
Arxiv Dives - Direct Preference Optimization (DPO)
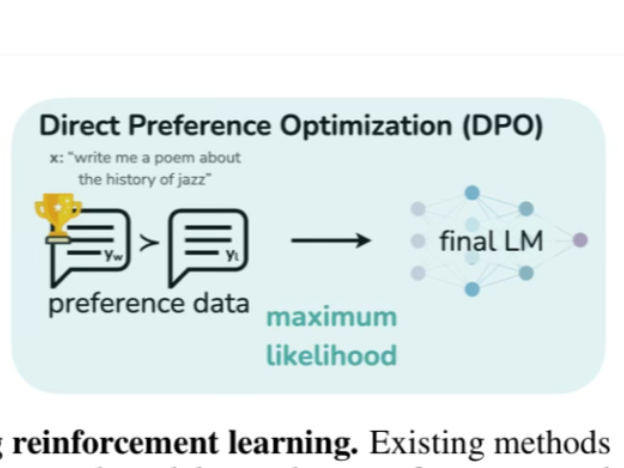
This paper provides a simple and stable alternative to RLHF for aligning Large Language Models with human preferences called "Direct Preference Optimization" (DPO). They reformulate the loss function as a classification task between prompt completions and show that they can get competitive performance without adding the complexity of the reward model and reinforcement learning.
Paper: https://arxiv.org/abs/2305.18290
Team: Stanford
Publish Date: May 29th, 2023
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session. Many thanks to the community asking great questions along the way. Feel free to watch the video and follow along for the full context.
Why is this paper important?
Large Language Models that are trained on large datasets of text have been shown to acquire a surprising set of capabilities. Whether it is to be an AI coding assistant, or a creative writing assistant, we want the model to understand a wide variety of knowledge.
The authors state that we want LLMs to understand the nuances of language and that there can be multiple valid responses to a single prompt.
When writing code there is excellent code that compiles and runs, as well as what poor inefficient code looks like that runs and gives the same output. Both are technically valid, one is just better than the other. When performing creating writing we want the model to be aware of common misconceptions believed by 50% of people, but we do not want it to claim this misconception to be true.
We want to build AI systems that follow our preferences so that they are safe, performant and controllable. DPO provides a simple classification loss for going from a model that knows a lot, to a model that behaves how humans want it to.
Zero to ChatGPT
In order to understand where DPO fits in, and why people are excited about it, let's look at the steps it takes to create a system like ChatGPT.
- Unsupervised pre-training (done by big company with lots of $, think LLama-2, Mistral, etc)
- Supervised Fine Tuning (can be done by you, tailored to your use case)
- Reinforcement learning from human feedback (RLHF) (can be done by you, but is hard)
- Requires a reward model
- Requires PPO optimization
DPO replaces step 3, making it easier to understand and more stable to train, all while maintaining or beating performance of RLHF. If you are curious about prior work and background on RLHF, we did a previous dive on InstructGPT that goes over the basics.
 Greg Schoeninger
Greg Schoeninger
Replacing RLHF with DPO
If we were to break down the total number of models required for end to end RLHF, we see you end up copying and modifying the base model four times.
