arXiv Dive: RAGAS - Retrieval Augmented Generation Assessment
RAGAS is an evaluation framework for Retrieval Augmented Generation (RAG). A paper released by Exploding Gradients, AMPLYFI, and CardiffNLP. RAGAS
The Best AI Data Version Control Tools [2025]
Data is often seen as static. It's common to just dump your data into S3 buckets in tarballs
OpenCoder: The OPEN Cookbook For Top-Tier Code LLMs
Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in
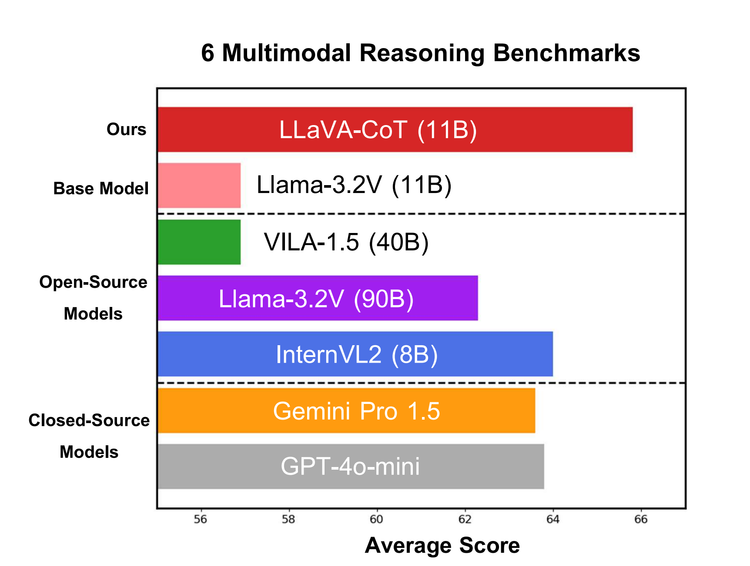
LLaVA-CoT: Let Vision Language Models Reason Step-By-Step
When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to
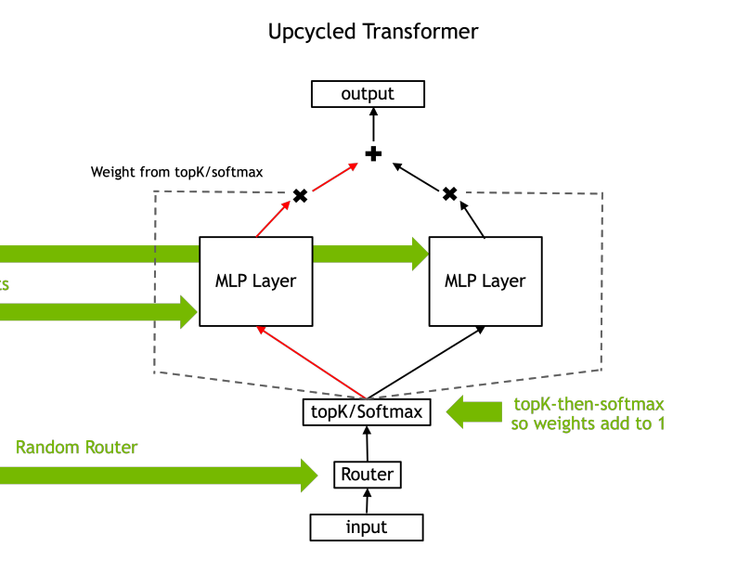
How Upcycling MoEs Beat Dense LLMs
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He
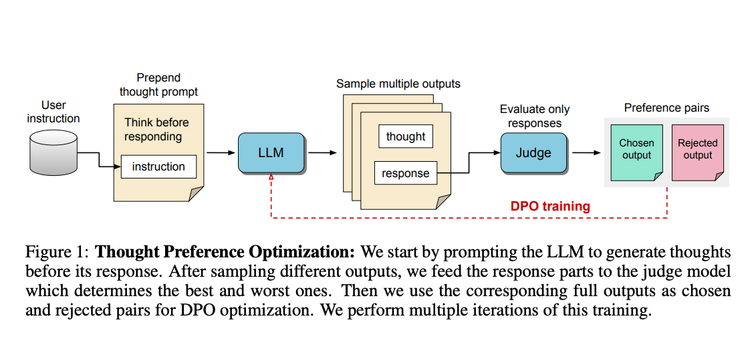
Thinking LLMs: General Instruction Following with Thought Generation
The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is
The Prompt Report Part 2: Plan and Solve, Tree of Thought, and Decomposition Prompting
In the last blog, we went over prompting techniques 1-3 of The Prompt Report. This arXiv Dive, we were lucky
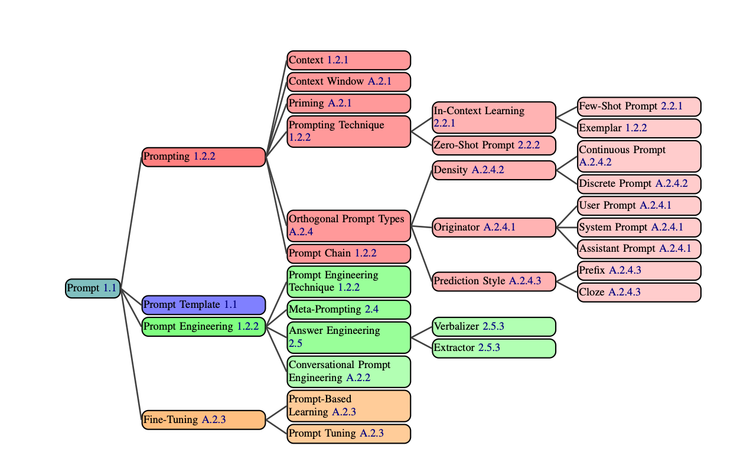
The Prompt Report Part 1: A Systematic Survey of Prompting Techniques
For this blog we are switching it up a bit. In past Arxiv Dives, we have gone deep into the
arXiv Dive: How Flux and Rectified Flow Transformers Work
Flux made quite a splash with its release on August 1st, 2024 as the new state of the art generative
arXiv Dive: How Meta Trained Llama 3.1
Llama 3.1 is a set of Open Weights Foundation models released by Meta, which marks the first time an




![The Best AI Data Version Control Tools [2025]](https://storage.ghost.io/c/bc/24/bc2443b9-eb39-4b32-b473-8eb4576181dd/content/images/size/w750/2024/12/ox-carrying-data.jpg)