Reading List For Andrej Karpathy’s “Intro to Large Language Models” Video

Andrej Karpathy recently released an hour long talk on “The busy person’s intro to large language models” that had some great tidbits whether you are an expert in machine learning or just getting starting in AI.
There are a lot of resources, papers, and concepts mentioned in the hour long session, so I thought it would be useful to capture them all into a reading list that one could work through to read more about every topic he touched on.
You can find the full talk here:
Intro to Large Language Models
I recommend first watching the video before diving into the reading list. Andrej does a great job of breaking down complex topics and making them understandable.
If you want to go even deeper, we go over these papers on Fridays in a group called Arxiv Dives, so feel free to join our discussion or hop in the Discord channel to recommend any papers we missed.

There are two halves to the talk, the first half goes over some background and fundamentals of LLMs and the second half talks about future research and an LLM OS he proposes.
Background Reading
The first half of the video, Andrej goes over some fundamentals of how LLMs are trained and can be run in practice today.
Understanding the core technology and techniques behind training and running these models is important to building up a higher level understanding of how he pictures using them in an LLM OS later in the talk.
We have gone over a lot of these topics already in Arxiv Dives, so I will link to the recaps for context while reading the papers that can be a bit technical.
Attention Is All You Need
This is the foundational paper that introduced transformers, which are the core neural network architecture behind the state of the art large language models today.
Paper: https://arxiv.org/abs/1706.03762
Arxiv Dive: https://blog.oxen.ai/arxiv-dives-attention-is-all-you-need/
Language Models are Unsupervised Multitask Learners (GPT-2)
Early version of GPT that was starting to show how unsupervised learning to predict the next word could lead to learning tasks they weren’t explicitly trained on.
Arxiv Dive: https://blog.oxen.ai/arxiv-dives-language-models-are-unsupervised-multitask-learners-gpt-2/
Training Language Models to Follow Instructions (InstructGPT)
The tech behind going from GPT-3 to ChatGPT, covers fine tuning, RLHF, and aligning language models.
Paper: https://arxiv.org/abs/2203.02155
Arxiv Dive: https://blog.oxen.ai/training-language-models-to-follow-instructions-instructgpt/
Llama-2
This paper goes over the Llama-2 model he mentions at the start of the video, which builds off of the research of the above two papers, but open sources the weights of the models for other people to fine tune and extend.
Paper: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models
Arxiv Dive: https://blog.oxen.ai/arxiv-dives-how-llama-2-works/
Running an LLM locally
At the beginning he talks a lot about all you need is ~500 lines of C code and the model weights. Here are a few links to example code and a tutorial of how to fine tune and run a model locally.
- Llama.cpp code: https://github.com/ggerganov/llama.cpp
- Andrej’s code: https://github.com/karpathy/llama2.c/blob/master/run.c
- Tutorial: https://blog.oxen.ai/how-to-run-llama-2-on-cpu-after-fine-tuning-with-lora/
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Human annotation is often the bottleneck in the final steps of training and aligning LLMs. RLAIF uses existing LLMs to help label data faster than you could with humans to get similar results.
Paper: https://arxiv.org/abs/2309.00267
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
DPO is proposed as as a more stable alternative to RLHF. DPO is stable, performant and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning.
Paper: https://arxiv.org/abs/2305.18290
Training Compute Optimal Language Models
Research on the number of parameters in a language model vs amount of training data used. Shows that scaling up the number of parameters and size of data consistently gives us “more intelligence for free”
Paper: https://arxiv.org/abs/2203.15556
Scaling Laws for Neural Language Models
Another paper studying the ratio between number of parameters, dataset size, and compute needed to train large language models.
Paper: https://arxiv.org/abs/2001.08361
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Investigation and studies of an early version of GPT-4 by OpenAI. If you train a bigger model for longer, it improves in its ability on a variety of tests traditionally seen as very difficult for humans such as the LSAT, AP Placement Tests, the SAT, etc.
