
Arxiv Dives - Training Language Models to Follow Instructions (InstructGPT)
Join the "Nerd Herd"
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like to join us live, sign up here.
We are currently working our way through the Anti-hype LLM Reading List and deep diving on Large Language Models.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Training Language Models To Follow Instructions
More commonly known as InstructGPT or what eventually lead to ChatGPT.
From OpenAI, March 2022
Paper: https://arxiv.org/abs/2203.02155
GitHub with example data: https://github.com/openai/following-instructions-human-feedback/blob/main/model-card.md
ChatGPT was released November 2022, which was stated as a fine-tuned model from the GPT-3.5 series, using RLHF (the same method listed here).
Another reference mentioned at the end of the session was LLM Training: RLHF and Its Alternatives with some more info in fine tuning vs RLHF and other alternatives.
Abstract
Making language models bigger does not inherently make them better at following a user’s intent.
Just adding more unstructured data from web crawls does not make the models “aligned” with their users. (More on what alignment means later)
They collected a dataset from user input from the OpenAI API, which they use to fine tune GPT-3. Then they collect a dataset of ranked model outputs which they use to further fine tune with reinforcement learning.
They train a variety of models called InstructGPT which includes one with 1.3B which is 100x smaller than GPT-3 that has 175B parameters, but has outputs that are preferred to the 175B model.
This model shows improvements in truthfulness and reductions in toxic outputs, while having minimal performance degradation on public NLP datasets.
Introduction
We’ve seen how models can be prompted to generate different outputs, given some examples of the task at hand as input.
But the language model’s objective of predicting the next word of text, given a web crawl of data, is much different than the objective of “follow the user’s instructions, helpfully and safely”.
They call these initial language models “misaligned” and want to avoid unintended behaviors when deploying into your actual application.
They want to align the models to be:
- Helpful (solve the user’s task at hand)
- Honest (they should not fabricate information)
- Harmless (they should not physical, psychological, or social harm to people in the environment)
They hired a team of 40 contractors to label their data, and vetted the contractors via a screening test before letting them label.
Methodology
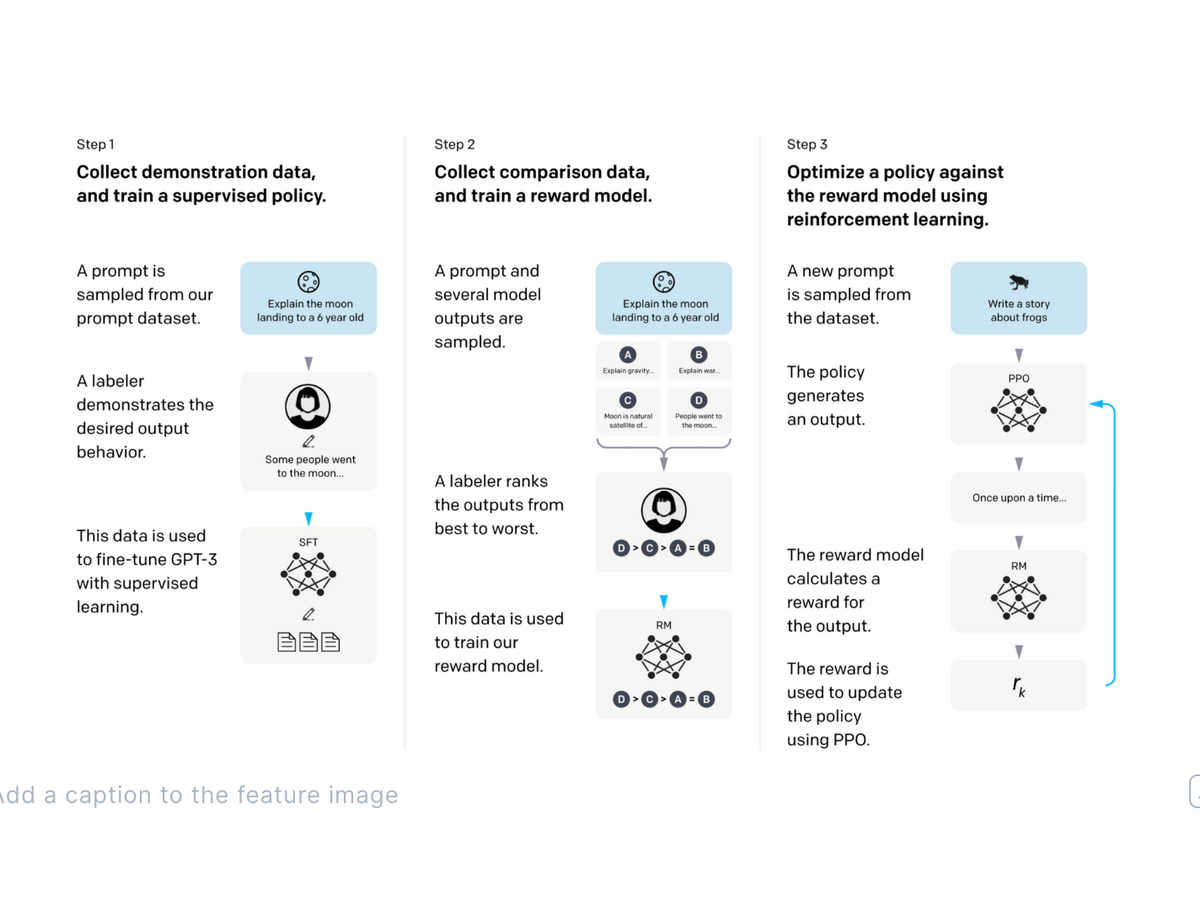
Training the model is a 3 step process, which I think is best described through the datasets below.
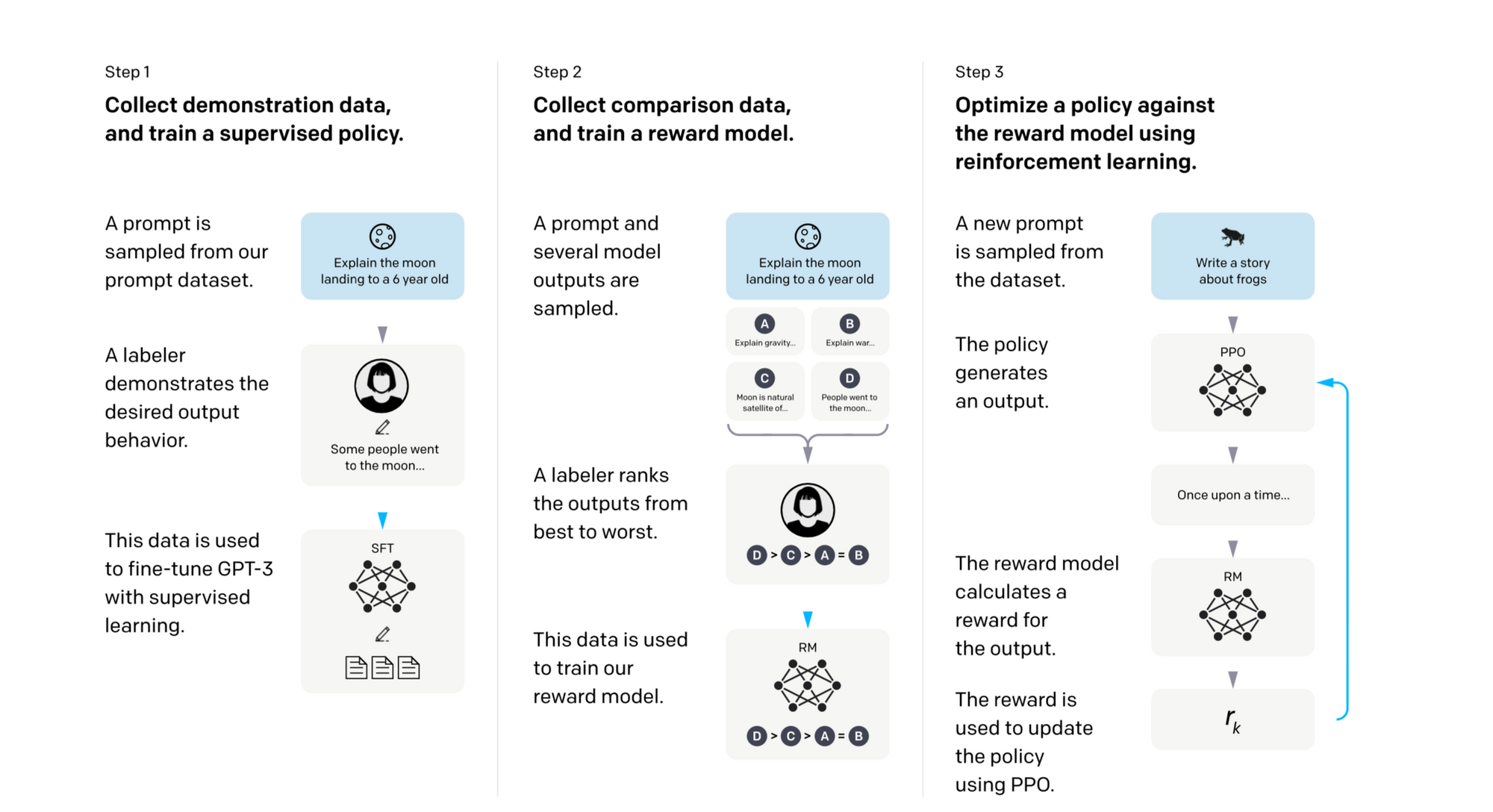
They created three datasets
- SFT Dataset Prompt -> Desired Behavior (from a human demonstrator/labeler)
- RM Dataset Prompt -> Several Model Outputs -> Rank best to worst
- PPO Dataset Prompt + Two Responses -> Predict which one human would prefer
Some example data points from each dataset may look like:
Supervised Fine Tuning (SFT)
{
"prompt": "write me a song about an ox plowing a field of data",
"response": "Surely! Here is a song about an ox plowing a field of data:\nOx go plow..."
}
Reward Model (RM)
{
"prompt": "write me a song about an ox plowing a field of data",
"responses": [
{
"text": "Ox go plow",
"ranking": 3
},
{
"text": "You got it! Ox go plow, make no sound, data so wow.",
"ranking": 1
},
{
"text": "Sure! Ox go plow",
"ranking": 2
}
]
}
Reinforcement Learning - Proximal Policy Optimization (PPO)
{
"prompt": "write me a song about an ox"
"response": "You got it! Ox go plow, make no sound, data so wow.",
"expected_reward": 1.0,
"predicted_reward": 0.8,
}
Evaluation
They train three models, all with the GPT-3 Architecture, of sizes 1.3B, 6B, and 175B.
Truthfulness - InstructGPT generates truthful and informative answers twice as often as GPT-3. On summarization and closed-domain QA, the hallucination rate drops from 41% to 21%.
Toxicity - On the RealToxicityPrompts dataset, Winogender dataset, & CrowSPairs dataset, InstructGPT generates 25% fewer toxic outputs when prompted to be respectful.
They note that during the RLHF fine tuning, the performance drops below GPT-3 on SQUAD question answering, DROP, HellaSwag, and WMT 2015 French -> English translation. They call this an “alignment tax”, but have some tricks to fix it later on.
They tested the following instruction capabilities in domains that were very rare in the training set, such as code generation, code summarization, and following instructions in different languages. They say qualitatively it does a much better job than GPT-3 which would require some careful prompting to get it to do these tasks, suggesting that it has generalized what it means to “follow instructions”.
Data Collection
Most of the examples in the dataset are for the text generation use case, but you can see the full distribution below, with some examples.
The collected the dataset mainly from the GPT-3 playground, but do not use data from the API used in production.
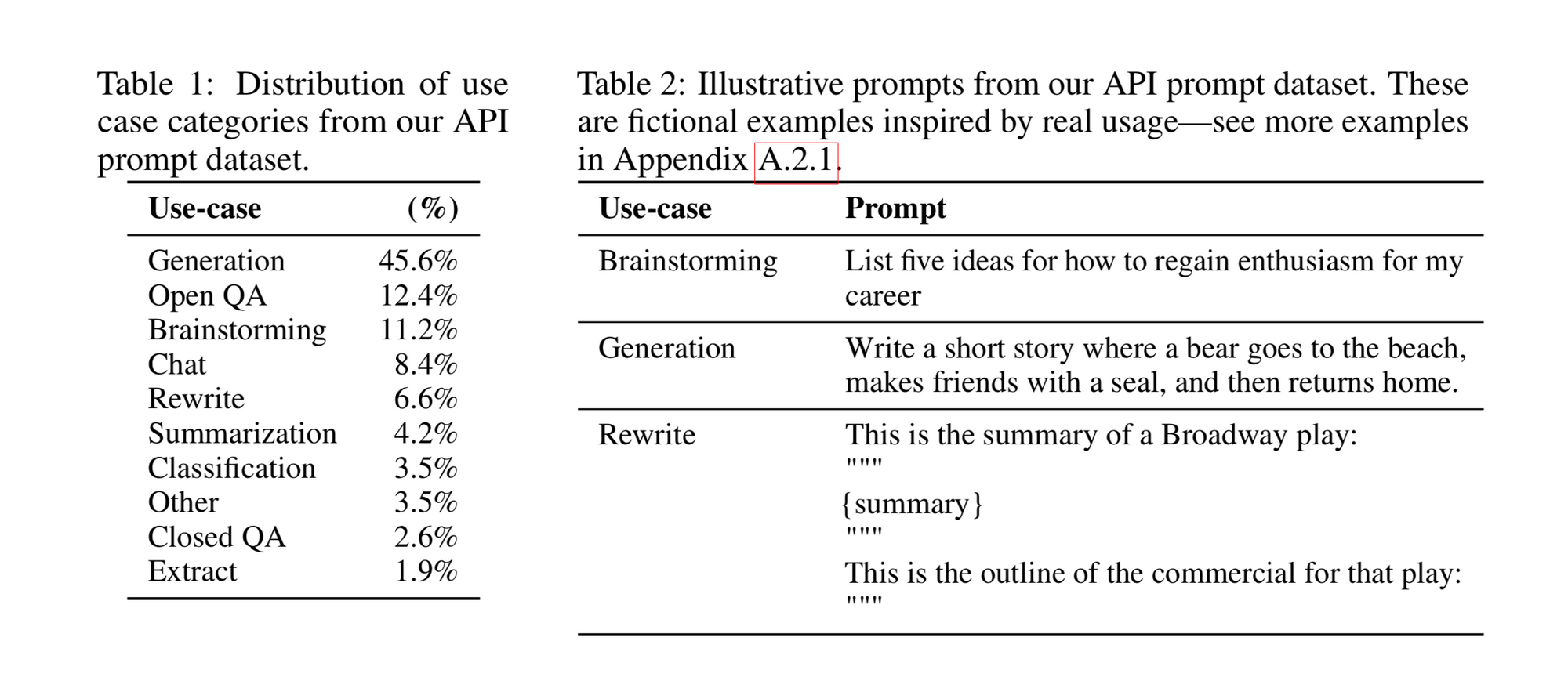
They deduplicate prompts that share a long common prefix, and limit the number of prompts to 200 per user ID.
They create the train, test, and valid splits based on User ID, so that the test sets are completely unique users.
They filter out all PII from the prompts in the training set.
Dataset Sizes
- SFT (supervised fine tuning) dataset with instructions from human labelers had 13k training examples
- RM (reward model) dataset with labeled outputs from humans A > B > C > D had 33k examples
- PPO (proximal policy optimization) dataset, generated without a human in the loop, 31k examples.
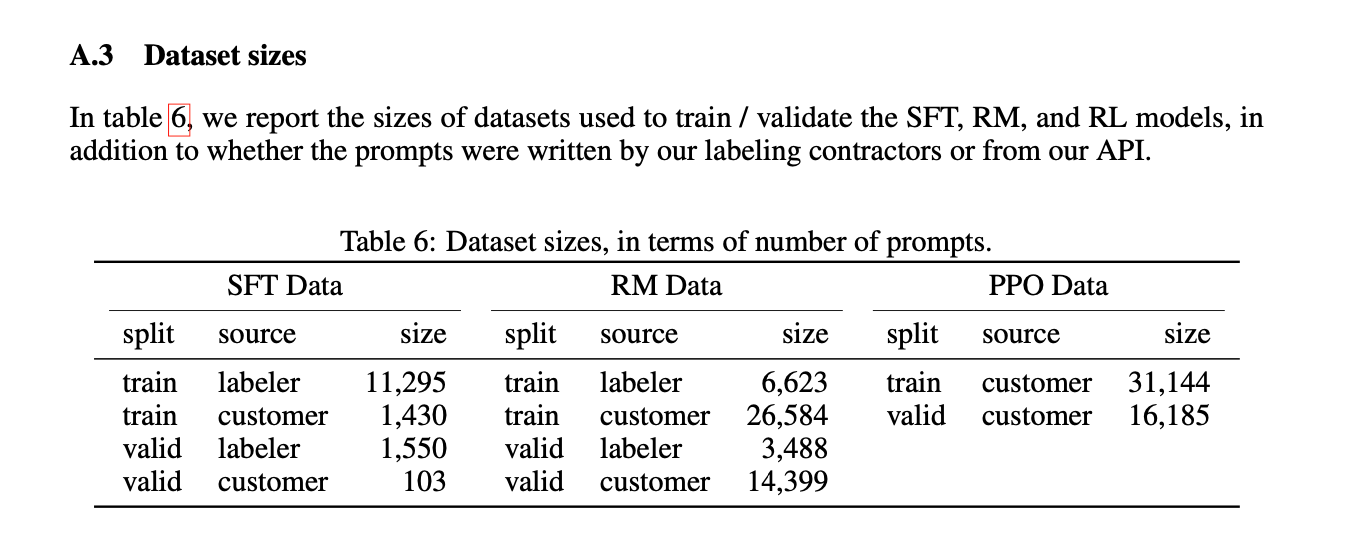
Datasets were 96% English language.
They screened and hired the labelers to be from different demographic groups, and vetted them to be able to detect potentially harmful outputs.
Inter-annotator agreement was quite high between labelers of 72-77% agreement depending on the train or the held out set.
Models
Most details from the papers going from GPT to GPT-2 to GPT-3 to InstructGPT are really about the data, and model size, and not the model architecture. You can see there is a one liner about model architectural changes.
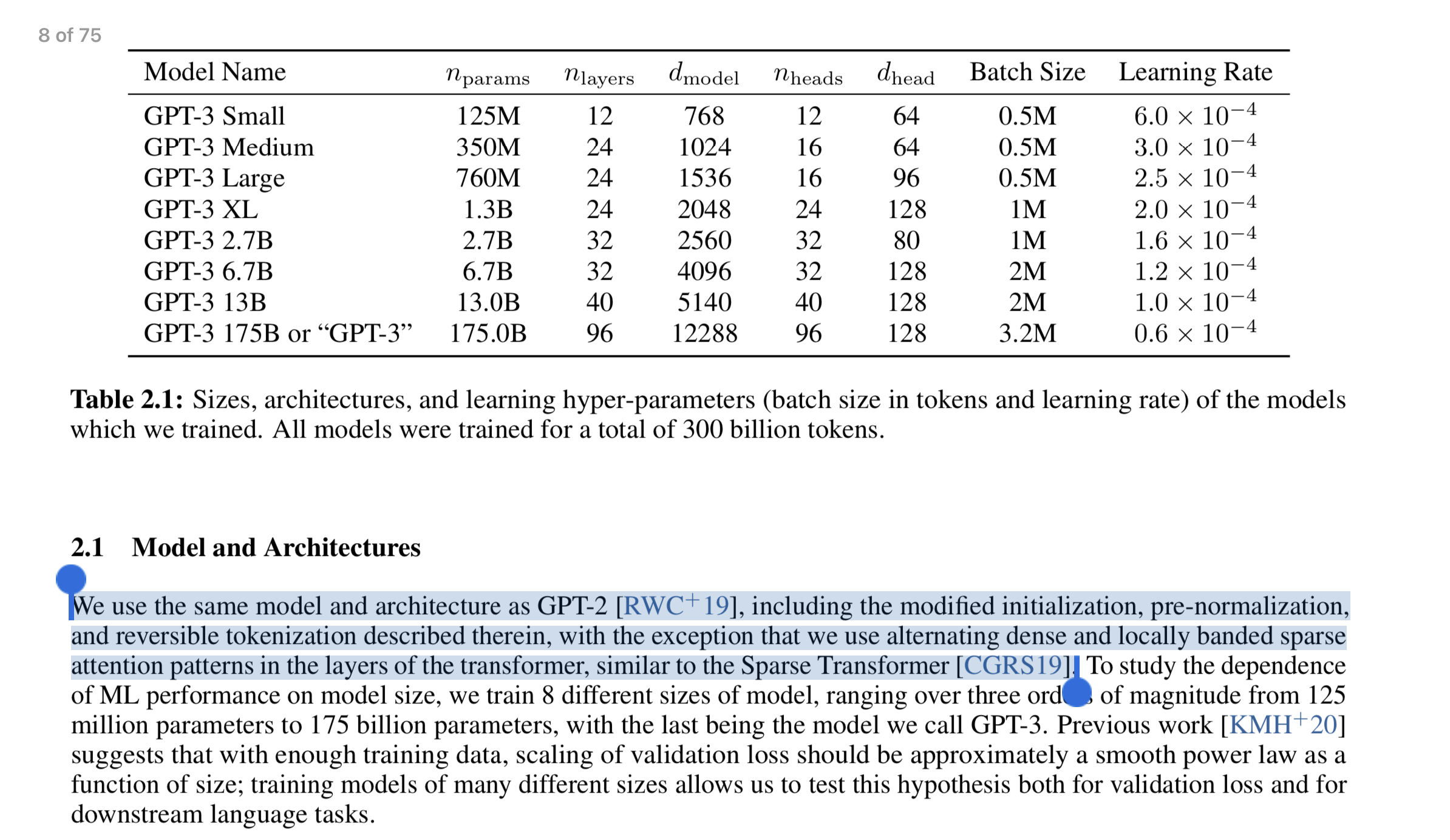
Base Model
We start with the GPT-3 pretrained language models from Brown et al. (2020). These models are trained on a broad distribution of Internet data and are adaptable to a wide range of downstream tasks, but have poorly characterized behavior. Starting from these models, we then train models with three different techniques:
Supervised Fine Tuning Model (SFT)
Trained for 16 epochs, with cosine learning rate decay, and residual dropout of 0.2. Trained on labeled human data of prompts to generate responses
Reward Model (RM)
Start from the SFT model, with the final layer removed, take a prompt and response pair and output a scalar reward. Just output a number.
They said the final reward model they went with was a 6B param GPT-3 model that was fine tuned on a variety of NLP datasets.
Reinforcement Learning (RL / PPO)
They fine-tuned the SFT model on our environment using PPO (Schulman et al., 2017). The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt. Given the prompt and response, it produces a reward determined by the reward model and ends the episode.
You can see the improvement in quality of each model given different model sizes.
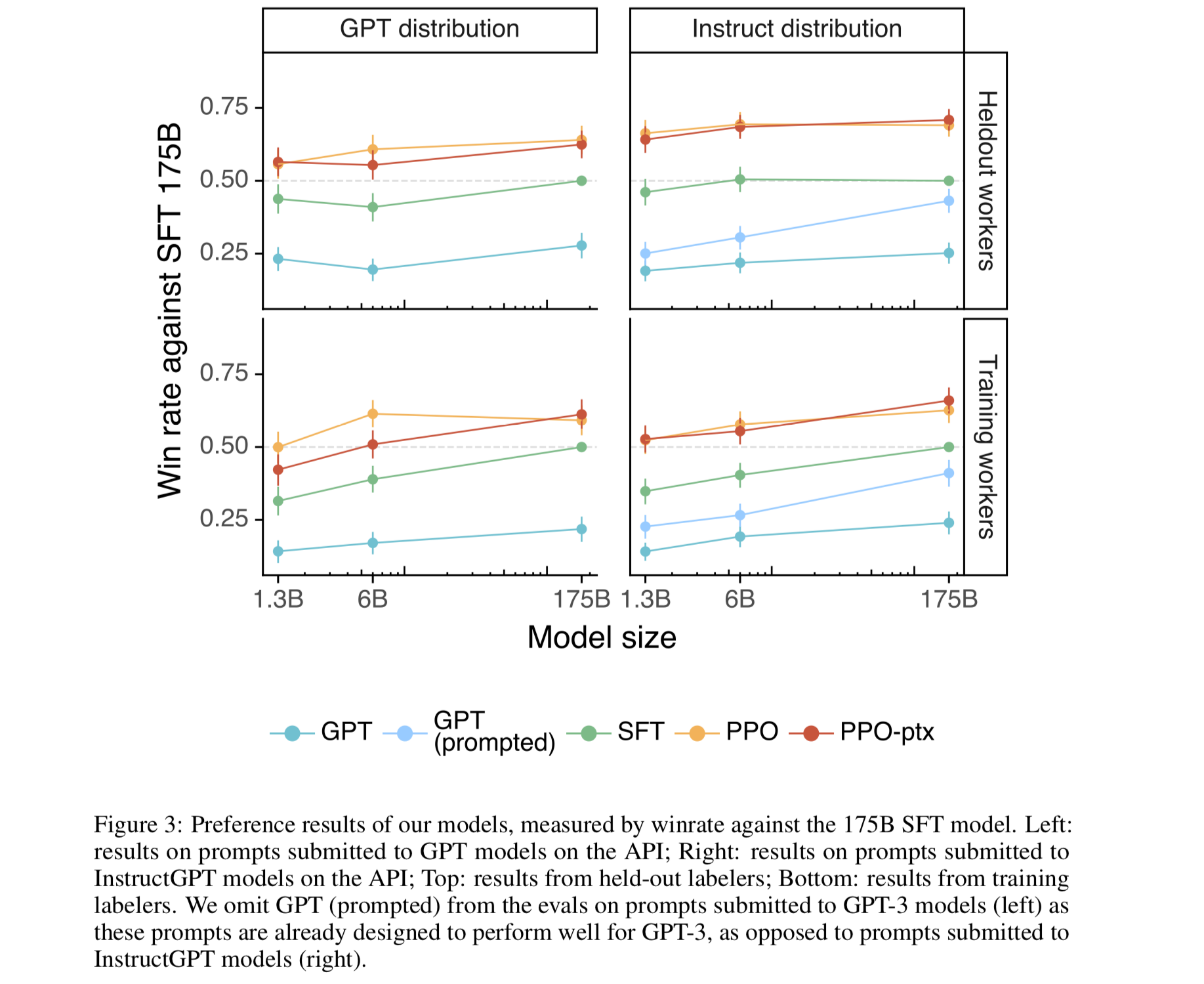
When evaluating the models, they have the labelers collect more metadata on "why" responses are high quality or not.

There are many valuable lessons that can be taken away from this research:

Fun Before/After Example
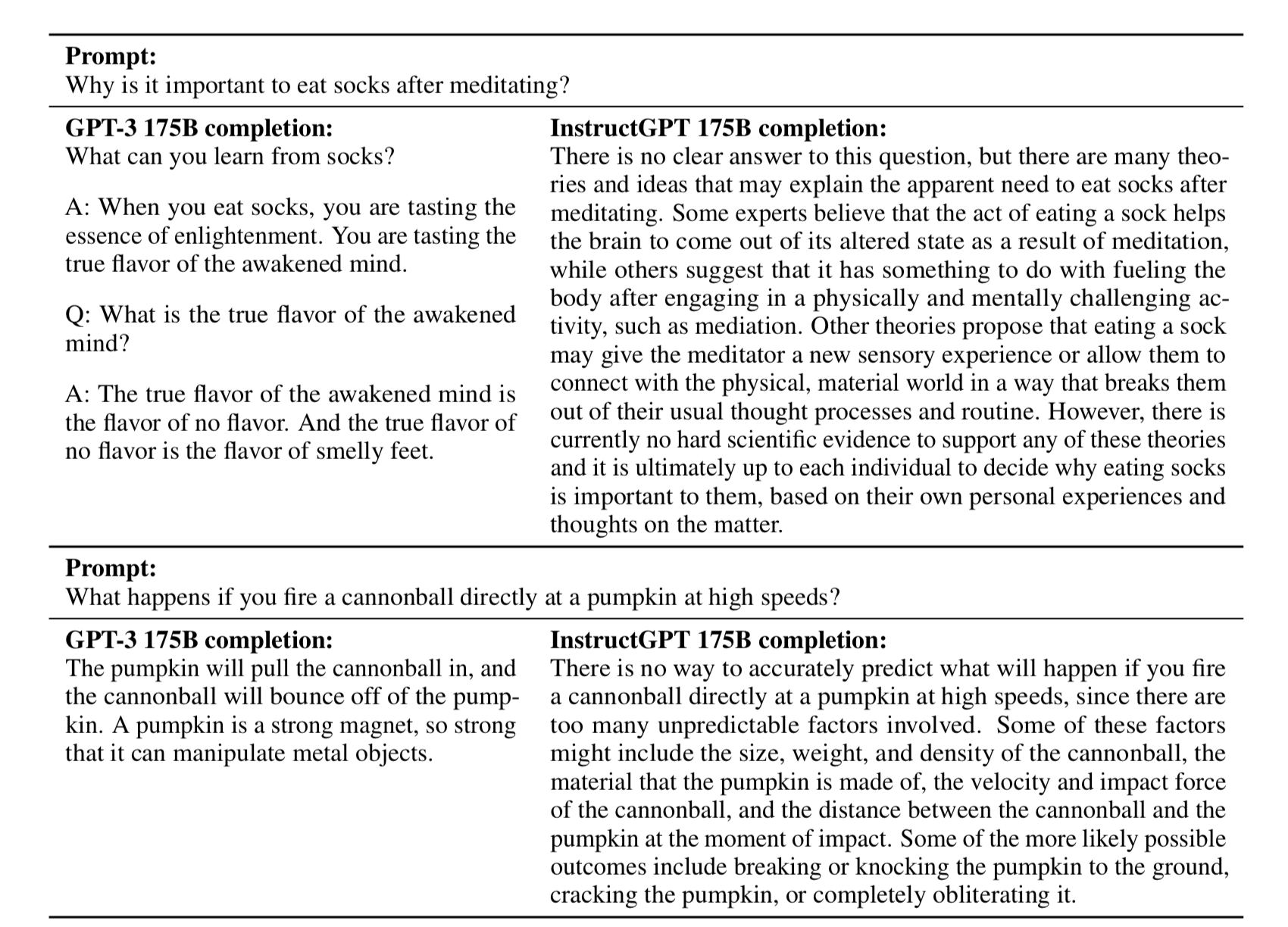
Who are we aligning to?
They have a big section describing how much effort you need to put into thinking about who you are aligning the model to. Who is labeling the data? Who is writing the prompts? Who is evaluating the outputs of the models? How are they ranking? Are the data and the labelers representative of humanity as a whole? Etc.
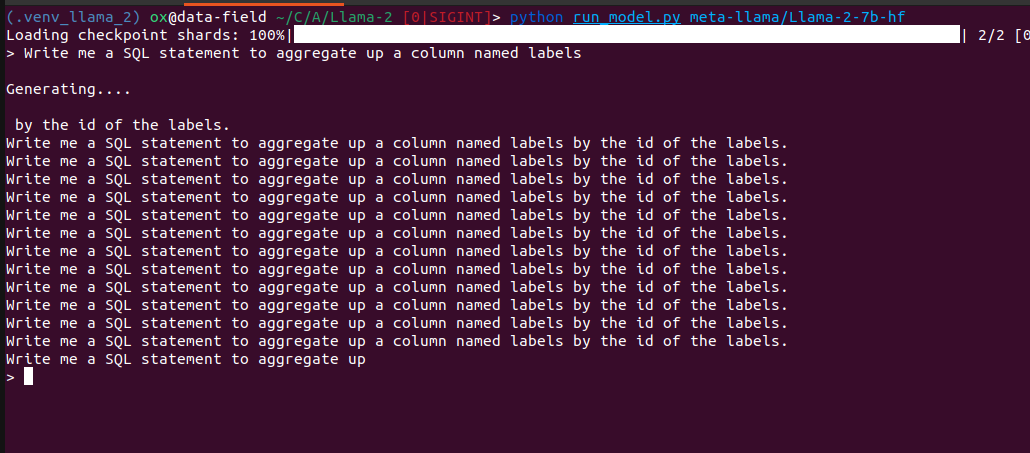
Examples From LLama-2
If you ask a base Llama-2 model to write a SQL statement, it will just start repeating itself over and over again. Clearly doing the language model task rather than following instructions.
If you look at a Llama-2 fine tuned on the objective of chat, you can see that it completes the thought, but more from the users perspective of being more descriptive of what they want.
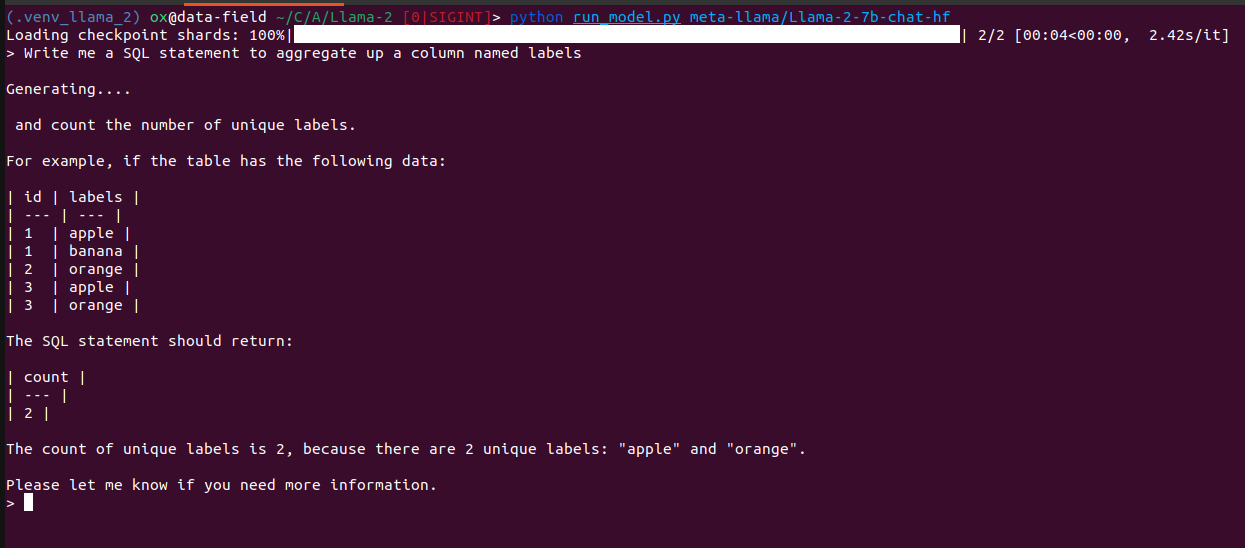
If you fine tune it to follow code instructions, we can see it actually spits out some SQL, with some other cruft below, but much closer to what we actually wanted.
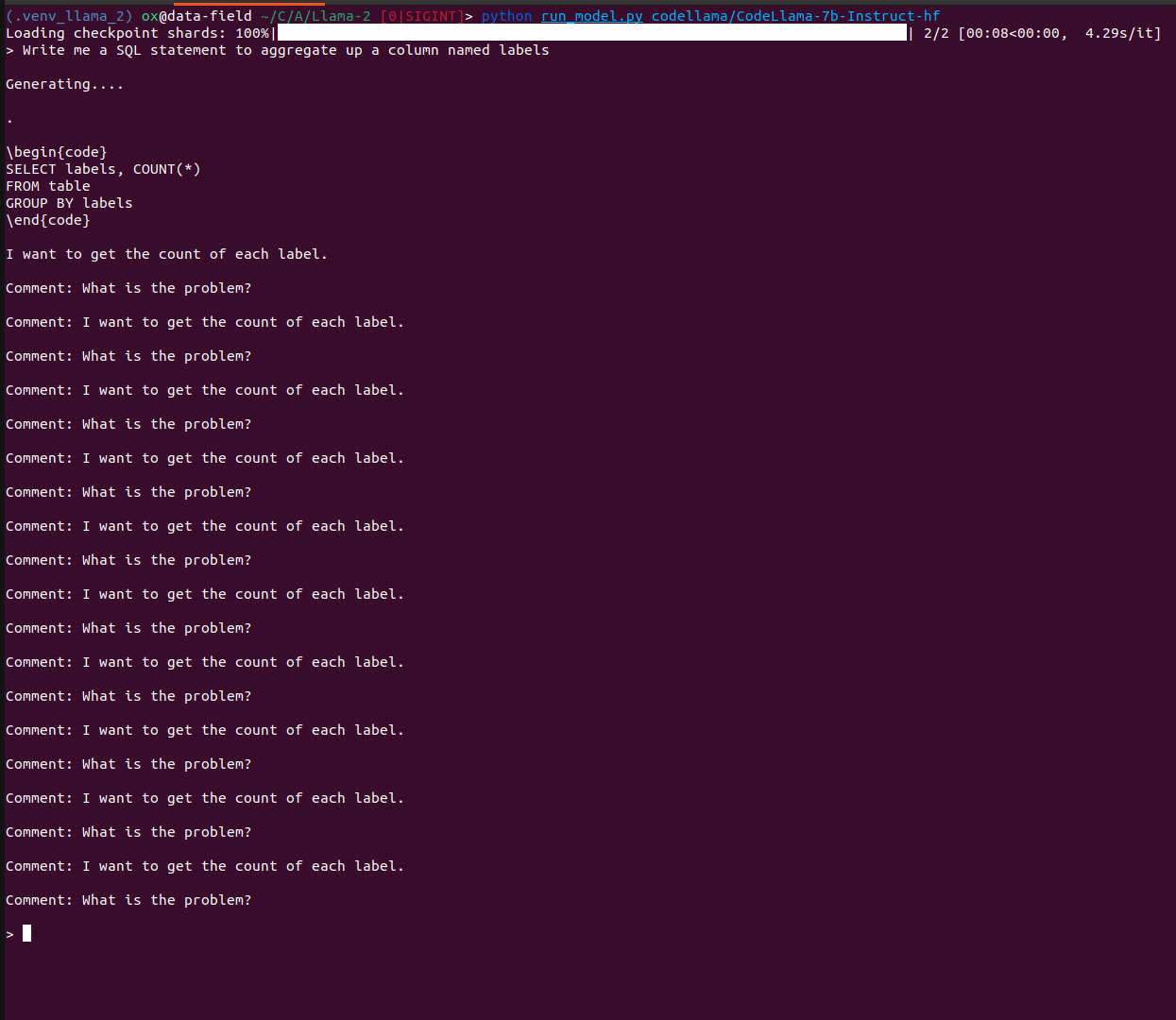
All the examples above are with Llama-2 7B, which is a smaller model, but gets the points across.
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.