ArXiv Dives: Text Diffusion with SEDD
Diffusion models have been popular for computer vision tasks. Recently models such as Sora show how you can apply Diffusion
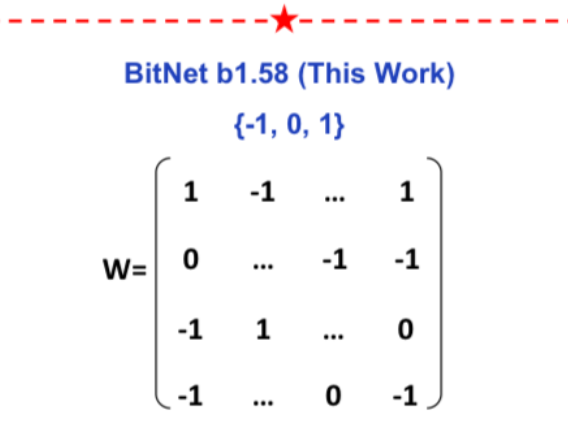
ArXiv Dives: The Era of 1-bit LLMs, All Large Language Models are in 1.58 Bits
This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1}
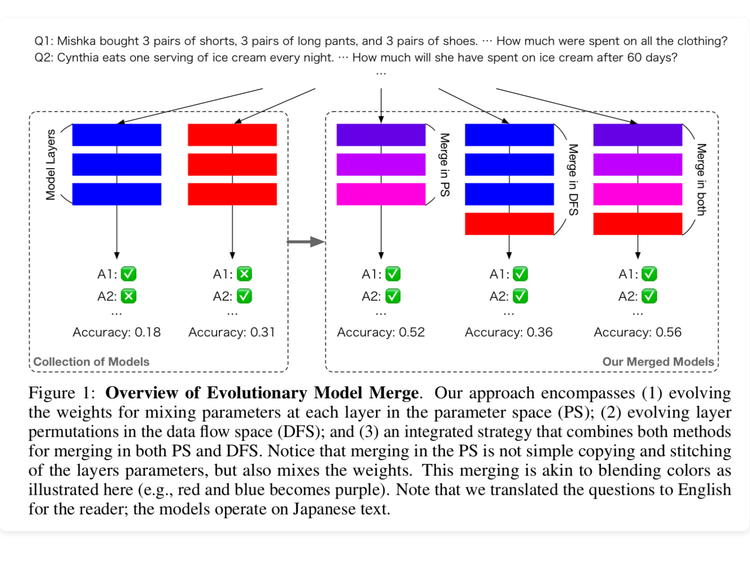
ArXiv Dives: Evolutionary Optimization of Model Merging Recipes
Today, we’re diving into a fun paper by the team at Sakana.ai called “Evolutionary Optimization of Model Merging
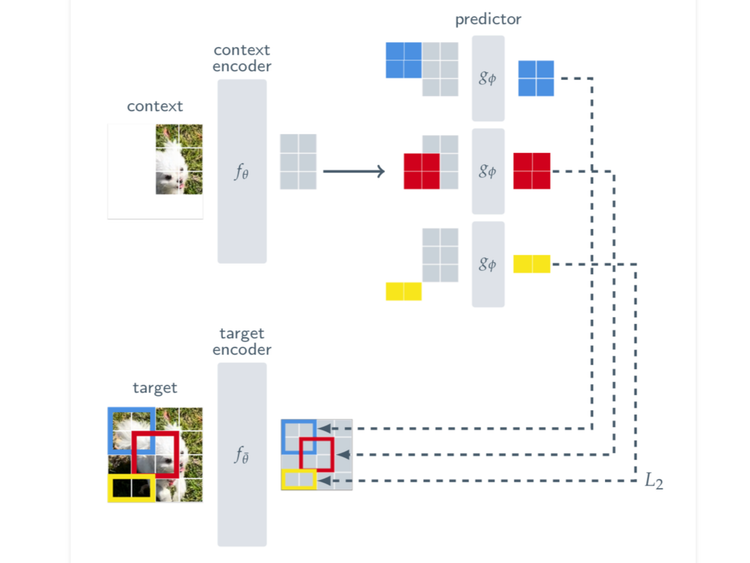
ArXiv Dives: I-JEPA
Today, we’re diving into the I-JEPA paper. JEPA stands for Joint-Embedding Predictive Architecture and if you have been following
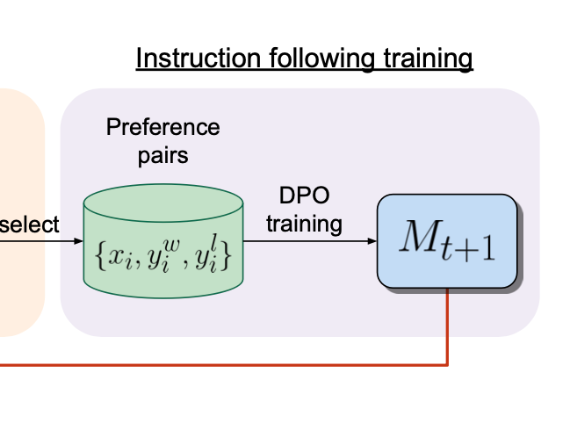
How to train Mistral 7B as a "Self-Rewarding Language Model"
About a month ago we went over the "Self-Rewarding Language Models" paper by the team at Meta AI
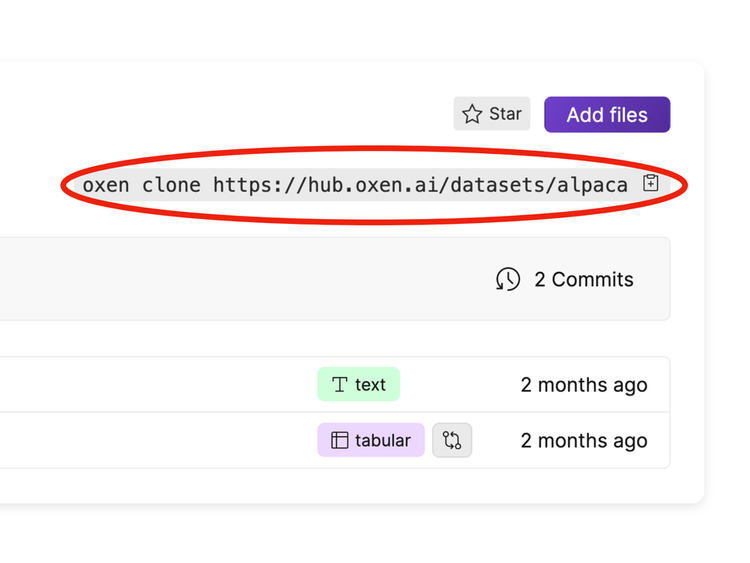
Downloading Datasets with Oxen.ai
Oxen.ai makes it quick and easy to download any version of your data wherever and whenever you need it.
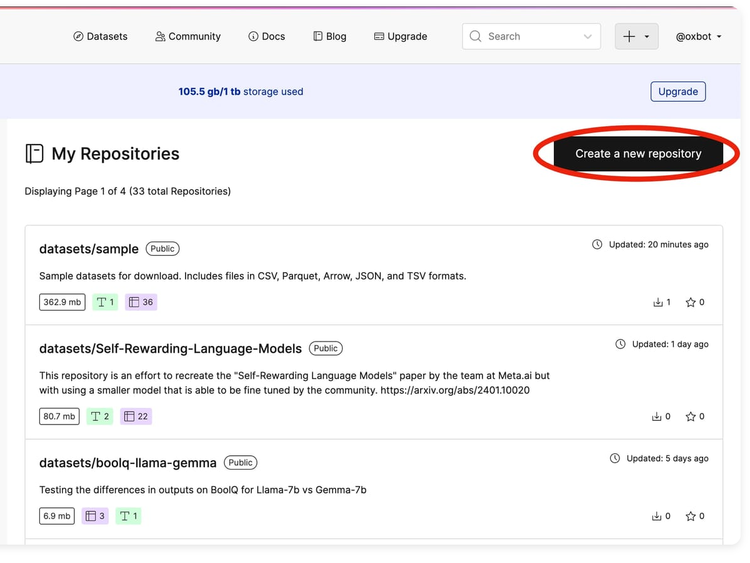
Uploading Datasets to Oxen.ai
Oxen.ai makes it quick and easy to upload your datasets, keep track of every version and share them with
ArXiv Dives - Diffusion Transformers
Diffusion transformers achieve state-of-the-art quality generating images by replacing the commonly used U-Net backbone with a transformer that operates on
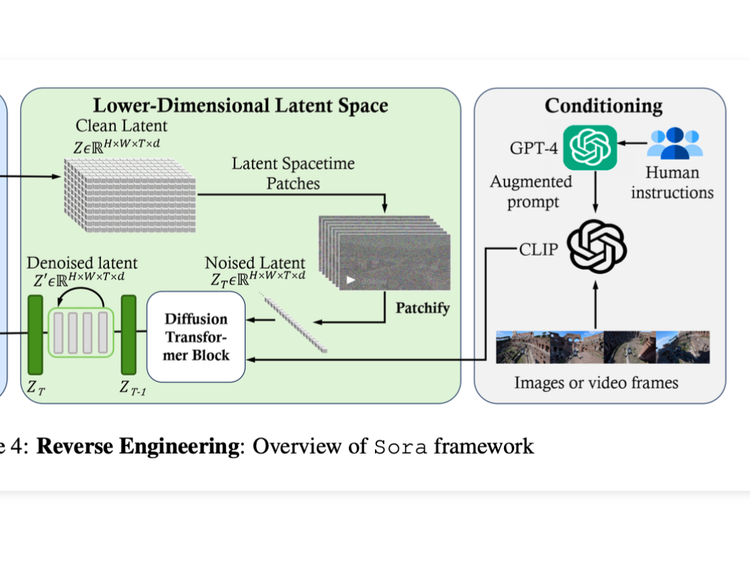
"Road to Sora" Paper Reading List
This post is an effort to put together a reading list for our Friday paper club called ArXiv Dives. Since
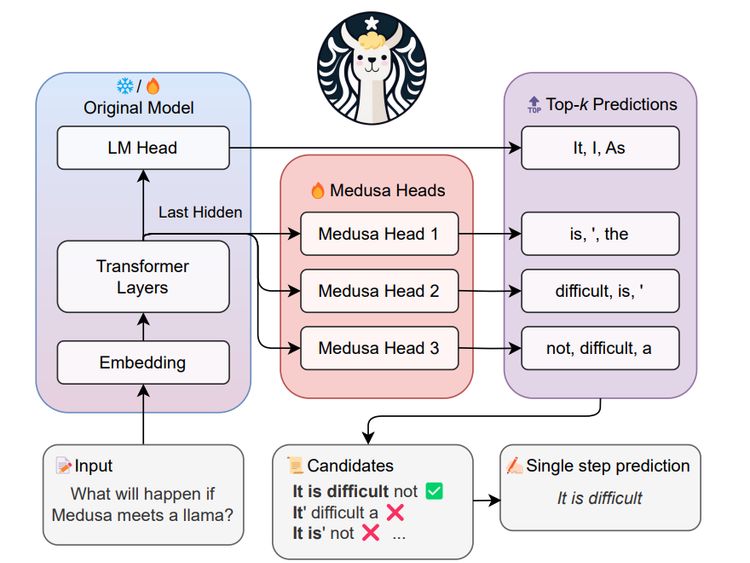
ArXiv Dives - Medusa
Abstract
In this paper, they present MEDUSA, an efficient method that augments LLM inference by adding extra decoding heads to