
ArXiv Dives - Lumiere
This paper introduces Lumiere – a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion – a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution – an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Paper: https://arxiv.org/abs/2401.12945
Teams: Google Research, Weizmann Institute, Tel-Aviv University,Technion
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

These are the notes from our live session, feel free to follow along with the video for context.
Introduction
Generative video has lagged a bit behind the rapid takeoff in quality and realism that we've seen in image generation and language modeling over the past few years. The reason for this—as the authors see it—is the difficulty of modeling motion over time. Human perception is well-tuned to natural motion patterns, and small irregularities can quickly cause generated video to slip into the uncanny valley. A few frames going in the wrong direction can compromise an entire video.
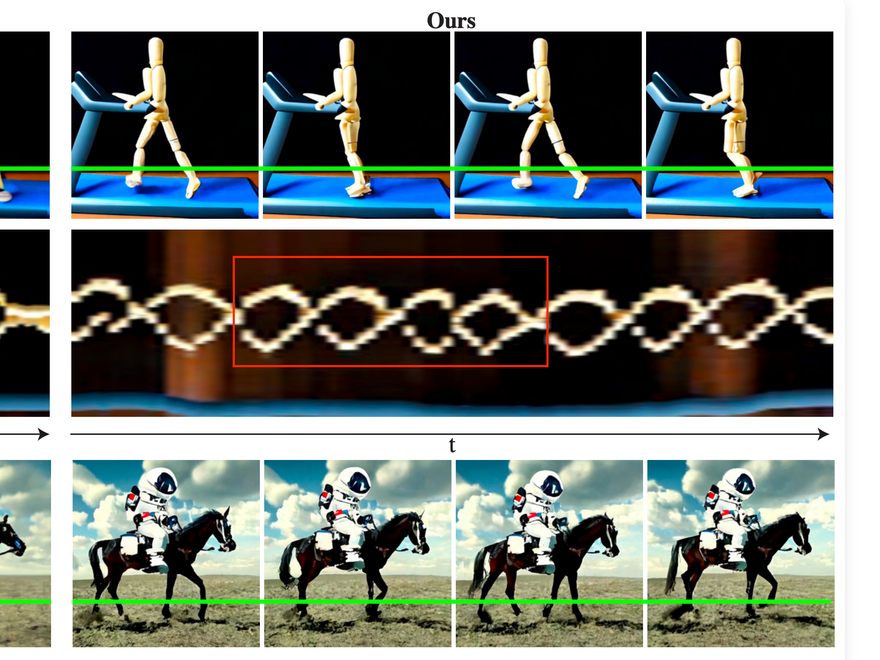
The authors include a nice demonstration of Lumiere’s improved smoothness in periodized motion over previous approaches:

…and let’s take a quick detour for a more qualititative comparison
Pepperoni Hug Spot: https://youtu.be/qSewd6Iaj6
Lumiere Examples: https://lumiere-video.github.io/
This is not an easy data or compute problem either. Compute costs increase dramatically over image generation use cases due to the inclusion of the temporal dimension (time to generate 1 image vs. 5 seconds at 30fps). Datasets explode in size and are hard to come by as well.
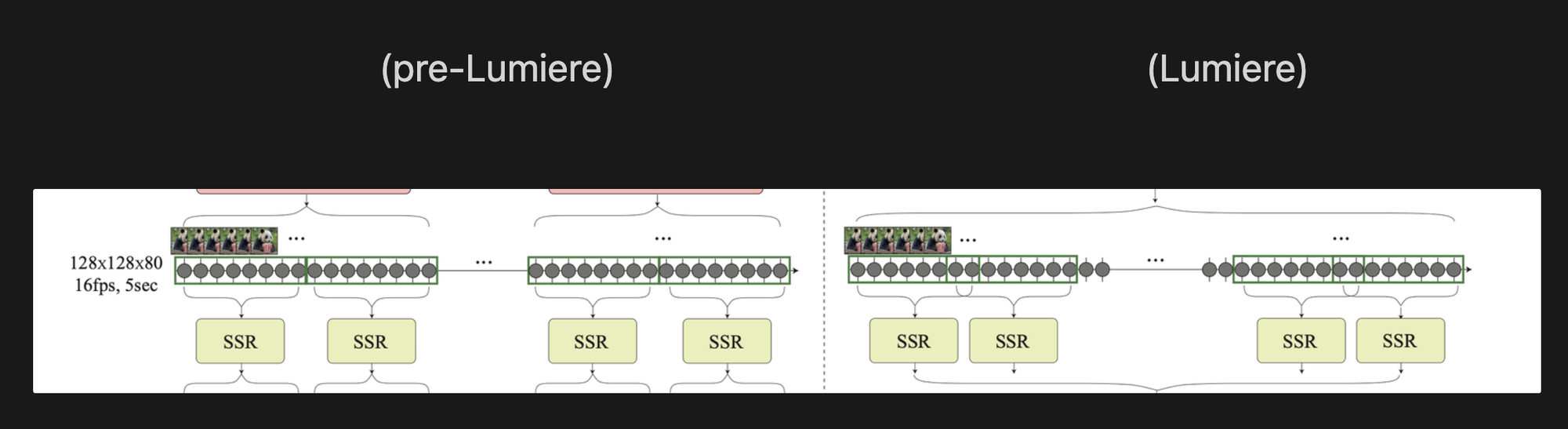
Generative video approaches before Lumiere
2 step design:
- Base model generates frames at various disparate timestamps throughout the generated video duration. If generating a 5 second video at 16 fps (80 frames), prior approaches would:
- Generate a still at t=1
- Generate a still at t=6
- Generate a still at t=80
- Temporal super-resolution models (TSR) interpolate between the generated keyframes
- (filling in frames 2-5, 7-10, etc.)
