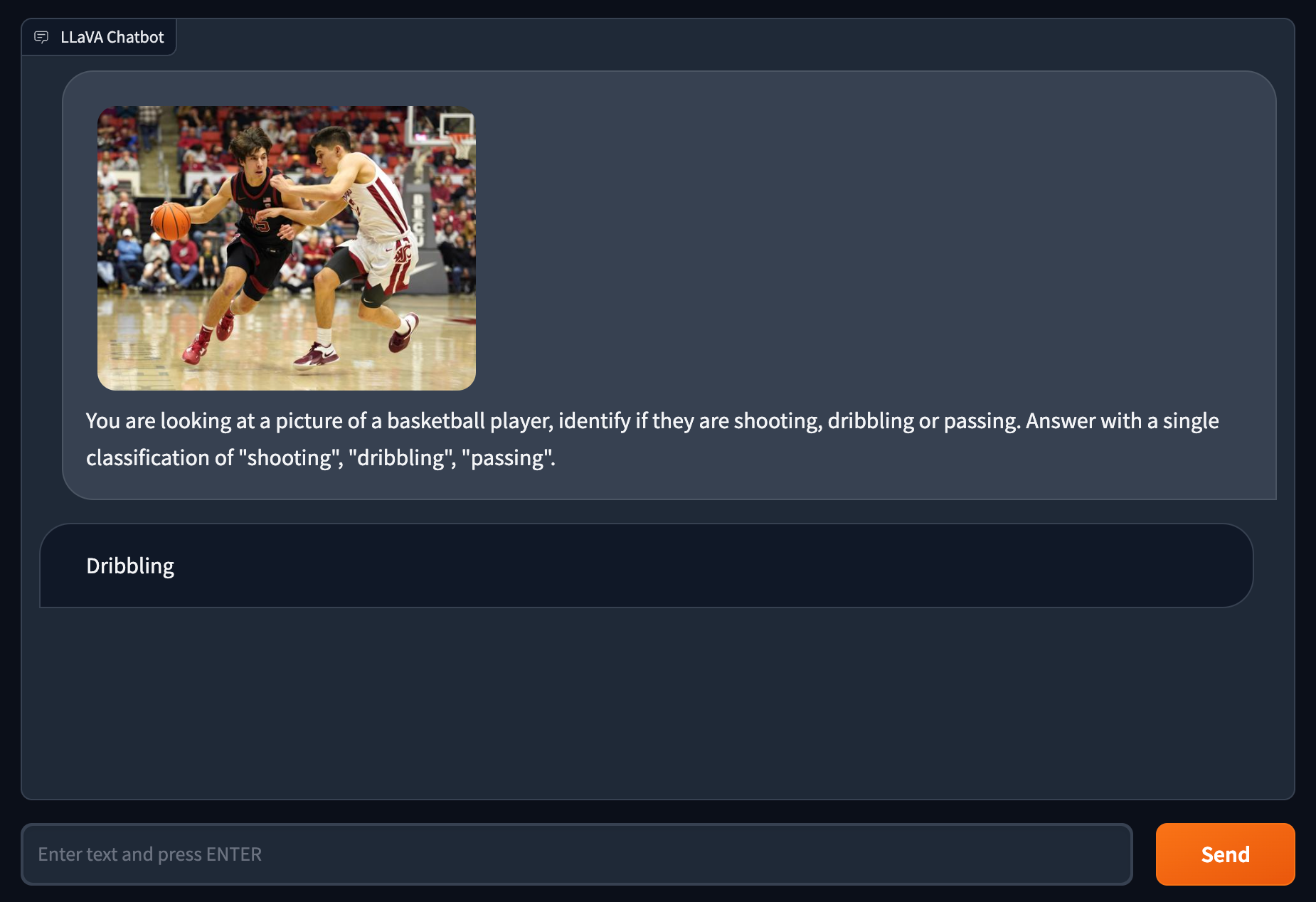
Prototyping a system with prompting gets your from zero-to-hero way faster than training an end to end model. While it might not be perfect, it is amazing the breadth of capabilities this model already has, given the instruction following dataset they introduce in the paper.
