ArXiv Dives: Text Diffusion with SEDD
Diffusion models have been popular for computer vision tasks. Recently models such as Sora show how you can apply Diffusion
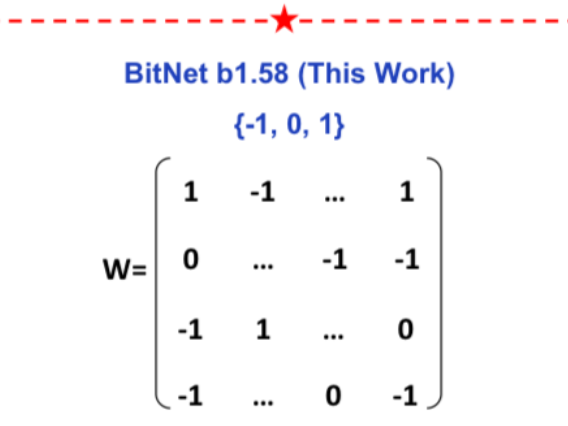
ArXiv Dives: The Era of 1-bit LLMs, All Large Language Models are in 1.58 Bits
This paper presents BitNet b1.58 where every weight in a Transformer can be represented as a {-1, 0, 1}
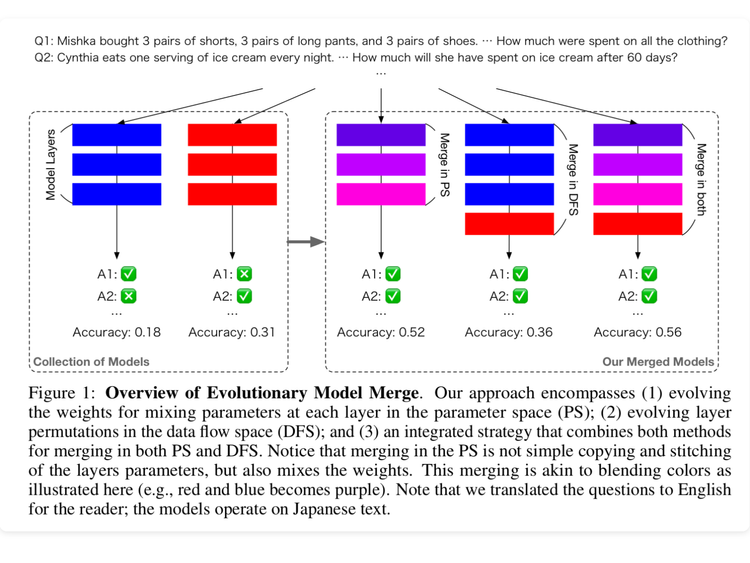
ArXiv Dives: Evolutionary Optimization of Model Merging Recipes
Today, we’re diving into a fun paper by the team at Sakana.ai called “Evolutionary Optimization of Model Merging
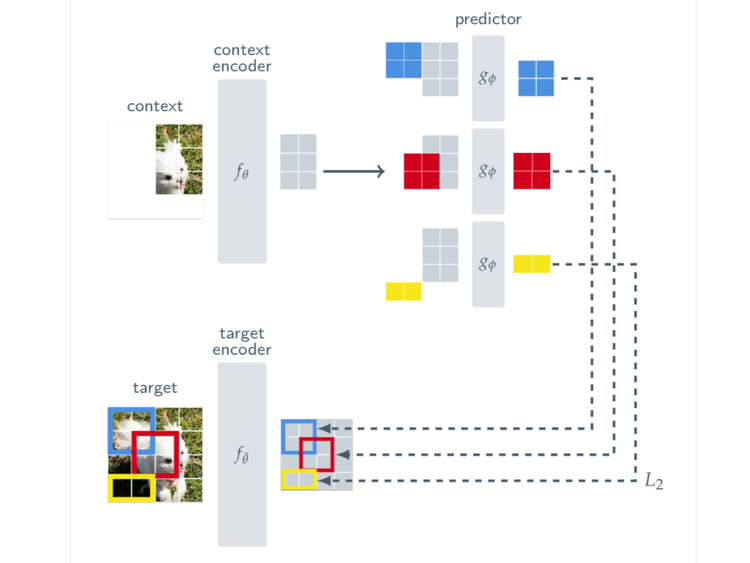
ArXiv Dives: I-JEPA
Today, we’re diving into the I-JEPA paper. JEPA stands for Joint-Embedding Predictive Architecture and if you have been following
ArXiv Dives - Diffusion Transformers
Diffusion transformers achieve state-of-the-art quality generating images by replacing the commonly used U-Net backbone with a transformer that operates on
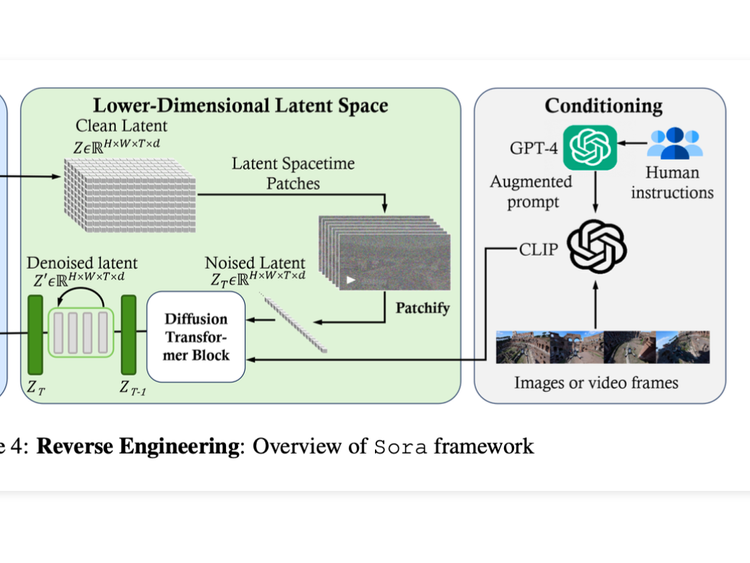
"Road to Sora" Paper Reading List
This post is an effort to put together a reading list for our Friday paper club called ArXiv Dives. Since
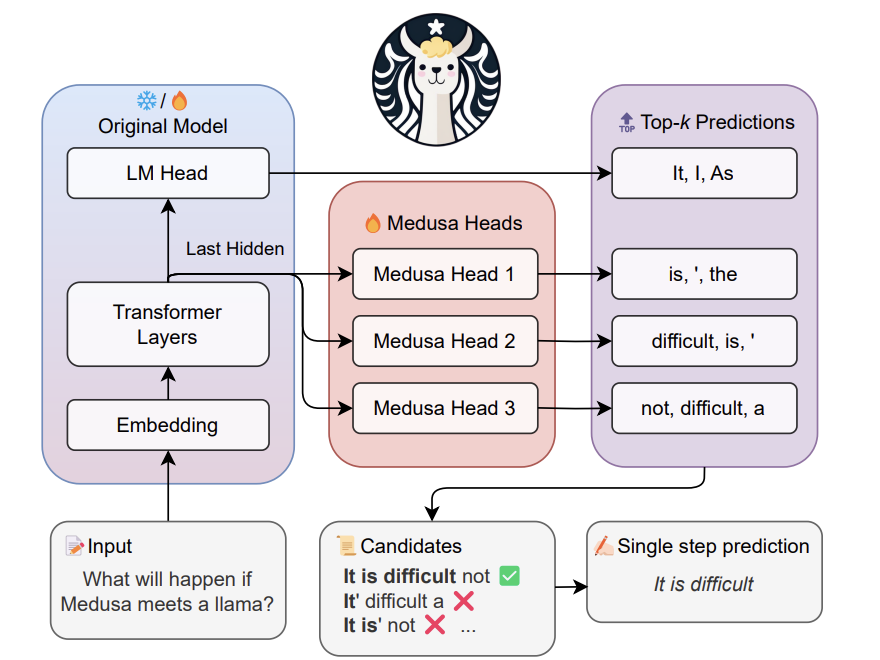
ArXiv Dives - Medusa
Abstract
In this paper, they present MEDUSA, an efficient method that augments LLM inference by adding extra decoding heads to
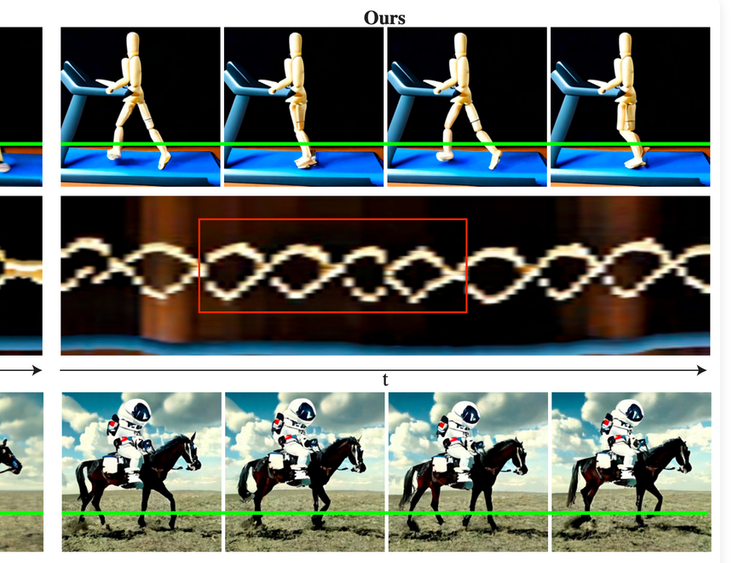
ArXiv Dives - Lumiere
This paper introduces Lumiere – a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion – a
ArXiv Dives - Depth Anything
This paper presents Depth Anything, a highly practical solution for robust monocular depth estimation. Depth estimation traditionally requires extra hardware
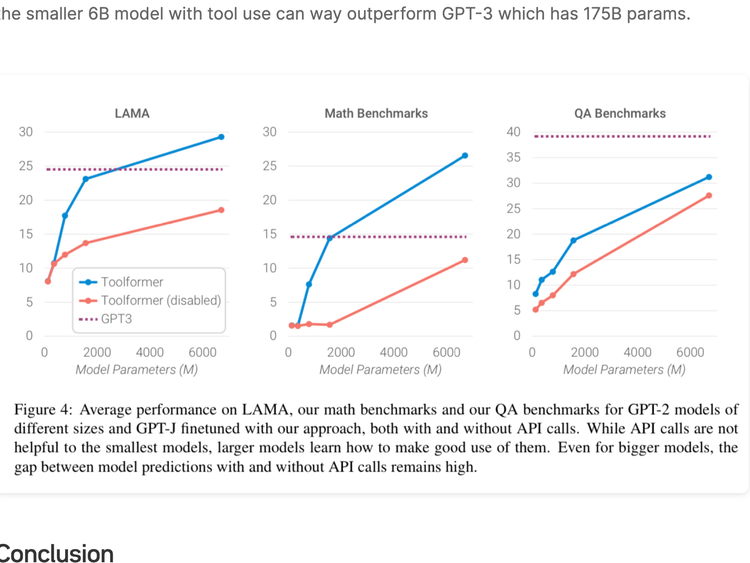
Arxiv Dives - Toolformer: Language models can teach themselves to use tools
Large Language Models (LLMs) show remarkable capabilities to solve new tasks from a few textual instructions, but they also paradoxically