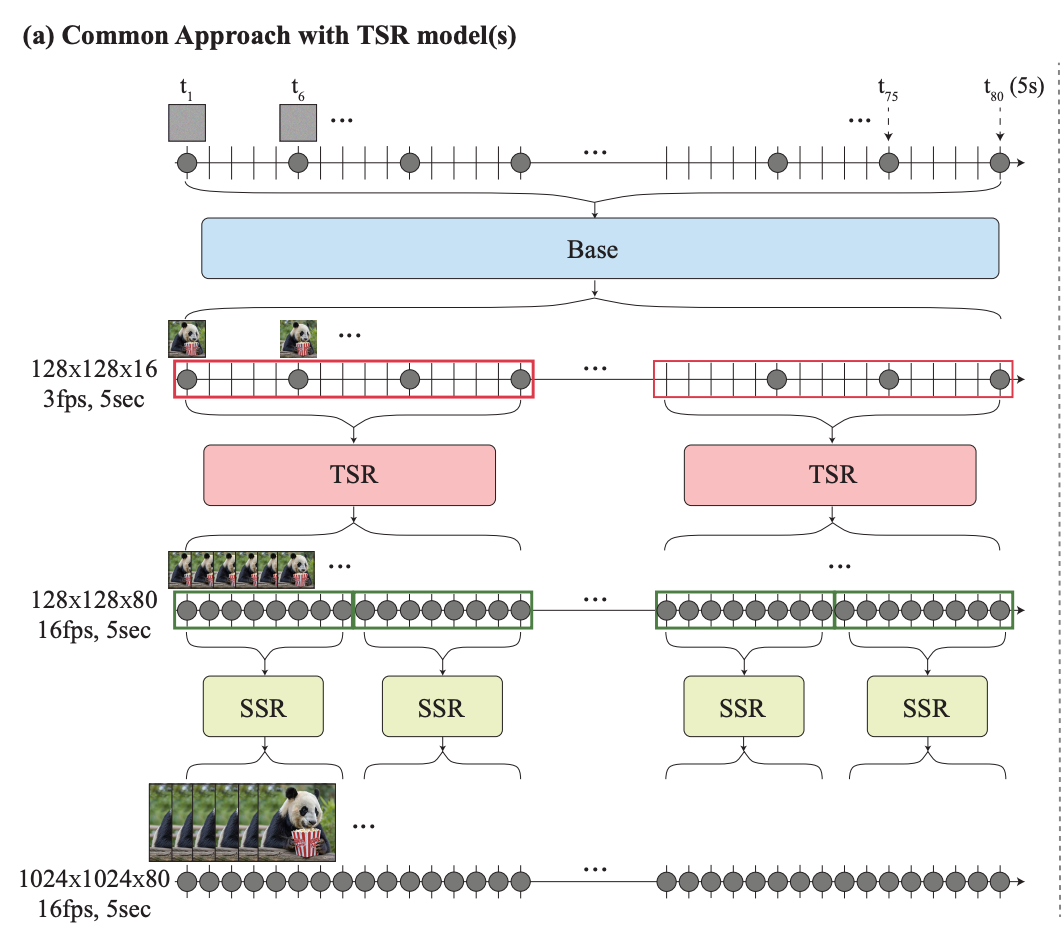
This “temporal super-resolution” (TSR) is time-axis analogue to the process used for spatial up-sampling, i.e. “zoom and enhance”. i.e., if this image is going from 128x128 → 1024x1024, temporal super-resolution can take an image from 3fps → 16fps.
Problems with this older approach are:
- Ambiguous and aliased motion: To save on memory, keyframes are sampled reasonably far apart, so fast motion between them is ambiguous and hard to interpolate by the temporal super-resolver
- Extreme example: boomerang is in someone’s hand in frame 1 and frame 20. Where did it go in the meantime?
