
ArXiv Dives: I-JEPA
Today, we’re diving into the I-JEPA paper. JEPA stands for Joint-Embedding Predictive Architecture and if you have been following Yann LeCunn, is a technique he has been hyping up for awhile. Excited to dive into what the hype is about and look at the technique.
Teams: Meta AI
Publish Date: April 13th, 2023
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
These are the notes from our live session, feel free to follow along with the video for context. If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

Semantic Image Representations
The goal of this paper is to create “highly semantic image representations” without relying on hand-crafted data-augmentations. They want to train a neural network in a self-supervised manner that does not require hand labeled training data.
If you have high quality semantic image representations, they can be used for many downstream tasks.
- Image Generation
- Semantic similarity search
- Image classification
- Semantic segmentation
- Object detection
- Depth estimation
Name your computer vision task - the process of abstracting pixel space into a latent space is very important.
Instead of representing images in pixel space, neural networks learn a function to transform them into a latent representation. The hope is that this representation contains more semantics about the image itself. For example the semantic representation would contain information like "dog ear" rather than "white RGB pixel".
Yann LeCunn is a big proponent of JEPA architectures and uses the analogy of planning or driving a car. While planning you think of things at multiple levels of abstraction. For natural language, if you were to plan a trip from LA → Paris, you would have to break it down into sub problems each with their own characteristics. How do I get from my house to the airport? How do I get from my chair to the door? Each one of these “thoughts” could be it’s own latent space that is processed hierarchically.
Another example he likes to give is when we are driving a car, we take in all the “pixels” of the image around us, but tend to drop out and only use certain information to make our next decision. We don’t pay attention to every leaf blowing on the tree when deciding to make a left hand turn. The dream is to allow a computer vision system to be able to process pixels to the level of semantic abstraction that is needed for the task at hand.
While this paper does not perform any of the planning explicitly, the argument is that higher quality semantic representations will allow systems to plan better in the future.
Previous Approaches
In the paper, they compare this approach to previous approaches of Invariance Based Pre-Training as well as Generative Modeling. Arguing JEPA creates more robust semantic representations.
Invariance Based Pre-Training
They refer to invariance based pre-training in this paper, which in this context means that you can recognize an object as an object, even when its appearance varies in some way. Common approaches to learning invariant representations are applying distortions to images such as random cropping, scaling, color shifts etc and then trying to predict the same embedding for the non-distorted image and the distorted one, but it is unclear how well this improves the abstraction of the representation.
Generative Pre-Training
Generative models of the world have shown great promise in terms of self-supervised pre-training, where you simply corrupt the whole image (with noise or other techniques) and try to reconstruct the image from the noise.
They argue that these generative techniques do not capture the semantic meaning within the images, because the latent vectors tend to perform worse on tasks like classification. You often need to do a second step of fine tuning on these representations to get competitive image classification scores.
I-JEPA
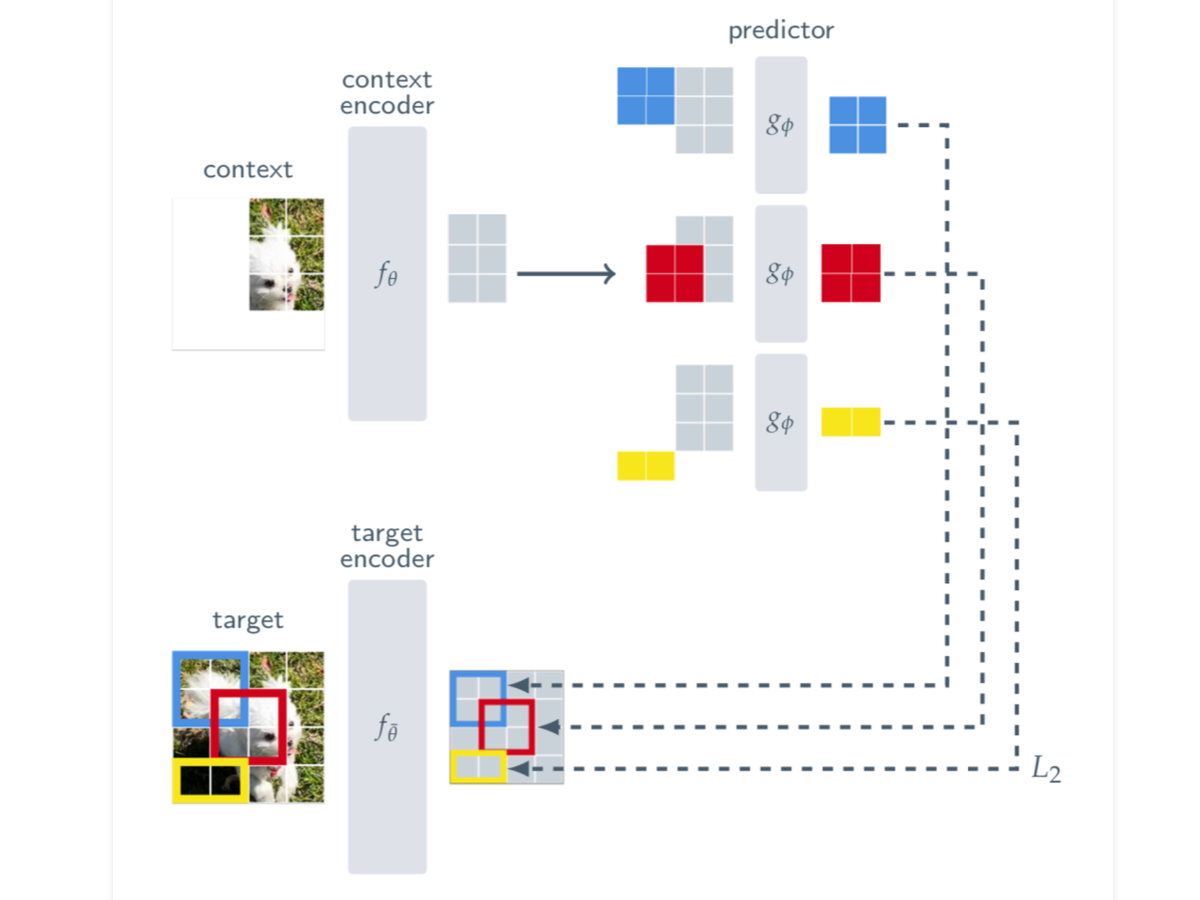
This work tries to improve the semantic representation of the latent vectors during self-supervision by taking a single “context block” from an image and trying to predict the representation of various target context blocks, where the representations are learned by a target encoder network.