- Pre-Trained Base LLM
- Supervised Fine Tuned (SFT) LLM
- Reward Model (LLM, but modified to be a reward model)
- PPO Optimized Language Model (Final LLM aligned to preferences)
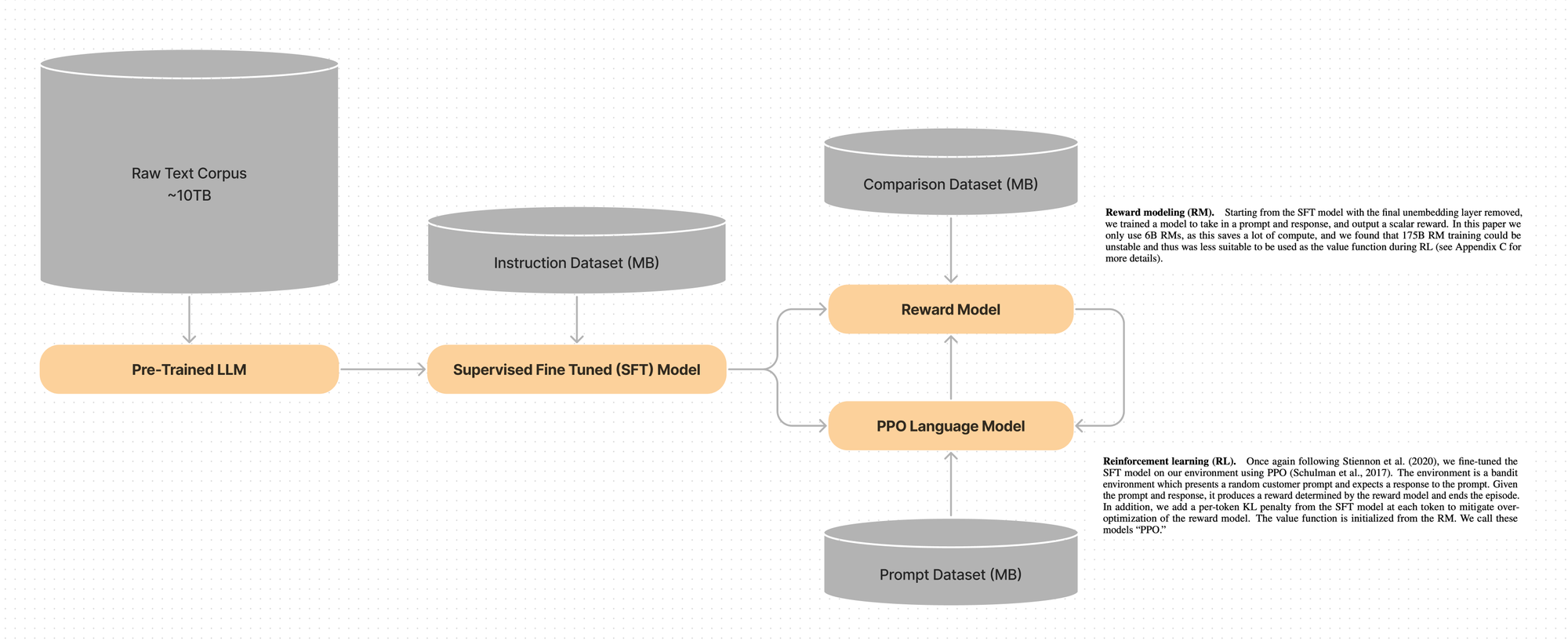
Each time you perform one of these steps, you are copying all the parameters and modifying them with some sort of training loop. This means if you want to do end to end RLHF with PPO for a 7B parameter model, each taking up ~14GB represented as f16, you will end up with four artifacts of a total of ~56GB of parameters.
The Reward Model is simply the SFT model copied, and modified so the un-embedding layer is removed, and a scalar reward head is added. The PPO model is also a copy of the SFT model, where the parameters will be updated to align with human preferences.
