This post is an effort to put together a reading list for our Friday paper club called ArXiv Dives. Since there has not been an official paper released yet for Sora, the goal is follow the bread crumbs from OpenAI's technical report on Sora. We plan on going over a few of the fundamental papers in the coming weeks during our Friday paper club, to help paint a better picture of what is going on behind the curtain of Sora.
If you'd like to join us live this Friday as we dive into this series, feel free to join below 👇 the more the merrier!
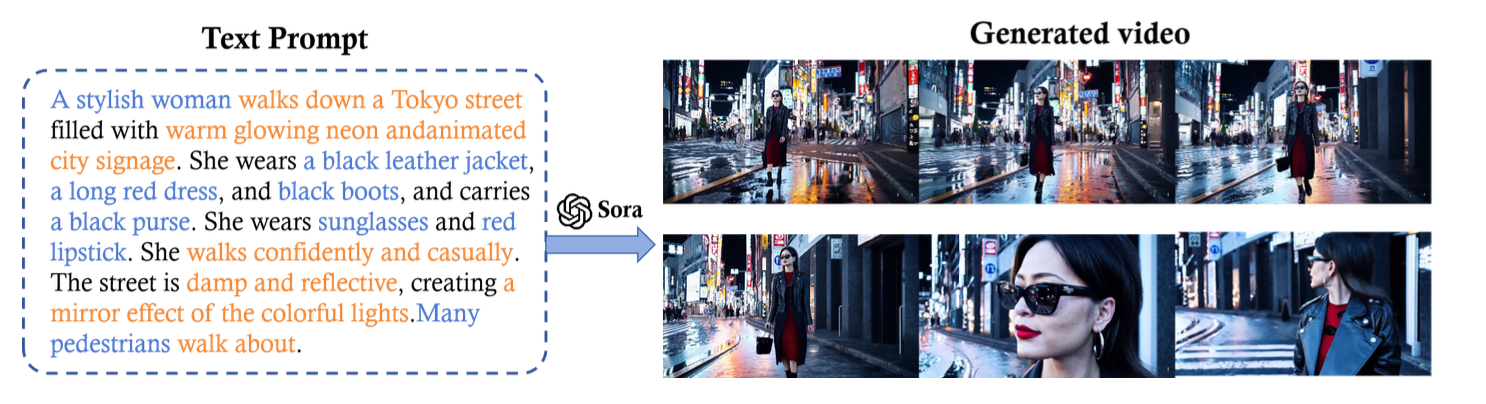
Sora has taken the Generative AI space by storm with it's ability to generate high fidelity videos from natural language prompts. If you haven't seen an example yet, here's a generated video of a turtle swimming in a coral reef for your enjoyment.
0:00
/0:15
While the team at OpenAI has not released an official research paper on the technical details of the model itself, they did release a technical report that covers some high level details of the techniques they used and some qualitative results.
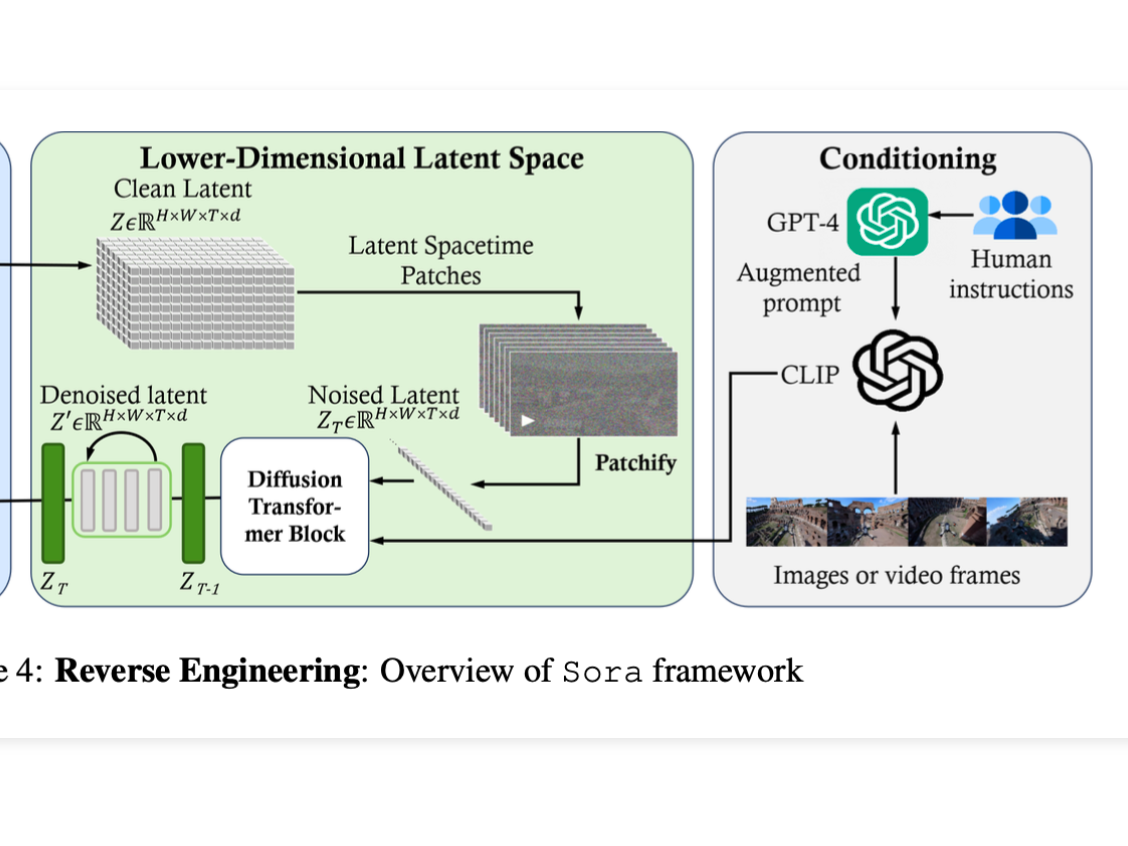
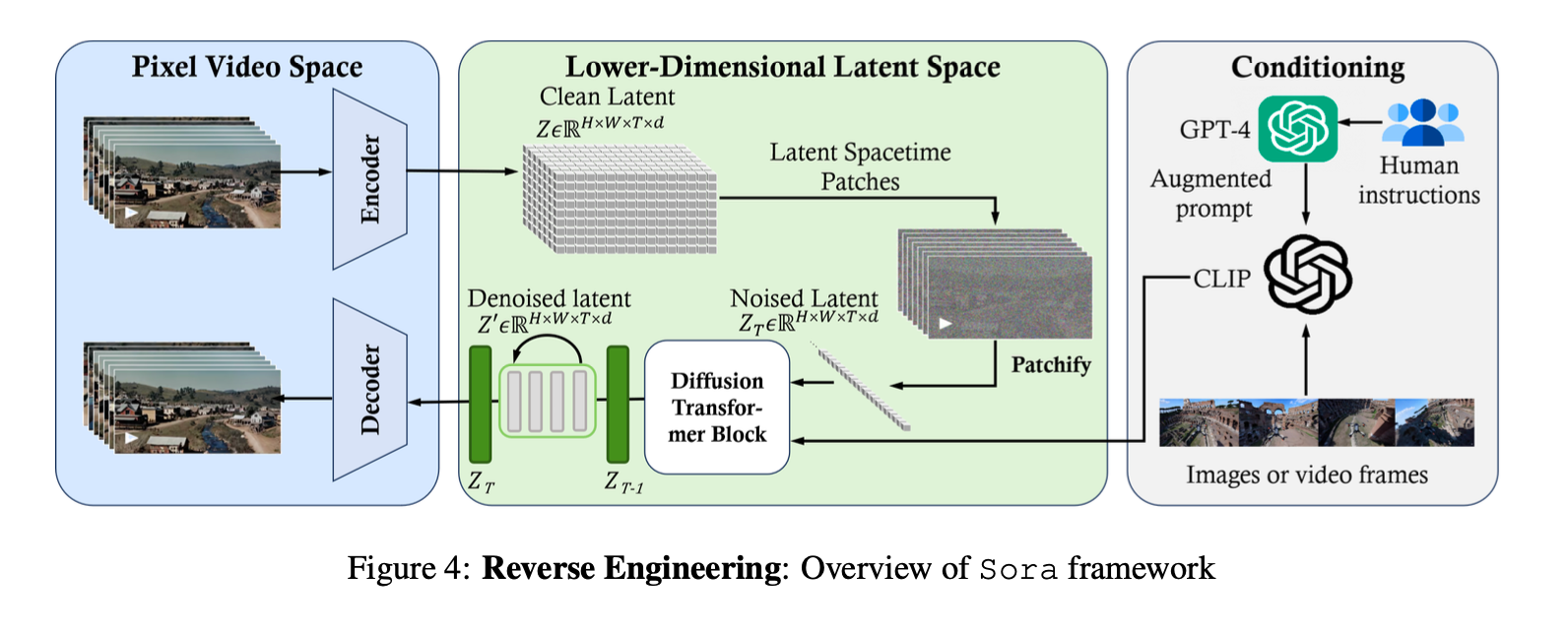
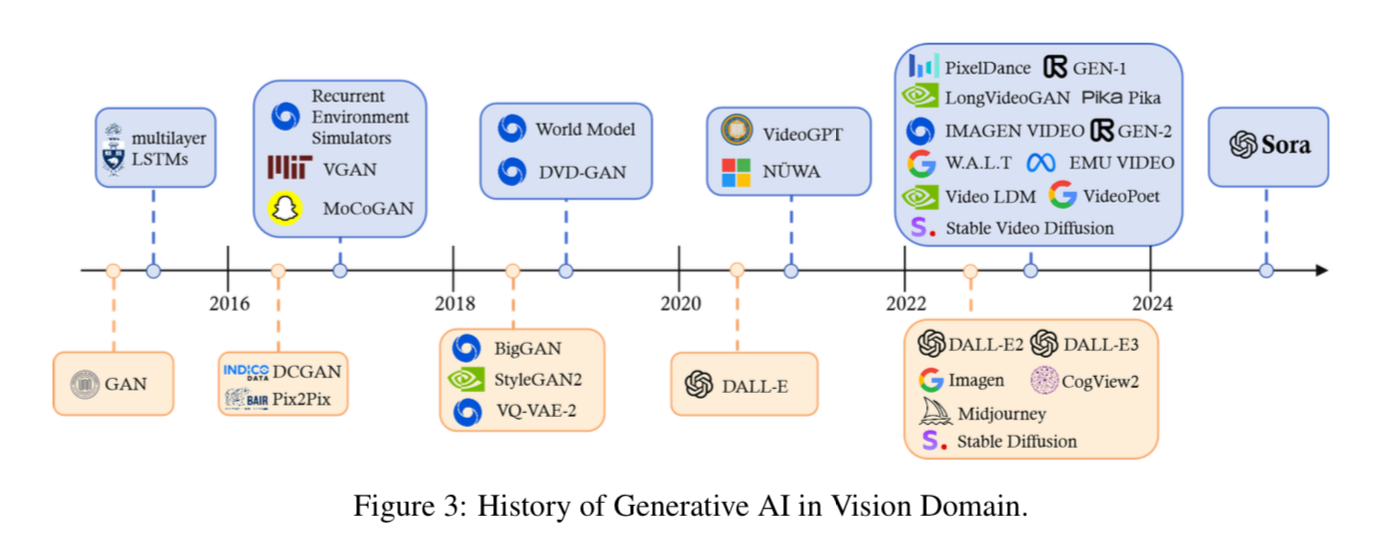
After reading the papers below, the architecture here should start to make sense. The technical report is a 10,000 foot view and my hope is that each paper will zoom into different aspects and paint the full picture. There is a nice literature review called "Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models" that gives a high level diagram of a reverse engineered architecture.
The team at OpenAI states that Sora is a "Diffusion Transformer" which combines many of the concepts listed in the papers above, but applied applied to latent spacetime patches generated from video.
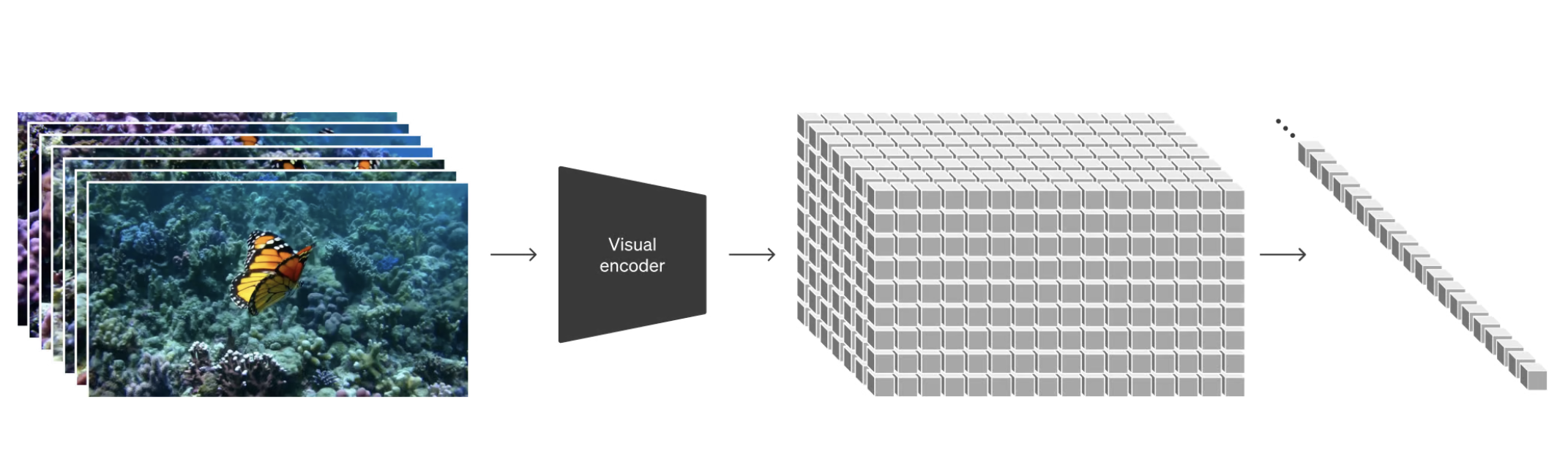
This is a combination of the style of patches used in the Vision Transformer (ViT) paper, with latent spaces similar to the Latent Diffusion Paper, but combined in the style of the Diffusion Transformer. They not only have patches in width and height of the image but extend it to the time dimension of video.
It's hard to say how exactly they collected the training data for all of this, but it seems like a combination of the techniques in the Dalle-3 paper as well as using GPT-4 to elaborate on textual descriptions of images, that they then turn into videos. Training data is likely the main secret sauce here, hence has the least level of detail in the technical report.
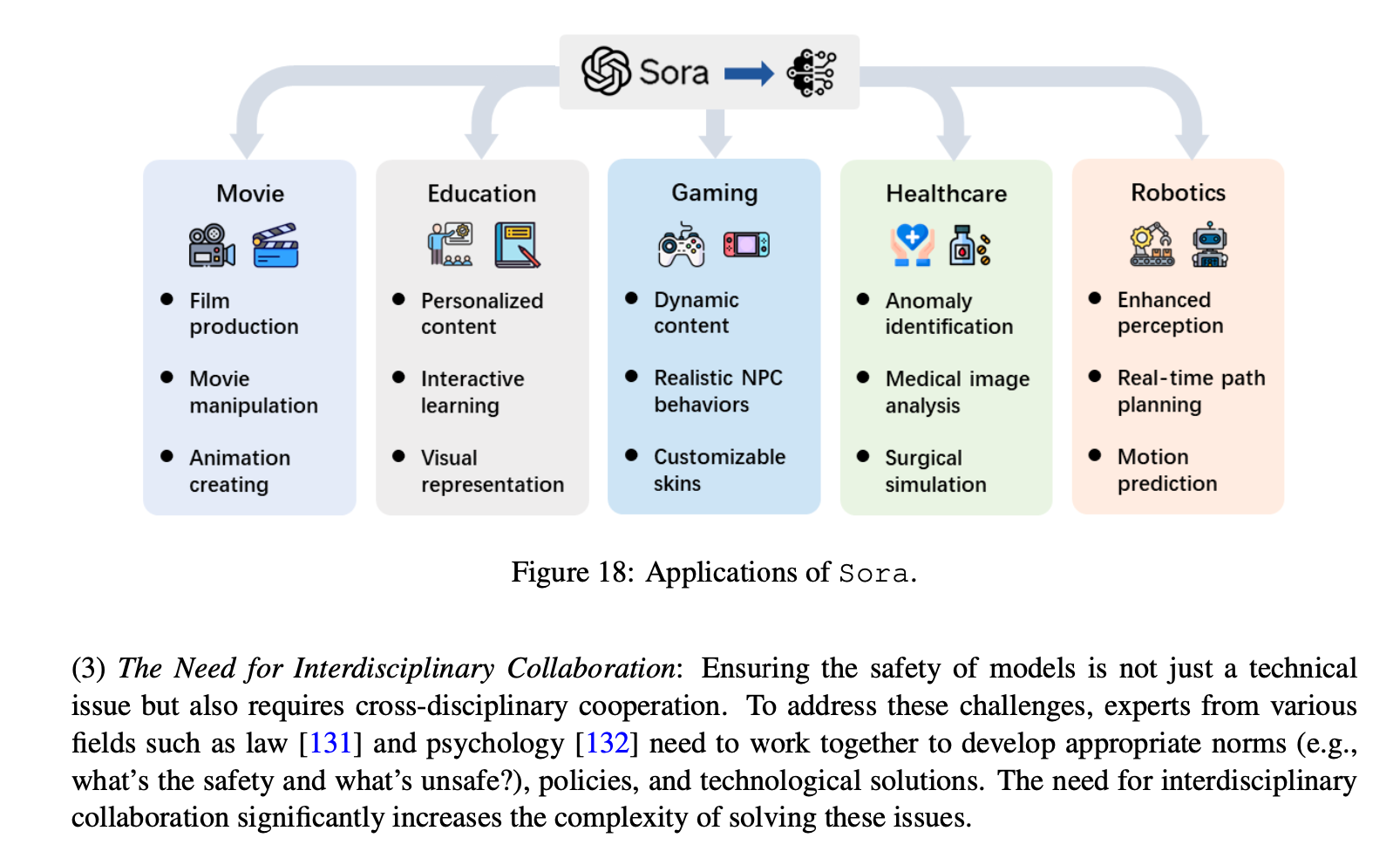
Use Cases
There are many interesting use cases and applications for video generation technologies like Sora. Whether it be movies, education, gaming, healthcare or robotics, there is no doubt generating realistic videos from natural language prompts is going to shake up multiple industries.
The note at the bottom of this diagram rings true for us at Oxen.ai. If you are not familiar with Oxen.ai we are building open source tools to help you collaborate on and evaluate data the comes in and out of machine learning models. We believe that many people need visibility into this data, and that it should be a collaborative effort. AI is touching many different fields and industries and the more eyes on the data that trains and evaluates these models, the better.
There are many papers linked in the references section of the OpenAI technical report but it is a bit hard to know which ones to read first or are important background knowledge. We've sifted through them and selected what we think are the most impactful and interesting ones to read, and organized them by type.
Background Papers
The quality of generated images and video have been steadily increasing since 2015. The biggest gains that caught the general public's eyes began in 2022 with Midjourney, Stable Diffusion and Dalle. This section contains some foundational papers and model architectures that are referenced over and over again in the literature. While not all papers are directly involved in the Sora architecture, they are all important context for how the state of the art has improved over time.
"U-Net: Convolutional Networks for Biomedical Image Segmentation" is a great example of a paper that was used for a task in one domain (Biomedical imaging) that got applied across many different use cases. Most notably is the backbone many diffusion models such as Stable Diffusion to facilitate learning to predict and mitigate noise at each step. While not directly used in the Sora architecture, important background knowledge for previous state of the art.
"Attention Is All You Need" is another paper that proved itself on a Machine Translation task, but ended up being a seminal paper for all of natural language processing research. Transformers are now the backbone of many LLM applications such as ChatGPT. Transformers end up being extensible to many modalities and are used as a component of the Sora architecture.
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" was one of the first papers to apply Transformers to image recognition, proving that they can outperform ResNets and other Convolutional Neural Networks if you train them on large enough datasets. This takes the architecture from the "Attention Is All You Need" paper and makes it work for computer vision tasks. Instead of the inputs being text tokens, ViT uses 16x16 image patches as input.
"High-Resolution Image Synthesis with Latent Diffusion Models" is the technique behind many image generation models such as Stable Diffusion. They show how you can reformulate the image generation as a sequence of denoising auto-encoders from a latent representation. They use the U-Net architecture referenced above as the backbone of the generative process. These models can generate photo-realistic images given any text input.
"Learning Transferable Visual Models From Natural Language Supervision" often referred to as Contrastive Language-Image Pre-training (CLIP) is a technique for embedding text data and image data into the same latent space as each other. This technique helps connect the language understanding half of generative models to the visual understanding half by making sure that the cosine similarity between the text and image representations are high between text and image pairs.
According to the technical report, they reduce the dimensionality of the raw video with a Vector Quantised Variational Auto Encoder (VQ-VAE). VAEs have been shown to be a powerful unsupervised pre-training method to learn latent representations.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
The Sora technical report talks about how they take in videos of any aspect ratio, and how this allows them to train on a much larger set of data. The more data they can feed the model without having to crop it, the better results they get. This paper uses the same technique but for images, and Sora extends it for video.
The team at OpenAI states that Sora is a "Diffusion Transformer" which combines many of the concepts listed in the papers above. The DiT replaces the U-Net backbone in latent diffusion models, with a transformer that operates on latent patches. This paper generates state of the art high quality images by using a more efficient model than a U-Net, therefore increasing the amount of data and compute that could be used to train these models.
They reference a few video generation papers that inspired Sora and take the generative models above to the next level by applying them to video.
ViViT: A Video Vision Transformer
This paper goes into details about how you can chop the video into "spatio-temporal tokens" needed for video tasks. The paper focuses on video classification, but the same tokenization can be applied to generating video.
Imagen Video: High Definition Video Generation with Diffusion Models
Imagen is a text-conditional video generation system based on a cascade of video diffusion models. They use convolutions in the temporal direction and super resolution to generate high quality videos from text.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
This paper takes the latent diffusion models from the image generation papers above and introduces a temporal dimension to the latent space. They apply some interesting techniques in the temporal dimension by aligning the latent spaces, but does not quite have the temporal consistency of Sora yet.
Photorealistic video generation with diffusion models
They introduce W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. This feels like the closest technique to Sora in the reference list as far as I can tell, and was released in December of 2023 by the teams at Google, Stanford and Georgia Tech.
In order to Generate Videos from text prompts, they need to collect a large dataset. It is not feasible to have humans label that many videos, so it seems they use some synthetic data techniques similar to those described in the DALL·E 3 paper.
DALL·E 3
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. They apply the re-captioning technique introduced in DALL·E 3 to videos. Similar to DALL·E 3, they also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model.
In order for the model to be able to follow user instructions, they likely did some instruction fine-tuning similar to the Llava paper. This paper also shows some synthetic data techniques to create a large instruction dataset that could be interesting in combination with the Dalle methods above.
Papers like Make-A-Video and Tune-A-Video have shown how prompt engineering leverages model’s natural language understanding ability to decode complex instructions and render them into cohesive, lively, and high-quality video narratives. For example: taking a simple user prompt and extending it with adjectives and verbs to more fully flush out the scene.
We hope this gives you a jumping off point for all the important components that could make up a system like Sora! If you think we missed anything, feel free to email us at hello@oxen.ai.
It is by no means a light set of reading. This is why on Fridays we take one paper at a time, slow down, and break down the topics in plain speak so anyone can understand. We believe anyone can contribute to building AI systems, and the more you understand the fundamentals, the more patterns you will spot, and better products you will build.