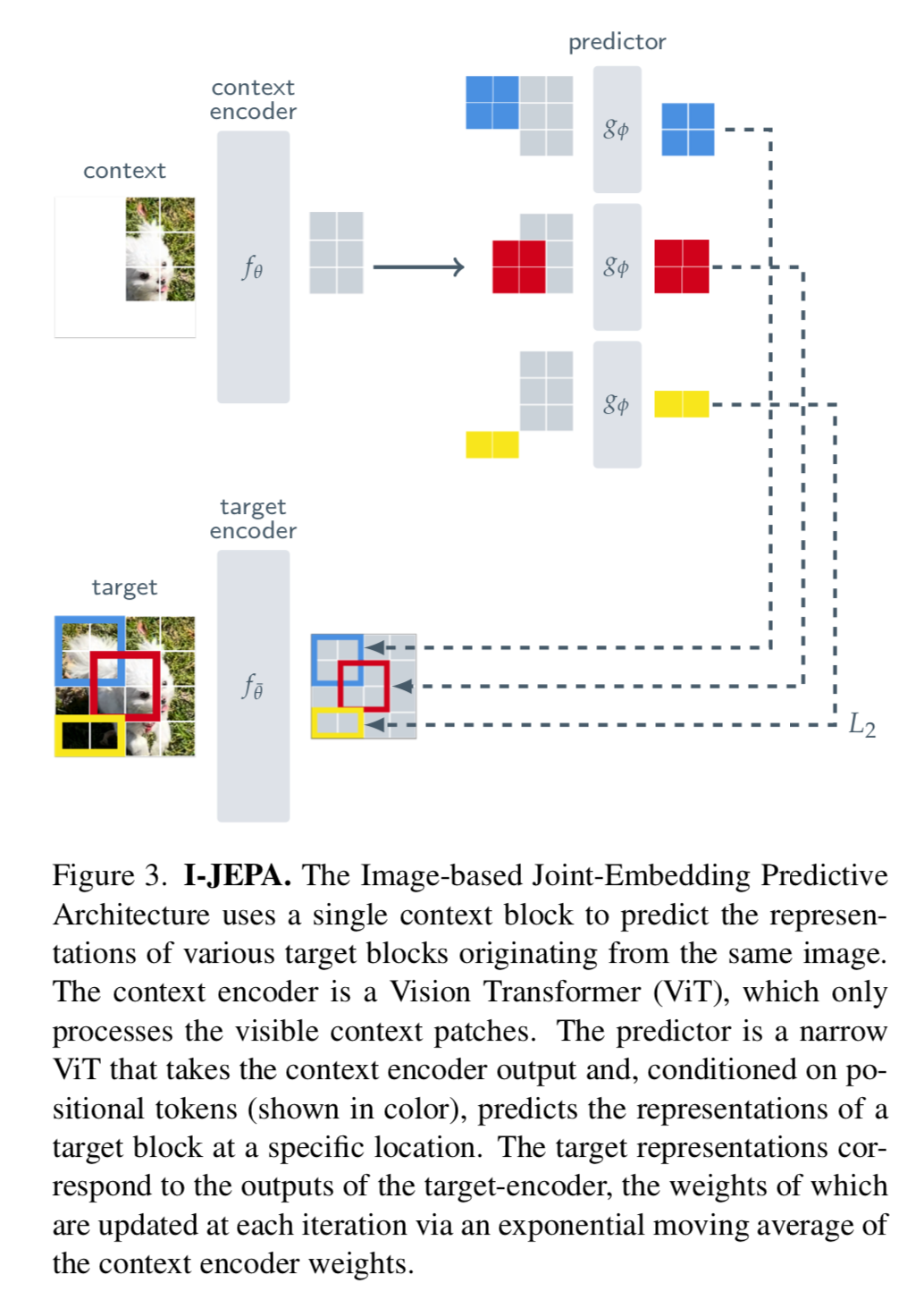
The previous approaches of invariance based training and generative modeling can be seen in figure 2.