Paper: https://arxiv.org/abs/2303.12712
Future Developments in LLMs
In the second half of the talk, Andrej dives into areas of research that the field of AI is broadly interested in. Then he introduces what he calls an LLM OS where he argues LLMs should not be thought of as a ChatBot or some kind of a “work generator”. Instead LLMs should be of as the kernel process of an emergent operating system.
If we think of an LLM as an operating system, we also have to think about all the vulnerabilities that may arise when using it. He lists off many interesting attack vectors that LLMs expose in the final section.
System One vs System Two Thinking
Thinking Fast and Slow
Daniel Kahneman describes a framework of thought with two systems. System 1 is fast, intuitive, and emotional; System 2 is slower, more deliberative, and more logical.
Book: https://www.amazon.com/Thinking-Fast-Slow-Daniel-Kahneman/dp/0374533555
Mastering the game of Go with deep neural networks and tree search
This is the AlphaGo paper which was the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.
Paper: https://www.nature.com/articles/nature16961
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
This paper shows that generating a set of intermediate reasoning steps increases the ability of LLMs to perform complex reasoning.
Paper: https://arxiv.org/abs/2201.11903
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
This paper looks at more system 2 type thinking with language models that involves more exploration, strategic look ahead or planning. You may be able to trade time for accuracy with this type of problem solving.
Paper: https://arxiv.org/abs/2305.10601
System 2 Attention (is something you might need too)
They add a second attention step to help the LLM decide what to attend to. This regenerates the input context to only include the relevant portions, before attending to the regenerated context to elicit the final response.
Paper: https://arxiv.org/abs/2311.11829
LLM OS
The LLM Operating System is best visualized with the diagram from the talk.
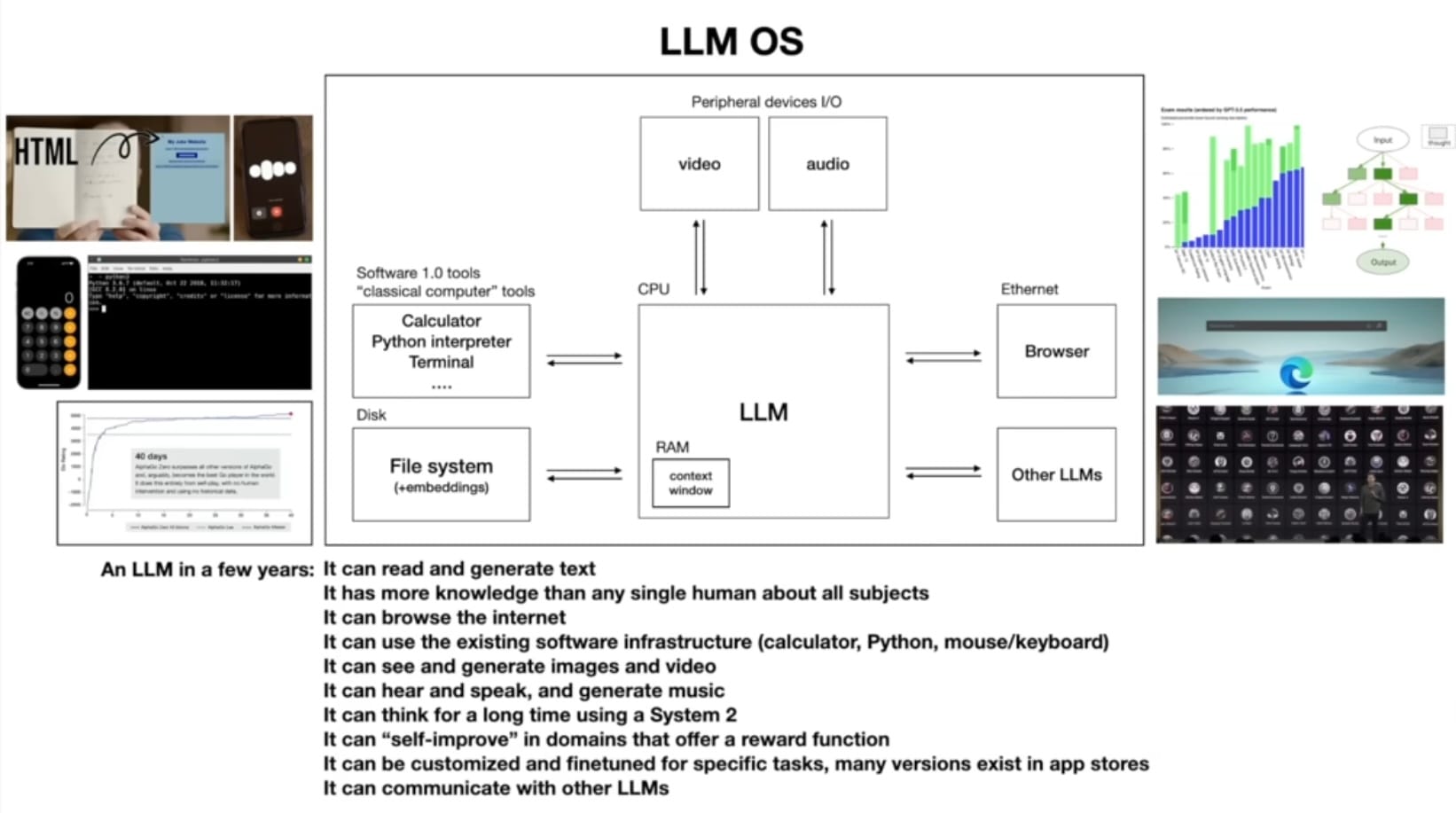
You can think of an LLM as a process that is coordinating memory and tool use for general problem solving. Memory could be prompts and contexts windows swapping out what information is currently being processed. Tools could be anything from a web browser to python code to a calculator.
He does not explicitly mention any papers in this section but here are a few that are good jumping off points for each of the components of the diagram above.
If anyone else knows of any more papers that could tie nicely to the LLM OS, please add them to our #paper-candidates in Discord!
Disk / File System
These papers are examples of the bottom left of the LLM OS diagram for how the LLM can interact with local documents or databases.
Retrieval Augmented Generation (RAG)
In the diagram above, the disk or filesystem needs to be able to retrieve context from local files in order to give the LLM additional information to make informed predictions and decisions. RAG helps find and retrieve relevant documents and inject them into a prompt to help answer questions.
Paper: https://arxiv.org/abs/2005.11401
Arxiv Dive: https://blog.oxen.ai/arxiv-dives-rag/
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP
A framework for RAG that helps with knowledge intensive tasks from the NLP teams at Stanford.
Paper: https://arxiv.org/abs/2212.14024
Multi-Modal Peripheral Device I/O
The following papers are for the top middle of the LLM OS Diagram and can be thought of as the peripheral input and outputs in the form of audio, video, images, etc of the OS. We as humans understand navigating the world through high level signals like videos and audio, so converting them to an embedding space that the LLM can understand is important.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train. This is important fundamental reading to build on Text-Image research like CLIP below.
Paper: https://arxiv.org/abs/2010.11929
CLIP - Learning Transferable Visual Models From Natural Language Supervision
CLIP’s helps map data of different modalities, text and images, into a shared embedding space. This shared multimodal embedding space makes text-to-image and image-to-text tasks much easier, and is the base for models like StableDiffusion
Paper: https://arxiv.org/abs/2103.00020
ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding
Combining 2D with 3D representations can help 3D models which usually suffer from lack of data.
Paper: https://arxiv.org/abs/2212.05171
NExT-GPT: Any-to-any multimodal large language models
They connect an LLM with multimodal adaptors and different diffusion decoders, enabling NExT-GPT to perceive inputs and generate outputs in arbitrary combinations of text, images, videos, and audio.