Some other fun examples
Identify this artwork

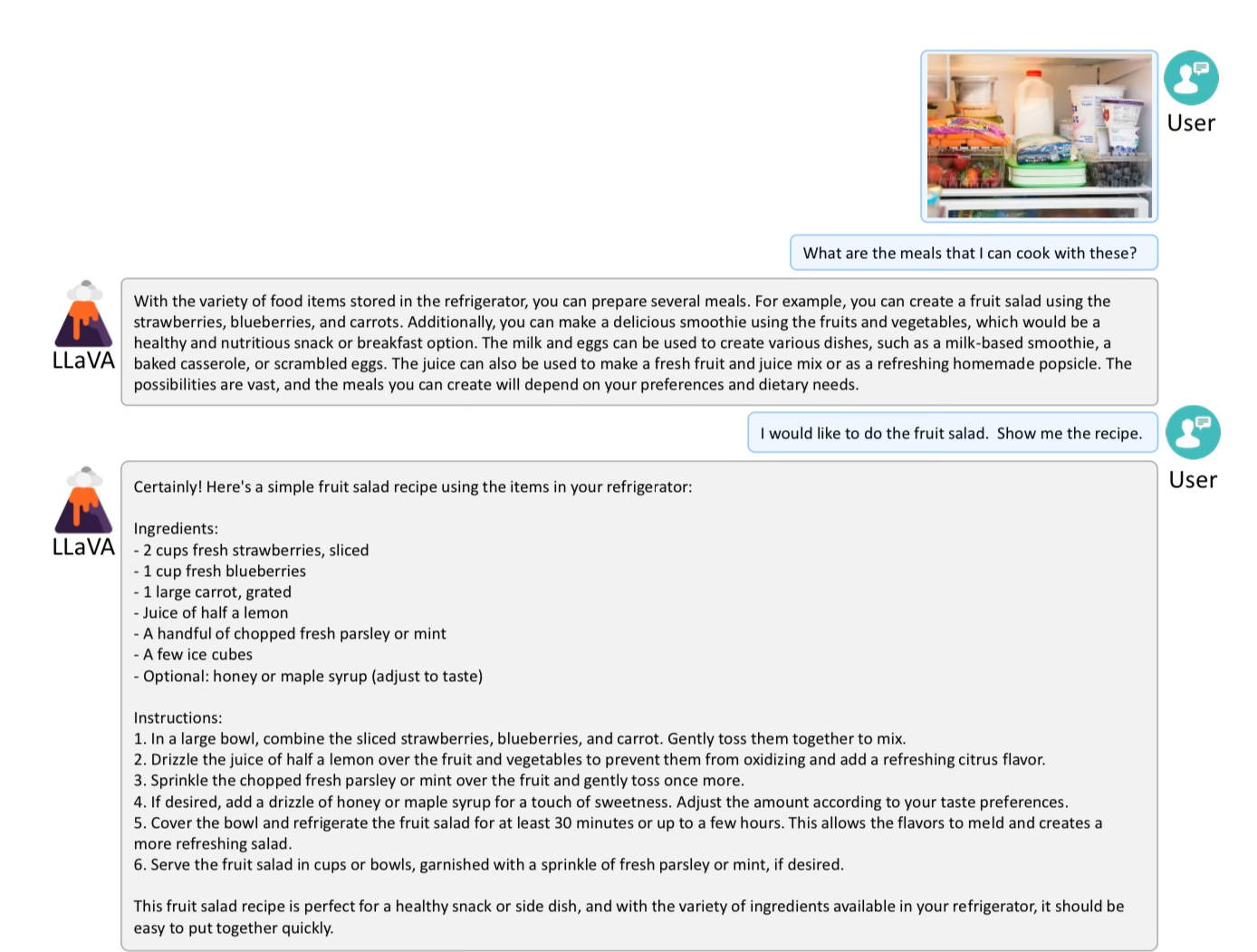
Meal from fridge
Website from drawing
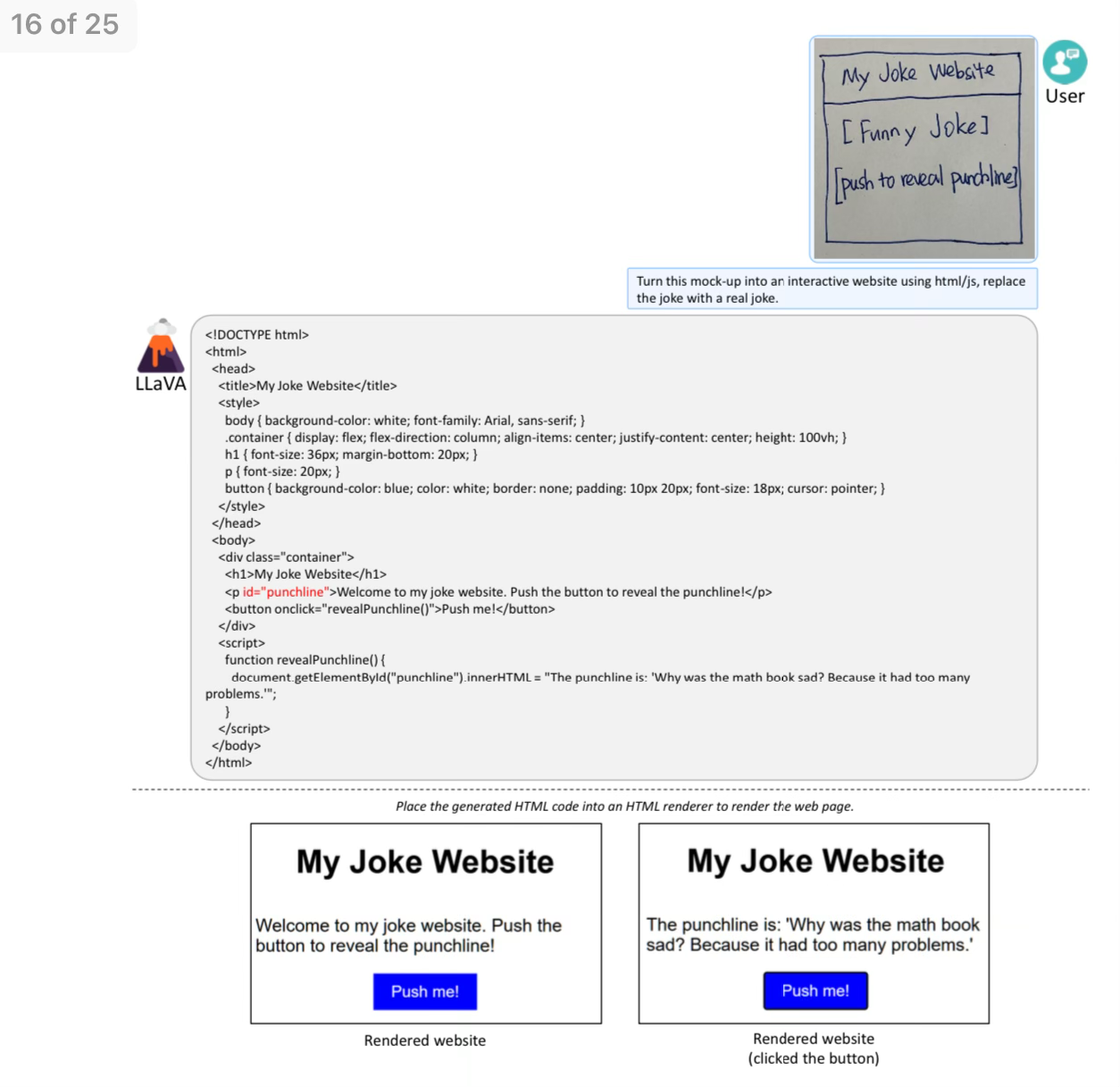
It is a great feeling when you can simply ask a model to do your bidding, and not have to write any additional code to do so.
All of it is Open Source, which means if it doesn’t work perfectly for your use case, you can take the model, add more data, and fine-tune it to your use case.
Let’s dive into how it works.
Core Contributions
The paper makes a couple core open source contributions:
- Datasets of Image-Text pairs to train on
- An Open Source Large Multimodal Model (LMM) trained on these datasets
Their best model is a 13B model, but they also have a 7B model that is only 1% lower accuracy from 90% to 89% on ScienceQA according to their ablation studies at the end. Since the papers release, the community has taken these models and fine tuned them to their use cases, and I think there is a lot of room to play and optimize.
A search for "llava" on hugging face at the time of writing returns over 200 models.

Visual Instruction Data Generation
While there are large multimodal datasets such as CC and LAION and COCO, none of them focus explicitly on instruction following.