DPO simplifies this process by removing the reward model all together.
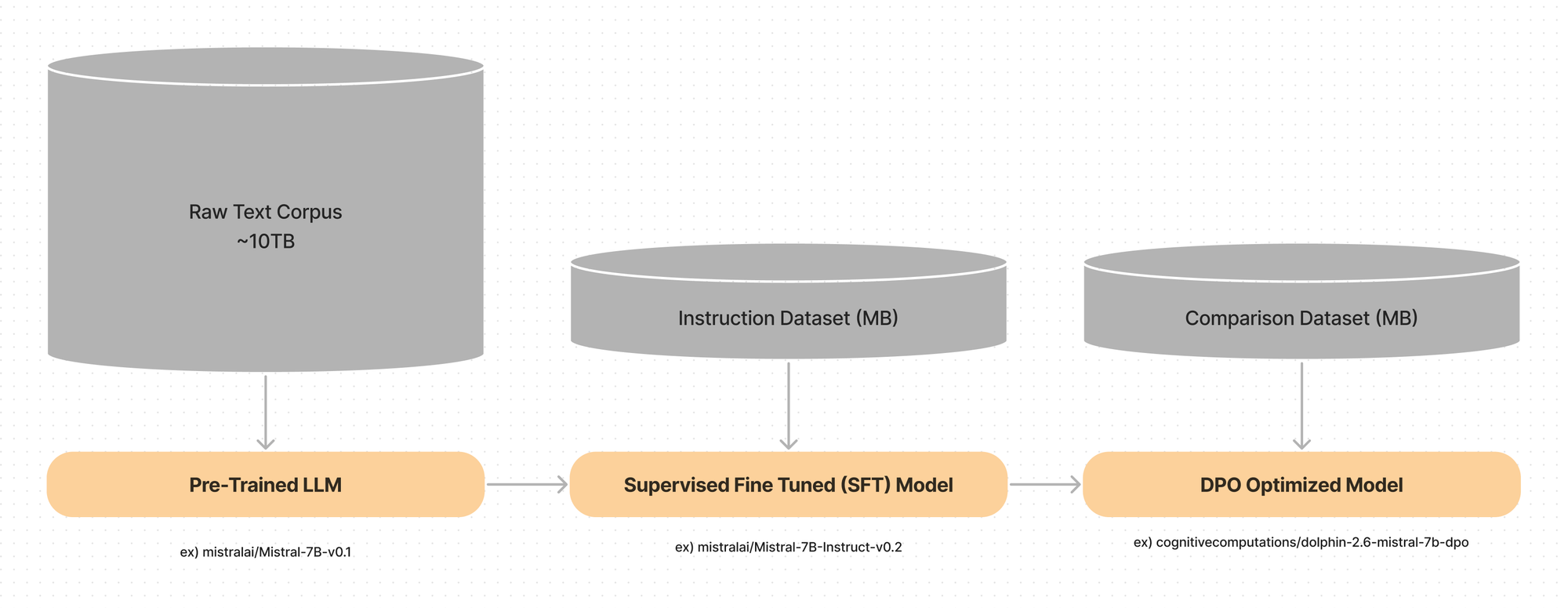
They instead feed a comparison dataset directly to the final model by modifying the loss function of the final step.
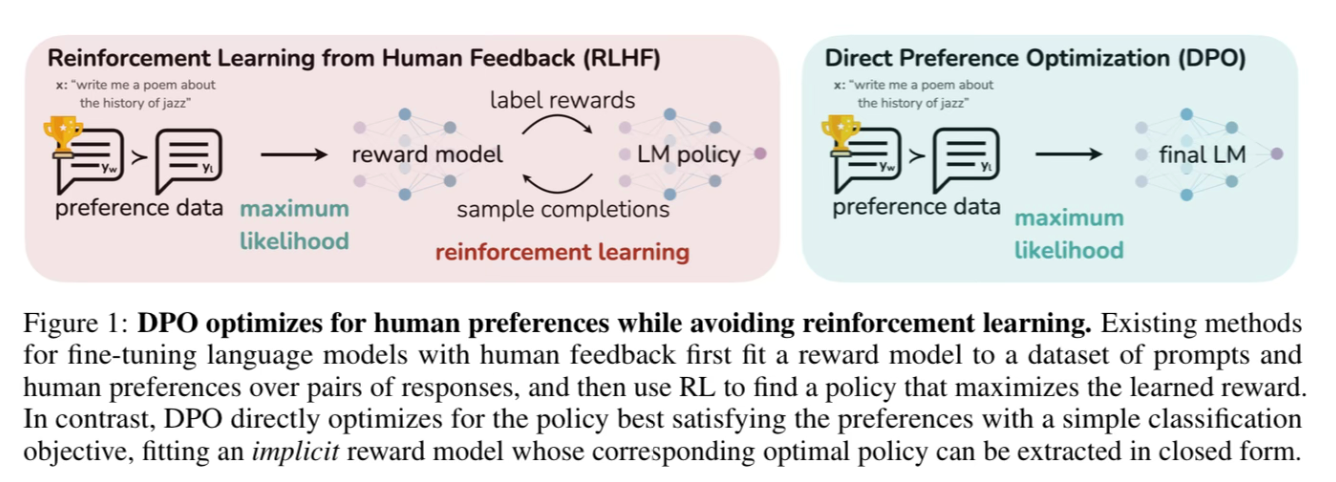
This is a great example of removing dependencies, and how keeping it simple can lead to better reseults.
Let’s Get Lost in The Loss Function 🕵️♂️
To understand fully the magic behind DPO, we must dive into the math. The loss function is the most important part of the paper. The paper states you can replace RL with “a simple classification loss”. Let’s see what that actually means in practice.
Scan the paper, and skip all the derivations until you get to section 4, equation 7.
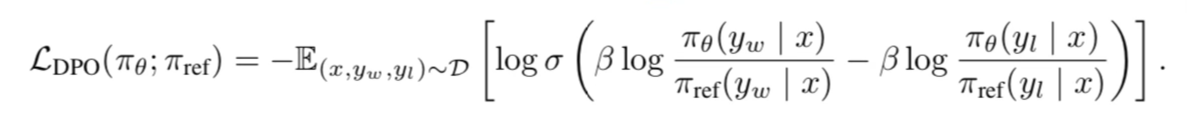
If you hit this section and said "it looks like Greek to me", you are in the right place. Let's try to explain what is going on here in plain english.
Loss is the measure of how well our model is doing, given the data. At the end of the day if we can minimize the loss, we are winning. Let’s start with a simplified version of the equation that has a winner (W) and a loser (L).
Loss = W - LIn our case the winner will be the text completion that we labeled as 👍 and the loser will be the text completion we labeled as 👎.
Prompt (X):
Oxen.ai’s data version control …
👍 W = Oxen.ai’s data version control gives you visibility into changes into your data over time with simple easy to remember commands and workflows that mirror git.
👎 L = Oxen.ai’s data version control is hard to learn because they throw a bunch of new lingo at you.
If we were training a language model at Oxen.ai, we would prefer the first completion and give it the thumbs up.
Back to the math, if we get a high score for W and a low score for L, W - L will be a large number. Usually you want to minimize loss so they slap a negative sign on the start of the equation.
Loss = -(W - L)Although the full equation above looks more complicated with logs and beta's and sigmas and pi's at the end of the day we are trying to have a high score for W and a low score for L.

At a high level this is a simple binary cross-entropy objective, and similar to what you learn in machine learning 101 when learning about classification loss functions.
Now let’s break it down a little further.
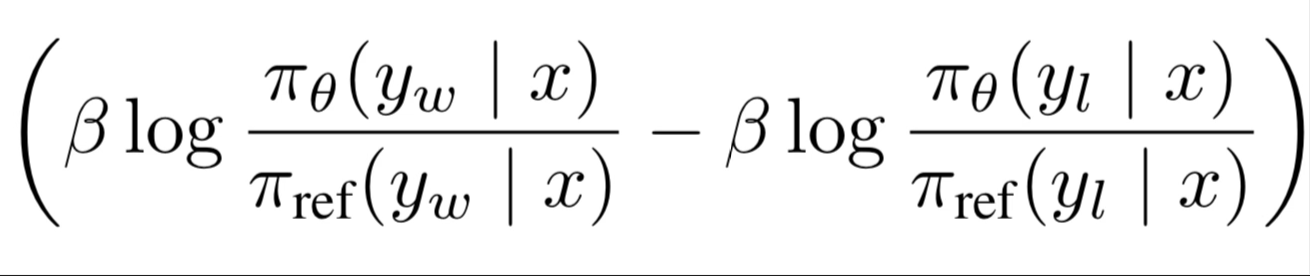
What are these pi’s, ys, and xs doing in here?
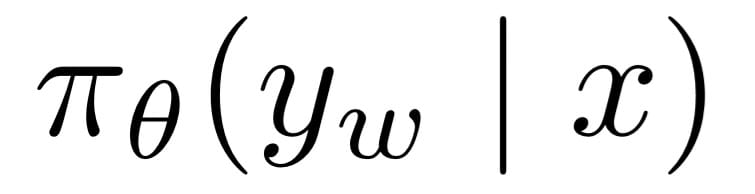
In this expression x is the prompt, y_w is the completion, and pi_theta is the language model. It can be read as the probability of the winning completion, given a prompt.
Looking at our example above, the probability of the winning completion would the sum of the probabilities of each token predicted.
Prompt: Oxen.ai’s data version control …
👍 W = gives (0.8) you (0.9) visibility (0.8) into (0.4) changes (0.75) …
👎 L = is (0.6) hard (0.2) to (0.4) learn (0.5) because (0.8)
0.8 + 0.9 + 0.8 + 0.4 + 0.75 should give you a higher total probability for W than L
In practice you use log probabilities for numerical stability, but you can think of the probability of the entire sequence as the sum of all its parts.
On the other side we have y_l and the probability of the losing completion given the same prompt.
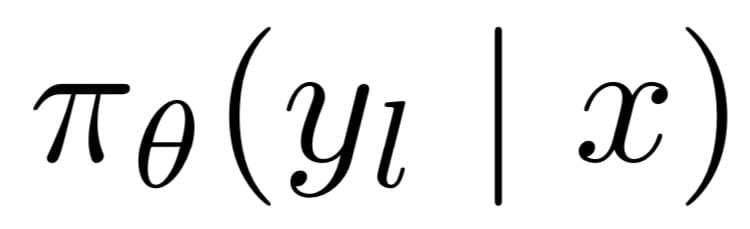
Hopefully you start to see a pattern in the equation. Probabilities of the winners minus losers.
Okay. Now that we understand the inner most terms, let’s zoom back out. We have our pi_theta divided a pi_ref.
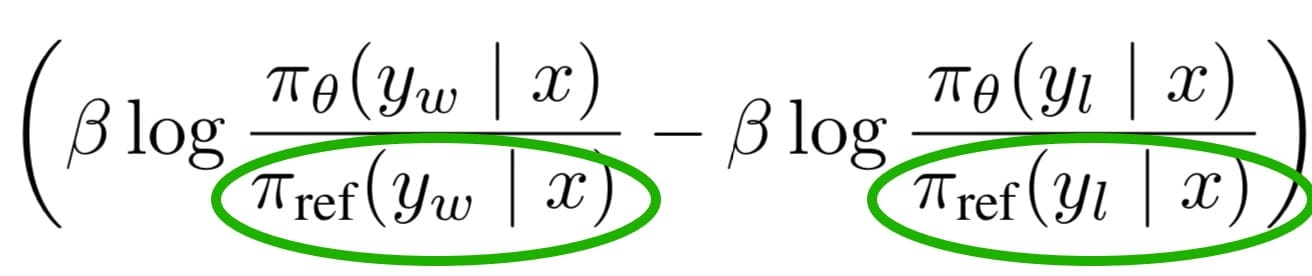
pi_theta is the simply the language model we are training. pi_ref is the pre-trained language model we have already learned.
The reason they divide by the "reference model" is to make sure your DPO trained language model does not deviate too far from the knowledge of the original model. The pre-trained model has already learned a lot about the world, and we do not want to overfit to the just the preference data. They state that pi_theta and pi_ref are both initialized to the Supervised Fine Tuned (SFT) model.
You will often hear the drift between two distributions called the KL Divergence. This equation uses the KL Divergence so that the probability of y_w (winner) given the input x is high from the original language model, we want it to also be high from the new language model.
Overall we have the probability of the winning completion, minus the probability of the losing completion. Then we divide by the probability of the pre-trained reference language model in the denominator as regularization.
One more look at the full thing now that you have seen the individual parts.
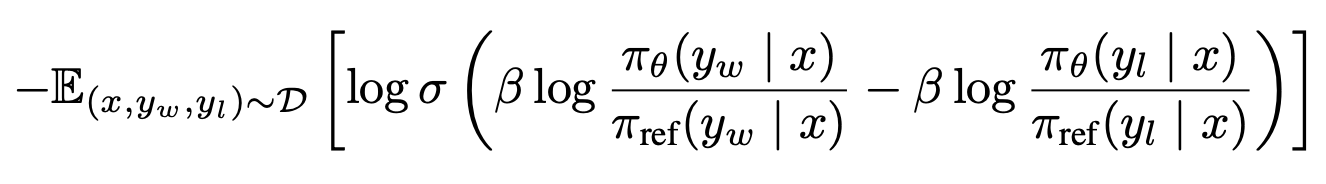
Squinting your eyes and assuming the beta and log and sigmoid are well chosen hyper parameters for numerical stability, I hope this helps you gain an intuition how this loss function would score a pair of completions. At it's core it is a binary cross-entropy loss function with additional parameters inside.
Putting It All Together
Now that we understand the loss equation better, the full DPO pipeline is relatively straightforward.
- Sample two completions from our reference language model given a prompt
x. - Optimize our new language model through backprop to
pi_thetato minimize our loss.- The model gets rewarded if the completion
y_whas a higher probability thany_l. - The model gets rewarded if the completions of W and L are close to the pre-trained model
pi_ref'scompletions.
- The model gets rewarded if the completion
Experiments
In the paper they run a few different experiments to compare DPO to PPO and RLHF.
Sentiment Generation
For this task, the prompt x is a prefix of a movie review from the IMDB dataset and the policy must generate a completion Y with positive sentiment. They are seeing if they can align a language model to only generate completions with positive sentiment.
X: Iron man was ...
Y_W: the best movie of all time because ...
Y_L: the worse marvel movie I think I have ever seen ...