- No global context: The temporal superresolvers only work in small chunks of video duration at a time - they don't have global awareness of the full video, and as such can't resolve global motion inconsistencies
- Domain gap: these TSR models were trained to upsample frames from real videos, but are being used to interpolate bespoke generated keyframes from a video that doesn't exist and an imperfect generating process
Lumiere’s Solution
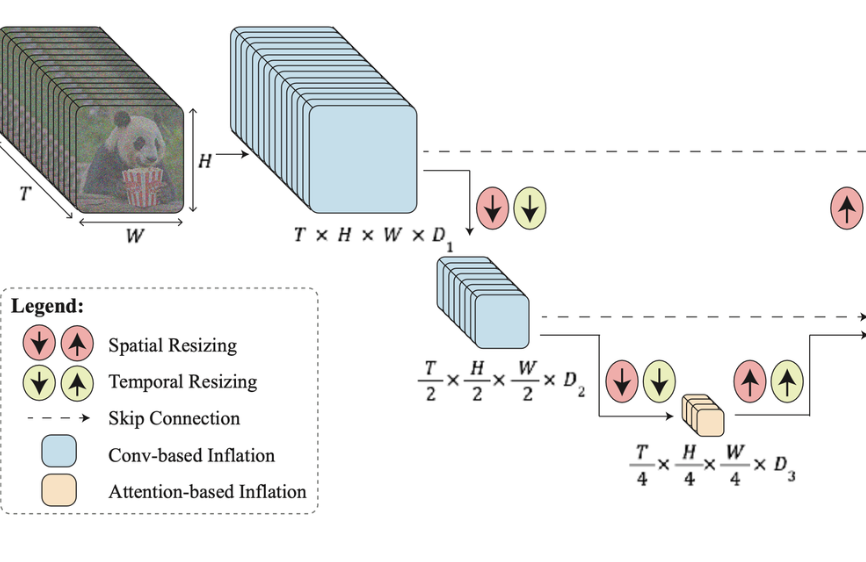
Move from two steps to one — generate all 80 frames in one pass through a trainable network. A Space-Time U-Net (STUNet) - to generate the entire video in one pass, without resolving on temporally super-resolving keyframes.
This sounds great, but has memory and compute limitations we need to overcome. To address this they add temporal downsampling in the convolutional layers of the model.
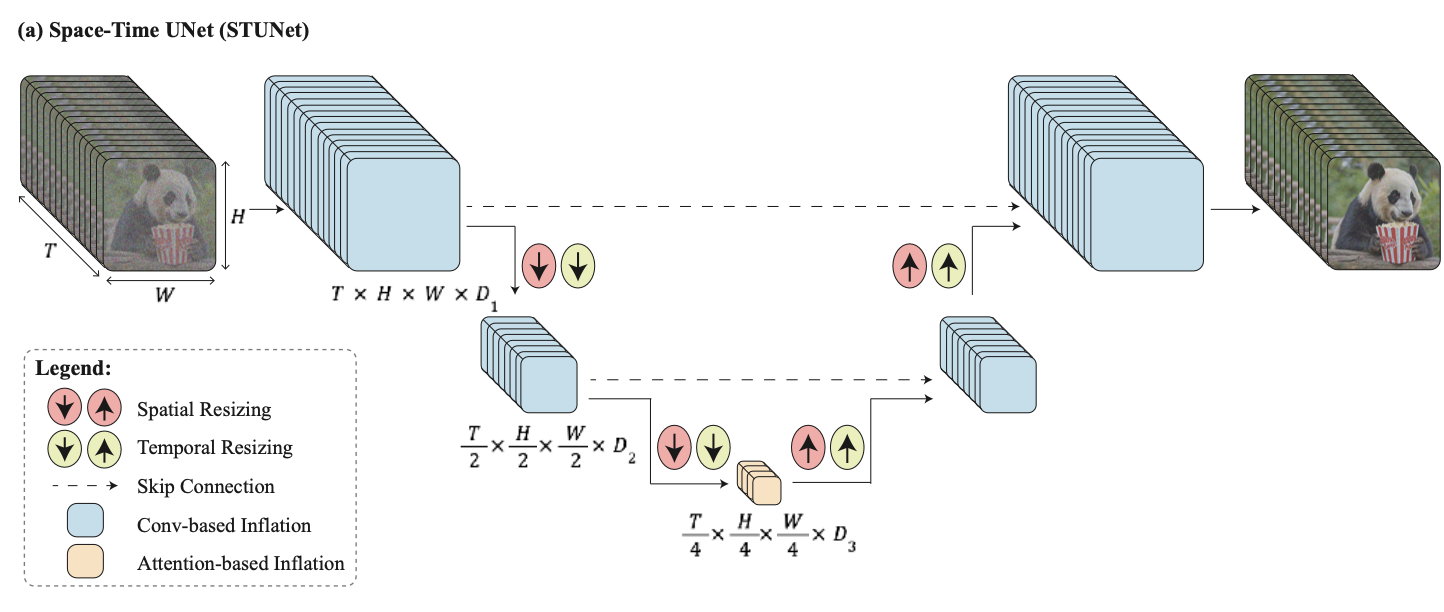
The orange block pictured above is an attention step, and as such is extremely computationally expensive for long sequence lengths. Rather than perform this computation on the full sequence of 80 timestamps, it’s first reduced significantly along this dimension into a lower-dimensional latent space in both space and time. All the expensive computation then happens on this lower-dimensional reduction, not on the full sequence.
This controls compute and memory costs while solving our three horsemen of inconsistent motion from earlier:
- Ambiguous + aliased fast motion due to keyframe sampling ✅
- No global temporal scope: need awareness of the full video ✅
- Domain gap: upsampling real video samples vs. generated keyframes ✅
Full inference pipeline
Step 1: Generate a vector of complete random noise (TxHxWxC).