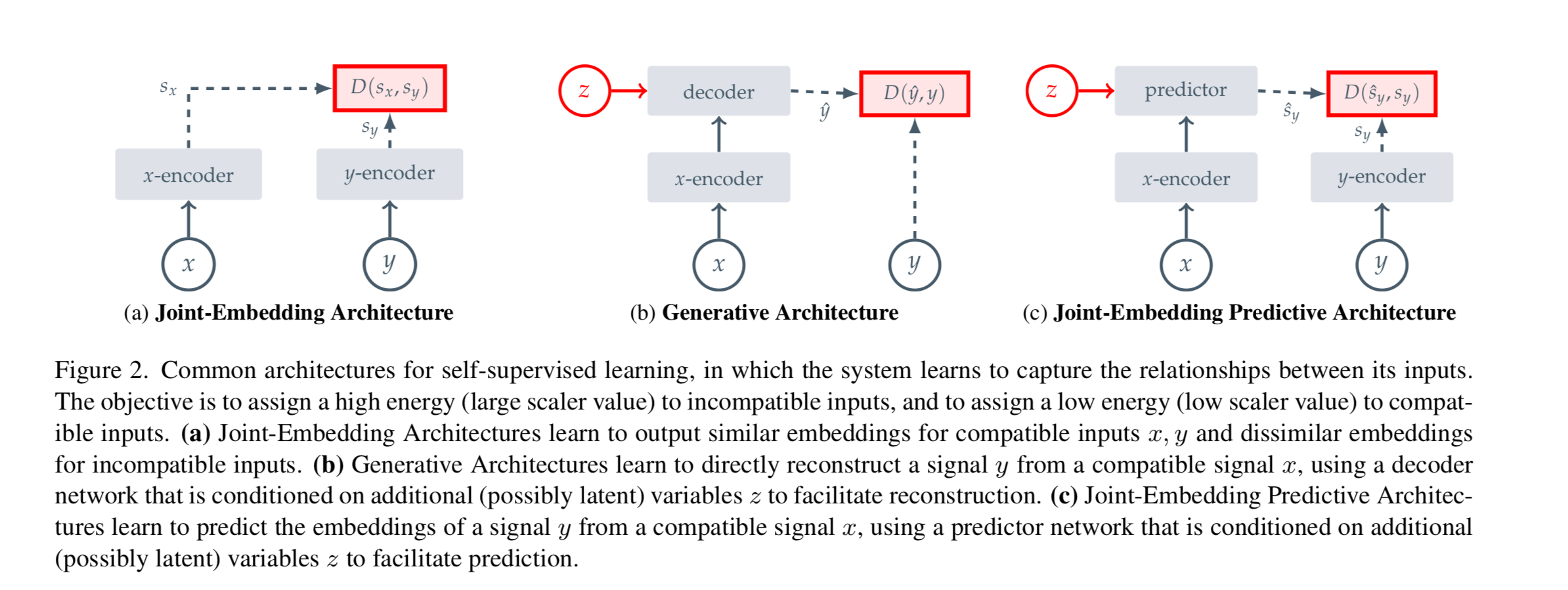
They mention the “energy” of the system, this is just a fancy way of saying they assign a high number to incompatible inputs and a low number to compatible inputs. For example compatible inputs might be an image and a piece of text that represent the same thing.
The joint-embedding architecture tries to make the distance between the encoded vectors small given two inputs. This could be an example of invariance based pre-training where you corrupt X and try to predict Y. X and Y do not even necessarily be the same type of data as we saw in CLIP where X and Y are image-text pairs.
Generative architectures tend to compare the output of the decoder with the Y value you are trying to deconstruct through methods like MAE (Mean Average Error). This is not the best metric for evaluating how well an image is generated because drastic changes in pixel space can still be semantically the same image.
Joint-Embedding Predictive Architectures (JEPA) try to merge the best of both worlds, where you encode X and Y, but add in a predictor that learns to predict the embeddings of Y from the input X, not just the pure similarity score.
Method
The model architecture for the context-encoder, target-decoder, and predictor blocks are all Vision Transformers (ViT). If you are not familiar with ViT's or Transformers in general we have some other dives where we get into the gnitty gritty details.
The architecture of the ViT is similar to that of the MAE paper on Masked Auto Encoder, however the predictions are done in the latent space not at the raw pixel values. We have seen the MAE paper referenced a good bit in the literature so maybe a useful dive in the future.
Sampling Context and Targets
First they take image patches, just like the first step in any Vision Transformer. They sample 4 target blocks that may be overlapping. The "blocks" are not the patches themselves, but they are the set of representations (s_0 .. s_n) of each patch.
Then they sample a context block that is not overlapping with any of the targets. The context block is anywhere from 85%-100% of the image. After it is is sampled, they remove all the patches that overlap with the targets since those would be too easy to predict.

Prediction
Back to the image from above, there are M target block representations we wish to predict from our single context block. In the case of the image below, M=3.
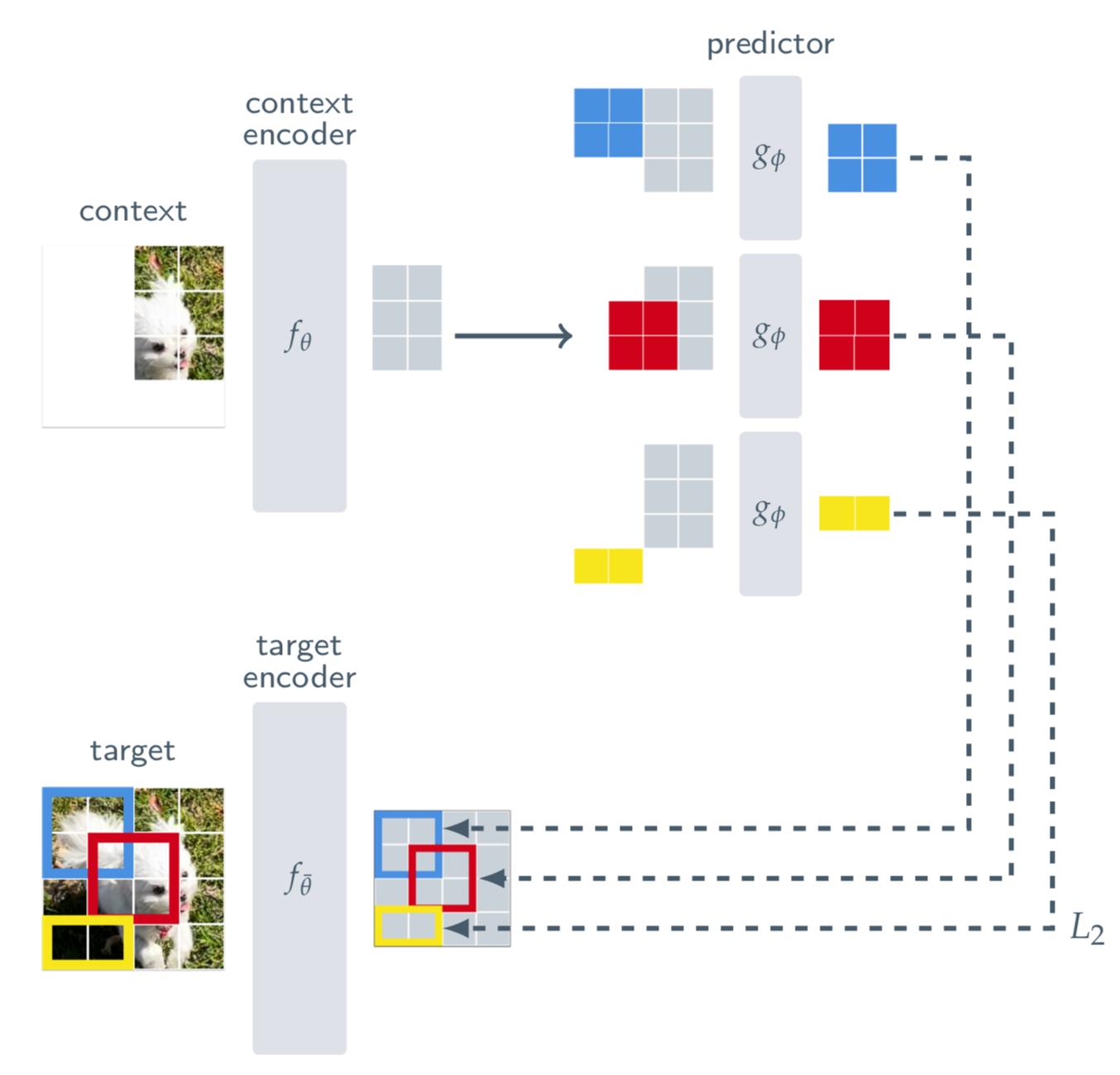
For a given target block, you feed in the context and a mask of the target so that there is not overlapping information. Since there are M target blocks, the predictor is applied M times, each time with a separate mask given the context and the target.
The predictors job is the predict the latent space of the target blocks given what it knows about the context.
Where do the latent spaces come from?
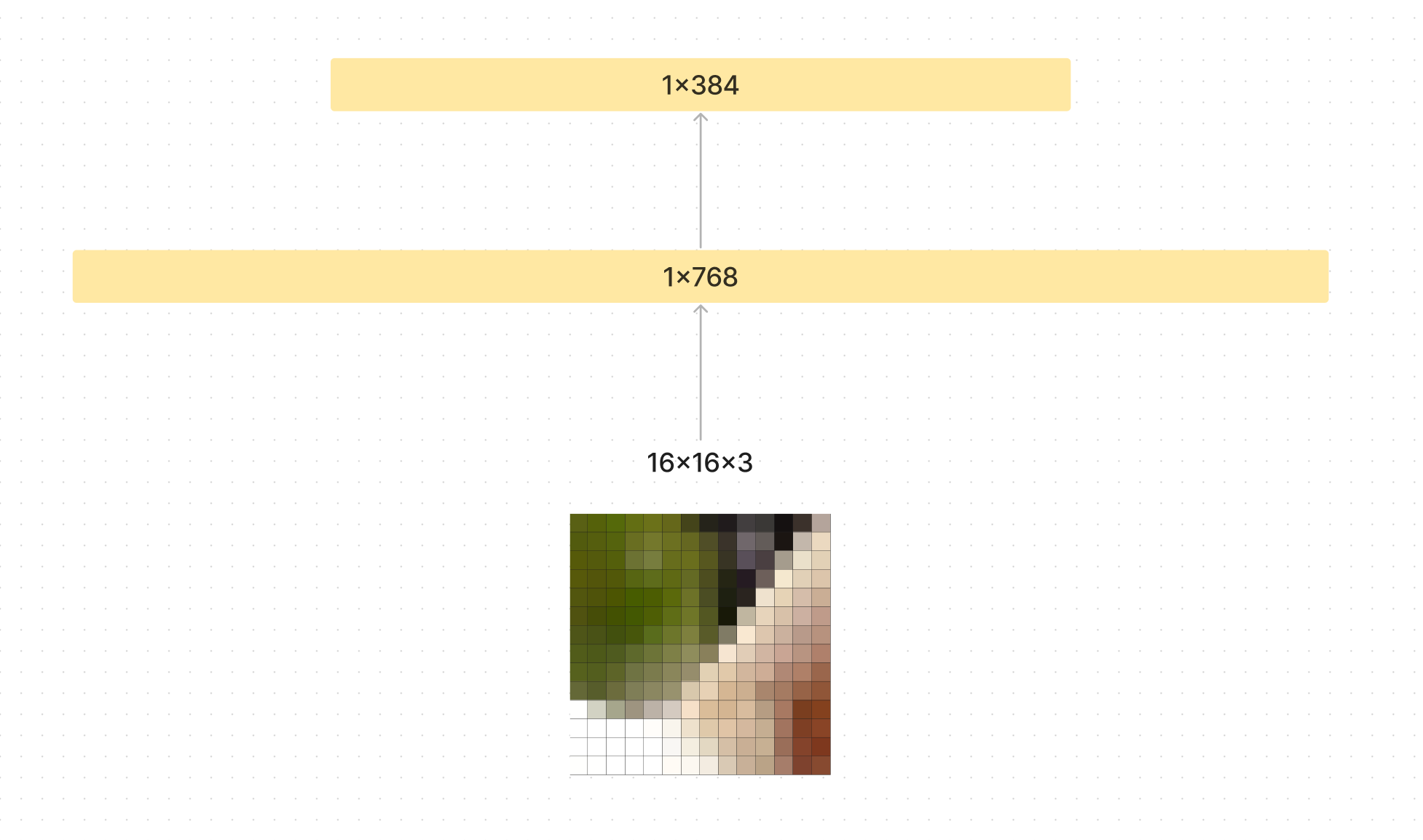
If you have 16x16x3 patch size you would flatten each patch into 768 values.
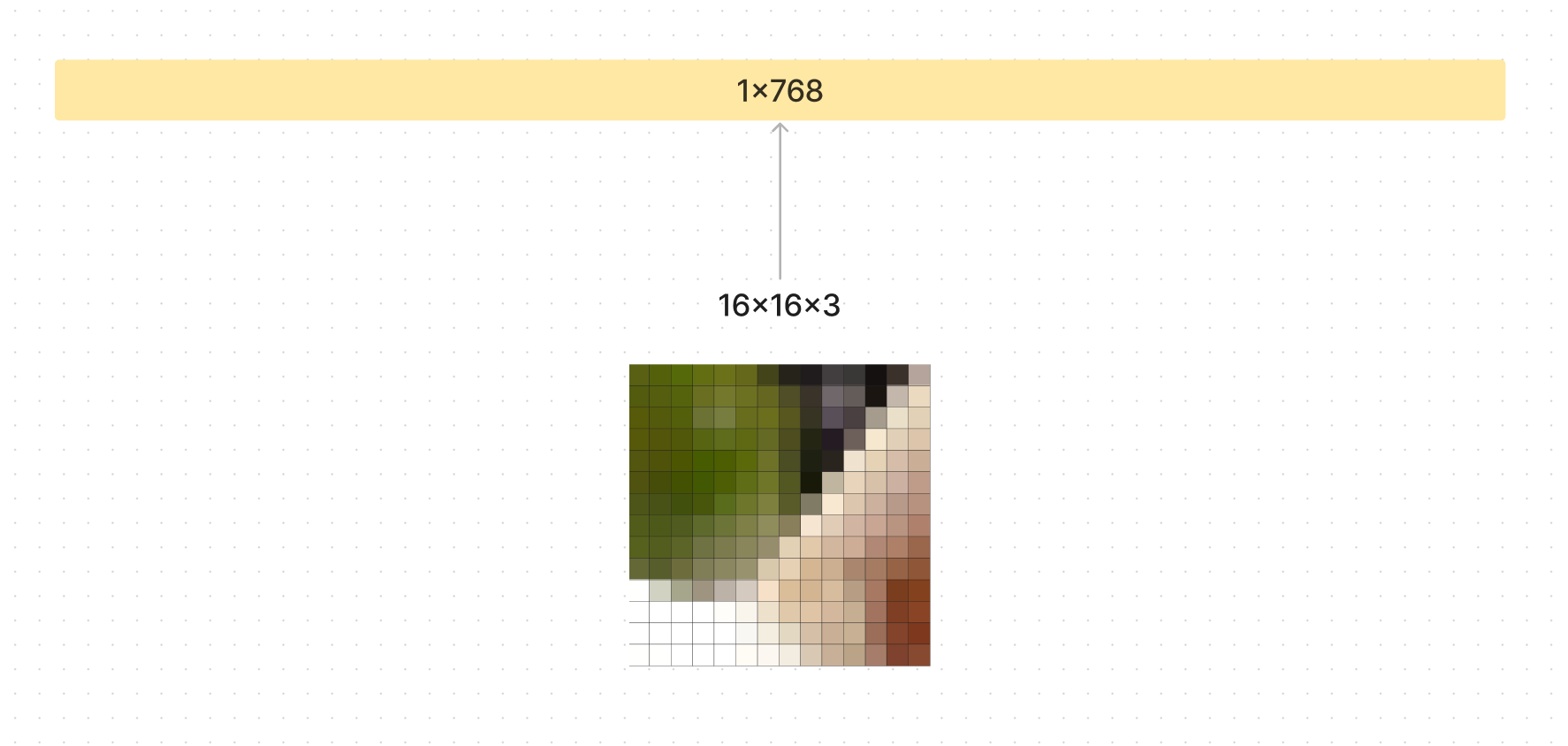
If you had a 224x224 image with a patch size of 16, 224/16=14 means you have 14x14 patches. This creates a 768x196 matrix that can be fed into the transformer.
Source: https://yurkovak.medium.com/vision-transformer-vit-under-the-magnifying-glass-part-1-70be8d6661a7
Each image patch can call out to each other patch and say “hey, I am a fluffy ear, any noses to go along with it to help me decide if I’m a cat or dog?” Then the nose patch says, “I’m a nose! Let us combine our powers into a new representation.
The way these patches communicate with each other to create their semantic representation are through transformer blocks.
Transformer Block
At the end of the transformer block, you get h(x_i) which is the hidden space that we are concerned with. This latent vector is an updated representation that has taken in the context of all the other patches. The idea is this updated representation will have passed through context from all the other patches to update the representation from "furry ear" to "furry dog ear".
Attention Head
The attention heads are the real magic of the transformer block. I updated the diagram we went through in our Mechanistic Interpretability of Transformers series to take in image patches instead of words in a sentence.
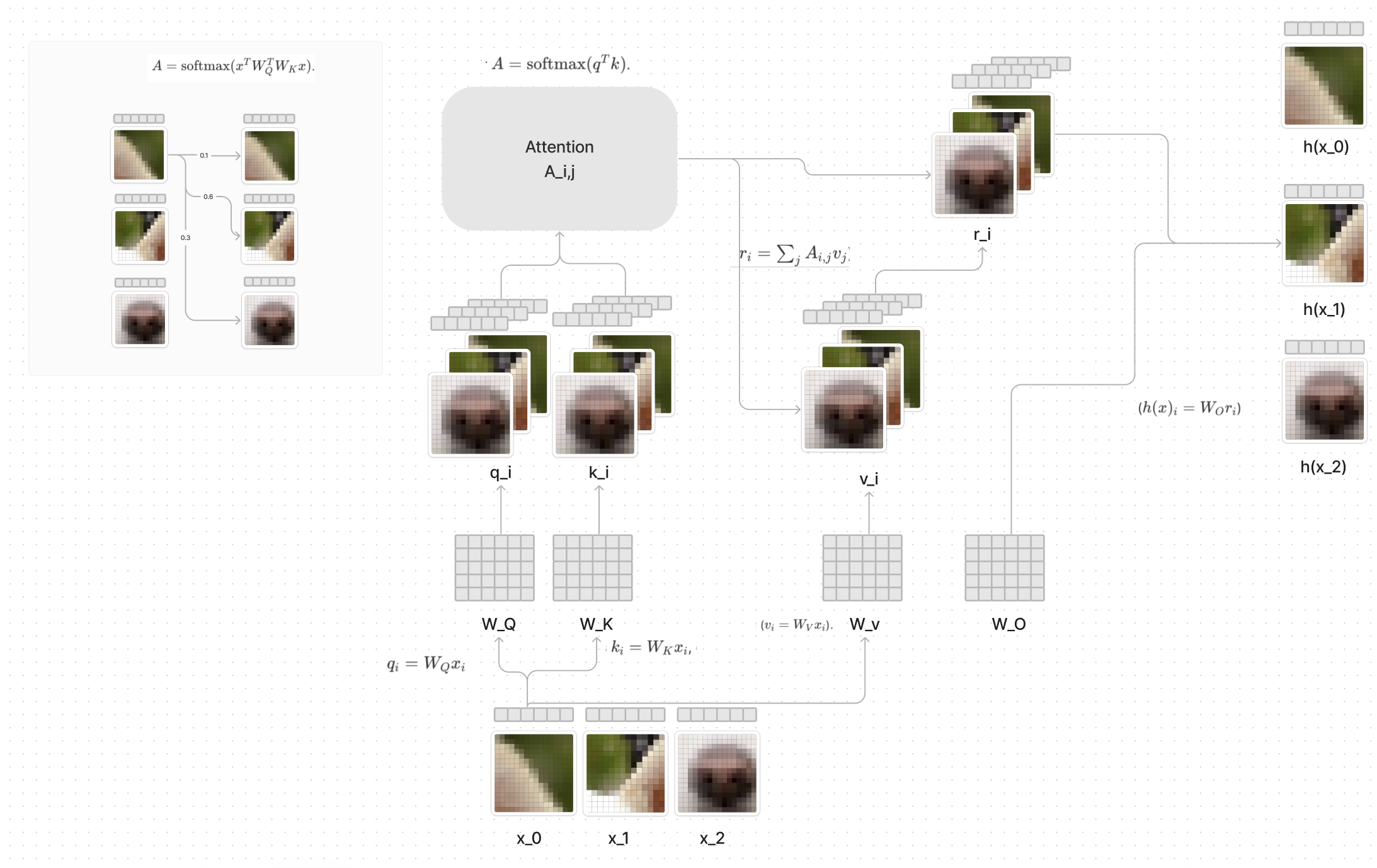
If you want to learn what all the fancy math in here means, feel free to checkout the past dives.
In the appendix they say that the embedding dimension of the predictor is 384, and the depth (number of transformer blocks) is anywhere between 6-12 in various experiments.
Loss
The loss is a simple L2 distance between the patch level representations within the blocks. So looking at our blocks again, you sum over the M target blocks, and compute the L2 value between the vectors of each patch in the context and the target, then take the average over each target block.

Evaluation on Image Classification
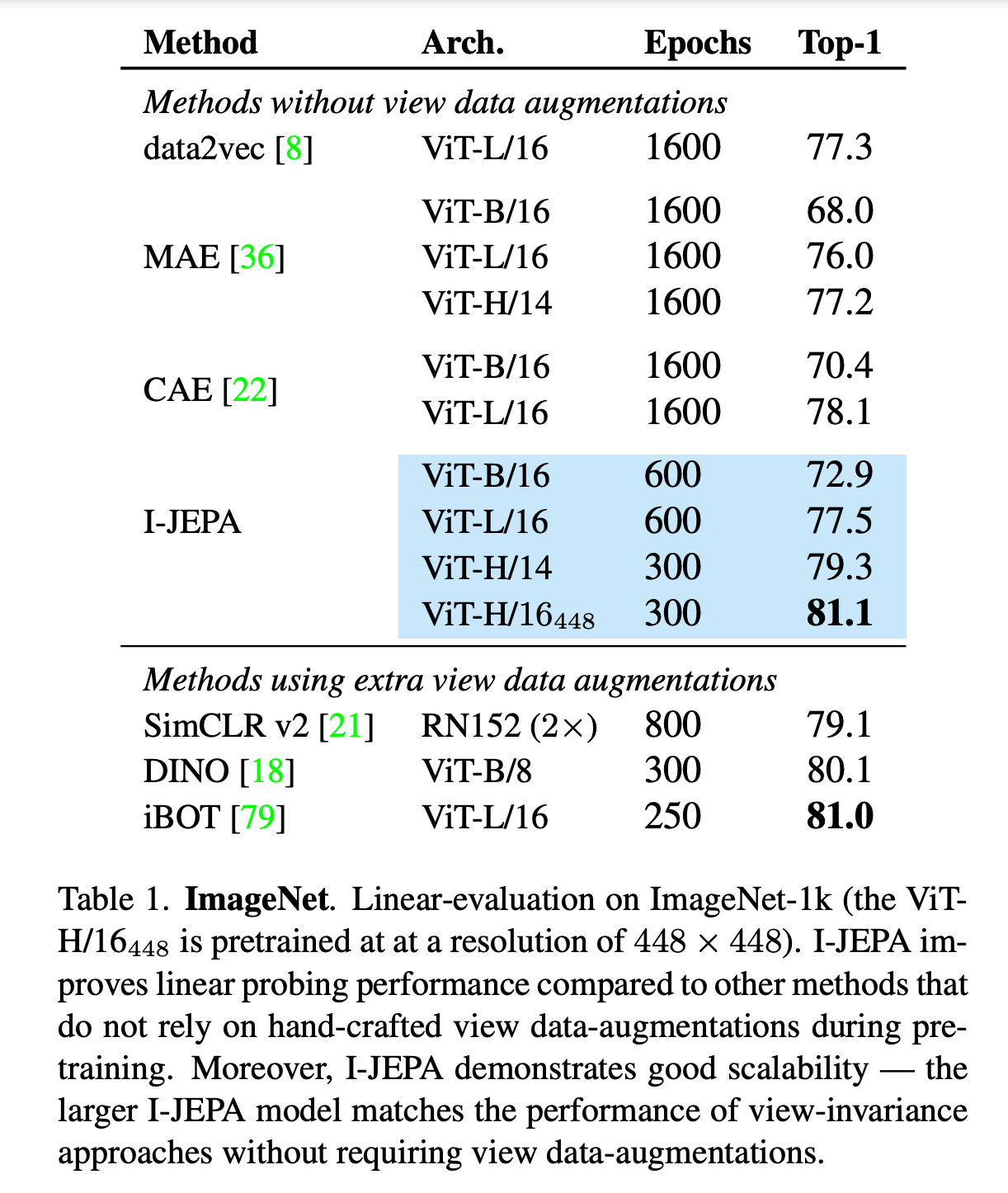
To study how good the image representations are, they report results on various image classification tasks with a “linear probe” and partial fine tuning. All I-JEPA models are trained at 224x224 resolution, except for ViT-H/16 which is trained at a resolution of 448x448. They compare the results to many approach’s before it including the MAE work that does similar operations in pixel space.
They evaluate the classification accuracy on ImageNet by using an average pooled representation of the output tokens.

I-JEPA demonstrates it can match performance of view invariance approaches without requiring data augmentation.
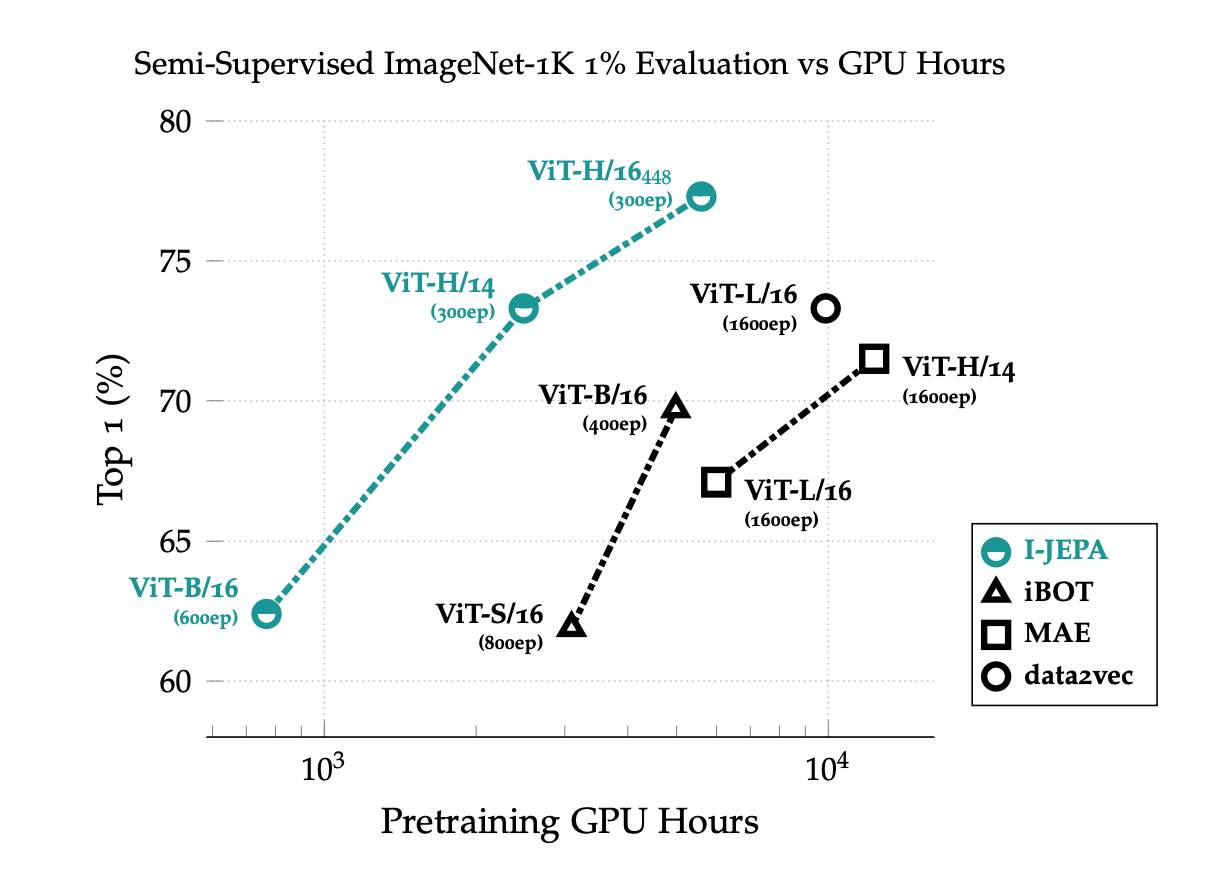
You can see it also takes less epochs to get to higher accuracy.
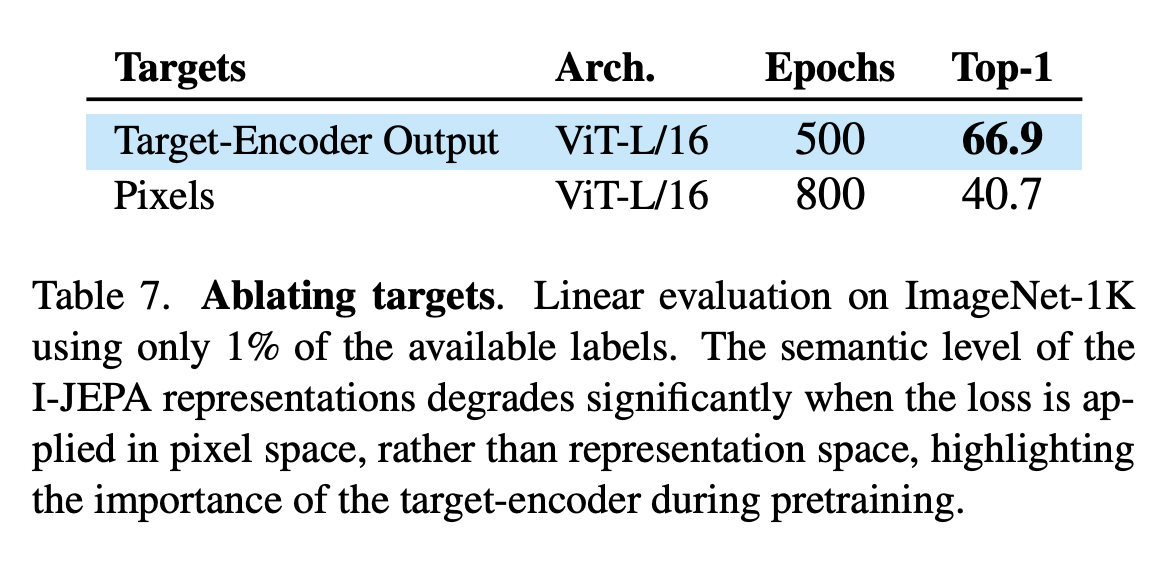
One very convincing ablation study was that they look at the linear probe when training I-JEPA in pixel space vs latent-space. Latent space blows it out of the water in less epochs.
It is also more computationally efficient and learns more semantic off-the-shelf representations.
Conclusion
After reading the diffusion transformers paper as well as the I-JEPA paper, it is clear that working in latent spaces rather than pixel spaces is:
- More efficient
- Gives higher quality semantics
We had a Discord community member @johnweak15 take a stab at implementing I-JEPA on his own and found some interesting take aways.
 Ugenteraan
UgenteraanThe main question we had was trying to understand how the model gets out of a random initialization state and avoids mode collapse. If the context encoder and the target encoder are randomly initialized aren't the latent representations going to be also going to be random at the start? So what is the ground truth latent space you are trying to optimize for? How does the network get there from a random state?
It feels like the network could either solve by mode collapsing all the latent spaces down to a single value or never have enough signal to give you something meaningful. Any clarity on initialization or intuition on how the underlying mechanism works would be appreciated! Feel free to join our Discord if you have any thoughts or answers.
Next Up
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.

All the past dives can be found on the blog.
The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI