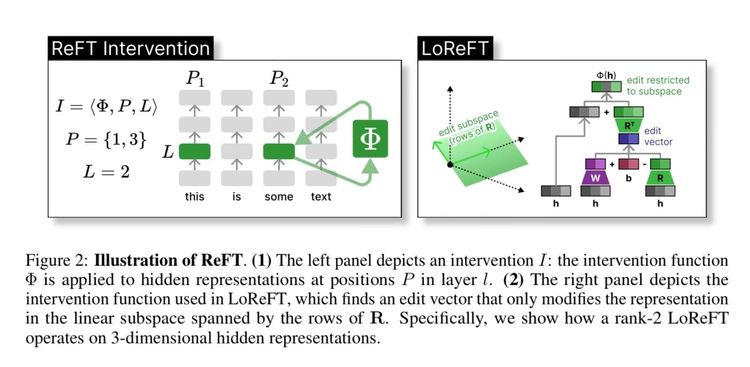
ArXiv Dives: How ReFT works
ArXiv Dives is a series of live meetups that take place on Fridays with the Oxen.ai community. We believe
ArXiv Dives:💃 Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
Modeling sequences with infinite context length is one of the dreams of Large Language models. Some LLMs such as Transformers
ArXiv Dives: Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
The ability to interpret and steer large language models is an important topic as they become more and more a
ArXiv Dives: Efficient DiT Fine-Tuning with PixART for Text to Image Generation
Diffusion Transformers have been gaining a lot of steam since OpenAI's demo of Sora back in March. The
ArXiv Dives: Evaluating LLMs for Code Completion with HumanEval
Large Language Models have shown very good ability to generalize within a distribution, and frontier models have shown incredible flexibility
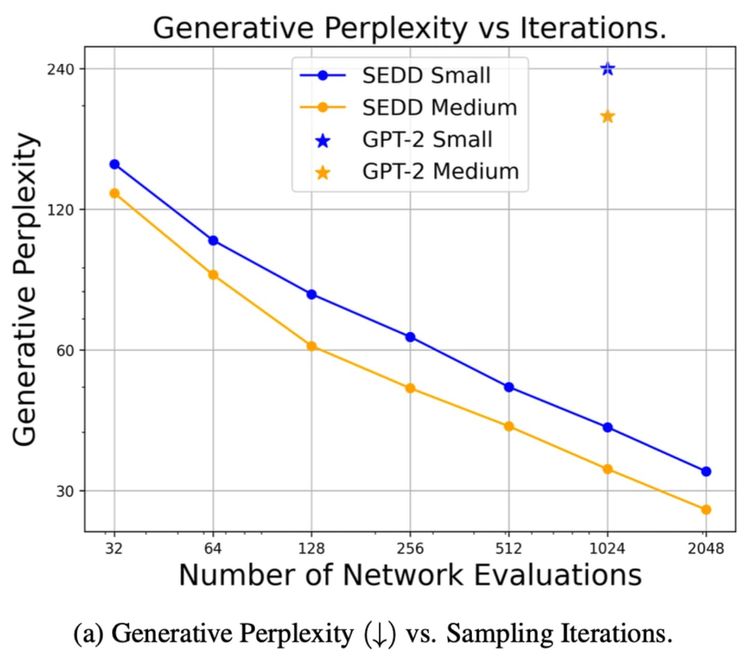
How to Train Diffusion for Text from Scratch
This is part two of a series on Diffusion for Text with Score Entropy Discrete Diffusion (SEDD) models. Today we
ArXiv Dives: Text Diffusion with SEDD
Diffusion models have been popular for computer vision tasks. Recently models such as Sora show how you can apply Diffusion
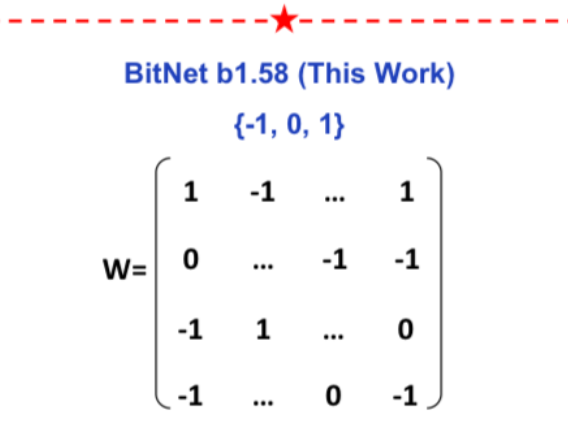
ArXiv Dives: The Era of 1-bit LLMs, All Large Language Models are in 1.58 Bits
This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1}
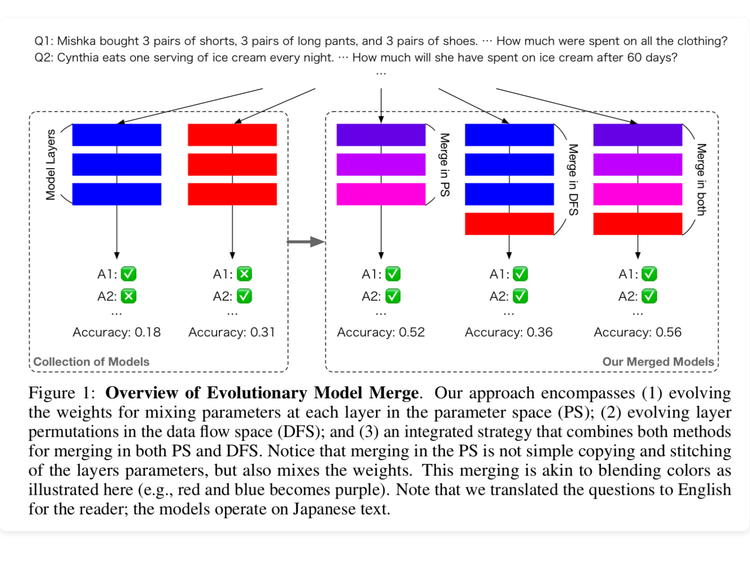
ArXiv Dives: Evolutionary Optimization of Model Merging Recipes
Today, we’re diving into a fun paper by the team at Sakana.ai called “Evolutionary Optimization of Model Merging
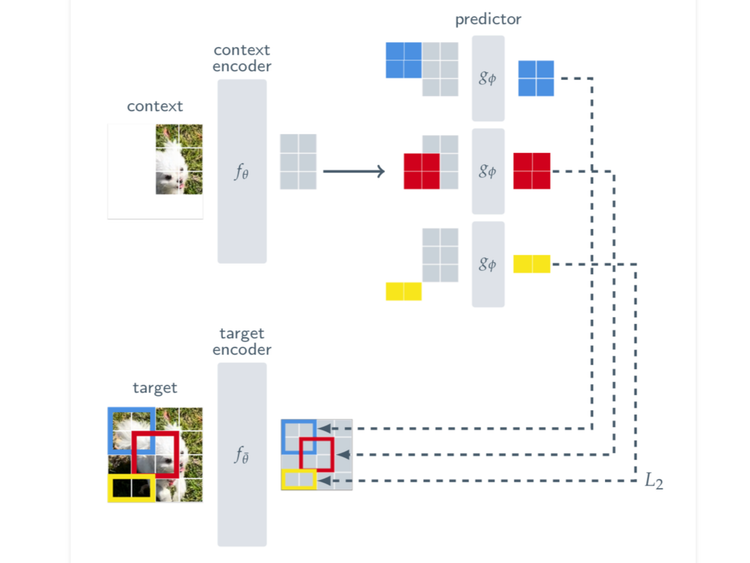
ArXiv Dives: I-JEPA
Today, we’re diving into the I-JEPA paper. JEPA stands for Joint-Embedding Predictive Architecture and if you have been following