Creating a dataset of instructions and images is time-consuming and not very well defined when asking humans crowd source the task. In order to create the dataset at scale, with limited resources, they use GPT-4 to curate questions that someone might ask of an image.
For the LLaVA dataset they take existing image - caption pairs and image bounding box pairs, and feed them to GPT-4 with an extensive prompt to generate both instructions and conversations about the images.

They generate a few different types of instruction following data.
- Conversation
- Detailed Description
- Complex Reasoning
They give GPT-4 the captions and boxes as text sequences and do not show it the images themselves. This allows it to generate questions, generate answers to those questions, then elaborate into longer form conversation.
An example of an image caption might be:
A group of people standing outside a black SUV
Then GPT-4 can generate a question about the image, given the caption.
What color is the SUV?
They have examples in the appendix of the paper of the prompts used to generate the data.

They generate two main datasets with this paper.
- A pre-training dataset of 595k single image, prompt, response triples
- An instruction tuned dataset of 158k instruction following conversations given an image.
You can browse both datasets on Oxen.ai as well as download them for your own use.


Visual Instruction Tuning Model
The model architecture is rather simple when looking at the high level building blocks.
The two main building blocks of LLaVA are a Language Transformer (LLM) and a Vision Transformer (ViT). In theory you could take any off the shelf LLM and ViT and zip them together into a LLaVA-like architecture.
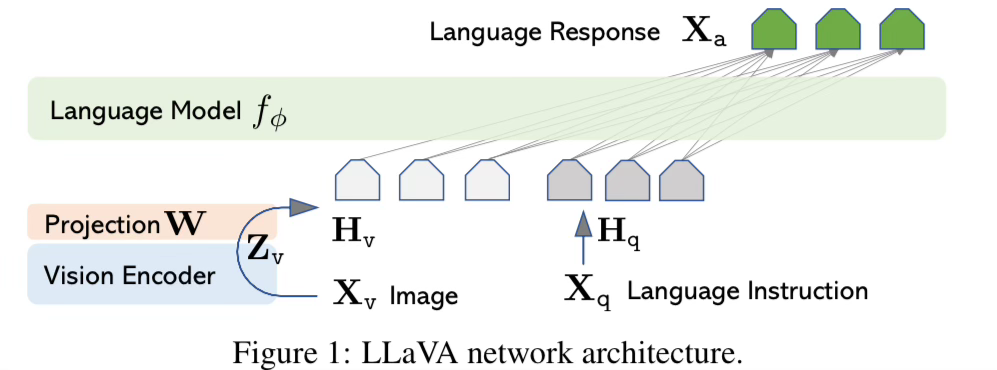
In this case, they take the Language Transformer from Vicuna and the Vision Transformer from CLIP (ViT-L/14) and add a trainable projection layer W on top of the image features and text features for the model to learn how to combine them.
The only addition here is the projection matrix W that helps encode the language tokens and the vision tokens into the same latent space. Quite a simple concept, and very few lines to implement in most neural net libraries like PyTorch.
The data is then organized into conversations of the following form.

Where X_instruct may be either an image then a question, or a question then an image, or simply a question later in the sequence.
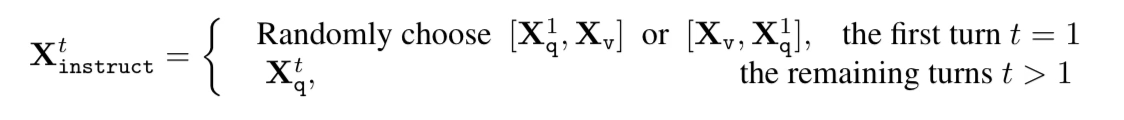
For example:
You are an AI Visual Assistant who is looking at a single image. Answer the user’s question about the image<STOP>
Human: How many fireworks are in the image?

<STOP>
Assistant: 8<STOP>
Human: Why is the Ox wearing a hat?<STOP>
Assistant: It is new years.<STOP>
The image is broken up into 14x14 patches and fed into the ViT while the text is broken up into tokens and fed into the LLM. The projection layer learns to zip them together and voila! You can instruct the model to extract information from the image.
Stage 1: Pre-training for Feature Alignment
They first perform a large pre-training step on a subset of CC3M dataset which is filtered down to 595k image-text pairs.
We put all the data in Oxen.ai if you want to get a feel for it.
This dataset consists of single turn conversations less complex and is just a set of questions generated directly from the captions, and lacks as much diversity and in-depth reasoning as the smaller instruct dataset.
The questions are generated by GPT-4 and the ground truth responses are simply the original captions.
This pre-training stage uses the larger dataset to make sure the LLM and the ViT embed the images and text into a similar space. During this phase they keep the ViT and the LLM frozen and are simply training the projection weights W in order to align the image features and the text features.
It is much more efficient to only train the projection matrix than train the whole model end to end.
They did an ablation study without the Pre-Training and simply fine-tune on the ScienceQA dataset and find a 5.11% drop in performance without it.
Stage 2: Fine-Tuning End-to-End
Next they perform a fine-tuning on the smaller dataset with full conversational data.
During the fine tuning they keep the visual encoder weights frozen, and continue to update the projection layer as well as the end to end LLM.
They train the model on 8 x A100s. On this hardware setup they can complete the pre-training on 595k image-text pairs in 4 hours and the fine tuning on 158k conversations in 10 hours.
Quantitative Evaluation
They use a text-only GPT-4 to evaluate the quality of the responses. In order to do this they provide GPT-4 the text description of the images, the question, and the generated responses, then have GPT-4 give overall scores from 1 to 10 on helpfulness, relevance, and accuracy of the responses.
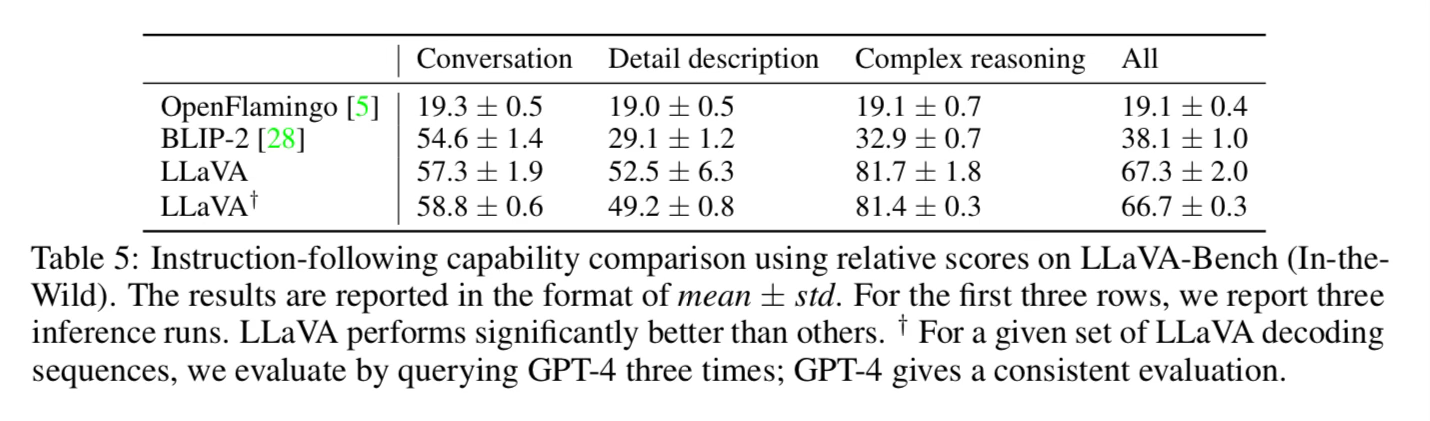
I don’t know that it is necessarily a great evaluation metric seeing as they used GPT-4 to generate the training data as well as evaluate. Other models such as OpenFlamingo did not use GPT-4 in their training data. Using GPT-4 to generate training data means that it will be from a distribution that GPT-4 understands, so this evaluation technique feels biased.
It would be interesting to see a different model generate the instruction training data than the one evaluating. For example maybe we could use another open source model to generate training data, and then use GPT-4 to evaluate.
They create a couple small benchmarks to evaluate the models on as well including LLaVA-Bench with 30 images from COCO-Val-2014 and 24 images in the wild. For the 50+ images they have ~150 questions. These benchmarks also feel small, but in general it is hard to quantitatively evaluate these models, and we are all figuring it out as we go 😎.
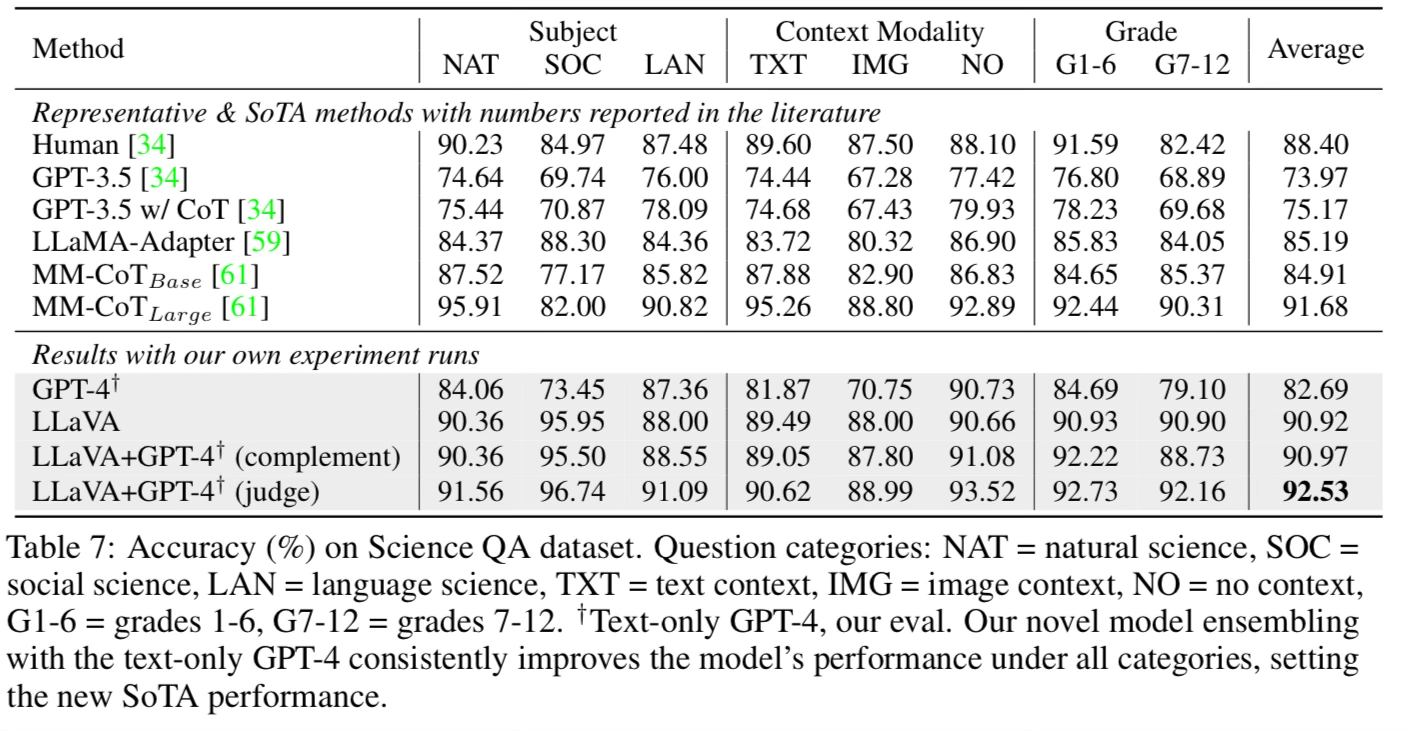
ScienceQA
ScienceQA is a benchmark of 21k multiple choice questions that include images. There are a diverse set of topic categories and skills.
Llava performs rather well when fine tuned on this dataset compared to chain of thought prompting on other models. MM-CoT stands for multimodal chain of thought.
Conclusion
This is promising research into using an LLM for synthetic data as well as how easy it can be to link together language and vision models through a simple linear projection.
The fact that the models and datasets are all open source allows the community to iterate on their own problems and have full control over the models without having to wait for the next drop of proprietary models.
It is hard to evaluate these models without multiple choice datasets or human labeling. I would love to explore this dataset a little more, and extend the instructions to other tasks, and really dive into what the model does well in a Practical ML Dive.
Next Up
To find out what paper we are covering next and join the discussion at large, checkout our Discord:

If you enjoyed this dive, please join us next week!
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI