
Arxiv Dives - Language Models are Unsupervised Multitask Learners (GPT-2)
Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. These are the notes from the group session for reference. If you would like to join us live, sign up here.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Research Page: https://openai.com/research/better-language-models
Fun Exercise
Let’s all try to predict the next word of something that is not in our training data.
People guessed: "long", "heard", "an", "heard".
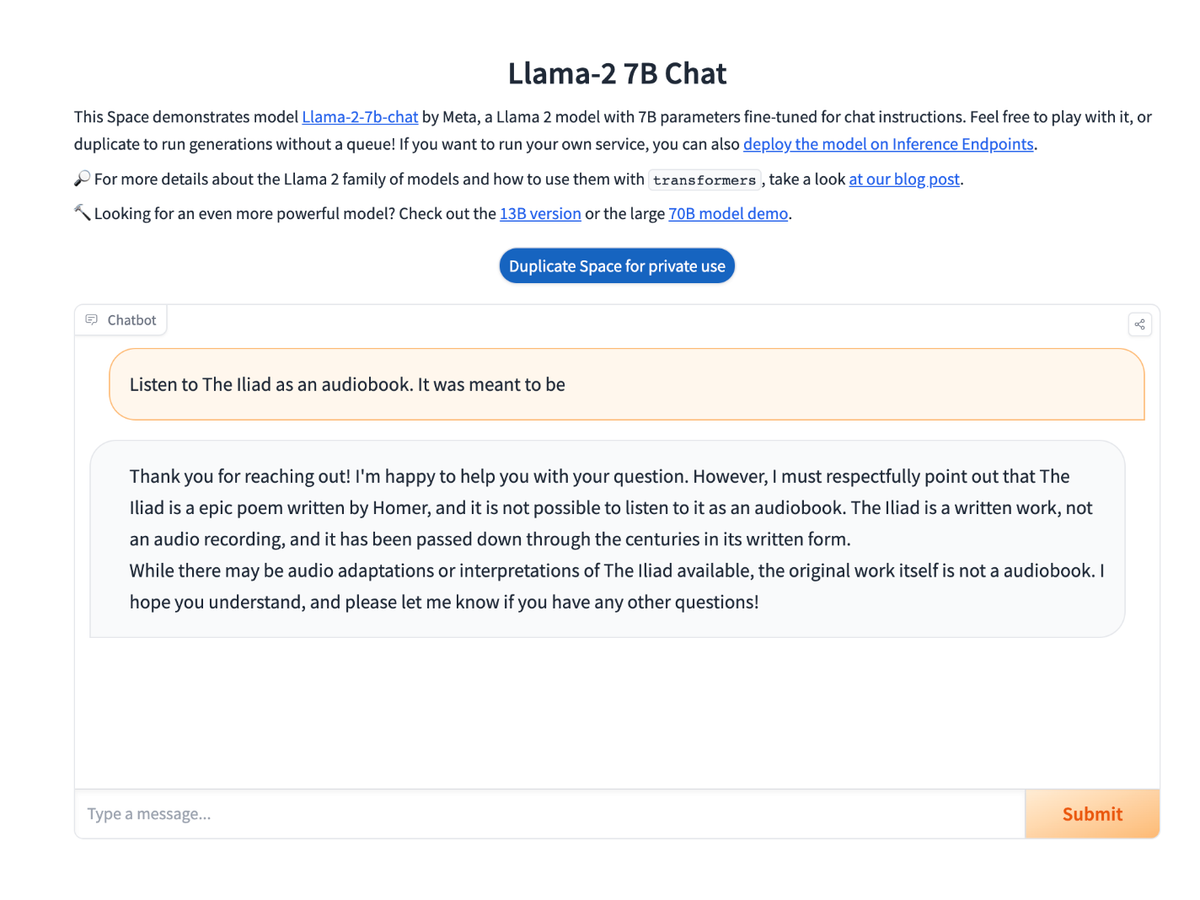
Llama-2 7B chat guessed...a long description of why you can't listen to the Iliad because it is not an audiobook.
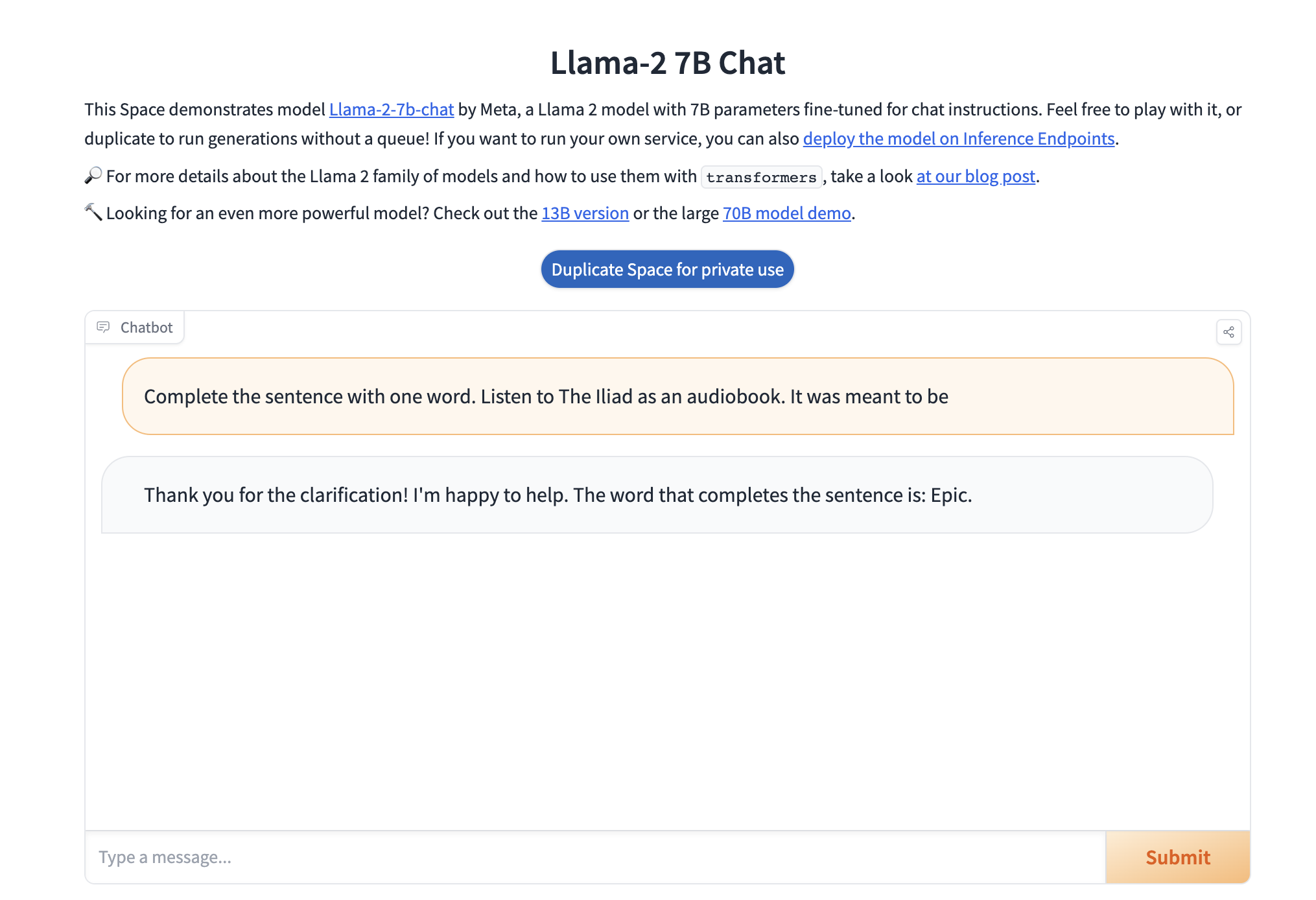
To be fair I did not instruct it, when given a little more context, it guesses "Epic".
A newer model called Falcon-180B guessed "heard." Agreeing with us humans.
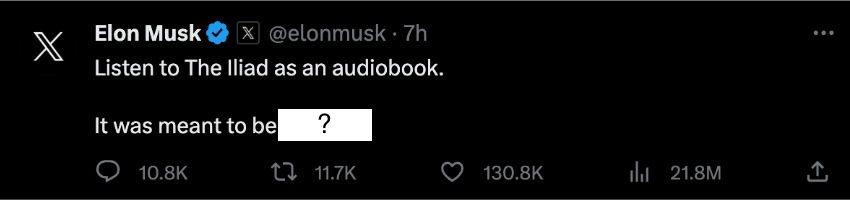
The actual tweet said...🥁
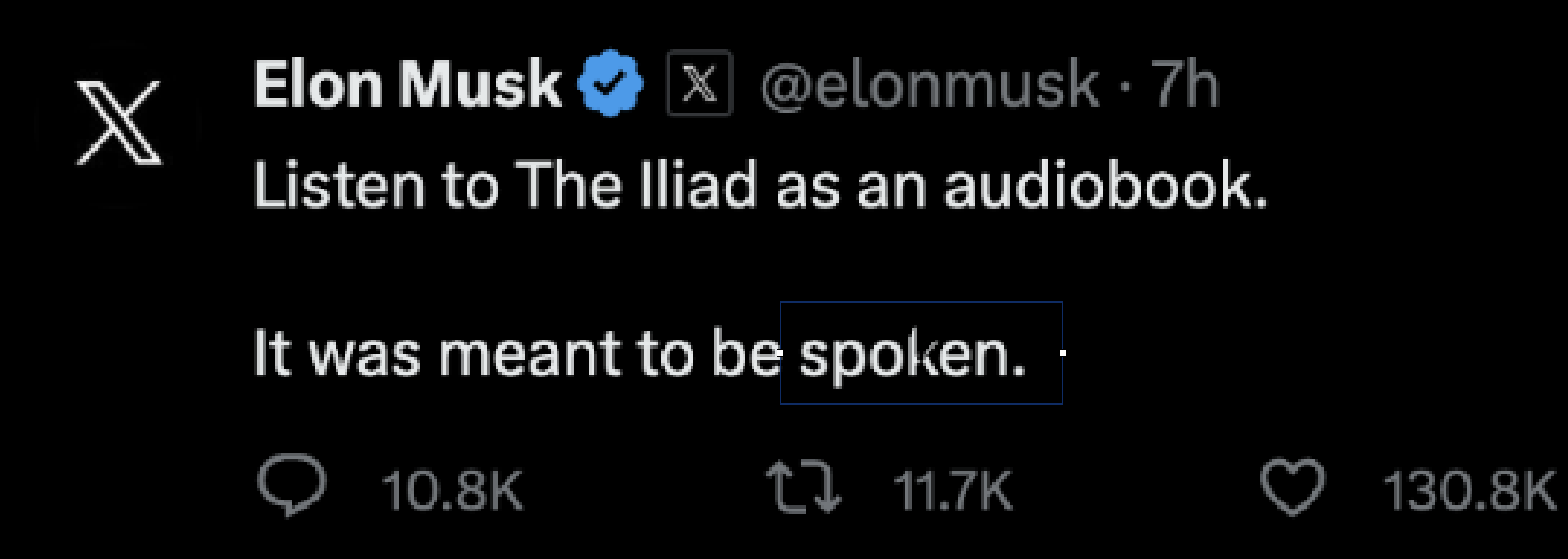
"Spoken"! Not a single one of us or the language models got it right. Illustrating how hard of a task language modeling can be.

This is the GPT-2 Paper. Published February, 2019.
Abstract
Natural Language Processing tasks such as question answering, machine translation, reading comprehension, and summarization, are typically structured as supervised learning tasks on specific datasets.
For example, you would have one dataset for Q/A, one for Machine Translation, one for summarization, and the models would specialize.
In this paper, they argue that you can get significant results with a more unsupervised approach to learning multiple tasks.
They demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a dataset of a few million web pages called WebText.
The largest model at the time was GPT-2 (1.5 Billion Parameters) and achieved state of the art performance on 7 out of 8 tested language modeling datasets in a zero shot setting, but still under fits on WebText.
Introduction
We would like to move towards more generalist systems that can perform many tasks, without having to manually create and label a training dataset for each one.
It is a lot of effort to manually curate datasets of hundreds or thousands of examples for every single task imaginable.
There has been some effort in collecting multi-task learning datasets where there are many objectives mixed into a single model.
Approach
At the core of the approach is language modeling.
Language modeling is simply: given the previous words, predict what the next word is.
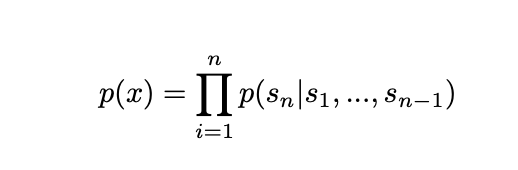
They state that learning a single task can be formalized as p(output | input), but since they want to create a generalized system they really want to be able to generate p(output | input,task). That is the probability of some output, given an input and a task.
There has been some work with training models to do multiple tasks with a little more structure in the training data. For example, the training data may look like:
(Translate this sentence from English to French, English sentence, French sentence) (Answer the question, document, question, answer)
A single model called MQAN was able to infer and perform many tasks with this kind of input data.
They argue that on the web there is already so much diversity in data, and that is passively available, that simply training a large enough language model on this data the model will inherently learn patterns that the more structured approach will.
They do note that it takes much longer to converge and much more data for this unstructured approach.
Training Dataset
Most language modeling work has been done with a single domain of text such as news, Wikipedia, books, etc.
They state that there is nearly an endless amount of data in the common crawl dump, but that this data is extremely noisey, and content is “mostly unintelligible”.
Instead they curated a new dataset, which emphasizes document quality. The metric they used was that they scraped all outbound links on Reddit which received at least 3 karma, and used this as a filter for “humans found this content interesting, educational, or just funny”.
The resulting dataset, WebText, is about 45 million links. They used Dragnet and Newspaper content extractors to get clean text from the HTML. After some deduplication and some heuristic based cleaning, the resulting dataset was 8 million documents with about 40GB of text. They removed Wikipedia since it is such a common dataset and could lead to dataset bleed into the evaluation metrics.
Input Representation
The goal of a general language model is to be able to compute the probability and generate any string. Many representations in the past had required a dictionary of words, which limits the number of outputs you could have, and going down to the byte level has also shown to be impractical.
Byte-Pair-Encoding is a practical middle ground. Despite the name, BPE operates on Unicode code points, not byte sequences.
They settle on a vocabulary size of 50,257 of the most common Unicode code point sequences. Note: if we did get it all the way down to bytes, the vocab size would be 256, but it is helpful to group common sequences so the network doesn’t have to learn everything from scratch.
Model
The model they use is a Transformer with a few modifications from the original OpenAI GPT model. Namely a context window of 1024 tokens, some modifications to the residual layers, and layer normalization tweaks.
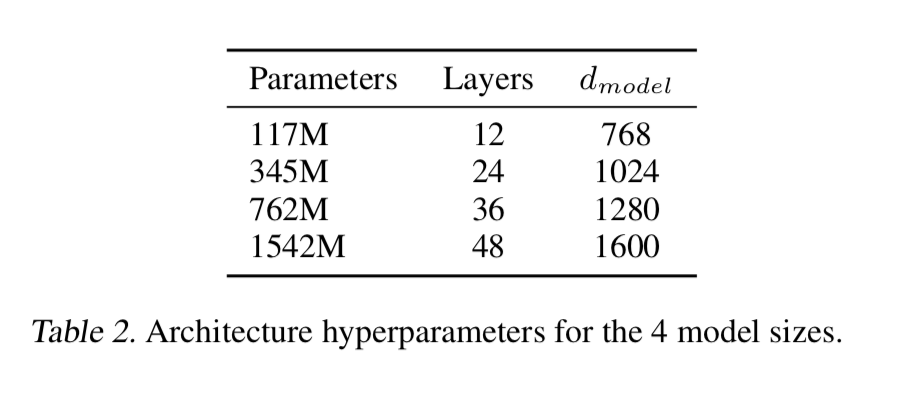
The different model sizes, give state of the art results for zero-shot on many datasets.
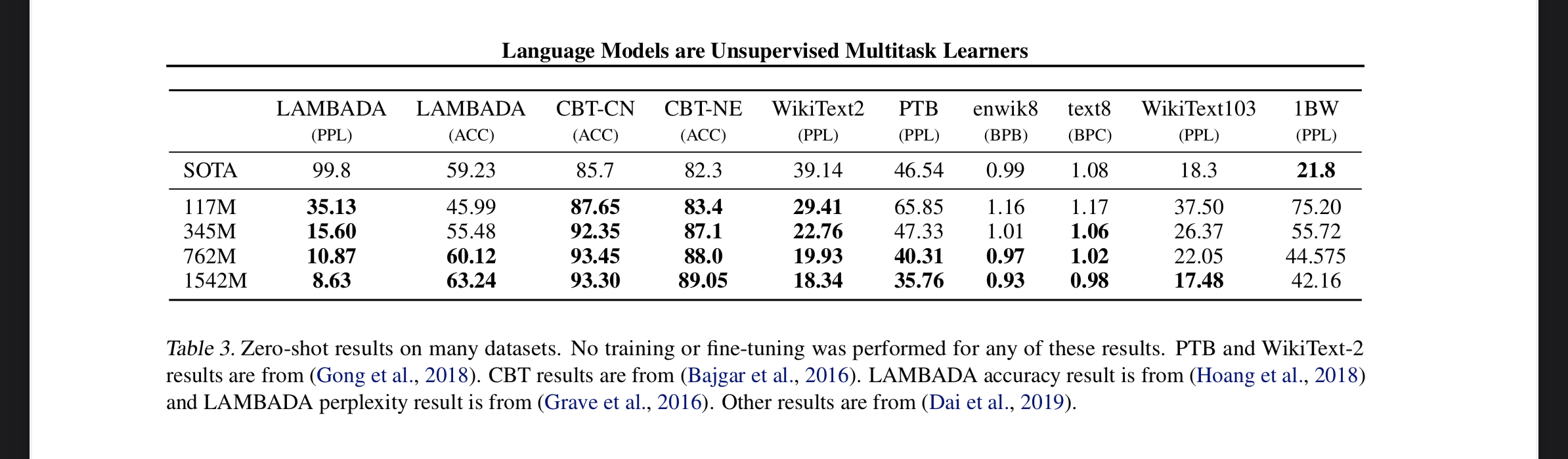
Datasets
Children’s Book Test
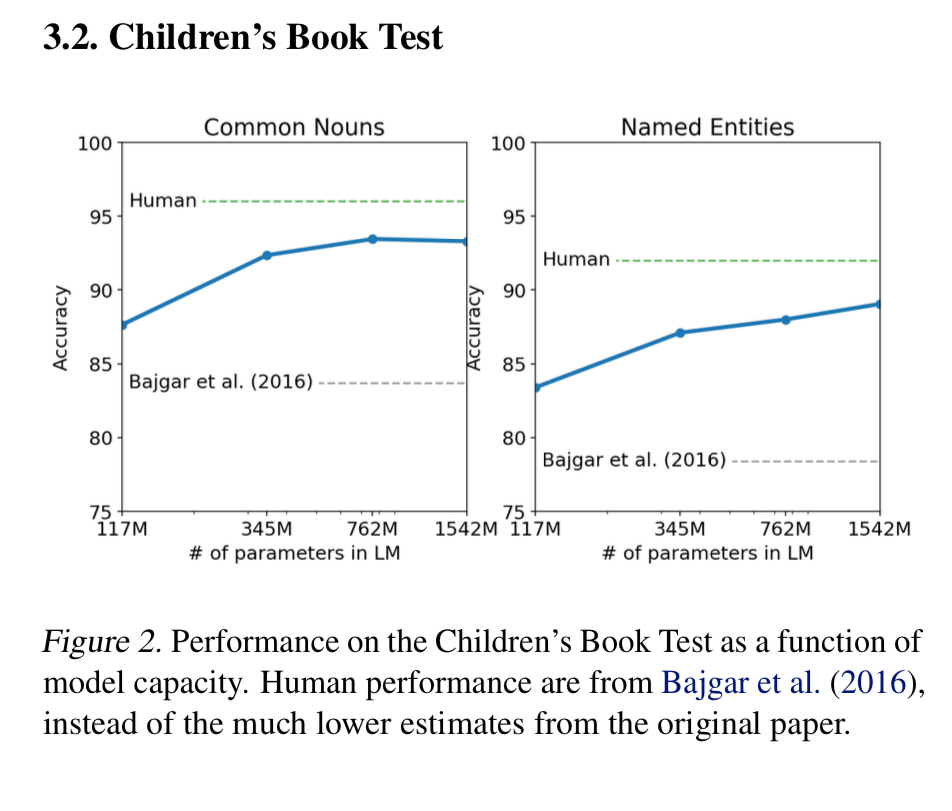
This dataset has been arranged in order to detect the accuracy on different types of words such as nouns, verbs, named entities, etc.
The task is to predict out of ten possible answers, which of the choices for an omitted word is correct.
They note that there was one book that overlapped with the test set books, The Jungle Book.
LAMBADA
This dataset tests the models ability to model long range dependencies in text.
The task is for the model to predict the final word of a sentence which requires at least 50 tokens of context for a human to predict.
They got massive bumps in perplexity from 99.8 to 8.6 (lower is better) and huge bump in accuracy from 19% to 52.66%. They note that a lot of the errors the model was making was still valid continuations of the sentence, just not valid final words. When they added a stop word filter for words such as “the”, “and”, “a” etc the accuracy bumps up to 63.24%.
Winogrand Schema Challenge
This task is supposed to measure common sense reasoning by measuring how well the model is able to resolve ambiguities in text.
https://cdn.aaai.org/ocs/4492/4492-21843-1-PB.pdf
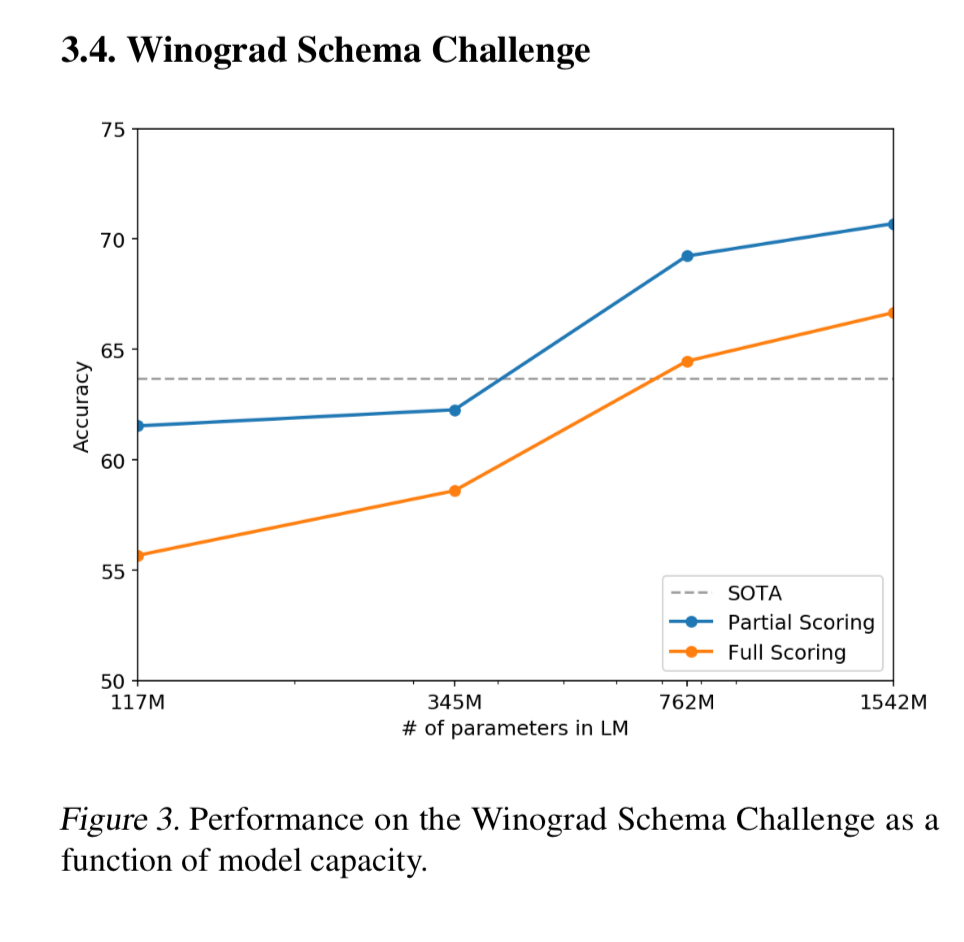

The dataset is quite small, with only 273 examples. According to the Wikipedia page, this challenge has now been considered “defeated” by transformer based language models.
Reading Comprehension
Conversation Question Answering Dataset (CoQA) consists of documents from 7 different domains with dialogs between a question asker and question answered paired with the document.
They took the document and the conversation, and tried to predict the final token, and got a 55% F1 on the development set. This beat some baseline systems without using the 127,000 manually collected question / answer pairs.
They do note that it seemed the model used some simple retrieval metrics to answer questions that were not always correct. For example if it was a “who” question, it would often just pick a random name it saw in the document.
Summarization
They used the CNN and Daily Mail datasets to evaluate summarization.
To induce the summarization they simply added the text TL;DR: after the article and generate 100 tokens with a top-k random sampling (k=2). Then they used the first 3 generated sentences as the summary.

They qualitatively say the text looks like summaries, but often get counts, dates, or specifics wrong about the article.
There are metrics like ROUGE they say the numbers are not too far off more supervised neural baselines, but do not do much better than just randomly picking 3 sentences from the article.
Translation
They condition the model with a bunch of text that is
“English text = French text”
And then prompt it with “English text = “ and have the model complete.
There is a metric called BLEU that scores how well translations do. They got a score of 5 BLEU for English -> French. And 11.5 BLEU on French -> English. But is still much worse than the best unsupervised approach 33.5 BLEU.
The performance was mainly surprising because they filtered out all non-english web pages from the WebText dataset before training. They ran a language detector after the fact on the dataset and only detected 10MB of data in the French Language, which is 500x smaller than the monolingual French corpus commonly used in other unsupervised machine learning translation research.
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.