Arxiv Dives - Self-Rewarding Language Models
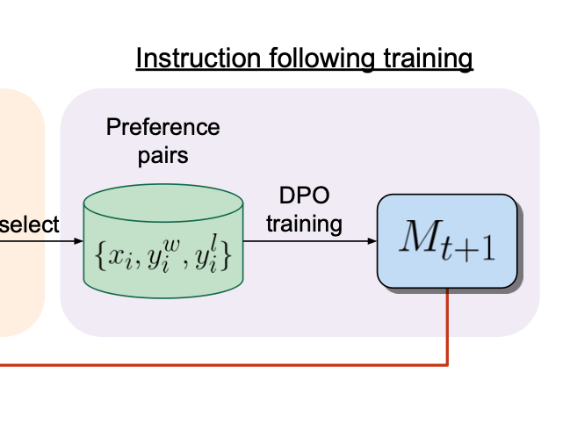
The goal of this paper is to see if we can create a self-improving feedback loop to achieve “superhuman agents”
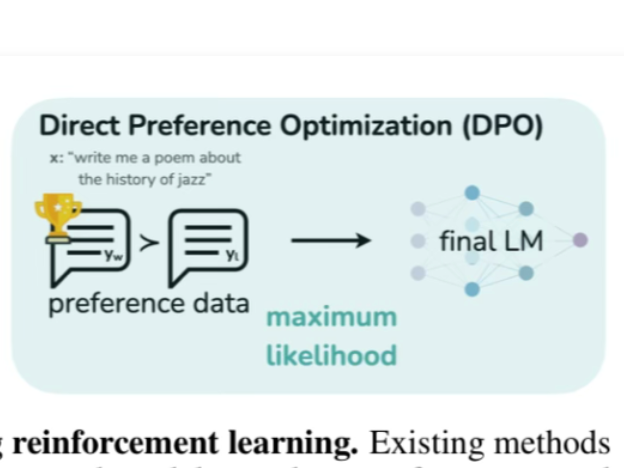
Arxiv Dives - Direct Preference Optimization (DPO)
This paper provides a simple and stable alternative to RLHF for aligning Large Language Models with human preferences called "
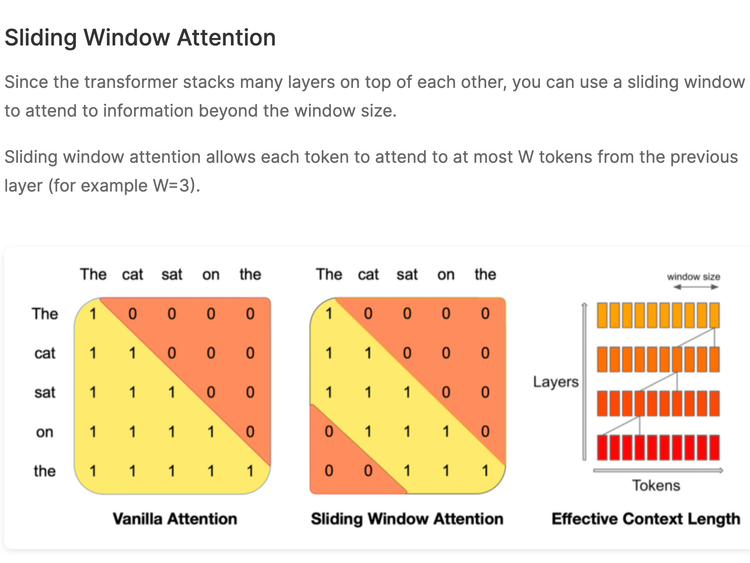
Arxiv Dives - Efficient Streaming Language Models with Attention Sinks
This paper introduces the concept of an Attention Sink which helps Large Language Models (LLMs) maintain the coherence of text
Arxiv Dives - How Mixture of Experts works with Mixtral 8x7B
Mixtral 8x7B is an open source mixture of experts large language model released by the team at Mistral.ai that
Arxiv Dives - LLaVA 🌋 an open source Large Multimodal Model (LMM)
What is LLaVA?
LLaVA is a Multi-Modal model that connects a Vision Encoder and an LLM for general purpose visual
Arxiv Dives - How Mistral 7B works
What is Mistral 7B?
Mistral 7B is an open weights large language model by Mistral.ai that was build for
Mamba: Linear-Time Sequence Modeling with Selective State Spaces - Arxiv Dives
What is Mamba 🐍?
Mamba at it's core is a recurrent neural network architecture, that outperforms Transformers with faster
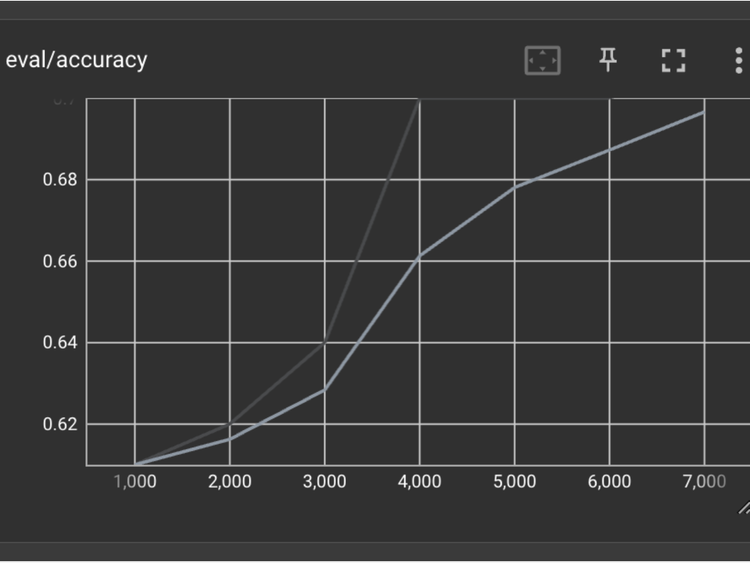
Practical ML Dive - How to customize a Vision Transformer on your own data
Welcome to Practical ML Dives, a series spin off of Arxiv Dives.
In Arxiv Dives, we cover state of the
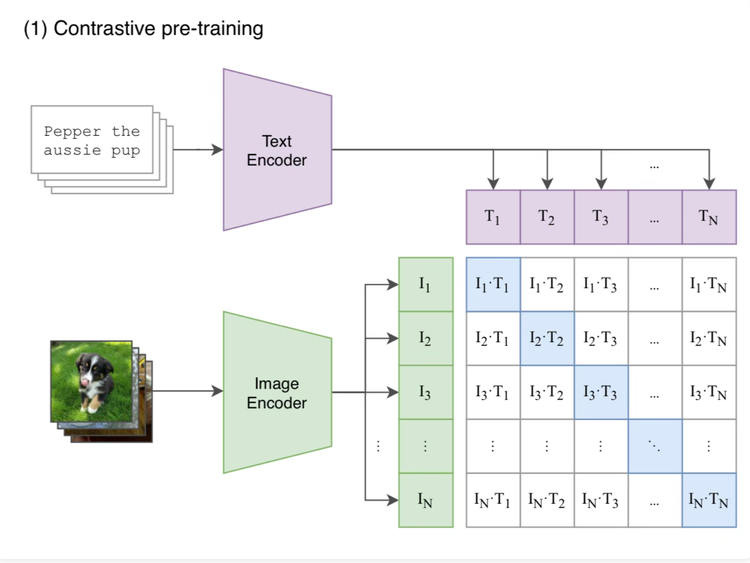
Arxiv Dives - Zero-shot Image Classification with CLIP
CLIP explores the efficacy of learning image representations from scratch with 400 million image-text pairs, showcasing zero-shot transfer capabilities across
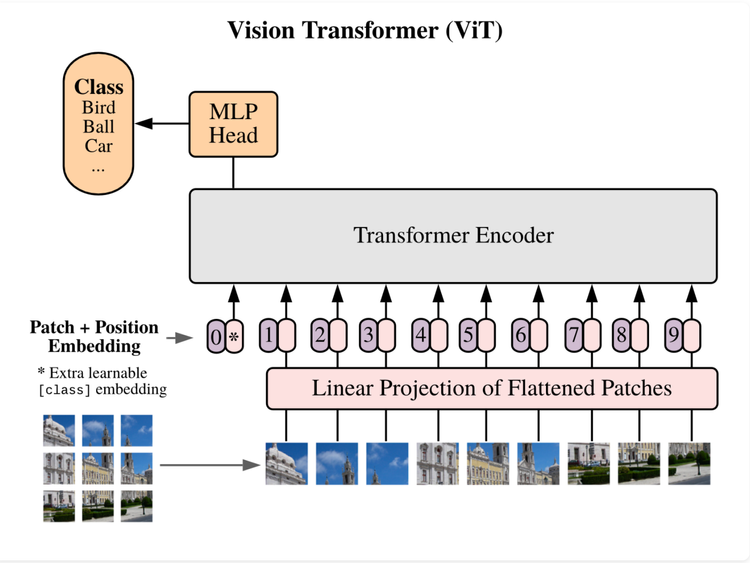
Arxiv Dives - Vision Transformers (ViT)
With all of the hype around Transformers for natural language processing and text, the authors of this paper beg the