
Arxiv Dives - Stable Diffusion
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like to join us live, sign up here.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Arxiv: https://arxiv.org/abs/2304.02643
Published: December 2021
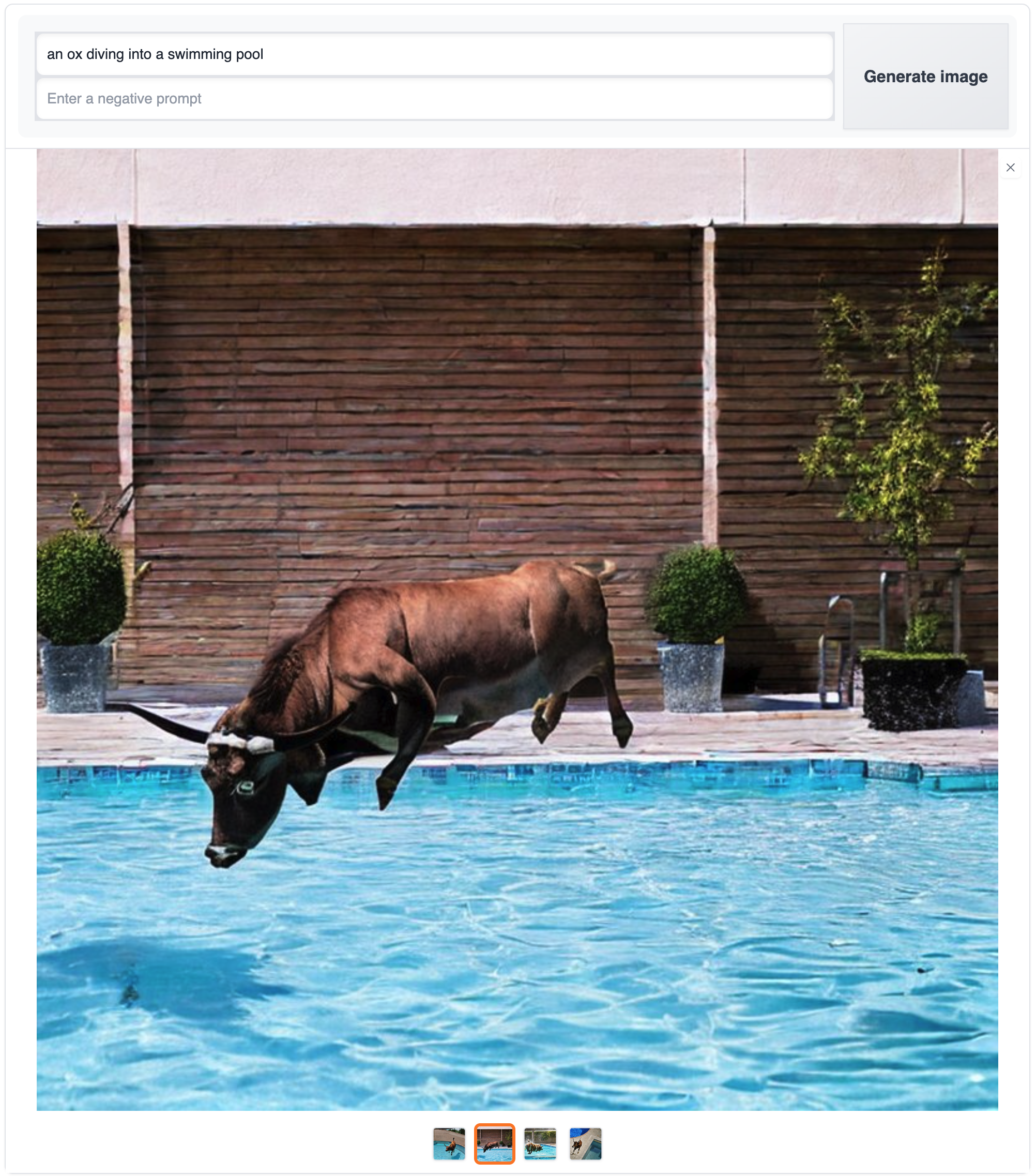
A peek at what this paper enables…
https://huggingface.co/spaces/stabilityai/stable-diffusion
A few things to note here that show the contributions of this model architecture:
- We are able to effectively condition the generated images from text prompts
- The generation speed is fast. 11s to generate four 768^2 images of this quality - via a free + unlimited hosting service
- The generated images, while not perfect, appear high-quality and are free from any “artifacts” (such as the checkerboard / tiling pattern below) common to earlier generations of image generation models, especially GANs (Generative Adversarial Networks)

Core contributions
Why is this paper important?
- Takes an existing model class (Diffusion Probabilistic Models) which were state-of-the-art but ridiculously computationally expensive, and massively reduces the computational costs while maintaining / increasing performance.
- “Democratizing High-Resolution Image Synthesis”
What is the core mechanism that allows them to achieve this?
- Downsampling / dimensionality reduction! Training images are encoded into a lower-dimensional latent space, from which the diffusion model is run to generate images.
🏊 Let’s dive in! 🤿
Background knowledge: Diffusion Models
Diffusion process: An iterative, stochastic process that progressively adds noise to data until the underlying signal is “destroyed”

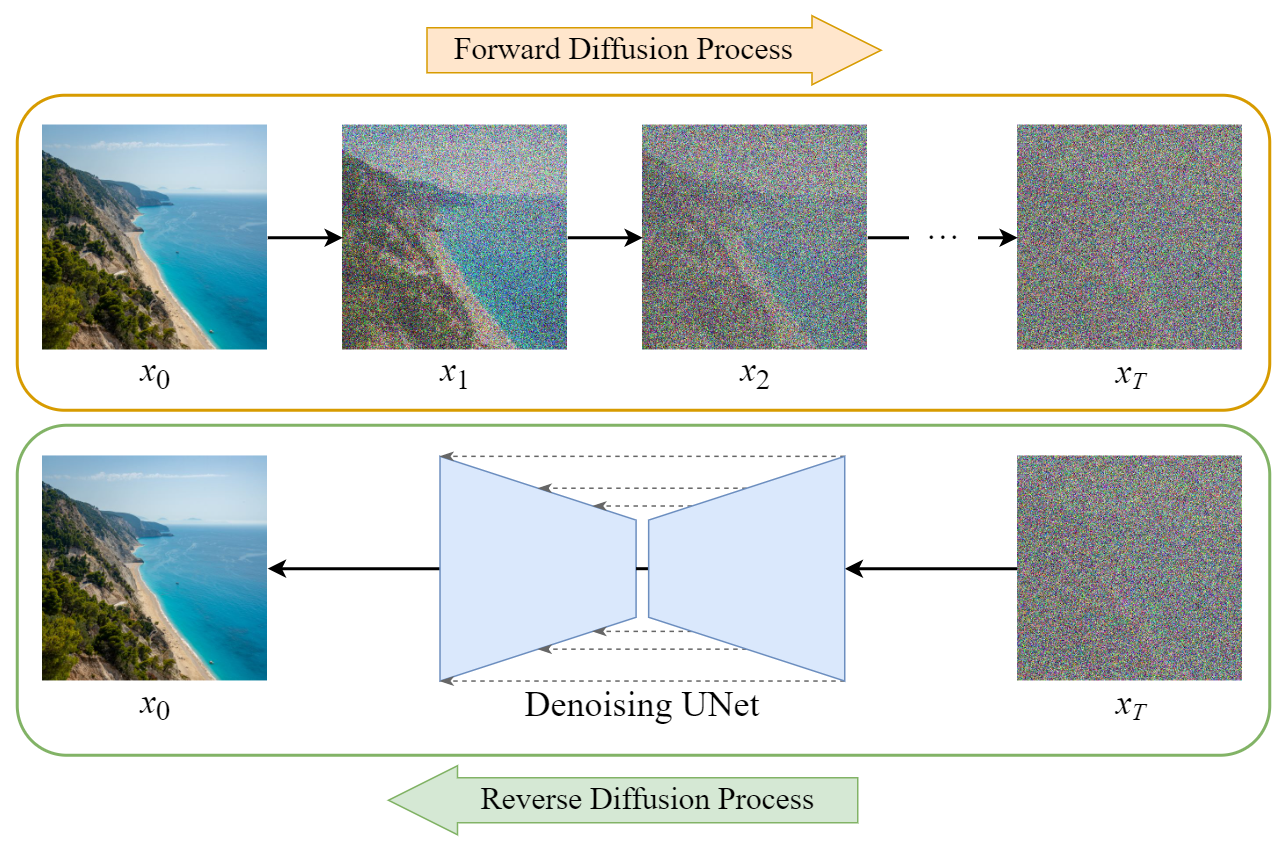
Reverse Diffusion Process
The goal here is to train a neural network to reverse this noising process - to go from a randomly sampled bit of Gaussian noise and denoise it into an intelligible, high-quality image.
How the model does it:
- Take some training images (high-quality image samples like the cat above)
- Apply various intensities of noise to the images (not all the way to completely destroyed signal)
- Keep track of what noise was added (to evaluate the model’s performance and nudge it in the right direction.
- Model predicts the noise that was added, removes that noise from the image - (attempts to denoise the image)
- Evaluate performance against the actual added noise, calculating a loss function
- Use gradient descent to nudge the model in the right direction (to be able to more accurately predict the noise)
(do this a lot!)
The model is learning to predict the noise added to an image, so that it can subtract out that noise and get back (closer) to the original image.
Onward to Latent Diffusion Models (+ stable diffusion)
These diffusion models operate via a very intuitively interesting mechanism and can produce consistently high-quality samples under the right training architectures and parameters.
Their training is also much more stable compared to the previous state of the art GAN architectures. Particularly, they are much more resistant to mode collapse, a failure mode where the model finds a particularly low loss sample and converges on producing exclusively that sample.
This is great progress - but what still needs improvement?
The model is extremely computationally expensive to run. The de-noising process operates at the pixel-level:
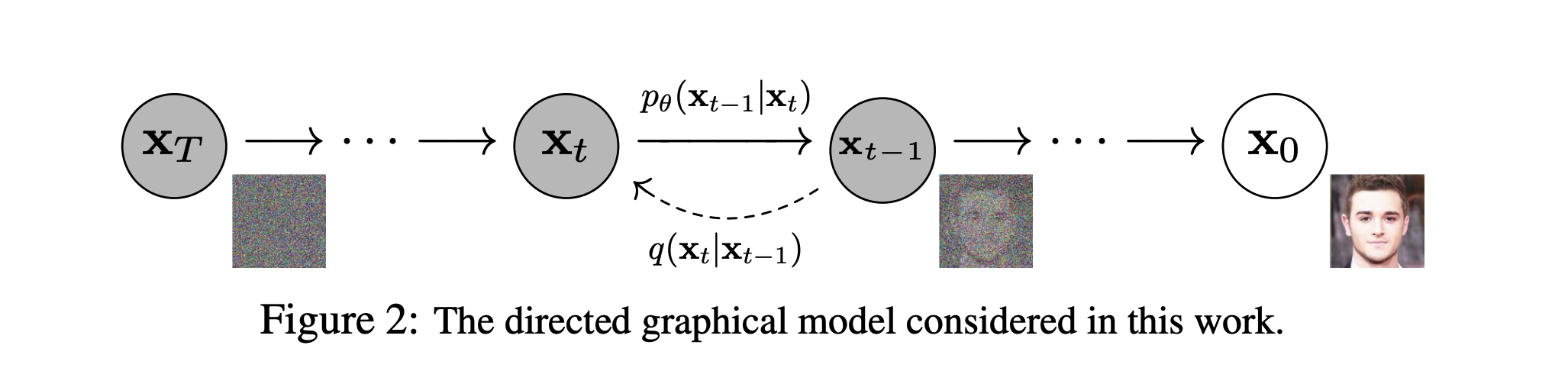
- For training, we start with whole images, noise them to various degrees (each pixel receives noise), and feed the noised image into a UNet which learns to predict the noise.
- For inference, we start with a full-sized noise image, which is run through successive de-noising steps via our trained network.
As a result, even relatively small image generations are prohibitively expensive, and the scaling to large (megapixel+) images is extremely poor.
Enter…Latent Diffusion Models!
Solving computational challenges with compression to a latent space
A large portion of the variance and information encoded in images is not perceptually identifiable or important to us as humans.
Think of a 5MB img getting compressed to 800 kB while still being recognizable as the same image to us.
What matters:
- An image of a human having 2 eyes, a nose, and a mouth
- An ox having 4 legs and two symmetrical-ish horns
- Proportions, symmetry, color consistency, balance
These are things that affect human perception of image quality.
What doesn’t matter:
- The relative red-intensities of pixels in the top right and bottom left corner of the image
- The brightness or saturation of the image (within reason)
- The difference between two visually indistinguishable shades of brown hair
When diffusion models are operated in pixel space, a large amount of computational power and model learning is spent on these small, perceptually irrelevant details rather than on the core, lower-level representations.
The Fix
To remedy this, the authors change up the diffusion model architecture and break training into two separate phases.
- Train a model (autoencoder) to reduce images into a lower-dimensional latent space.
- Train a diffusion model (above) to denoise the new, dimension-reduce latent image representations.
Compression into latent space:
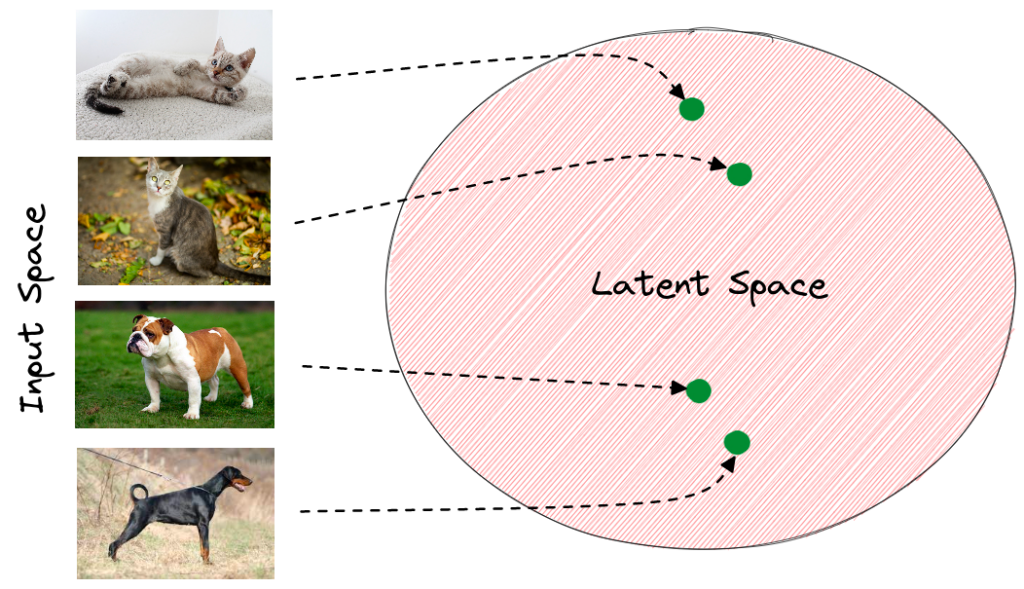
A latent representation is a reduced / compressed representation of the original data which aims to capture its most essential features - filtering out the noise (”Stuff that doesn’t matter”) we discussed above.
…such that observations which are meaningfully more similar in the real world will also be closer to each other in the latent space, see below:
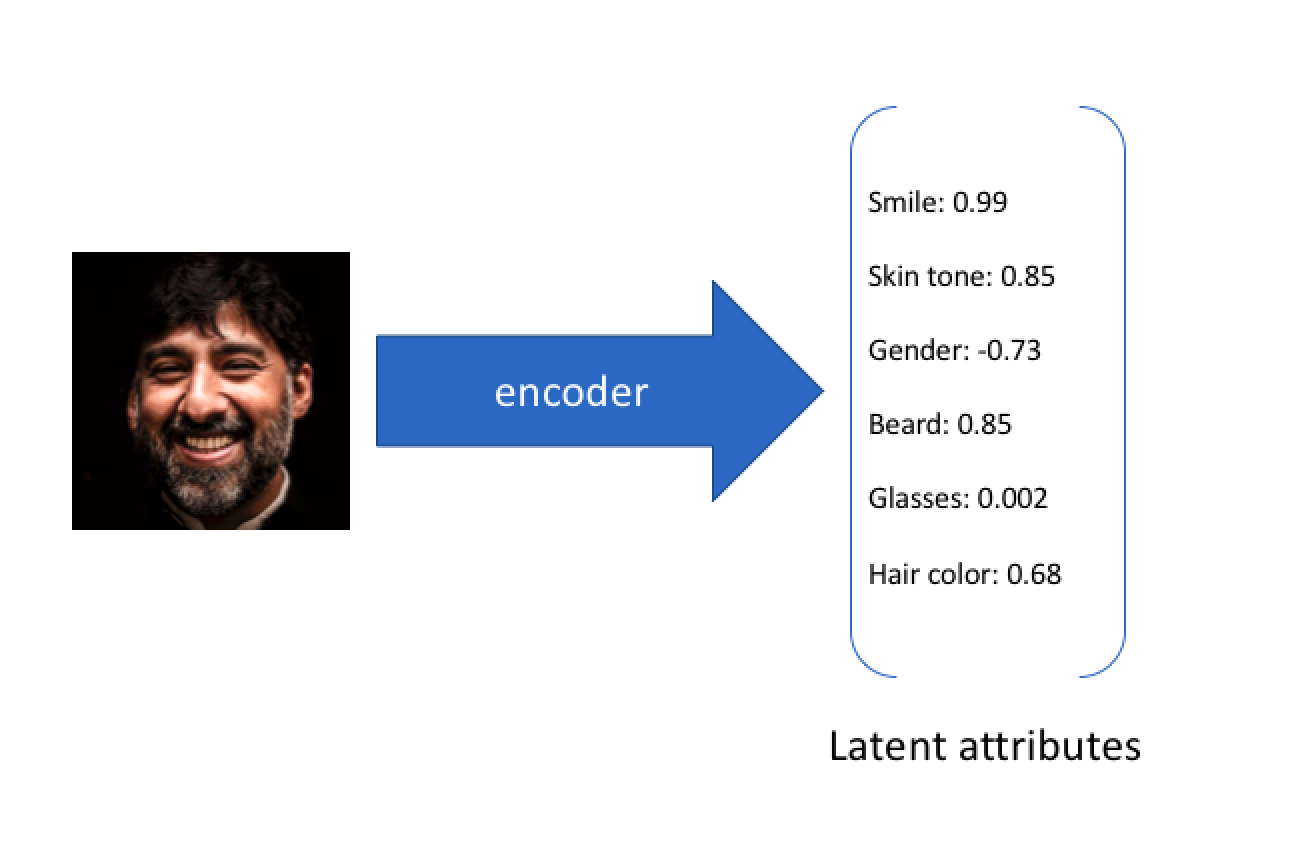
It can be thought of (in broad strokes) as reducing the below image from ~400x400 pixels (480,000 data points) into a compressed vector of 6 key data points (smile, beard, glasses, etc.)
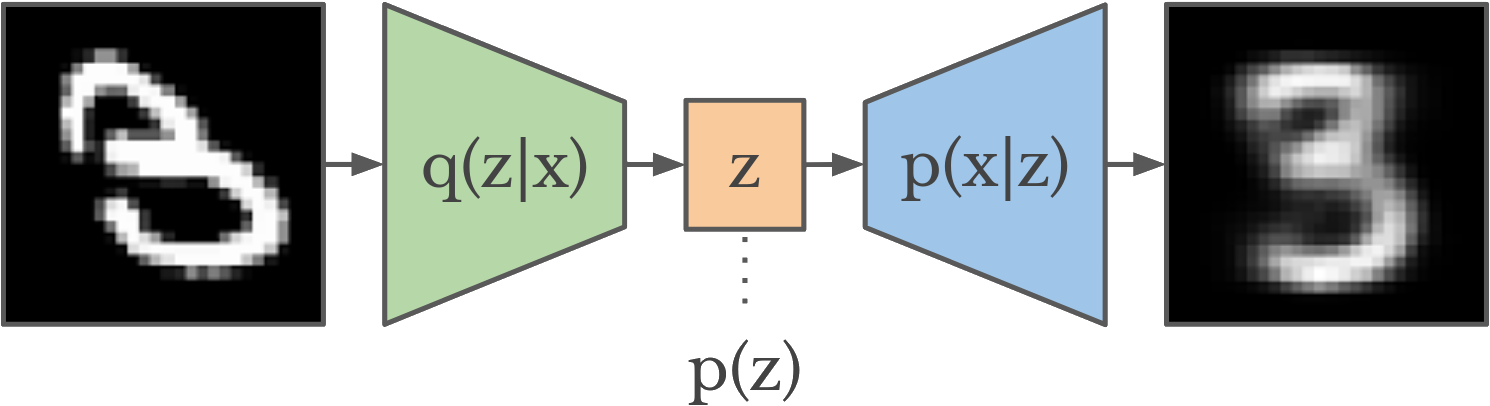
(minimize the “reconstruction error”) - how faithfully can you reconstruct the input image (64x64) from z (which may be just a few floating point numbers)
Rather than noising (during training) and de-noising (during inference) a 256x256x3 image (196608 data points)…
…it can be something more like 32x32x3 (3072 data points)…
…with the added bonus of forcing the diffusion model to focus on deeper, higher-level attributes - not superficial, pixel-level variations.
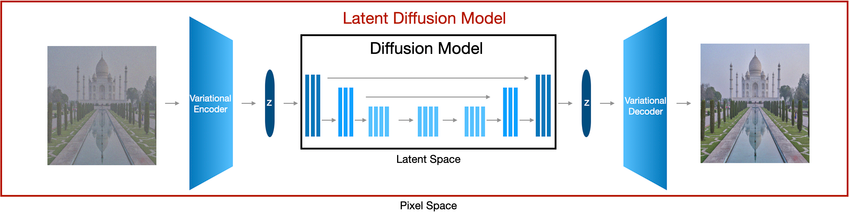
This “trick” allows the authors to achieve state-of-the-art performance on a wide array of tasks in a fraction of the computational time.
How much dimensionality reduction?
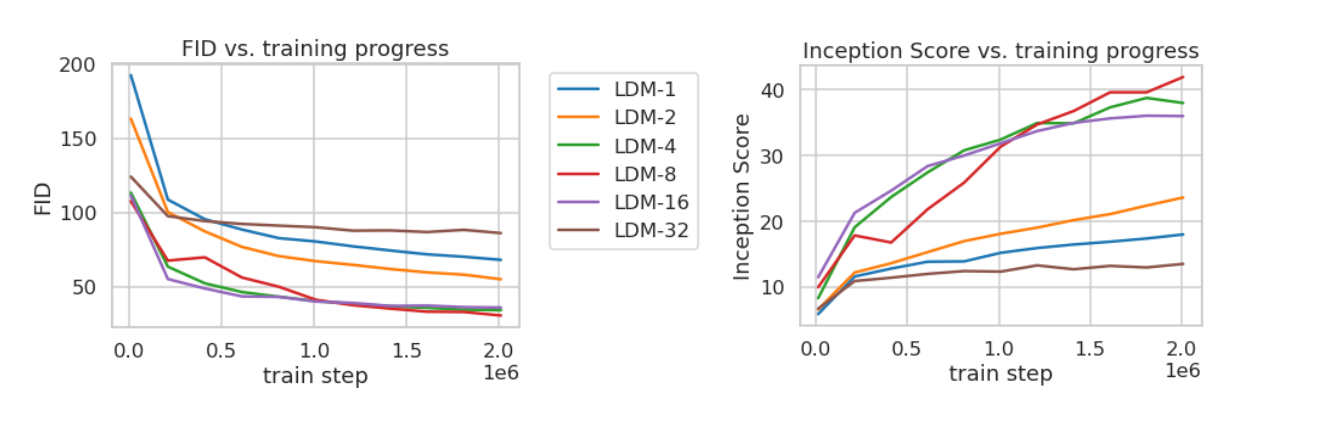
The authors tested several factors for reducing the 256x256x3 input images into a lower-dimensional latent space:
f ∈ {1, 2, 4, 8, 16, 32}
applied to both image dimensions.
- Corresponding latent space dimensions:
- f = 1 → 256x256x3
- f = 2 → 128x128x3
- f = 4 → 64x64x3
- f = 8 → 32x32x3
- f = 16 → 16x16x3
- f = 32 → 8x8x3
There are clear tradeoffs here.
- An f of 1 doesn’t actually reduce input size, retaining maximal information but doing nothing to minimize compute costs
- An f of 32 results in an 8x8x3 latent vector, speeding up training and inference considerably but also dramatically reducing the amount of information the latent space is capable of representing.
The authors directly analyzed this tradeoff, and found compression factors of 4, 8, and 16 to yield the best performance (lower FID and higher Inception Score are indicative of more faithful image recreations.
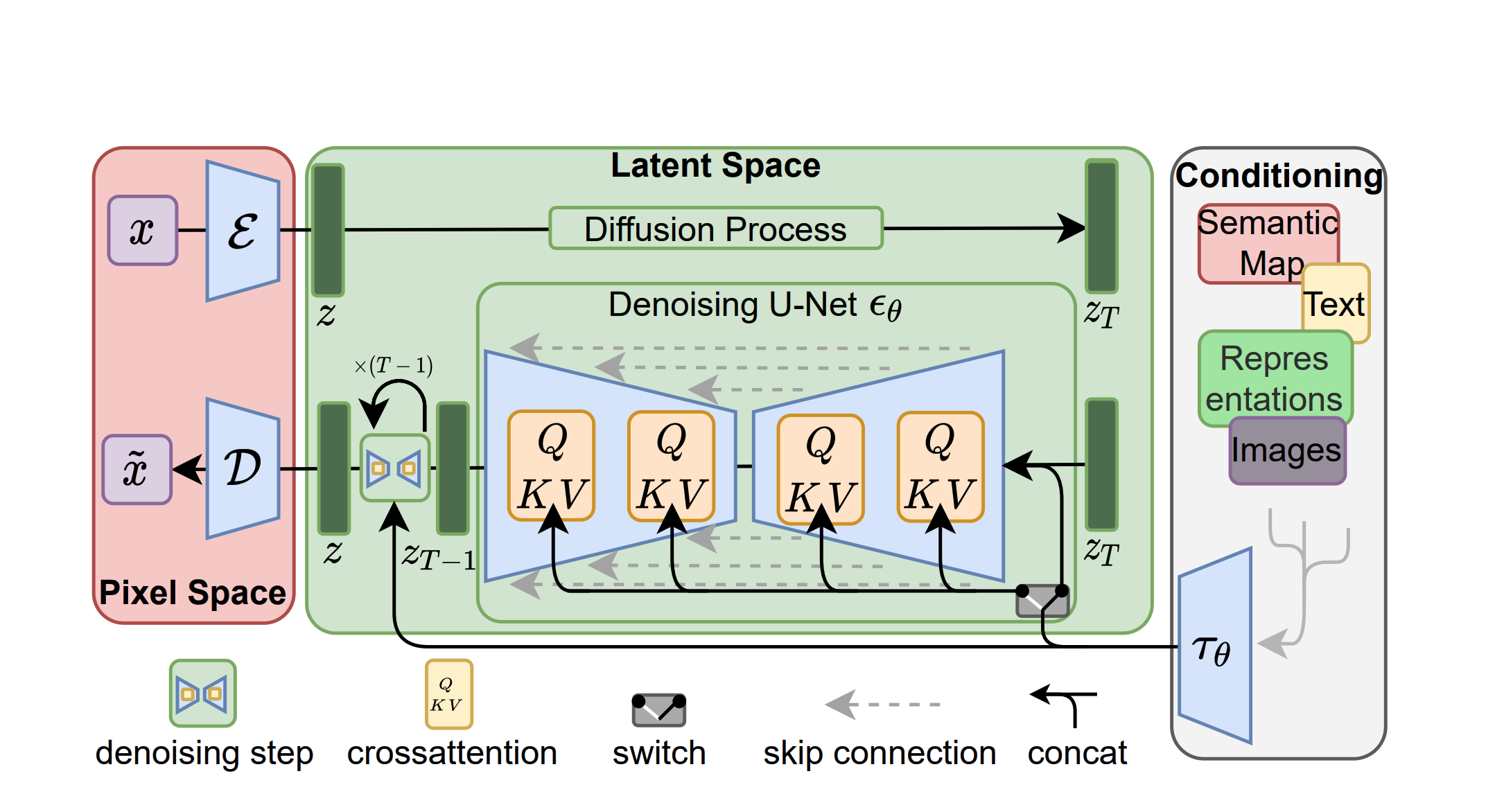
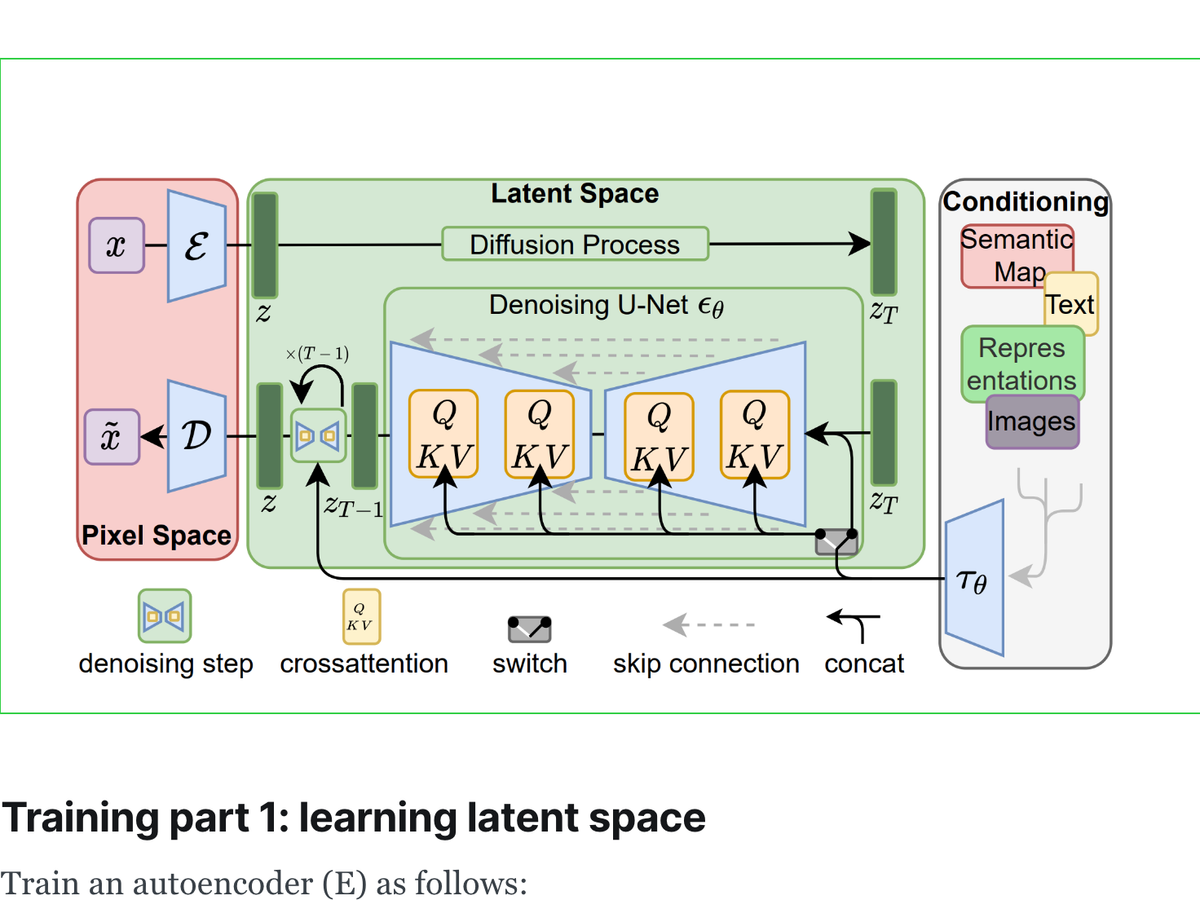
Training part 1: learning latent space
Train an autoencoder (E) as follows:
- Take an image (x), run it through E to compress it into a latent representation (z).
- Decompress it into pixel space (D) → ~x
- Calculate a loss, learn mistakes, repeat.
Training part 2: learning a diffuser on the latent representations
- An image (x) is fed through an encoder (E), yielding a lower-dimensional representation of that image, z.
- The z undergoes a sequential diffusion process, eventually yielding random noise, z(t).
- A convolutional model (”Denoising U-Net”) repeatedly tries to guess the noise that was added to the image and subtract it out. It’s trying to predict z given z(t-whatever)
- It fails a lot, but it continues to get better, and eventually reliably learns to reconstruct z.
- (Optionally, we can also pass in text embeddings (from a pre-trained text vectorizer like OpenAI’s CLIP) to train a model which can be guided by text prompts, like Stable Diffusion.)
Limitations + Impact
Well-stated by the authors (all emphasis mine)
Generative models for media like imagery are a double-edged sword: On the one hand, they enable various creative applications, and in particular approaches like ours that reduce the cost of training and inference have the potential to facilitate access to this technology and democratize its exploration.
On the other hand, it also means that it becomes easier to create and disseminate manipulated data or spread misinformation and spam.
In particular, the deliberate manipulation of images (“deep fakes”) is a common problem in this context, and women in particular are disproportionately affected by it.
Generative models can also reveal their training data, which is of great concern when the data contain sensitive or personal information and were collected without explicit consent.
Finally, deep learning modules tend to reproduce or exacerbate biases that are already present in the data.
Wrapping up
- This paper makes a lot of sense!!
- Great example of seeing the limitations of an existing, promising model and using well-researched methods (departure to a latent space w/ autoencoders) to break those limitations wide open
- and…it’s all open source!
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.