Paper: https://next-gpt.github.io/
LLaVA - Visual Instruction Tuning
In this paper, they present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, they introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
Paper: https://arxiv.org/abs/2304.08485
LaVIN - Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
In this paper, they propose a novel and affordable solution for the effective visual language adaption of LLMs, called Mixture-of-Modality Adaptation (MMA).
Paper: https://arxiv.org/abs/2305.15023
CoCa: Contrastive Captioners are Image-Text Foundation Models
This technique helps bridge the multimodal gap between language models and images and is key for generative image techniques or “peripheral device io” in the diagram above.
Paper: https://arxiv.org/abs/2205.01917
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
State-of-the-art text-to-video generation, also on the peripheral device side of the diagram.
Paper: https://arxiv.org/abs/2311.10709
Tool Use, Software 1.0, Web Browsing, etc
LLMs on their own are not great at performing tasks that we have already written software for such as calculators. Just because the probability of one number following another is high does not mean it is the correct number.
For this reason we need our LLMs to be able to call external tools within their execution. Below are some papers that explore tool usage with LLMs.
Toolformer: Language Models Can Teach Themselves to Use Tools
Shows how LLMs can use tools to augment their abilities in areas where simply predicting the next word does not perform that well.
Paper: https://arxiv.org/abs/2302.04761
Large Language Models as Tool Makers
Abbreviated LATM - Google Deepmind shows not only how LLMs can use tools, but how they can create them in the first place.
Paper: https://arxiv.org/abs/2305.17126
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
They train a ToolLlama that can execute complex instructions and generalize to unseen APIs
Paper: https://arxiv.org/abs/2307.16789
Jailbreaking LLMs and Security
Just like there are attack vectors in traditional operating systems. LLMs open up a whole new set of exploits ranging from inappropriate responses to phishing attacks to stealing user data through remote function calls.
Below are papers that explore existing attack vectors and ones that may have already been solved for. The main take away is that the same cat and mouse game that exists with traditional software in security will exist in the world of LLMs as well, in a new way.
Jailbroken: How Does LLM Safety Training Fail?
This paper studies many different types of jailbreaks or vulnerabilities in LLMs
Paper: https://arxiv.org/abs/2307.02483
Universal and Transferable Adversarial Attacks on Aligned Language Models
They find a suffix that can be appended to a language model that will allow it to generate objectionable behaviors and produce an affirmative response even if the model was aligned to not behave in this fashion.
Paper: https://arxiv.org/abs/2307.15043
Visual Adversarial Examples Jailbreak Aligned Large Language Models
They show that you can construct images in a way that encode information that an LLM will decode and behave in ways that were unintended from the alignment work.
Paper: https://arxiv.org/abs/2306.13213
Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection
This shows a lot of prompt injection attacks that could be placed into web pages that LLM reads to instruct them to behave in unintended ways.
Paper: https://arxiv.org/abs/2302.12173
Hacking Google Bard - From Prompt Injection to Data Exfiltration
This blog post shows how the use of extensions and tools in Google Bard can lead to personal data being extracted from other places from your google account or ecosystem.
Blog: https://embracethered.com/blog/posts/2023/google-bard-data-exfiltration/
Poisoning Language Models During Instruction Tuning
Datasets are often constructed from users using an LLM. This work shows how you can contaminate a dataset with examples to trigger models to not perform as well as intended.
Paper: https://arxiv.org/abs/2305.00944
Poisoning Web-Scale Training Datasets is Practical
This paper shows how you could poison a large scale pretraining dataset with knowledge or behavior that is malicious or could hurt model performance for just $60 USD
Paper: https://arxiv.org/abs/2302.10149
Conclusion
Hopefully this reading list gives anyone a good jumping off point to deepen their expertise in the growing field of large language models. If anything, this makes it very clear to me that we are still in the early innings of this technology, and there is a lot of work to go.
I believe the best way to stay on the bleeding edge of these ideas and implement them into your products is to stay up to date with the research.
To stay up to date with Arxiv Dives or any other research from Oxen.ai follow us on Twitter or join our discord!
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.