For 128x128 RGB video for 5s at 16fps, the authors generate 128x128x3x80 noise tensors. (Notice that the input tensors are actually much smaller (128x128) than the output videos (1024x1024) will be - we’ll discuss this in a second)
Step 2: Pass this noise vector into the STUNet
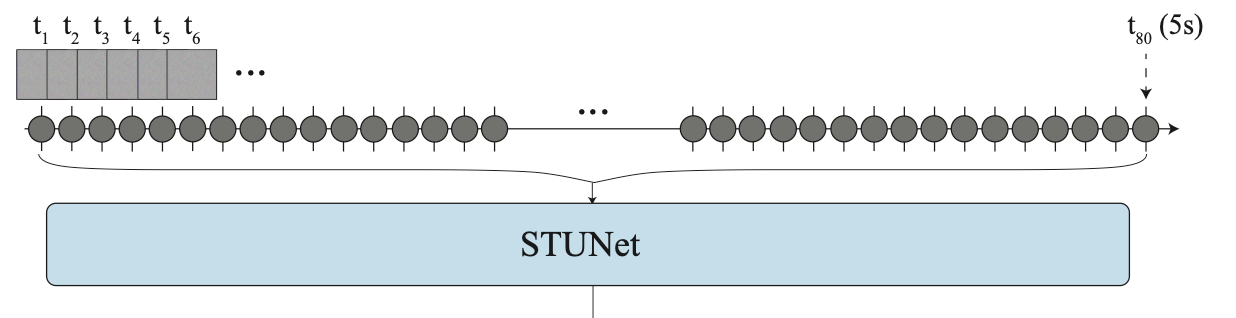
Step 3: Receive as output a 80x128x128x3 video.

At this point, the “temporal resolution” (16 fps) is exactly where we need it to be. This is the chief contribution of Lumiere again - that we don’t require a second temporal upsampling step here. But, our video is in much lower spatial resolution than desired (128x128), so…
Step 4: Upsample the generated video from 128x128 → 1024x1024
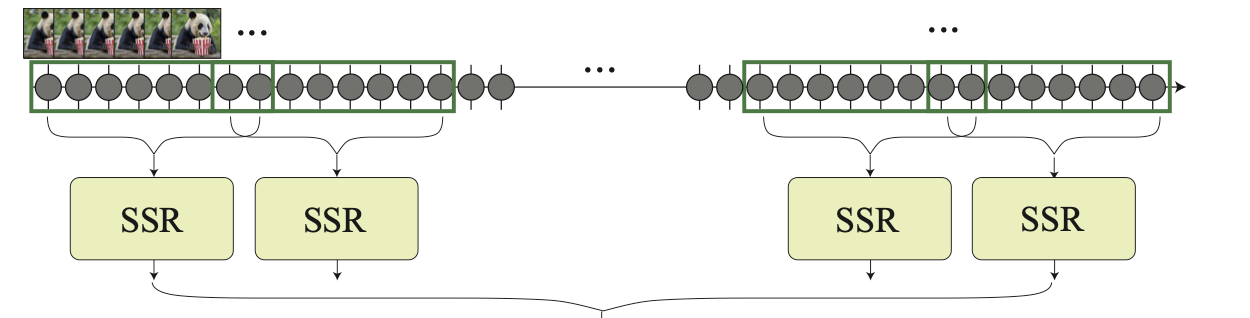
This step a completely separate model from the STUNet - a spatial super-resolver - in practice, the same type of model used for “zoom and enhance” style tech or up sampling old family photos.

There’s a slight catch here, though. Due to memory limitations, the full 5 second video can’t be passed into the SSR at once. Instead, smaller sections of the output video must be upscaled, then stitched back together in some way to form a coherent upscaled video.
Here, the authors make another great design decision focused on their core goal of maintaining smooth, natural motion. They upsample overlapping video sections rather than adjacent ones (1..10, 8..18, 16..26) instead of (1..10, 11..20, 21..30) to allow for less perceptible transitions between the stitched-together sections and avoid any artifacts / aliasing that tends to arise from sudden transitions between differently-upscaled sections.
But how do we combine these separate diffusions together?
MultiDiffusion
MultiDiffusion is a technique which allows seamless integration of multiple diffusion processes with shared constraints. A very easy to understand case of this is in generating panoramic scenes one panel at a time.

Without multidiffusion, there are sharp borders between the generated image chunks—by using MultiDiffusion to frame the optimization problem as not just generating 4 separate images, but generating four parts of one common scene, the results are much more effectively blended into a panorama.
We can think of the MultiDiffusion SSR process used by the authors here as doing a similar stitching together of overlapping pieces, but on the time axis instead of the horizontal space axis used above.