First they performed supervised fine tuning on GPT-2-L on the train split of the IMDB dataset, so that the model would generate text that looks like movie reviews. Then they use a pre-trained sentiment classifier to generate the labeled preference dataset. This was then the dataset they evaluated DPO on.
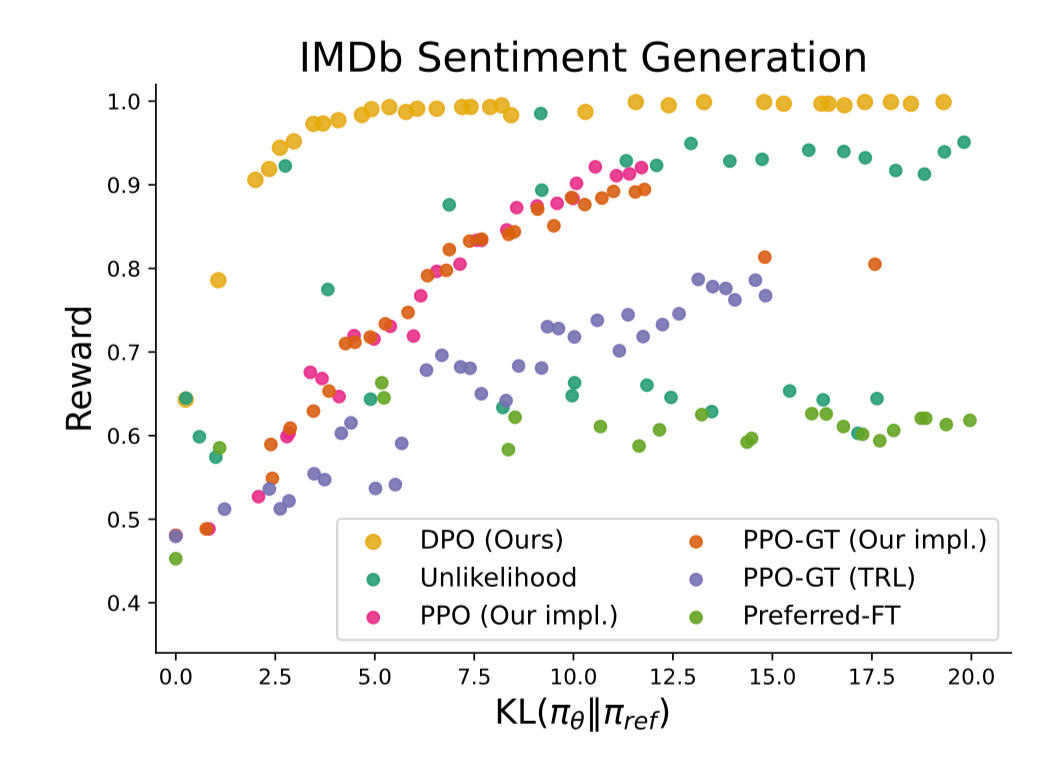
The graph they present in the paper shows how the model generates a bunch of positive sentiment sentences (high reward) across a variety of KL divergence scores. They ran a suite of 22 different hyper parameter settings to generate this data for different types of models. (Section 6.1)
The takeaway is that DPO provides the highest alignment to preferences across completions that vary in probability distribution from the original reference model.
Summarization
For this task they take a forum post from reddit as the input X, then the policy must generate a summary Y of the main points in the post.
They use the Reddit TL;DR summarization dataset for this experiment along with human preferences already gathered.
Again, first perform supervised fine tuning on the reddit responses to learn to generate summaries. Then they used Anthropic’s Helpful and Harmless dialogue dataset containing 170k dialogues between a human and an assistant to align the model with human preferences.
In order to evaluate the summarizations they use GPT-4 as the evaluator across a variety of temperature settings.
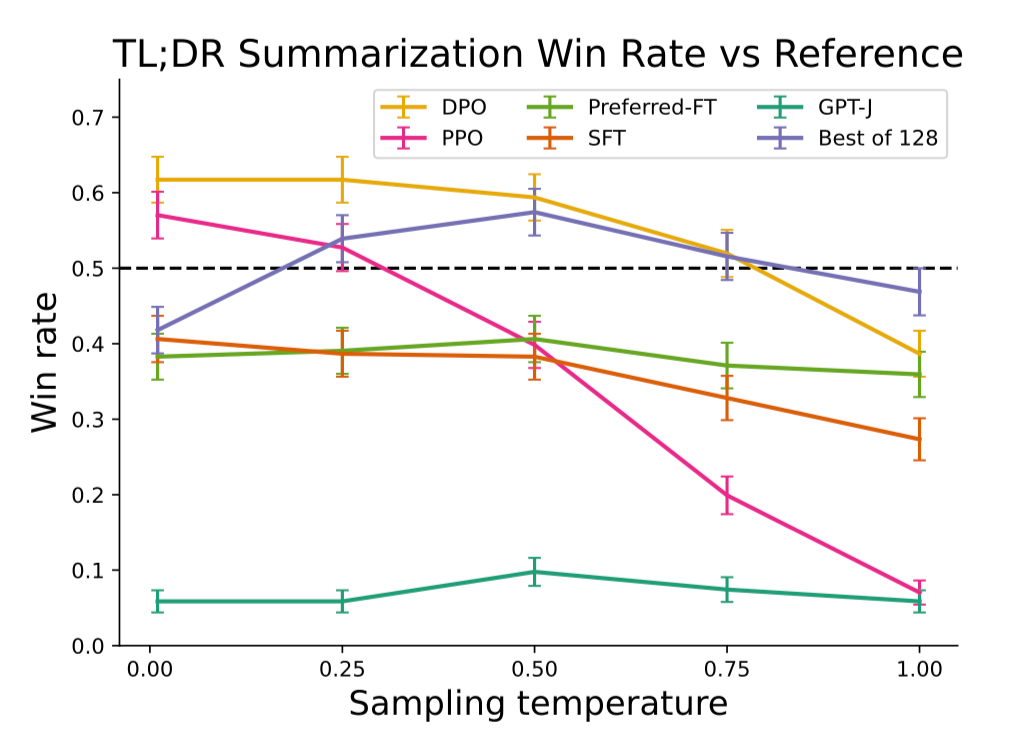
You can see that DPO exceeds PPO and pure SFT in summarization while being more robust to changes in temperature.
In order to justify usage of GPT-4 for evaluation, they conduct a study comparing it to human evaluators.
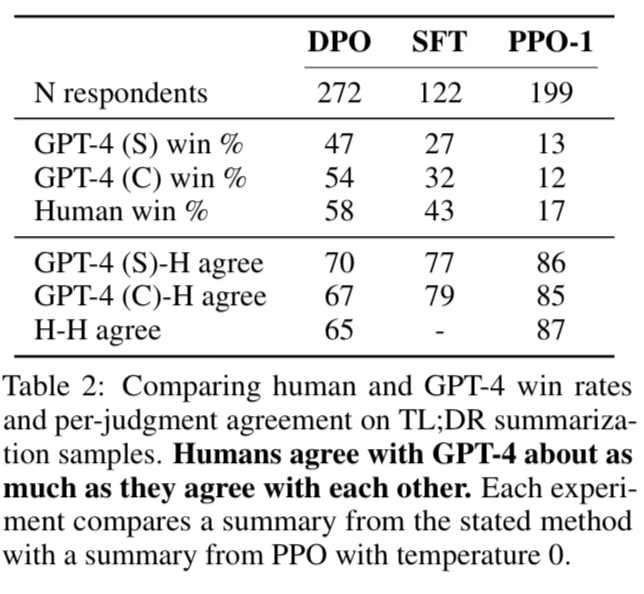
(S) stands for simple prompt which asks which summary is better
(C) stands for concise prompt which asks which summary is more concise.
GPT-4 tends to agree with humans about as often as humans agree with each other, suggesting that GPT-4 is a reasonable proxy.
Conclusion
DPO is exciting because it reduces the overhead of taking a model from a pretty good SFT model, to a high quality model aligned with your preferences. They propose DPO as an alternative to RLHF that was introduced in the InstructGPT paper by OpenAI, and it is really cool to see what academia can improve on given limited resources.
An open question at the time of publishing was how well this scales to larger models - in the paper they only trained models up to 6B parameters. Since the release of the paper, we have seen many open source models use DPO with great success.
It also remains to be seen how well DPO can generalize to out of distribution data. People are starting to experiment with using DPO as a self-play technique to see if you can improve a language model simply by sampling from it, and asking it to access it’s own outputs. We will dive into some of these self-play papers in upcoming ArXiv Dives!
Next Up
To find out what paper we are covering next and join the discussion at large, checkout our Discord 👇

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.

The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI