
🧠 GRPO VRAM Requirements For the GPU Poor


Since the release of DeepSeek-R1, Group Relative Policy Optimization (GRPO) has become the talk of the town for Reinforcement Learning in Large Language Models due to its effectiveness and ease of training. The R1 paper demonstrated how you can use GRPO to go from a base instruction following LLM (DeepSeek-v3) to a reasoning model (DeepSeek-R1).
To learn more about instruction following, reasoning models, and the full DeepSeek-R1 model, I suggest you checkout some of our other deep dives.

Running out of VRAM
When I saw there was already an easy to use implementation of GRPO in the trl library, I was off to the races. I broke out my little Nvidia GeForce RTX 3080 powered laptop with 16GB of VRAM and quickly started training. As anyone who’s tried to train an LLM at home quickly find, the parameters in the sample code gave a big whopping out of memory (OOM) error.
torch.OutOfMemoryError: CUDA out of memory.
Tried to allocate 1.90 GiB. GPU 0 has a total capacity of 15.73 GiB of which 1.28 GiB is free.
Including non-PyTorch memory, this process has 14.43 GiB memory in use. Of the allocated memory 11.82 GiB is allocated by PyTorch, and 2.41 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)The goal of this post is to save you some time picking the right model size for your hardware budget. The most impactful decisions you’ll have to make when kicking off a fine tune are the model size and if you are performing a full fine tune or a parameter efficient fine tune (PEFT).
Show Me The Usage
We performed a series of experiments to determine the VRAM requirements for training various sizes of models. The parameter count is varied from 0.5 billion - 14 billion, and we compare full fine tuning of the weights vs parameter efficient fine tunes (with LoRA). All training runs were done on an H100, so here OOM means >80GB of VRAM.
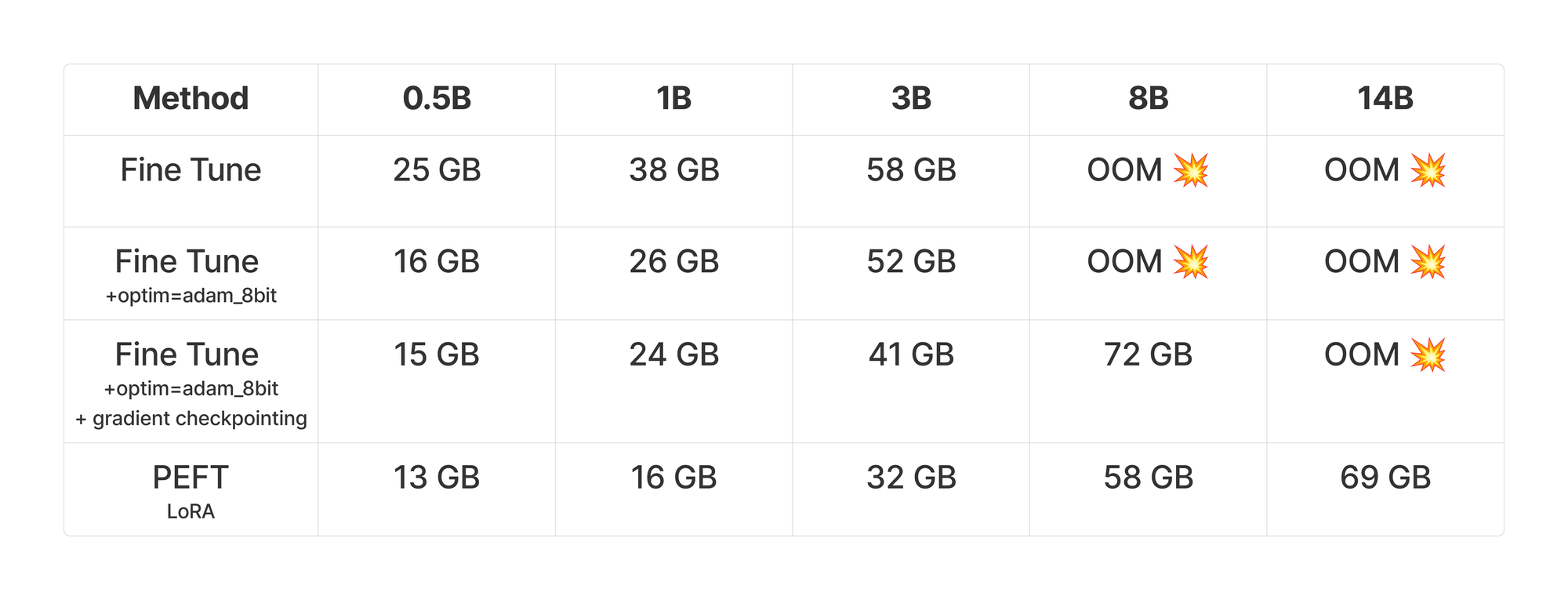
Inside the table you’ll find the peak memory usage in the first 100 steps of training on the GSM8K dataset. The models we used for the experiments were:
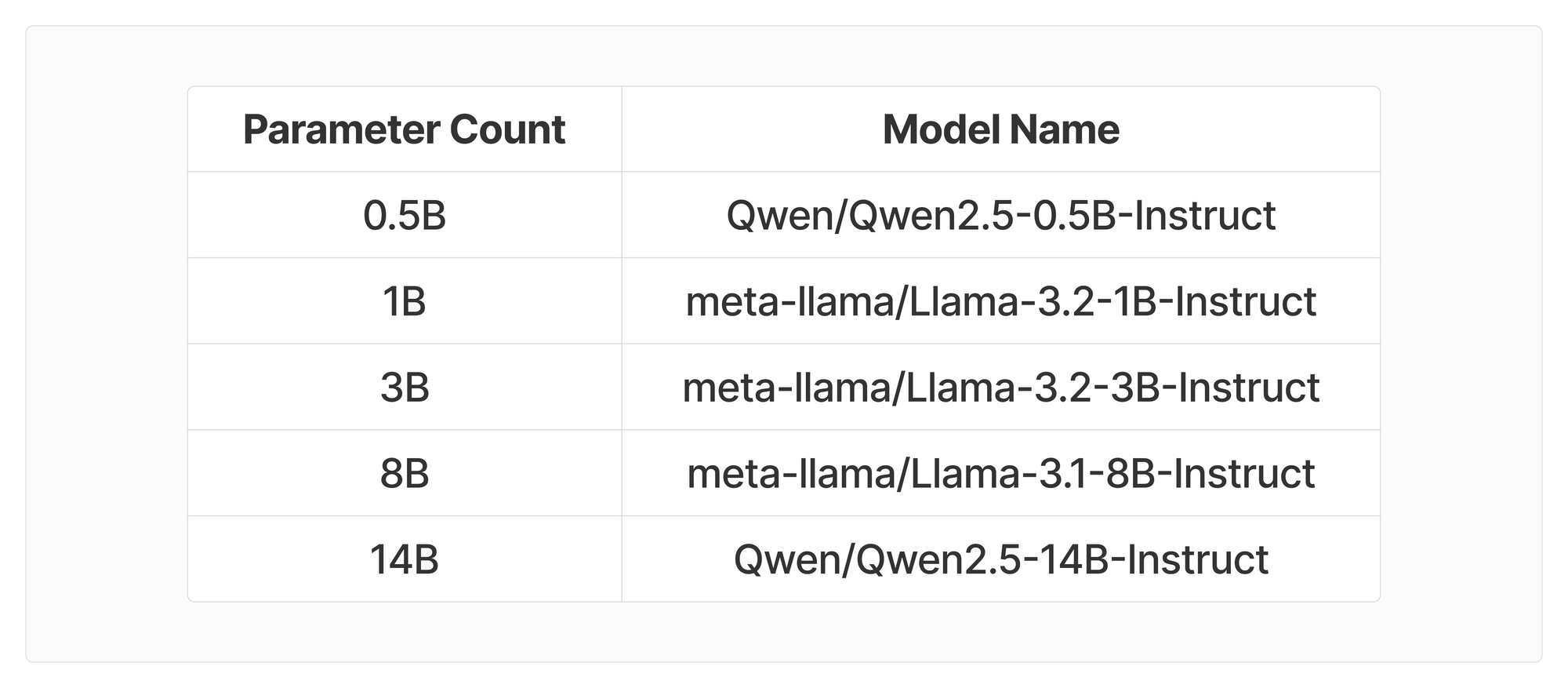
All the experiments were done using Shadeform’s GPU Marketplace, making it easy to spin up and down an H100 for a couple bucks per experiment.

Why so much memory?
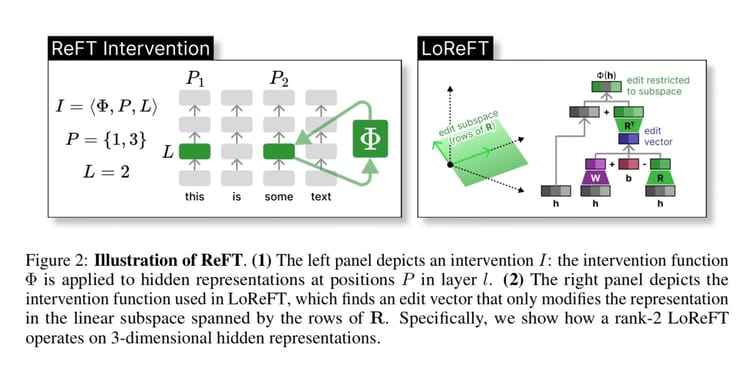
GRPO can be summarized in the following diagram below.
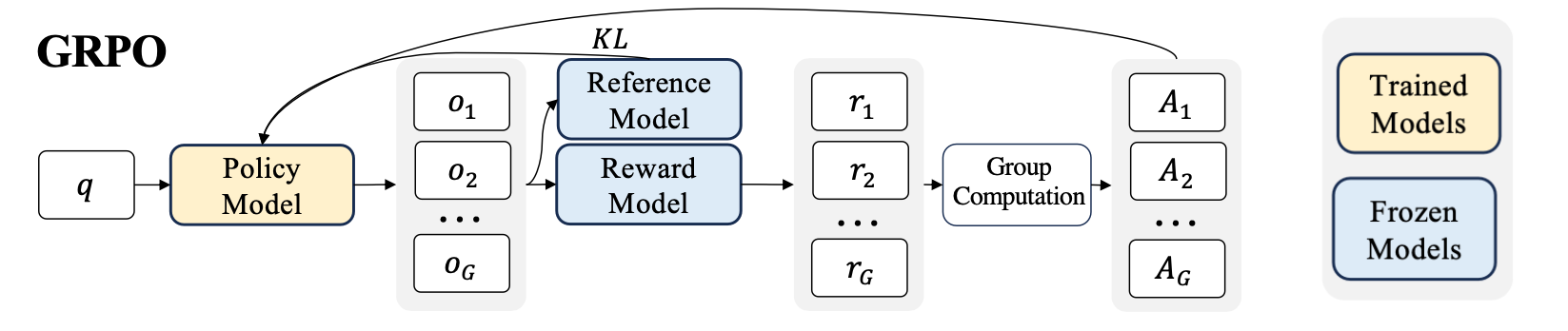
GRPO is memory hungry because internally it involves multiple models, and multiple outputs per query in the training data. The policy model, reference model and reward model in the diagram above each are an LLM you are running inference on. (Although technically the reward model might not be parameterized and could just be a python function or regex, which we will see later in the code).
If it looks complicated, or you don’t understand what the different terms mean, don’t worry. We will be breaking GRPO down in our paper club on Friday, and linking to the blog here once it’s finished.

Why Does 8-Bit Optimization and Gradient Checkpointing Help?
Training a large language model requires storing three main types of information in memory: the model's parameters, the gradients needed for learning, and the optimizer's tracking data. Think of it like this: if the model's parameters take up X amount of space, the gradients will take up about the same amount. Then optimizers like AdamW need even more space because they're like a record-keeper, tracking the history of recent updates to make better decisions about future changes.
To reduce this memory burden, we have two helpful techniques. First, we can use "8-bit" versions of optimizers like AdamW, which store their tracking data more efficiently while still maintaining good performance - similar to how compressing a photo can save space while keeping most of the image quality. Second, we can use gradient checkpointing, which is like taking strategic snapshots of the training process instead of recording everything. While this makes training about 20-30% slower, it dramatically reduces memory usage. Together, these techniques make it possible to train larger models even for the GPU poor like us.
Minimal Code Example
Libraries like trl are already starting to support GRPO, making it easy to fine-tune LLMs supported by the transformers library. The code is as simple as swapping out your trainer for a GRPOTrainer and defining a few rewards. The minimal code for GRPO is ~99 lines and can be spun up very quickly if you are using a small model like "meta-llama/Llama-3.2-1B-Instruct" and dataset like openai/GSM8K.
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import GRPOConfig, GRPOTrainer
import re
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split]
data = data.map(lambda x: {
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
})
return data
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def accuracy_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
"""Reward function that extracts the answer from the xml tags and compares it to the correct answer."""
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def main():
dataset = get_gsm8k_questions()
model_name = "meta-llama/Llama-3.2-1B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map=None
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
training_args = GRPOConfig(
output_dir="output",
learning_rate=5e-6,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_generations=4,
max_prompt_length=256,
max_completion_length=786,
num_train_epochs=1,
save_steps=100,
save_total_limit=1,
max_grad_norm=0.1,
log_on_each_node=False,
)
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
format_reward_func,
accuracy_reward_func
],
args=training_args,
train_dataset=dataset,
)
trainer.train()
if __name__ == "__main__":
main()Cheers @willccbb for the starter code that was used to run all of these experiments.
What does "Num Generations" do?
Num Generations is a hyper parameter that determines how many completions we are going to sample per query in the training data. This increases the VRAM consumption significantly because it inherently increases the size of the data you have to generate. With a proper temperature setting, this is one of the keys to the RL, allowing the model to generate a variety of responses that get scored by the reward model.
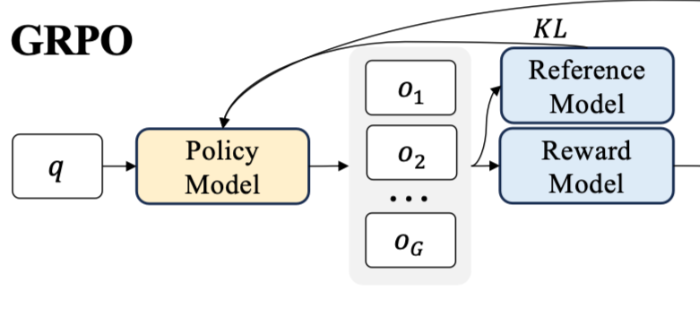
There is currently an open GitHub issue that may help address the memory bottleneck.
https://github.com/huggingface/trl/issues/2709
Instead of computing all the above values again for num_completions=8,16,64 (the DeepSeekMath paper uses 64) we just did these tests with a 1B param model to show you the memory growth. I would recommend sticking to num_generations=4 until the memory bottleneck is fixed, I still got decent performance with the low number.
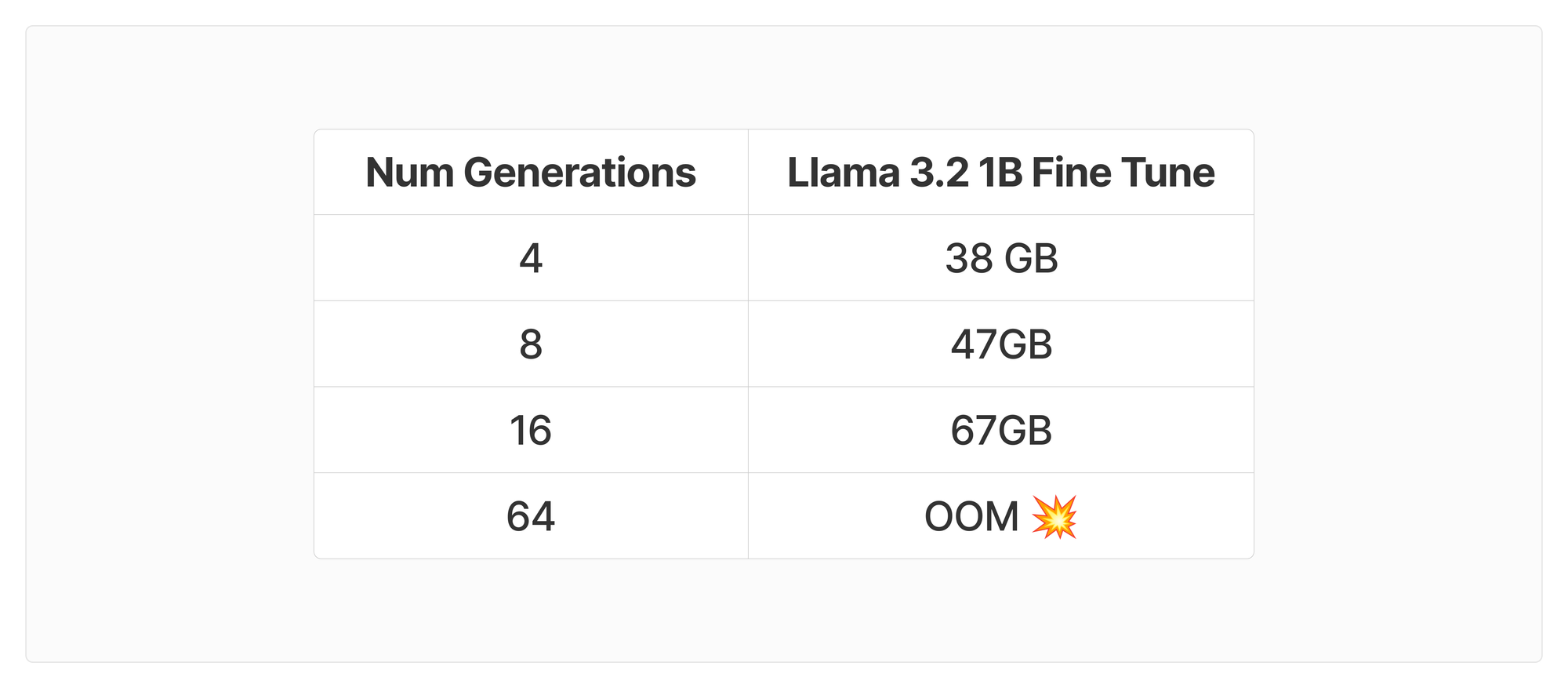
Other Important Factors for VRAM
It would take a decent amount of experiments to do an exhaustive hyper parameter sweep of everything that impacts memory usage. Instead, I just call out the settings to pay attention to here, and the values the experiments were run with.
batch_size=1since GRPO generates multiple responses per query, the batch size gets out of hand quickly.gradient_accumulation_steps=4the optimizer is another place that sucks up a lot of VRAM usage. This parameter determines how far back we are going to store gradients to help the optimizer navigate it’s hill climb.num_completions=4we already chatted about this a bit, the DeepSeekMath paper used 64. That was simply out of our compute budget.max_prompt_length=256if you want to train reasoning for larger context, you will have to bump up your VRAM. GSM8K are relatively small prompts and work well for this test.max_completion_length=786again, the reasoning chain is limited here just because we have limited memory to compute attention over. The more tokens in the context or generated, the larger memory we will need.- LoRA
target_modules=["q_proj", "k_proj", "o_proj", "up_proj", "down_proj"]there are a couple different iterations I tried on this.target_modules="all-linear"is a popular way to squeeze the most performance (in terms of accuracy) out of your LoRA. Ultimately I went with some attention layers and some linear layers to get a balance that could fit onto 16GB of VRAM on my laptop.
Rough Math for Computing VRAM Usage
If you are training in FP16, this is some back of the envelope math that can help you get an idea of where we are spending most of the memory.
- Model Params = 2 bytes per param
- Reference Model Params = 2 bytes per param
- Gradients = 2 bytes / param
- Optimizer states = 8 bytes per param
- 8-Bit Optimizer = 4 bytes per param
- PEFT helps reduce the gradients
- Num completions increases the size of the kv cache from my understanding, if someone can help give pointers on the actual math here, feel free to join our discord and let me know, I’ll update the blog accordingly.
What about accuracy?
The point of this post was not to compute accuracy for every permutation of hyper parameters, but I did manage to complete an end to end training on the 1B parameter Llama 3.2 model. Before GRPO the model achieved ~19% on the held out test set, and after the model sky rocketed to ~40.5% after one epoch of training 🎉. While no where near state of the art, this shows the power of GRPO, and I’m excited to run more experiments in the future.
Next Up
If you like not only reading the research but practically trying it on your own data, come join our research community and attend our Arxiv Dive's on Fridays. Each Friday we dive into a technical research paper and talk about how to apply it to your own work. Also feel free to join our Discord if you have any follow up questions.
This Friday (Feb 7th, 2025) we are diving into the math and gnitty gritty details behind GRPO that were out of scope for this blog.

If you like random tweets about fine-tuning, datasets, or research papers we are diving into, feel free to follow me on the socials as well @gregschoeninger.


Member discussion