More on MultiDiffusion here: https://multidiffusion.github.io/
Putting it together…
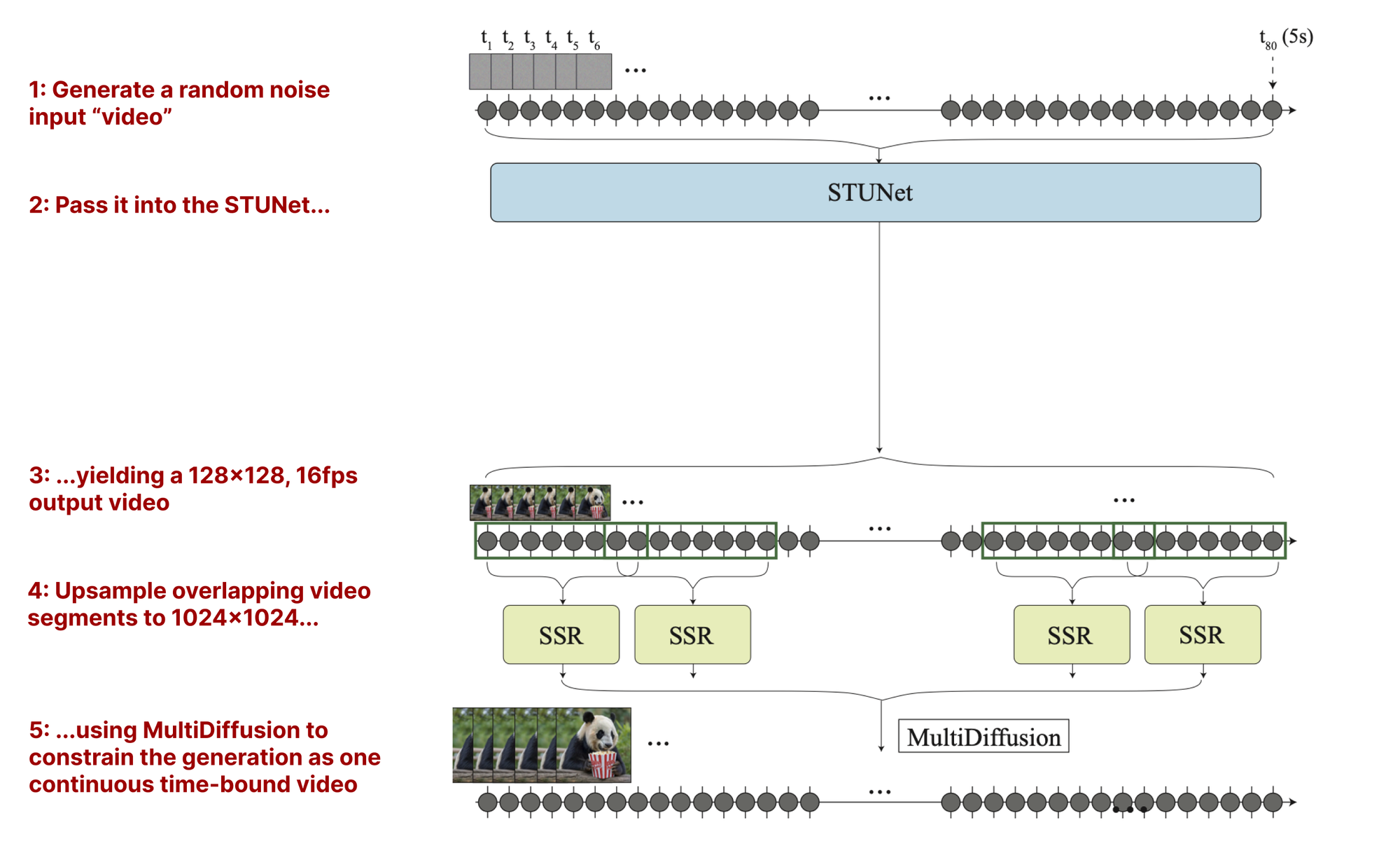
The result is a wonderfully smooth output video with believable, stable, natural motion.
STUNet architecture
Let’s open up what we’ve been treating as a black box. This architecture, by including temporal resizing within the network rather than using a fixed temporal resolution, is the key to generating the entire video in one pass.
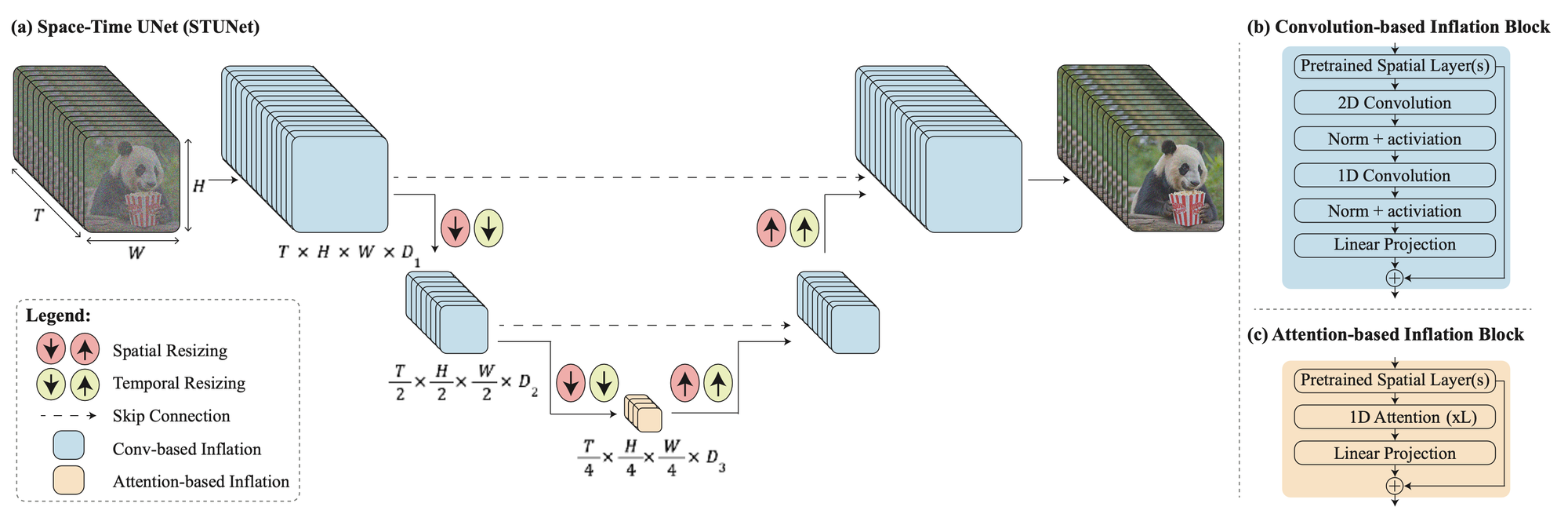
Image generator → video generator
The authors start with an existing, pre-trained text-to-image diffusion architecture (Imagen). This model is designed to produce one image - not a sequence of them, like is needed for video. So, they “inflate” it to accommodate the additional temporal dimension.
The pre-trained layers of the text-to-image model are frozen, only the temporal layers added during inflation are fine-tuned.
Besides this, they also add blocks to downsample in the new temporal dimension. The spatial downsampling is already accounted for by the existing convolutional architecture of underlying U-Net—they add an additional temporal downsampling step after each such block.
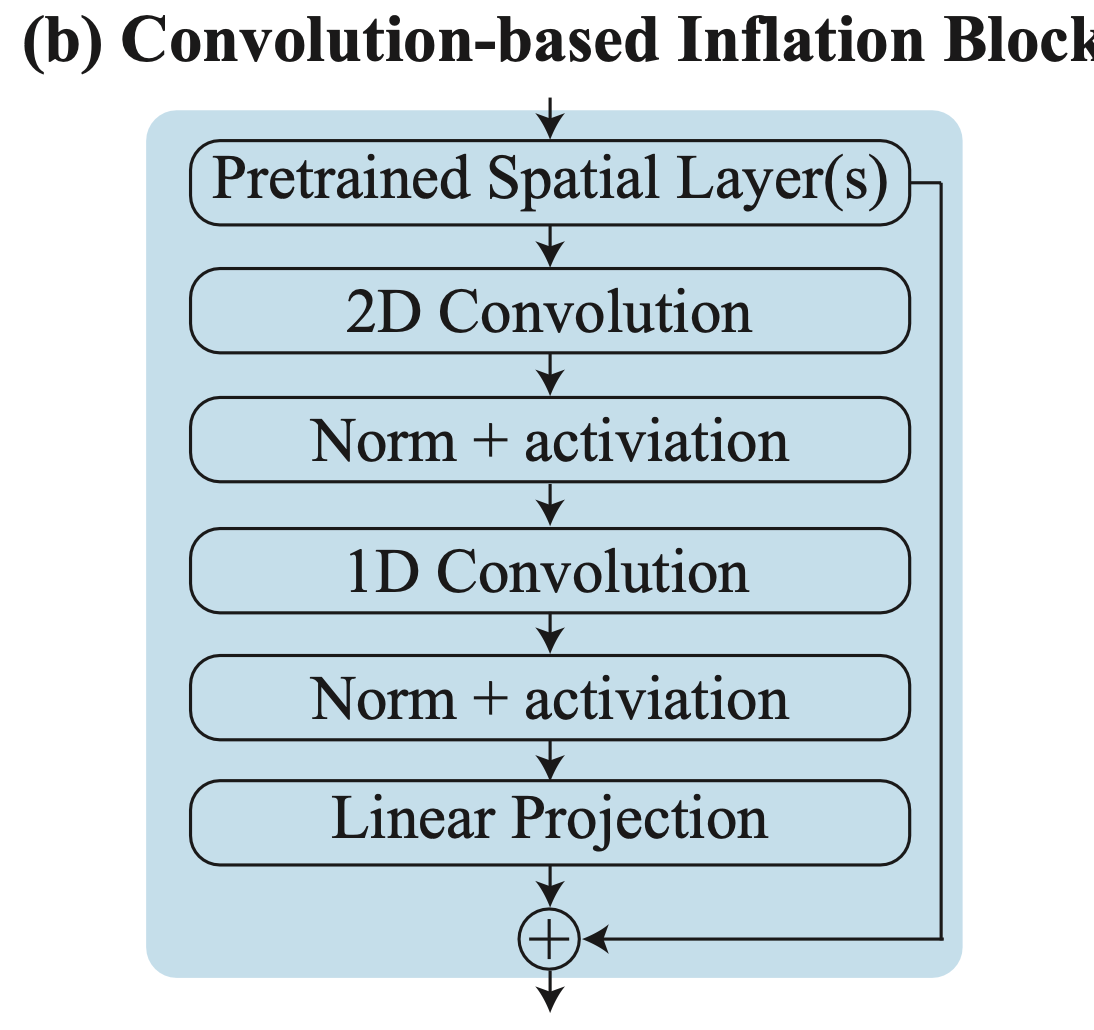
Convolutional temporal down/up-sampling blocks
These are used for the temporal up / downsampling at all layers except the very coarsest. Rather than a 3D convolution over the entire width-height-time axis, they first perform a standard 2D convolution (over width and height only), followed by a 1D convolution over the time dimension.
Adding Attention
As we’ve seen in previous dives, attention is a key mechanism for increasing performance and long-term coherence at sequence generation tasks—but it comes at the cost of compute costs which are quadratic in sequence length.
This is why Lumiere’s temporal downsampling innovation is so crucial. Without it, we’d be applying attention to the full 80-frame sequence, running into the memory and compute limitations that made one-pass generation intractable in the past.
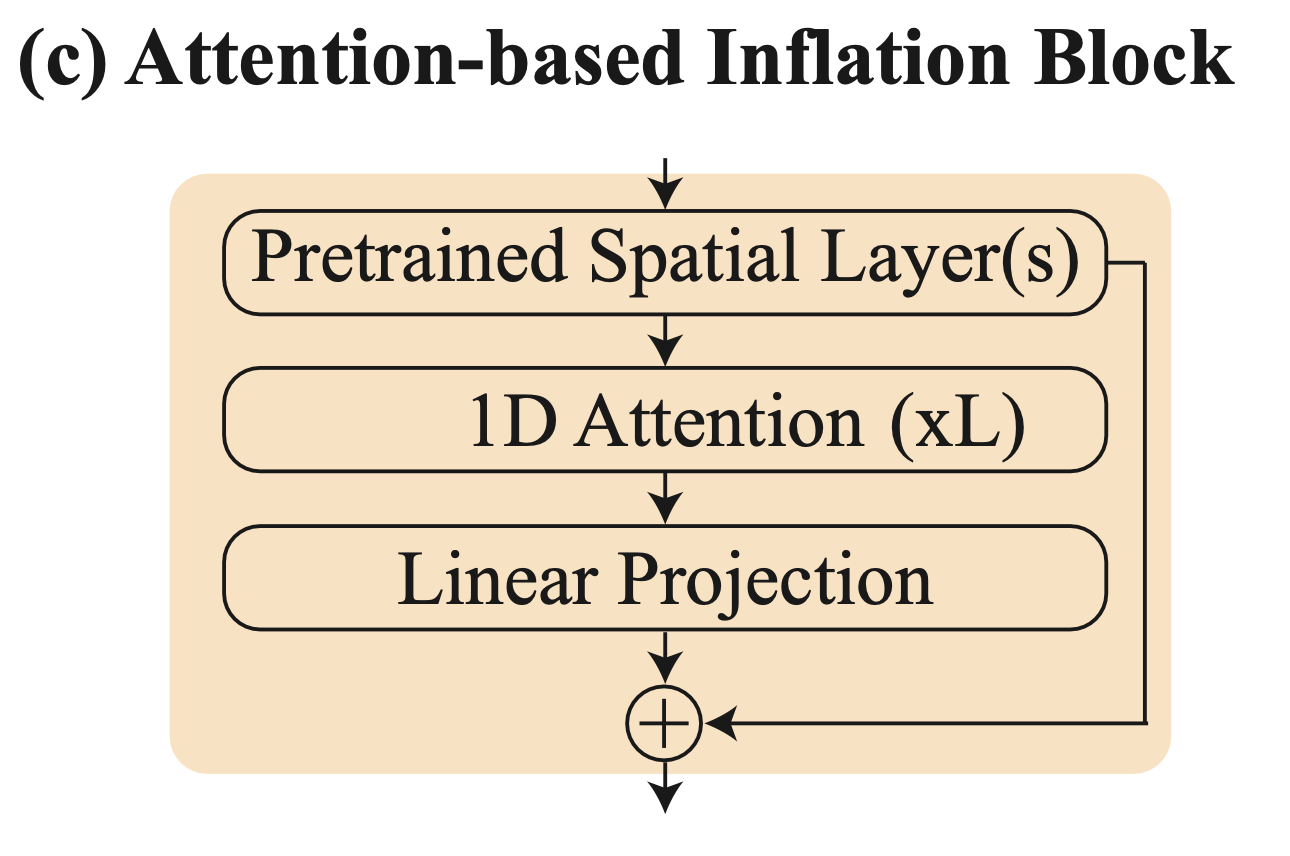
Now, the attention mechanism operates on a sequence reduced in length by a factor of 4 (temporal downsampling), reducing the compute and memory requirements by a factor of 16.
Downstream Applications
The authors claim that the one-pass generation makes this model particularly easy to apply to derivative downstream tasks since the entire resulting video is produced by one model rather than a cascade.
Here are some different ways this can be used:
Image-to-video: animate an image
Inpainting: fill in a missing section of a video
Cinemagraphs: animate part of a still image to make a video on a frozen background
See YouTube video at the start of the post for examples. We started a poll in our discord in the #arxiv-dives channel, hop in and vote for what you would use most here 👇

Evaluation
Performed zero-shot inference on the UCF101 dataset in to compare quantitatively on Frechet Video Distance (lower is better) and Inception Score (higher is better)
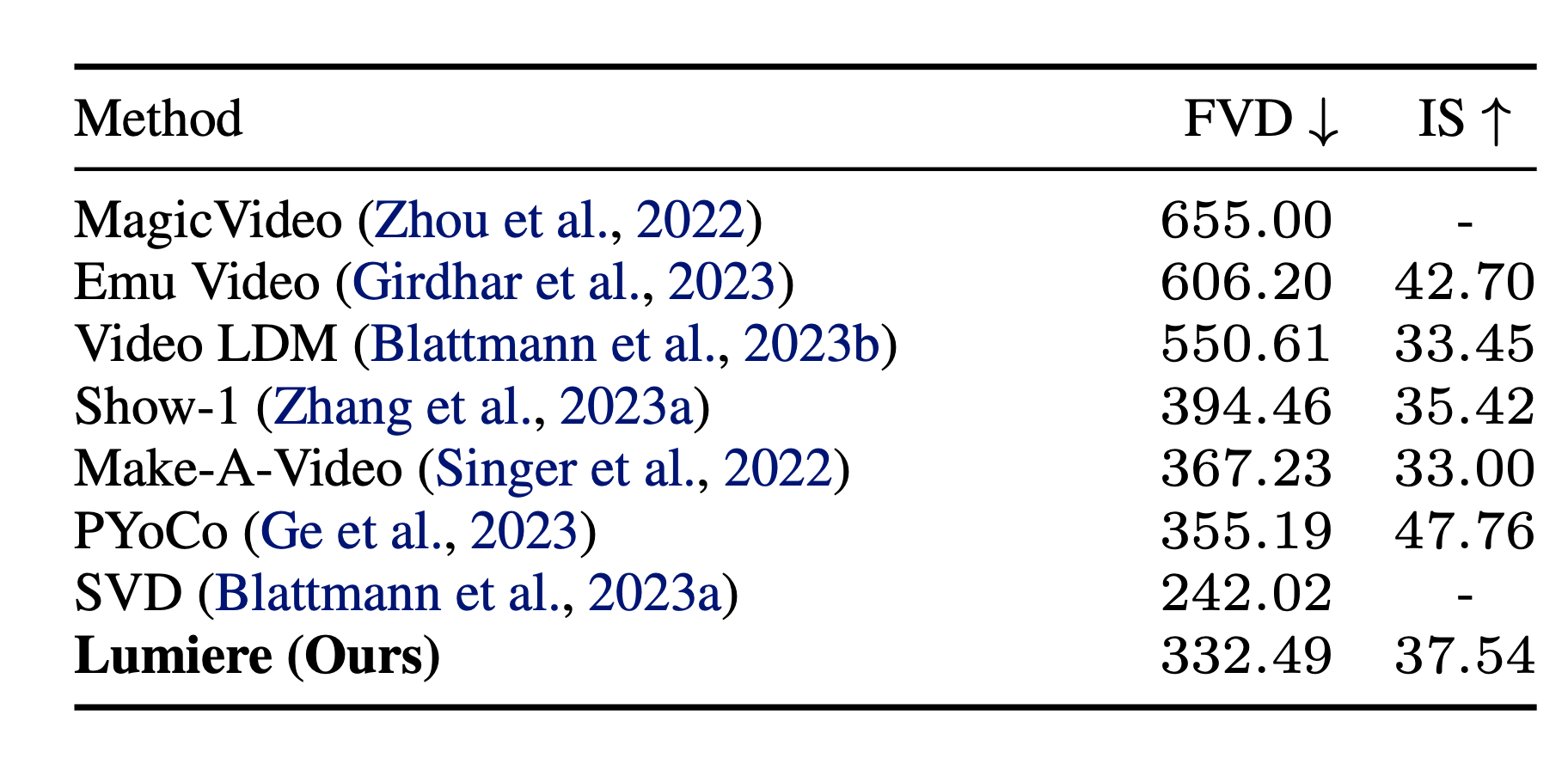
Competitive, if not earth-shattering performance - but the authors argue that these benchmarks are flawed because they:
- A: are oversensitive to low-level structural image details and don’t accurately reflect human perception of realism
- B: only operate on 16 frames, where the chief advantage of Lumiere is in its longer-term consistent motion (up to 80 frames)
To capture this, they also used a human preference study, which showed much stronger results in Lumiere’s favor–it’s uniformly preferred over alternatives below.

Takeaways
Shoving data into smaller latent spaces, and offloading the most computationally expensive operations to the areas of the architecture where the data is lowest-dimensional, continues to look like a Good Thing to Do.
The human preference ranking evidence (above) is super convincing, and the generated videos look excellent and realistic. The technique is obviously working, at least relative to its keyframe-generating predecessors.
Next Up
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.
If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI